文章目录
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。它最初是用来搜寻 XML 文档的,现在它同样适用于 HTML 文档的搜索
XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式 。 另外,它还提供了超过100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等 。 几乎所有我们想要定位的节点,都可以用 XPath 来选择 。
pip install lxml
读取本地html文件
etree模块会自动修正HTML文件中缺失的内容
from lxml import etree
# 读取html文档,字符串
fp = open("index.html",'r',encoding='utf-8')
html = fp.read()
# 实例化XPath解析对象,可以将字符串转换成Element对象
tree = etree.HTML(html)
print(tree)
web网站html文件
from lxml import etree
import requests
html = requests.get(url="https://www.baidu.com")
tree = etree.HTML(html.text)
print(tree)
xpath的使用其实就是根据表达式找出文档中所有符合条件的内容
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是text节点 |
fp = open("index.html",'r',encoding='utf-8')
html = fp.read()
tree = etree.HTML(html)
result = tree.xpath("//*") # 获取所有节点
print(result)
输入:

解释:
// 获取当前节点的子孙节点 * 代表匹配所有节点,//* 就代表获取当前节点的所有子孙节点
获取子孙节点中的div节点
# 获取当前节点下的所有div的子孙节点
result = tree.xpath("//div")
输出:

现在要获取<html>下的head节点以及head节点里面的title节点
result = tree.xpath("/html/head") # 获取head节点
print(result)
result = tree.xpath("/html/head/title") # 获取title节点
print(result)
输出:
解释:这里我们采用的是 /来进行获取的,每次获取一级,依次获取到目标元素
通过 / 、//可以获取子节点或者子孙节点,现在我学习如何通过子节点找父节点
找出li节点的父节点,找出li节点的父节点的父亲节点
result = tree.xpath("//li/..")
print(result)
result = tree.xpath("//li/../..")
print(result)
输出:

通过输出我们可以看到li的父节点是ul, ul的父节点是div
解释:
先通过 //li找到li节点在通过 .. 找到父节点
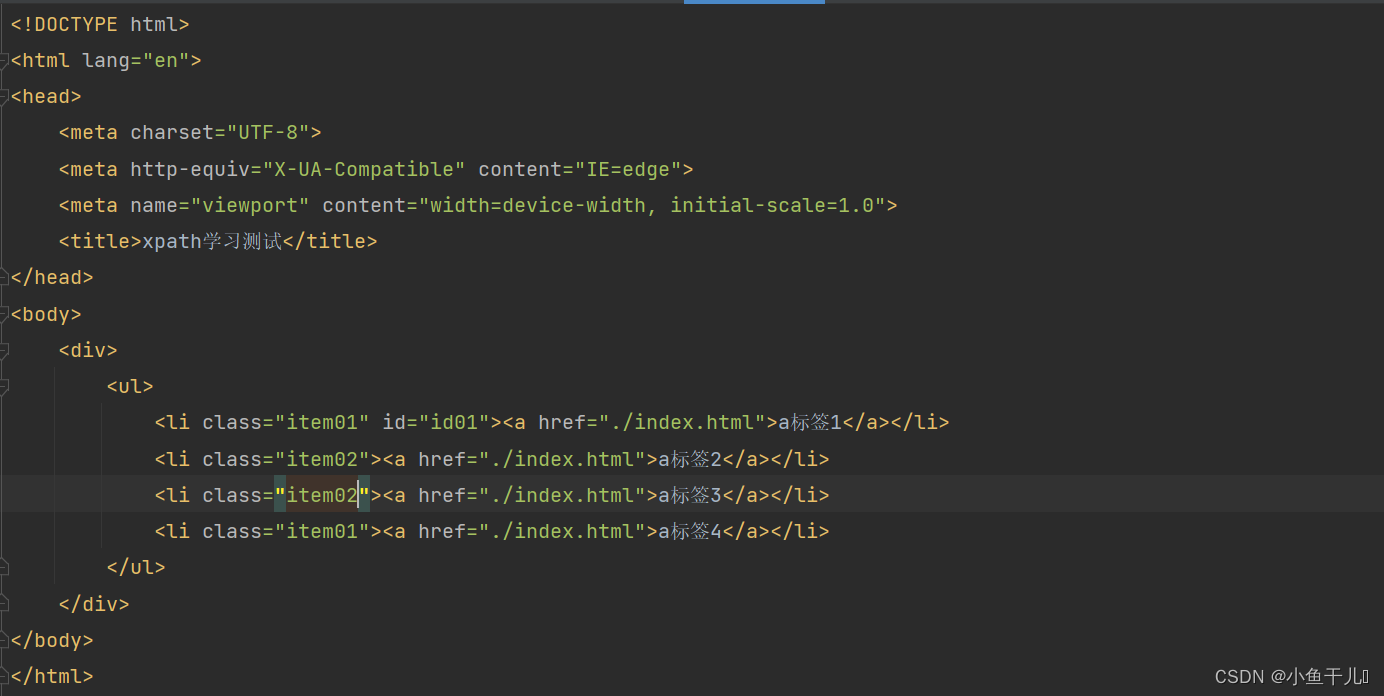
找出li标签中class=item01的元素
result = tree.xpath('/html/body/div/ul/li[@class="item01"]')
print(result)
输出:

选择属性中有id的
result = tree.xpath('/html/body/div/ul/li[@id]')
print(result)
输出:

解释:
通过@ 我们可以根据属性寻找节点,可以指定属性值,也可以直接根据属性进行查询
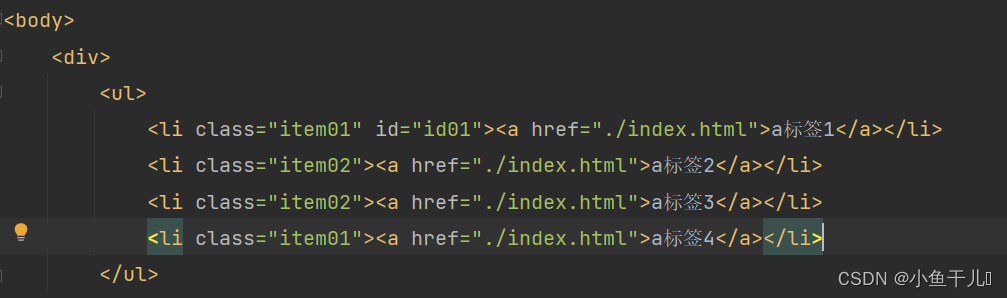
获取li中的文字
# 直接获取li标签下面所有子孙元素的文字
result = tree.xpath('/html/body/div/ul/li//text()')
print(result)
# 通过寻找子元素的方式,一级一级的找到文字
result2 = tree.xpath('/html/body/div/ul/li/a/text()')
print(result2)
输出:

通过输出的内容分析我们能够看出,直接通过li//text()获取到文本内容会比li/a/text()获取的多,因为li//text()或获取li中所有的文字包括换行,而li/a/text()只会找出a标签下所有的文字
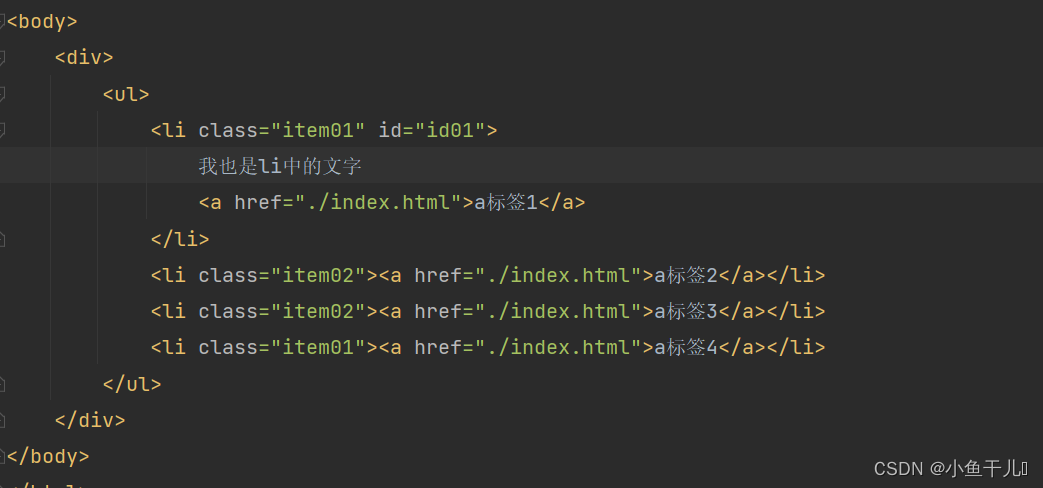
有时候我们在进行数据解析的时候会需要一些属性值,例如我们在写爬虫项目的时候我们往往需要url链接
找出li中id=id01 a标签中 href的值
result = tree.xpath('/html/body/div/ul/li[@id="id01"]/a/@href')
print(result)
输出

解释:
属性值的获取也是通过@ 来进行实现的,@href:获取href的属性值
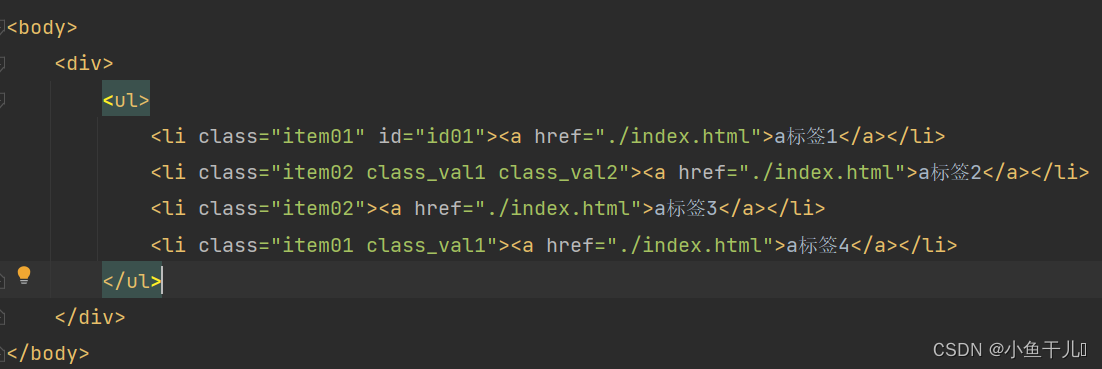
在实际的项目中会出现一个属性值有多个值的情况出现,例如class在实际项目中会有多个值的情况出现
获取class中含有class_val1的节点
# 这种方式是错误的,并不会找出对应的class中含有class_val1的节点
tree.xpath('/html/body/div/ul/li[@class="class_val1"]')
# 正确的做法 使用contains()函数
# 获取class中含有class_val1的节点
result = tree.xpath('/html/body/div/ul/li[contains(@class,"class_val1")]')
print(result)
输出:

解释:
contains()函数 获取指定属性中包含某一属性值的节点
使用方式contains(@属性,"属性值")
有时候我还需要根据多个属性来确定一个节点
找出li中 class中含有item01且id=id01 中a标签中的文本
result = tree.xpath('/html/body/div/ul/li[contains(@class,"item01") and @id="id01"]/a/text()')
print(result)

解释:
使用 and可以连接多个条件值
拓展类似的操作符还有
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| or | 或 | age=10 or age=20 | 如果age等于10或者等于20则返回true反正返回false |
| and | 与 | age>19 and age<21 | 如果age等于20则返回true,否则返回false |
| mod | 取余 | 5 mod 2 1 | |
| | | 取两个节点的集合 | //book | //cd | 返回所有拥有book和cd元素的节点集合 |
| + | 加 | 5+4 | 9 |
| - | 减 | 5-4 | 1 |
| * | 乘 | 5*4 | 20 |
| div | 除法 | 6 div 3 | 2 |
| = | 等于 | age=10 | true |
| != | 不等于 | age!=10 | true |
| < | 小于 | age<10 | true |
| <= | 小于或等于 | age<=10 | true |
| > | 大于 | age>10 | true |
| >= | 大于或等于 | age>=10 | true |
在有些时候我们在选择的时候可能匹配了多个节点,但是我们可能只需要其中的某些节点,xpath为我们提供了可以 根据索引进行取值的操作。
注意在xpath中索引从1开始,并不是以0开始
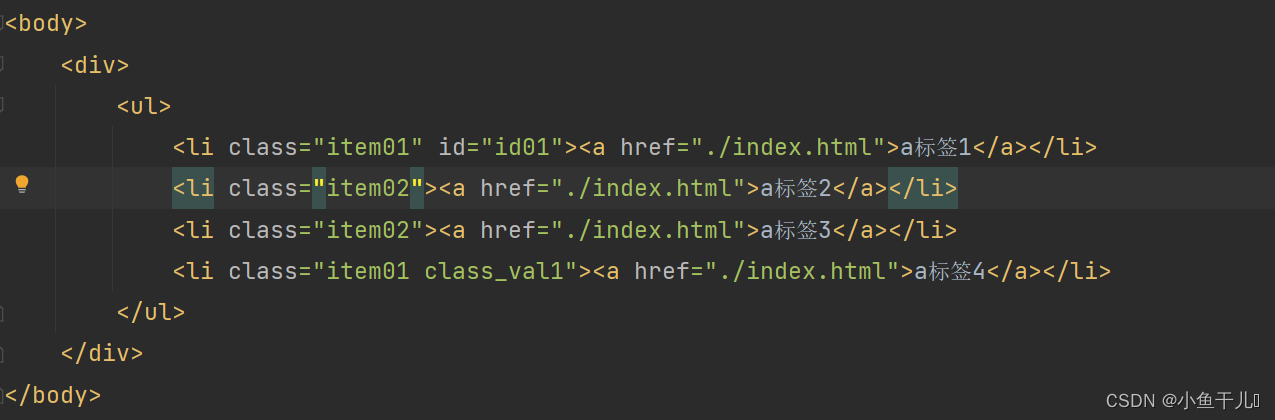
获取第一个li标签
获取前三个li标签
获取最后一个li标签
# 获取第一个`li`标签
result = tree.xpath('/html/body/div/ul/li[1]')
print(result)
# 获取前三个`li`标签
result2 = tree.xpath('/html/body/div/ul/li[position()<4]')
print(result2)
# 获取最后一个`li`标签
result3 = tree.xpath('/html/body/div/ul/li[last()]')
print(result3)
输出:

解释:
position() 返回当前正在被处理的节点的 index 位置
last() 返回所有匹配节点的最后一个的索引
轴可定义相对于当前节点的节点集。
(定义有点抽象,看完下面的实例就懂了)
获取li的所有的祖先节点
result = tree.xpath('/html/body/div/ul/li/ancestor::*')
print(result)
输出:

获取li祖先节点中的div
result = tree.xpath('/html/body/div/ul/li/ancestor::div')
print(result)
输出:

获取li节点的子孙元素
result = tree.xpath('/html/body/div/ul/li/child::*')
print(result)
获取li节点的子孙元素中a标签中href="./index.html"
result = tree.xpath('/html/body/div/ul/li/child::a[@href="./index.html"]')
print(result)
解释:
ancestor、child都称作轴 ancestor轴就是相对当前节点的所有祖先节点的集合,child轴就是相对当前节点的子孙节点的集合,而后面::后面跟着是对轴节点集合的操作 *代表匹配所有的节点 div 代表取节点集中的div节点,
另外还可以使用其他的筛选条件进行筛选child::a[@href="./index.html"]:选取子孙节点中a节点中href="./index.html"的节点,上面学习的筛选方式都可以在这里使用。
类似这样的轴还有很多
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
xpath轴的使用方式都是一样的,在实际中我们只需要根据自己的需求选择合适的轴。
关于lxml和xpath的教学大概就有这么多,这类教程很多用法都不便于讲解,这里只是提供一些用法,后续如果想熟练的使用xpath解析数据还需要勤加练习,结合自己的实际情况进行选择具体的xpath,
在使用一段时间后你可能会发现最常用的也就最基础的获取子节点、获取子孙节点、获取文本、获取属性值。这些也足够你解决你遇到的绝大部分问题,后面关于xpath轴的或许在实际中没等你想到就将问题解决了。但是我还是建议你学习,在我们看别人的代码的时候别人可能会用,我们平时可以不会写但是见到这样的代码的时候一定要认识。

我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun