文章目录
访问控制列表(Access Control List,ACL)是路由器和交换机接口的指令列表,用来控制端口进出的数据包。
这张表中包含了匹配关系、条件和查询语句,表只是一个框架结构,其目的是为了对某种访问进行控制。
1~99 和 1300~1999:标准IP ACL。(基于源P地址过滤)
100~199 和 2000~2699:扩展IP ACL。
(基于源、目的IP地址;源、目的TCP/UDP端口;协议类型)
AppleTalk: 600~699
IPX:800~899
基于每种协议设置一个ACL(per protocol)
基于每个方向设置一个ACL(per direction)
基于每个接口设置一个ACL(per interface)
入站ACL:对到来的分组进行处理后在路由到主站接口。效率高。
出站ACL:将分组路由到出站接口,然后根据ACL对其进行处理。
ACL要么应用于入站数据流要么应用于出站数据流。
ACL顺序︰
从上到下、每次一条语句。
1.访问列表的编号指明了使用何种协议的访问列表
2.每个端口、每个方向、每条协议只能对应于一条访问列表
3.访问列表的内容决定了数据的控制顺序
4.具有严格限制条件的语句应放在访问列表所有语句的最上面
5.在访问列表的最后有一条隐含声明:deny any -
每一条正确的访问列表都至少应该有一条允许语句
6.先创建访问列表,然后应用到端口上
7.访问列表不能过滤由路由器自己产生的数据
要求只允许PC1可以到达1.1.1.1其他不可以
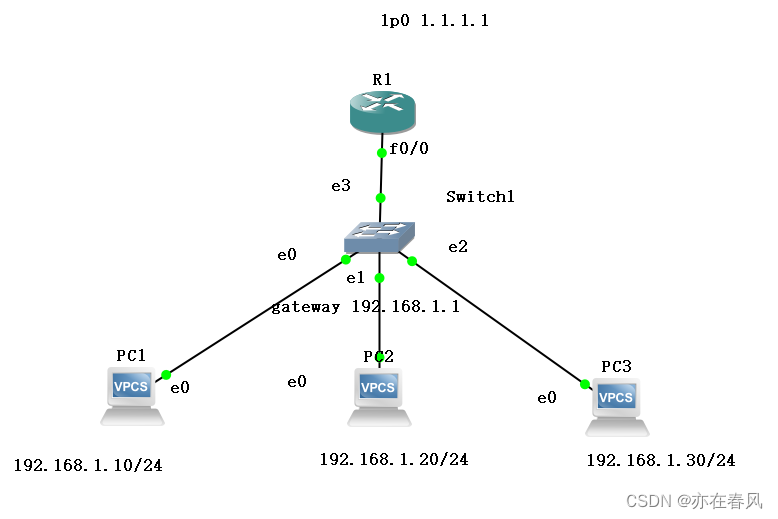
配置如下
R1# conf t
R1(config)#int f0/0
R1(config-if)#ip add 192.168.1.1 255.255.255.0
R1(config-if)#no shut
R1(config-if)#int loopb 0
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R1(config-if)#ex
R1(config)#exi
R1#
PC1
ip 192.168.1.10 24 192.168.1.1 24
PC2
ip 192.168.1.20 24 192.168.1.1 24
PC3
ip 192.168.1.30 24 192.168.1.1 24
验证一下
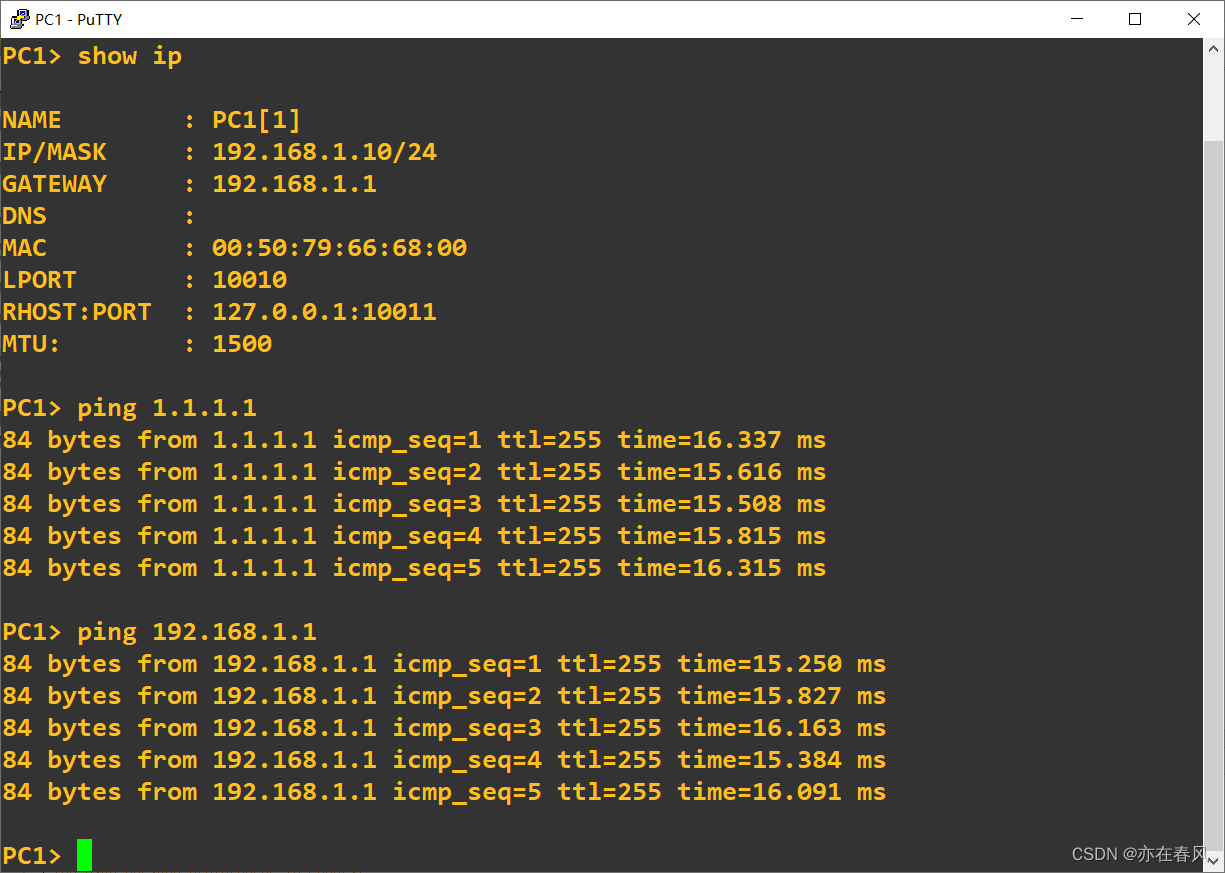
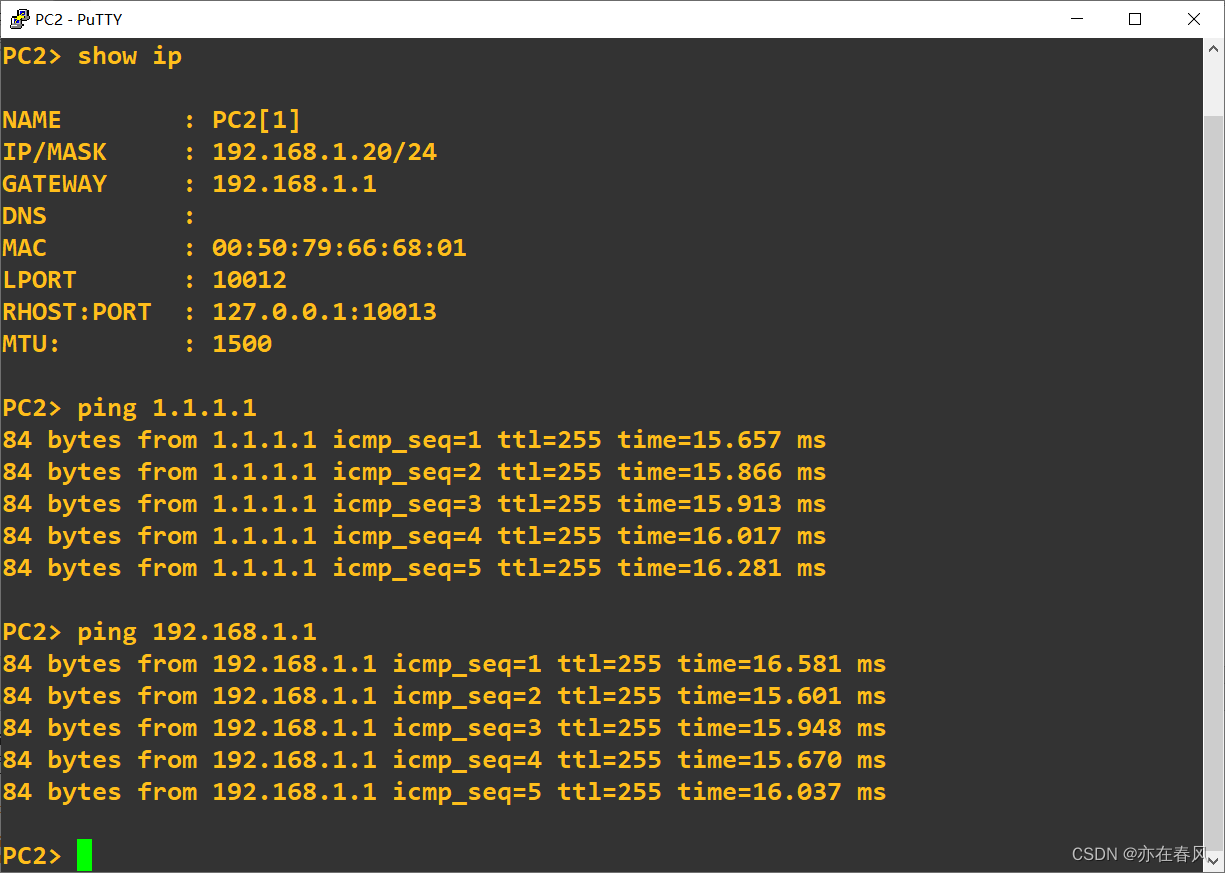
R1#conf t
R1(config)#access-list 100 per
R1(config)#access-list 100 permit icmp host 192.168.1.10 host 1.1.1.1 echo
R1(config) #access-list 100 deny icmp any host 1.1.1.1 echo
R1(config)#
解释
查看一下
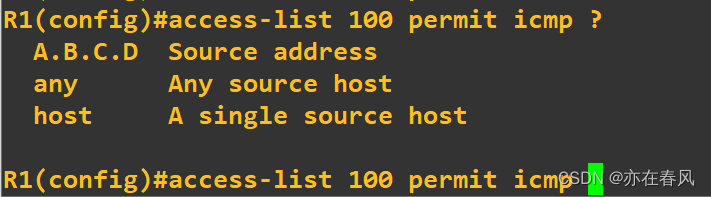
因为使用ping嘛,所以用的是ICMP协议,具体操作可以使用 ‘?’ 查看
看到ICMP 后面可以跟源地址,可以跟any,也可以跟主机,我们是为了PC1可以通过选择host,而且源地址选择一般是用于一个网段,any就是任何都可以
所以上述ACL配置选择拓展ACL,匹配由上到下
然后应用到端口
R1(config)#int f0/0
R1(config-if)#ip access-group 100 in
R1(config-if)#
写完之后我们验证一下
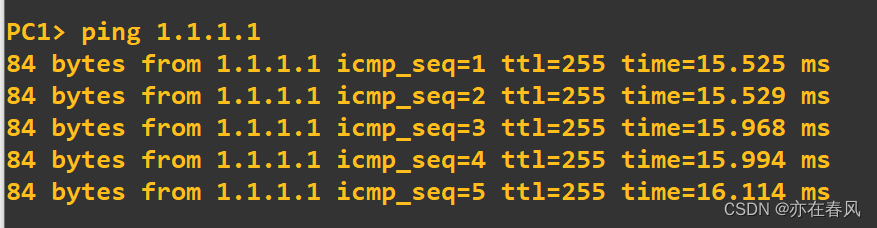

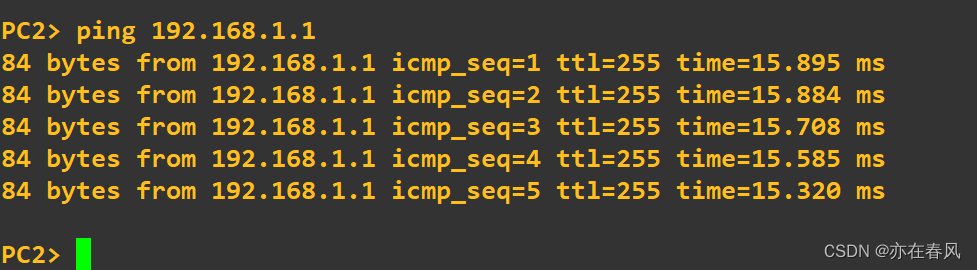
可以看到PC2被管理进制通讯交流
此时我们ping 一下网关看看是否可以交流
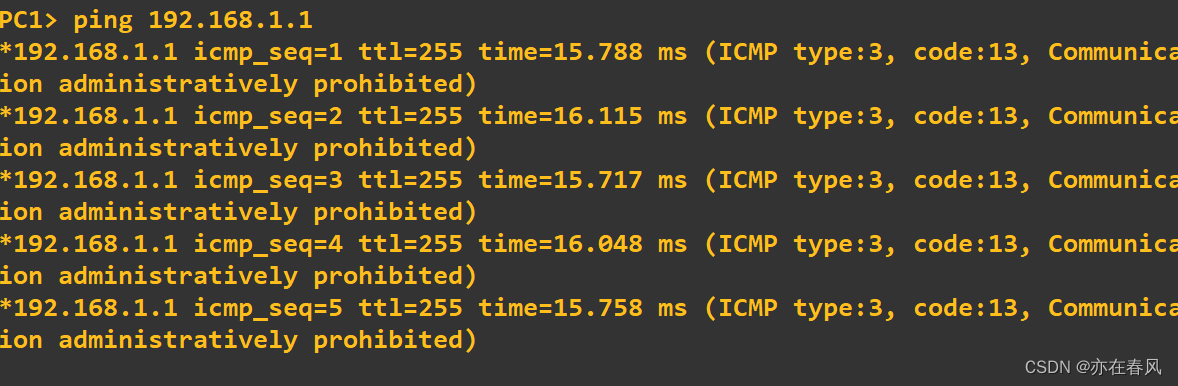
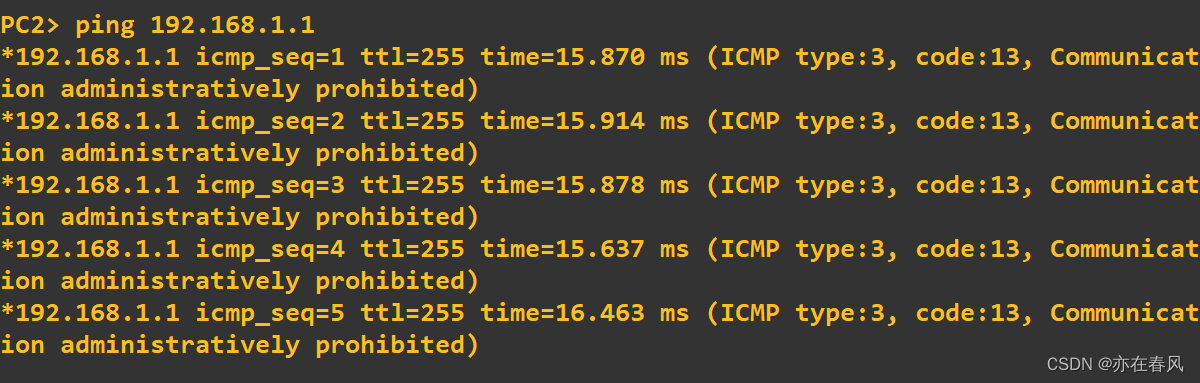
发现PC1与PC2均无法ping通网关
查看一下列表
show access-lists 100

为什么ping不通网关
因为ACL列表包含一个隐藏语句就是 deny any any
列表执行最后拒绝所有流量,所以之前列表没有192.168.1.1的匹配自然就被过滤掉
我们需要这样配置
access-list 100 permit ip any any
就可以了
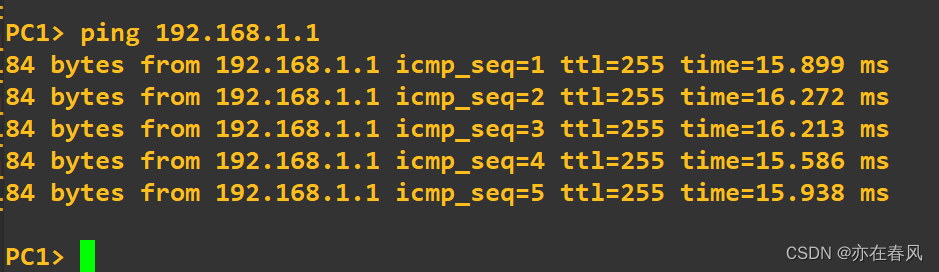

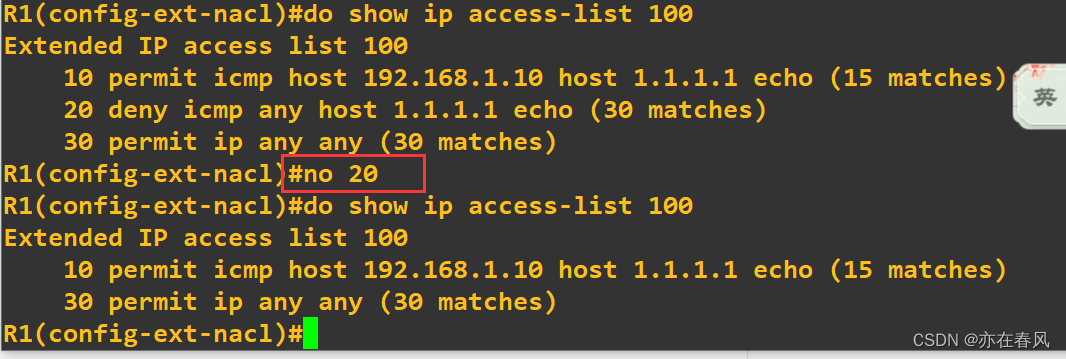
这是列表内容 假如对一条不满意怎么删除?

如下图所示,并没有删除语句,要删除就只能把整张表删掉

显然不合理,于是就有更高层次用法
ip access-list
我们是拓展ACL

加入表号进入配置查看ACL列表可以根据需要,根据序号进行删除
当然添加也可以指定添加,可以指定序号,其顺序是按照序号大小进行升序排列
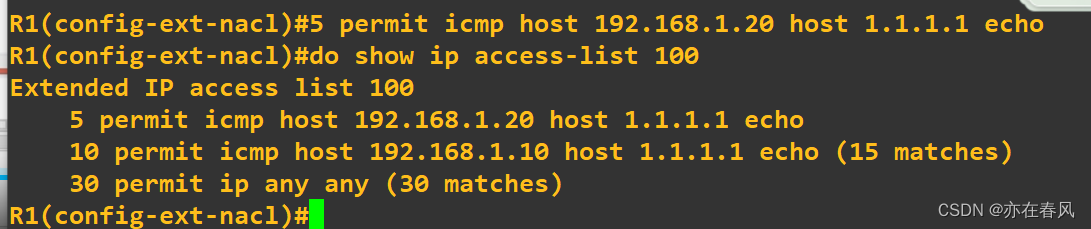
这样执行的列表顺序就可以改变了
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
是否有类似“RVMuse1”或“RVMuselist[0]”之类的内容而不是键入整个版本号。在任何时候,我们都会看到一个可能包含5个或更多ruby的列表,我们可以轻松地键入一个数字而不是X.X.X。这也有助于rvmgemset。 最佳答案 这在RVM2.0中是可能的=>https://docs.google.com/document/d/1xW9GeEpLOWPcddDg_hOPvK4oeLxJmU3Q5FiCNT7nTAc/edit?usp=sharing-知道链接的任何人都可以发表评论
当我在Rails控制台中按向上或向左箭头时,出现此错误:irb(main):001:0>/Users/me/.rvm/gems/ruby-2.0.0-p247/gems/rb-readline-0.4.2/lib/rbreadline.rb:4269:in`blockin_rl_dispatch_subseq':invalidbytesequenceinUTF-8(ArgumentError)我使用rvm来管理我的ruby安装。我正在使用=>ruby-2.0.0-p247[x86_64]我使用bundle来管理我的gem,并且我有rb-readline(0.4.2)(人们推荐的最少
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我将我的Rails应用程序部署到OpenShift,它运行良好,但我无法在生产服务器上运行“Rails控制台”。它给了我这个错误。我该如何解决这个问题?我尝试更新rubygems,但它也给出了权限被拒绝的错误,我也无法做到。railsc错误:Warning:You'reusingRubygems1.8.24withSpring.UpgradetoatleastRubygems2.1.0andrun`gempristine--all`forbetterstartupperformance./opt/rh/ruby193/root/usr/share/rubygems/rubygems
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file