1、集群的含义
2、企业集群分类
3、负载均衡集群架构
4、负载均衡群集工作模式分析(LVS)
5、LVS的负载调度算法
6、ipvsadm工具
7、NAT模式 LVS负载均衡集群部署
1、集群的含义
Cluster,集群、群集,为解决某个特定问题将多台计算机组合起来形成的单个系统
由多台主机构成,但对外只表现为一个整体
遇到的问题
互联网应用中,随着站点对硬件性能、响应速度、
服务稳定性、数据可靠性等要求越来越高,单台服务器力不从心
解决方案
使用价格昂贵的小型机、大型机
使用普通服务器构建服务集群
2、企业集群分类
负载均衡集群
LB: Load Balancing,负载均衡,多个主机组成,每个主机只承担一部分访问请求
提高应用系统的响应能力、尽可能处理更多的访问请求、减少延迟为目标,获得高并发、高负载(LB)的整体性能
LB的负载分配依赖于主节点的分流算法(接收、转发、连接数)
2.2高可用群集(HA 表示高可用 -》冗余、备份、缓解解决了单点故障)
HA: High Availiablity,高可用,避免 SPOF (single Point Of failure)
提高应用系统的可靠性、尽可能地减少中断时间为目标,确保服务的连续性,达到高可用
(HA)的容错效果
HA的工作方式包括双工和主从两种模式
2.3高性能运算群集
HPC: High-performance computing,高性能
提高应用系统的CPU运算速度、扩展硬件资源和分析能力为目标,获得相当于大型、超级计算机的高性能运算(HPC)能力高性能依赖于"分布式运算"、"并行计算",通过专用硬件和软件将多个服务器的CPU、内存等资源整合在一起,实现只有大型、超级计算机才具备的计算能力
拓展:
VRRP协议特点
VRRP协议:备份、冗余
根据优先级进行飘逸VIP
1、根据优先级选出主-备关系
2、主-备之间,可以以ping的方式检测对方的心跳(心跳线)
3、当主异常-》优先级下降-》当低于备的优先级-》VIP地址的飘逸
PS:VIP地址特性:只会存在于同一个热备组中优先级最高级的设备上
以上是抢占模式
VIP好处-》VIP占用一个ipv4 常规情况下,VIP占用的ipv4的地址也是不可重复的
①因为是虚拟IP,所以可以保护后端的真实IP
②VIP特性之一是可飘逸,相对于服务器的网卡IP而言,服务器的网卡是没法飘逸,当该节点发生故障,导致不可访问时
只能等待修复后,重新提供该网卡的ip ,但是VIP具有根据优先级进行飘逸的特性,所以只要在同一个热备组中,有服务器存活,就可以进行飘逸,不会影响对外暴露IP、提供服务
应用场景:高可用-》解决什么问题?-》单点故障
3、负载均衡群集架构
第一层,负载调度器(Load Balancer或Director)
第二层,服务器池(Server Pool)
第三层,共享存储(Share Storage)
4、负载均衡群集工作模式分析(LVS)
负载均衡群集是目前企业用得最多的群集类型
群集的负载调度技术有三种工作模式
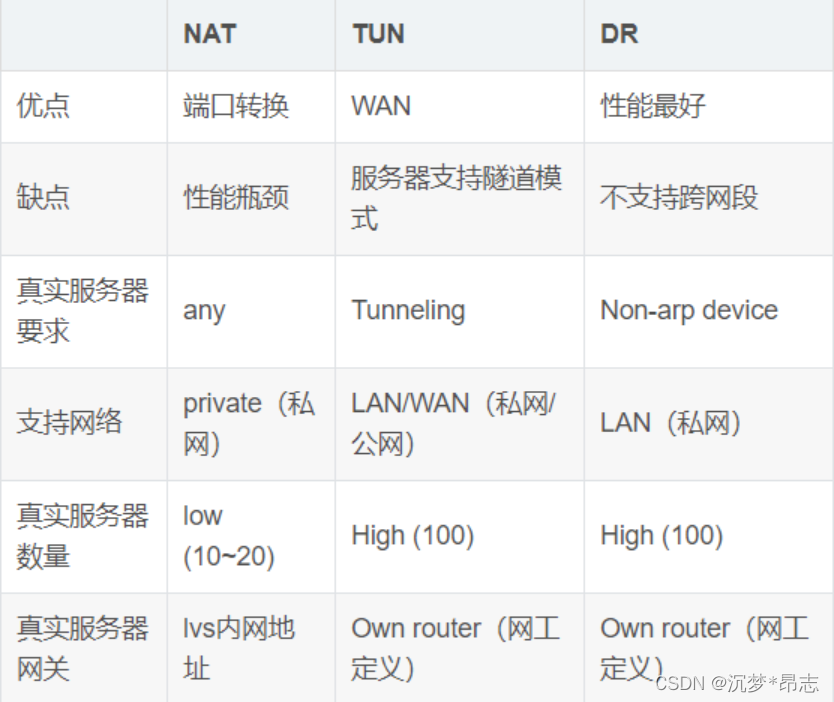
地址转换(NAT地址映射)
IP隧道(隧道模式叠加网络)
直接路由(DR NAT)
LVS的NAT模式
Network Address Translation,简称NAT模式
类似于防火墙的私有网络结构,负载调度器作为所有服务器节点的网关,即作为客户机的访问入口,也是各节点回应客户机的访问出口
服务器节点使用私有IP地址,与负载调度器位于同一个物理网络,安全性要优于其他两种方式
适用场景:LVS
单台LVS服务器的话:LVS如果做为LB-》工作在4层
HA-》LVS的负载均衡->LVS+keepalived—》可工作在4层和7层
并且,LB-4层的LVS负载均衡器能力在lvs Nginx apache haproxy常用的负载均衡器中是最强的
同时,在K8S中基于L4层的负载均衡技术———》默认适用的就是LVS
IP隧道
①RIP和DIP可以不处于同一物理网络中,RS的网关一般不能指向DIP,且RIP可以和公网通信。也就是
说集群节点可以跨互联网实现。DIP, VIP, RIP可以是公网地址。
②RealServer的通道接口上需要配置VIP地址,以便接收DIP转发过来的数据包,以及作为响应的
报文源IP。
③DIP转发给RealServer时需要借助隧道,隧道外层的IP头部的源IP是DIP,目标IP是RIP,而
RealServer响应给客户端的IP头部是根据隧道内层的IP头分析得到的,源IP是VIP,目标IP是CIP
④请求报文要经由Director,但响应不经由Director,响应由RealServer自己完成
⑤不支持端口映射
⑥RS的OS须支持隧道功能
直接路由
①直接路由(Direct Routing):简称 DR 模式,采用半开放式的网络结构,与 TUN
模式的结构类似,但各节点并不是分散在各地,而是与调度器位于同一个物理网络。
②负载调度器与各节点服务器通过本地网络连接,不需要建立专用的 IP 隧道
直接路由,LVS默认模式,应用最广泛,通过请求报文重新封装一个MAC首部进行转发,
源MAC是DIP所在的接口的MAC,目标MAC是某挑选出的RS的RIP所在接口的MAC地址;
③源IP/PORT,以及目标IP/PORT均保持不变
LVS工作模式总结和比较
5、LVS的负载调度算法
轮询(Round Robin)
将收到的访问请求按照顺序轮流分配给群集中的各节点(真实服务器)
均等地对待每台服务器,而不管服务器实际的连接数和系统负载。
加权轮询(Weighted Round Robin)
根据调度器设置的权重值来分发请求,权重值高的节点优先获得任务,分配的请求数越多
保证性能强的服务器承担更多的访问流量
最少连接(Least Connections)
根据真实服务器已建立的连接数进行分配
将收到的访问请求优先分配给连接数最少的节点
如果所有的服务器节点性能相近,采用这种方式可以更好的均衡负载
加权最少连接(Weighted Least Connections)
在服务器节点的性能差异较大时,可以为真实服务器自动调整权重性能较高的节点将承担更大比例的活动连接负载
(如果RR WRR分配、考虑的对象是访问请求的数量
最小连接:考虑的是真实服务器之上已经建立连接的连接数
加权最小连接:)
6、ipvsadm工具

7、NAT模式 LVS负载均衡集群部署
配置环境
LVS负载调度器:ens33:192.168.174.11 ens37:192.168.100.100(vmnet1)
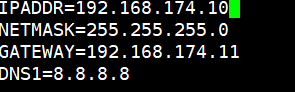
Web 节点服务器1:192.168.174.10
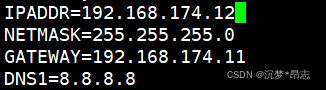
Web 节点服务器2:192.168.174.12
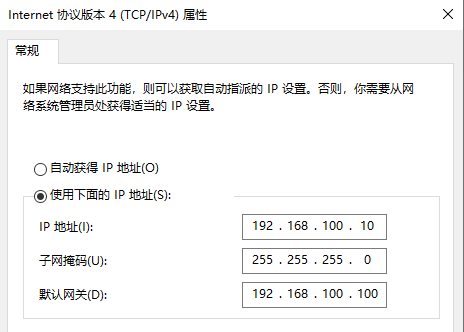
客户端(win10):192.168.100.10 (Vmnet1)
关闭三台自己机器的防火墙和增强服务
三台机器下载httpd
yum install -y httpd
然后lvs服务器添加一张网卡,将网卡设置为vmnet2(仅主机模式)
vmnet2网段为192.168.174.0段
复制一张ens37网卡
修改网卡配置为以下

保存退出
systemctl restart network
window机器的网卡配置为下图,也选择vmnet2网卡
倆台web服务器网卡配置为
保存退出
重启网卡
再进入lvs配置
vim /etc/sysctl.conf
net.ipv4.ip_forward=1
sysctl -p #刷新一下
配置iptables防火墙
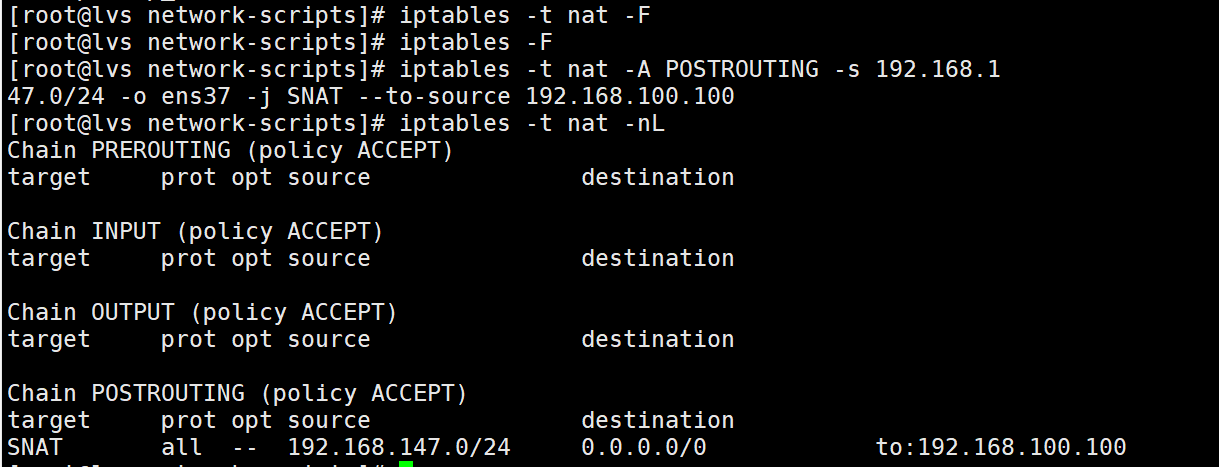
安装ipvsadm管理工具
yum install -y ipvsadm
加载LVS内核模块
modprobe ip_vs #手动加载ip_vs模块
cat /proc/net/ip_vs #查看ip_vs版本信息

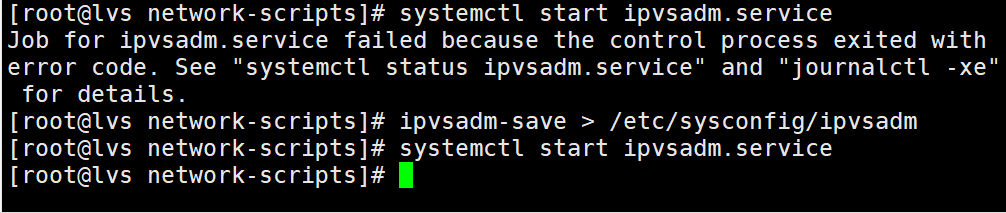
启动服务前必须保存负载分配策略,否则将会报错
ipvsadm-save > /etc/sysconfig/ipvsadm
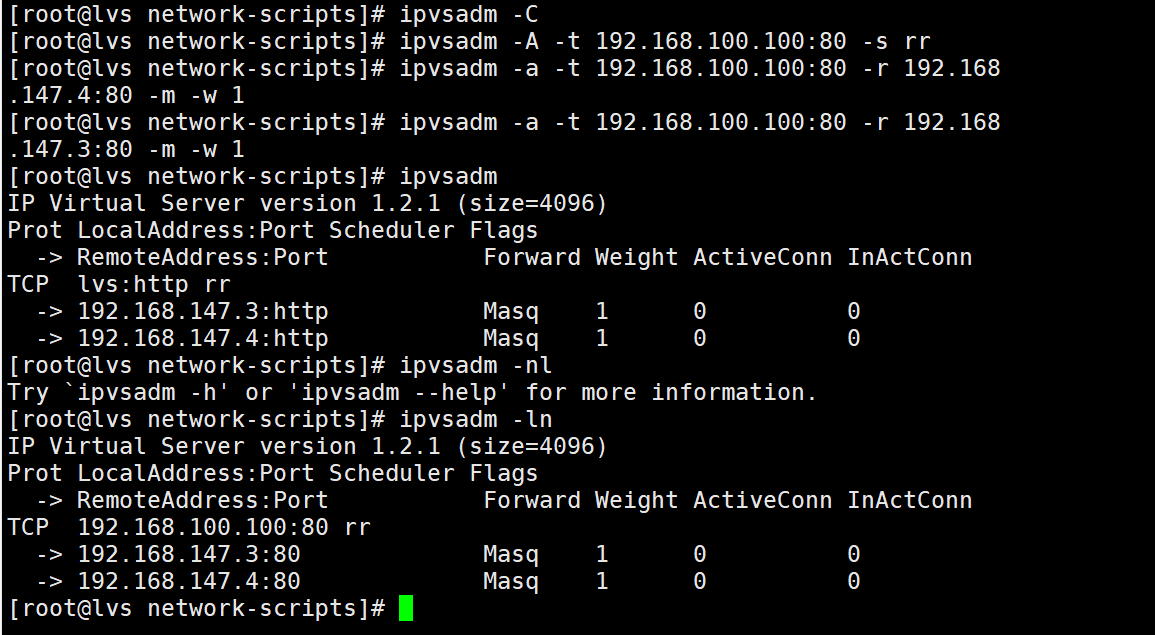
配置负载分配策略
NAT模式只要在服务器上配置,节点服务器不需要特殊配置
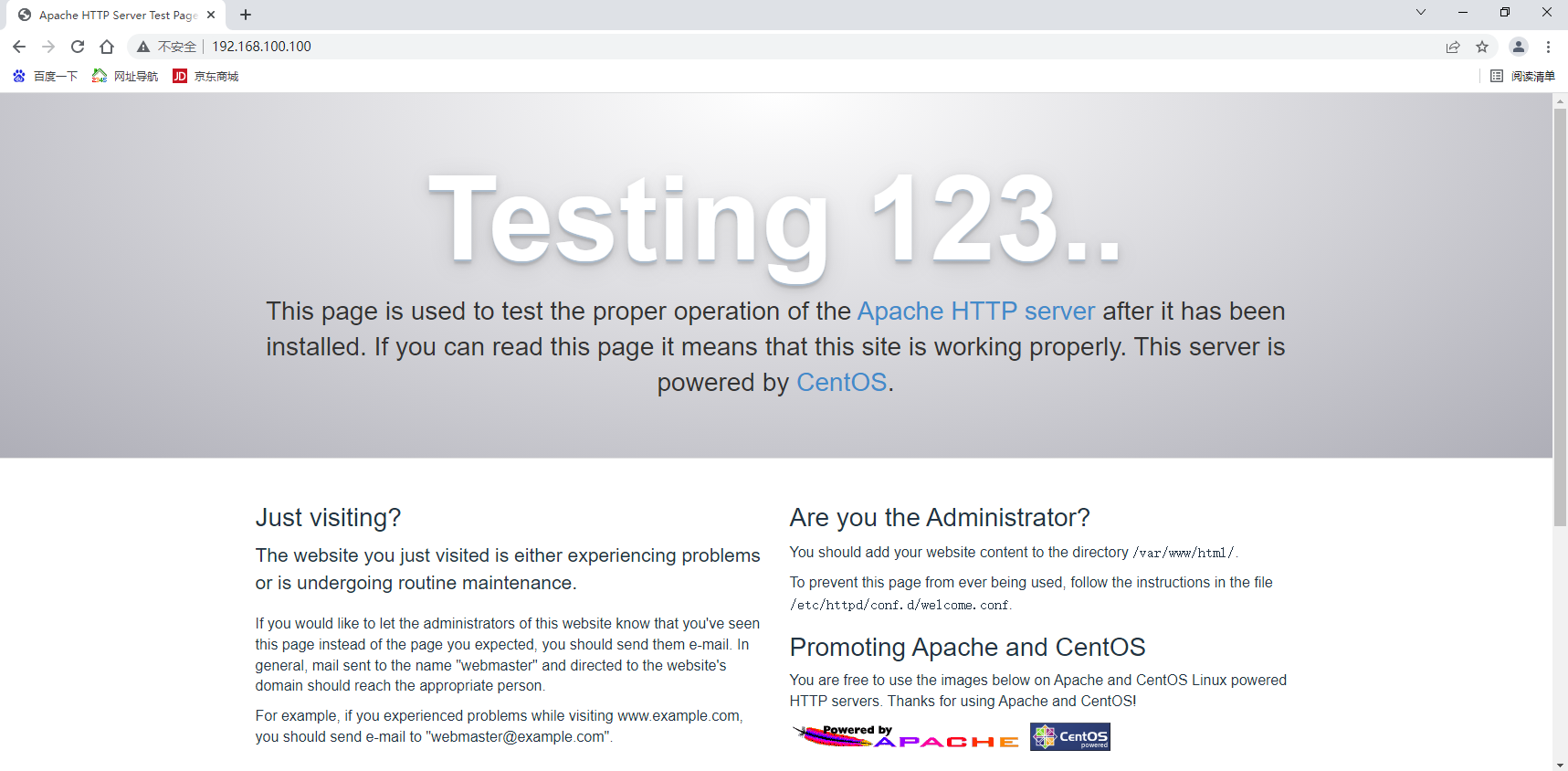
使用windows去访问192.168.100.100,多刷新几次查看lvs服务上的连接数
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
这应该是一个简单的问题,但我找不到任何相关信息。给定一个Ruby中的正则表达式,对于每个匹配项,我需要检索匹配的模式$1、$2,但我还需要匹配位置。我知道=~运算符为我提供了第一个匹配项的位置,而string.scan(/regex/)为我提供了所有匹配模式。如果可能,我需要在同一步骤中获得两个结果。 最佳答案 MatchDatastring.scan(regex)do$1#Patternatfirstposition$2#Patternatsecondposition$~.offset(1)#Startingandendingpo
我想开始使用“Sinatra”框架进行编码,但我找不到该框架的“MVC”模式。是“MVC-Sinatra”模式或框架吗? 最佳答案 您可能想查看Padrino这是一个围绕Sinatra构建的框架,可为您的项目提供更“类似Rails”的感觉,但没有那么多隐藏的魔法。这是使用Sinatra可以做什么的一个很好的例子。虽然如果您需要开始使用这很好,但我个人建议您将它用作学习工具,以对您来说最有意义的方式使用Sinatra构建您自己的应用程序。写一些测试/期望,写一些代码,通过测试-重复:)至于ORM,你还应该结帐Sequel其中(imho
有没有一种方法可以自动生成种子数据文件并创建种子数据,就像您在下面链接中的Laravel中看到的那样?LaravelDatabaseMigrations&Seed我在另一个应用程序上看到在Rails的db文件夹下创建了一些带有时间戳的文件,其中包含种子数据。创建它的好方法是什么? 最佳答案 我建议你使用Fabrication的组合gem和Faker.Fabrication允许您编写一个模式来构建您的对象,而Faker为您提供虚假数据,如姓名、电子邮件、电话号码等。这是制造商的样子:Fabricator(:user)dousernam
我有一个交互式RubyonRails应用程序,我想在特定时间将其置于“只读模式”。这将允许用户读取他们需要的数据,但阻止他们执行写入数据库的操作。执行此操作的一种方法是在数据库中放置一个true/false变量,该变量在进行任何写入之前进行检查。我的问题。有没有更优雅的解决方案来解决这个问题? 最佳答案 如果你真的想阻止任何数据库写入,我能想到的最简单的方法是覆盖readonly?始终返回true的模型方法,无论是在选定模型中还是对于所有ActiveRecord模型。如果模型设置为只读(通常通过调用#readonly!来完成),任何