声明:本文部分文章取自于
Java中关于二叉树详解_来学习的小张的博客-CSDN博客_java 二叉树原理
更多关于二叉树详情可以点击上面链接
目录
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 有一个特殊的节点,称为根节点,根节点没有前驱节点;
- 除根节点外,其余节点被分成
M(M > 0)个互不相交的集合T1、T2、......、Tm,其中每一个集合Ti (1 <= i<= m)又是一棵与树类似的子树。每棵子树的根节点有且只有一个前驱,可以有0个或多个后继;- 树是递归定义的。
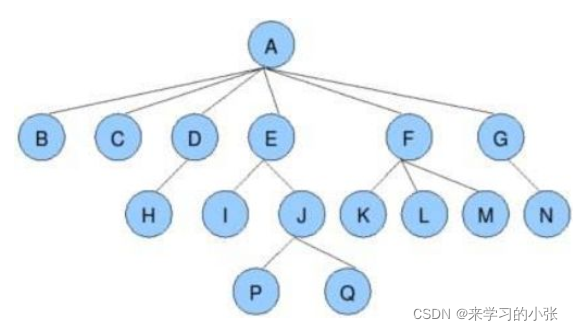
- 节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:
A的度为6;- 树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为
6;- 叶子节点或终端节点:度为
0的节点称为叶节点; 如上图:B、C、H、I…等节点为叶节点;- 双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点;
- 根结点:一棵树中,没有双亲结点的结点;如上图:A
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
以下概念仅做了解即可:
- 非终端节点或分支节点:度不为0的节点; 如上图:
D、E、F、G...等节点为分支节点;- 兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:
B、C是兄弟节点;- 堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:
H、I互为兄弟节点;- 节点的祖先:从根到该节点所经分支上的所有节点;如上图:
A是所有节点的祖先;- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙;
- 森林:由
m(m>=0)棵互不相交的树的集合称为森林。
使用前序、中序、后续来遍历二叉树
- 前序遍历:先输出父节点,再遍历左子树和右子树
- 中序遍历:先遍历左子树,再输出父节点,再遍历右子树
- 后序遍历:先遍历左子树,再遍历右子树,最后输出父节点
小结:看输出父节点的顺序,就确定是前序、中序还是后序。
分析二叉树的前序,中序,后序的遍历步骤:
1.创建一颗二叉树
2.前序遍历
3.中序遍历
4.后序遍历
5.前、中、后序遍历代码实现:
public class BinaryTreeDemo {
public static void main(String[] args) {
//先需要创建一颗二叉树
BinaryTree binaryTree=new BinaryTree();
//创建需要的结点
HeroNode root=new HeroNode(1,"宋江");
HeroNode node2=new HeroNode(2,"吴用");
HeroNode node3=new HeroNode(3,"卢俊义");
HeroNode node4=new HeroNode(4,"林冲");
HeroNode node5=new HeroNode(5,"武松");
HeroNode node6=new HeroNode(6,"鲁智深");
HeroNode node7=new HeroNode(7,"杨志");
//说明,我们先手动创建该二叉树,后面我们学习递归的方式创建而常数
root.setLeft(node2);
root.setRight(node3);
node2.setLeft(node4);
node2.setRight(node5);
node3.setLeft(node6);
node3.setRight(node7);
binaryTree.setRoot(root);
//测试:
System.out.println("前序遍历");//1,2,4,5,3,6,7
binaryTree.preOrder();
System.out.println("中序遍历");//4,2,5,1,6,3,7
binaryTree.infixOrder();
System.out.println("后序遍历");//4,5,2,6,7,3,1
binaryTree.postOrder();
}
}
//定义二叉树
class BinaryTree{
private HeroNode root;//根节点
public void setRoot(HeroNode root){
this.root=root;
}
//前序遍历
public void preOrder(){
if(this.root!=null){
this.root.preOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//后序遍历
public void infixOrder(){
if(this.root!=null){
this.root.infixOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//后序遍历
public void postOrder(){
if(this.root!=null){
this.root.postOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
}
//先创建HeroNode结点
class HeroNode{
private int no;
private String name;
private HeroNode left;//默认为null
private HeroNode right;//默认为null
public HeroNode(int no, String name) {
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode [no=" + no + ", name=" + name + "]";
}
//编写前序遍历的方法
public void preOrder(){
System.out.println(this);//先输出父结点(谁调用这个方法,谁就是this)
//递归向左子树前序遍历
if(this.left!=null){
this.left.preOrder();
}
//递归向右子树前序遍历
if(this.right!=null){
this.right.preOrder();
}
}
//编写中序遍历的方法
public void infixOrder(){
//递归向左子树中序遍历
if(this.left!=null){
this.left.infixOrder();
}
//输出父结点
System.out.println(this);
//递归向右子树中序遍历
if(this.right!=null){
this.right.infixOrder();
}
}
//编写后序遍历的方法
public void postOrder(){
//递归向左子树后序遍历
if(this.left!=null){
this.left.postOrder();
}
//递归向右子树后序遍历
if(this.right!=null){
this.right.postOrder();
}
//输出父结点
System.out.println(this);
}
}目的:使用前序、中序、后序的方式来查询指定的节点。
前序查找思路:
中序查找思路:
后序查找思路:
查找指定节点的部分代码实现:
//编写前序查找的方法
public HeroNode preSearch(int no){
//先判断当前节点是否符合
if(this.no==no){
return this;
}
HeroNode resNode=null;
//向左递归
if(this.left!=null){
resNode=this.left.preSearch(no);
}
//向右递归(判断左递归得到的节点是否为空,如果为空,则进行右递归)
if(resNode==null&&this.right!=null){
resNode=this.right.preSearch(no);
}
return resNode;//如果最终还是没有找到,则返回null
}
//编写中序查找的方法
public HeroNode infixSearch(int no){
HeroNode resNode=null;
if(this.left!=null){
resNode=this.left.infixSearch(no);
}
if(this.no==no){
return this;
}
if(this.right!=null&&resNode==null){//左边没有找到,找右边
resNode=this.right.infixSearch(no);
}
return resNode;//不管有没有找到,都返回resNode
}
//编写后序查找的方法
public HeroNode postSearch(int no){
HeroNode resNode=null;
if(this.left!=null){
resNode=this.left.postSearch(no);
}
if(this.right!=null&&resNode==null){
resNode=this.right.postSearch(no);
}
if(this.no==no){
return this;
}
return resNode;
}规定:如果要删除的节点是叶子节点,则直接删除,如果是非叶子节点,则删除该子树。
思路:
首先先处理:
考虑如果树是空树root,如果只有一个root节点,则等价将二叉树置空。
如果不是,则进行下面步骤:
节点删除的代码实现:
//二叉树部分:删除节点
public void deleteNode(int no){
if(root!=null){
//如果只有一个root节点,这里立即判断root是不是要删除节点
if(root.getNo()==no){
root=null;
}else {
//递归删除
root.deleteNode(no);
}
}else {
System.out.println("二叉树为空,删除失败");
}
}
//链表部分:
//递归删除节点
public void deleteNode(int no){
//判断当前节点的左子节点
if(this.left!=null&&this.left.no==no){
this.left=null;
return;
}
//判断当前节点的右子节点
if(this.right!=null&&this.right.no==no){
this.right=null;
return;
}
//左子树递归删除
if(this.left!=null){
this.left.deleteNode(no);
}
//右子树递归删除
if(this.right!=null){
this.right.deleteNode(no);
}
}基本说明:从数据存储来啊看,数组存储方式和树的存储方式可以相互转化,即数组可以转换成树,也可以转换成数组。
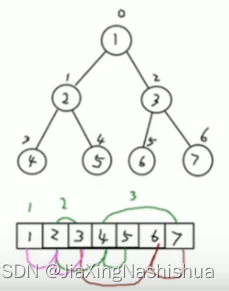
要求:
(1)图中的二叉树的节点,要求以数组的方式来存放arr【1,2,3,4,5,6,7】
(2)要求在遍历数组arr时,仍然可以以前序遍历、中序遍历和后序遍历的范围广是完成节点的遍历。
思路:
提示:(可以自己对着上图验证一下)
顺序存储二叉树的代码实现:
public class ArrayBinaryTreeDemo {
public static void main(String[] args) {
int[] arr={1,2,3,4,5,6,7};
ArrayBinaryTree arrayBinaryTree = new ArrayBinaryTree(arr);
arrayBinaryTree.preOrder(); //1,2,4,5,3,6,7
}
}
//编写一个ArrayBinaryTree,实现顺序存储二叉树遍历
class ArrayBinaryTree{
private int[] arr;//存储数据节点的数组
public ArrayBinaryTree(int[] arr){
this.arr=arr;
}
//编写一个方法,完成顺序存储二叉树的前序遍历
//重载preOrder
public void preOrder(){
this.preOrder(0);
}
public void preOrder(int index){
//如果数组为空,或arr.length=0
if(arr==null || arr.length==0){
System.out.println("数组为空,不能按照二叉树的前序遍历");
}
//输出当前这个元素
System.out.println(arr[index]);
//向左递归遍历
if((index*2+1)<arr.length){
preOrder(2*index+1);
}
//向右递归遍历
if((index*2+2)<arr.length){
preOrder(2*index+2);
}
}
}
问题分析:
使用场景:
线索二叉树基本介绍:
思路分析:
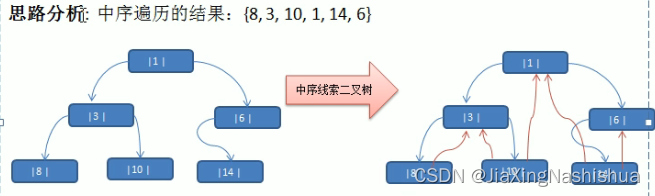
说明:当线索化二叉树后,Node节点的属性left和right,有如下情况:
(1)left指向的是左子树,也可能是指向的前驱节点,比如 1 节点left指向的左子树,而 10 节点的left指向的就是前驱节点。
(2)rigth指向的是右子树,也可能是指向后继节点,比如 1 节点right指向的是右子树,而 10 节点的right指向的是后继节点。
public class ThreadedBinaryTreeDemo {
/*
中序线索化二叉树
*/
public static void main(String[] args) {
HeroNode root=new HeroNode(1,"tom");
HeroNode node2=new HeroNode(3,"jack");
HeroNode node3=new HeroNode(6,"smith");
HeroNode node4=new HeroNode(8,"mary");
HeroNode node5=new HeroNode(10,"king");
HeroNode node6=new HeroNode(14,"dim");
//二叉树,后面我们要递归创建,现在简单处理使用手动创建
root.setLeft(node2);
root.setRight(node3);
node2.setLeft(node4);
node2.setRight(node5);
node3.setLeft(node6);
BinaryTree binaryTree = new BinaryTree();
binaryTree.setRoot(root);
binaryTree.threadedNodes();
//测试:
HeroNode leftNode = node5.getLeft();
HeroNode rightNode = node5.getRight();
System.out.println("10 节点的前驱节点:"+leftNode);
System.out.println("10 节点的后继节点:"+rightNode);
}
}
class BinaryTree{
private HeroNode root;//根节点
//为了实现线索化,需要创建要给指向当前节点的前驱节点的指针
//在递归进行线索化时,pre总是保留前一个节点
private HeroNode pre=null;
public void setRoot(HeroNode root){
this.root=root;
}
//重载threadedNodes方法
public void threadedNodes(){
this.threadedNodes(root);
}
//编写对二叉树进行中序线索化的方法
/**
*
* @param node:就是当前需要线索化的节点
*/
public void threadedNodes(HeroNode node){
//如果node==null,不能线索化
if(node==null){
return;
}
//(一)先线索化左子树
threadedNodes(node.getLeft());
//(二)线索化当前节点
//处理当前节点的前驱节点
//以8节点来理解
//8节点的.left=null,8节点的.leftType=1
if(node.getLeft()==null){
//让当前节点的左指针指向前驱节点
node.setLeft(pre);
//修改当前节点的左指针的类型,指向前驱节点
node.setLeftType(1);
}
//处理后继节点
if(pre!=null&&pre.getRight()==null){
//让前驱节点的右指针指向当前节点
pre.setRight(node);
//修改前驱节点的右指针类型
pre.setRightType(1);
}
//!!! 每处理一个节点后,让当前节点是下一个节点的前驱节点
pre=node;
//(三)再线索化右子树
threadedNodes(node.getRight());
}
}
//先创建HeroNode结点
class HeroNode{
private int no;
private String name;
private HeroNode left;//默认为null
private HeroNode right;//默认为null
//说明
//1.如果leftType==0表示指向的是左子树,1则表示指向前驱节点
//2.如果rightType==0表示指向是右子树,1则表示指向后继节点
private int leftType;
private int rightType;
public HeroNode(int no, String name) {
this.no = no;
this.name = name;
}
public int getLeftType() {
return leftType;
}
public void setLeftType(int leftType) {
this.leftType = leftType;
}
public int getRightType() {
return rightType;
}
public void setRightType(int rightType) {
this.rightType = rightType;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode [no=" + no + ", name=" + name + "]";
}
}遍历线索化二叉树:
说明:对前面的中序线索化的二叉树,进行遍历
分析:因为线索化后,各个节点指向有变化,因此原来的遍历方式不能使用,这是需要使用新的方式遍历线索化二叉树,各个节点开头通过线型方式遍历,因此无需使用递归方式,这样也提高了遍历的效率。遍历的次序应当和中序遍历保持一致。
代码实现:
//遍历线索化二叉树
public void threadedList(){
//定义一个变量,存储当前遍历的节点,从root开始
HeroNode node=root;
while(node!=null){
//循环的找到leftType==1的节点,第一个找到就是8节点
//后面随着遍历而变化,因为当leftType==1是,说明该节点按照线索化处理后的有效节点
while(node.getRightType()==0){
node=node.getLeft();
}
//打印当前这个节点
System.out.println(node);
//如果当前节点的右指针指向的是后继节点,就一直输出
while (node.getRightType()==1){
//获取到当前节点的后继节点
node=node.getRight();
System.out.println(node);
}
//替换这个遍历的节点
node=node.getRight();
}
}
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO