一般情况下,我们都是使用散点图进行聚类可视化,但是某些的聚类算法可视化时散点图并不理想,所以在这篇文章中,我们介绍如何使用树状图(Dendrograms)对我们的聚类结果进行可视化。
树状图是显示对象、组或变量之间的层次关系的图表。树状图由在节点或簇处连接的分支组成,它们代表具有相似特征的观察组。分支的高度或节点之间的距离表示组之间的不同或相似程度。也就是说分支越长或节点之间的距离越大,组就越不相似。分支越短或节点之间的距离越小,组越相似。
树状图对于可视化复杂的数据结构和识别具有相似特征的数据子组或簇很有用。它们通常用于生物学、遗传学、生态学、社会科学和其他可以根据相似性或相关性对数据进行分组的领域。
背景知识:
“树状图”一词来自希腊语“dendron”(树)和“gramma”(绘图)。1901年,英国数学家和统计学家卡尔皮尔逊用树状图来显示不同植物种类之间的关系。他称这个图为“聚类图”。这可以被认为是树状图的首次使用。
我们将使用几家公司的真实股价来进行聚类。为了方便获取,所以使用 Alpha Vantage 提供的免费 API 来收集数据。Alpha Vantage同时提供免费 API 和高级 API,通过API访问需要密钥,请参考他的网站。
import pandas as pd
import requests
companies={'Apple':'AAPL','Amazon':'AMZN','Facebook':'META','Tesla':'TSLA','Alphabet (Google)':'GOOGL','Shell':'SHEL','Suncor Energy':'SU',
'Exxon Mobil Corp':'XOM','Lululemon':'LULU','Walmart':'WMT','Carters':'CRI','Childrens Place':'PLCE','TJX Companies':'TJX',
'Victorias Secret':'VSCO','MACYs':'M','Wayfair':'W','Dollar Tree':'DLTR','CVS Caremark':'CVS','Walgreen':'WBA','Curaleaf':'CURLF'}
科技、零售、石油和天然气以及其他行业中挑选了 20 家公司。
import time
all_data={}
for key,value in companies.items():
# Replace YOUR_API_KEY with your Alpha Vantage API key
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={value}&apikey=<YOUR_API_KEY>&outputsize=full'
response = requests.get(url)
data = response.json()
time.sleep(15)
if 'Time Series (Daily)' in data and data['Time Series (Daily)']:
df = pd.DataFrame.from_dict(data['Time Series (Daily)'], orient='index')
print(f'Received data for {key}')
else:
print("Time series data is empty or not available.")
df.rename(columns = {'1. open':key}, inplace = True)
all_data[key]=df[key]
在上面的代码在 API 调用之间设置了 15 秒的暂停,这样可以保证不会因为太频繁被封掉。
# find common dates among all data frames
common_dates = None
for df_key, df in all_data.items():
if common_dates is None:
common_dates = set(df.index)
else:
common_dates = common_dates.intersection(df.index)
common_dates = sorted(list(common_dates))
# create new data frame with common dates as index
df_combined = pd.DataFrame(index=common_dates)
# reindex each data frame with common dates and concatenate horizontally
for df_key, df in all_data.items():
df_combined = pd.concat([df_combined, df.reindex(common_dates)], axis=1)
将上面的数据整合成我们需要的DF,下面就可以直接使用了
层次聚类(Hierarchical clustering)是一种用于机器学习和数据分析的聚类算法。它使用嵌套簇的层次结构,根据相似性将相似对象分组到簇中。该算法可以是聚集性的可以从单个对象开始并将它们合并成簇,也可以是分裂的,从一个大簇开始并递归地将其分成较小的簇。
需要注意的是并非所有聚类方法都是层次聚类方法,只能在少数聚类算法上使用树状图。
聚类算法我们将使用 scipy 模块中提供的层次聚类。
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform top-down clustering
clustering = sch.linkage(dist_mat, method='complete')
cuts = sch.cut_tree(clustering, n_clusters=[3, 4])
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Top-Down Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()
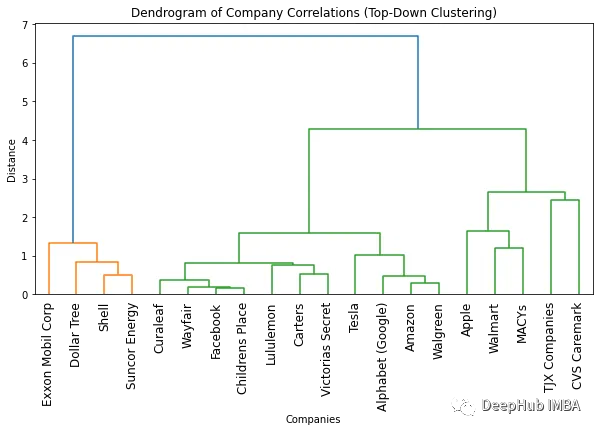
找到最佳簇数的最简单方法是查看生成的树状图中使用的颜色数。最佳簇的数量比颜色的数量少一个就可以了。所以根据上面这个树状图,最佳聚类的数量是两个。
另一种找到最佳簇数的方法是识别簇间距离突然变化的点。这称为“拐点”或“肘点”,可用于确定最能捕捉数据变化的聚类数量。上面图中我们可以看到,不同数量的簇之间的最大距离变化发生在 1 和 2 个簇之间。因此,再一次说明最佳簇数是两个。
使用树状图的一个优点是可以通过查看树状图将对象聚类到任意数量的簇中。例如,需要找到两个聚类,可以查看树状图上最顶部的垂直线并决定聚类。比如在这个例子中,如果需要两个簇,那么第一个簇中有四家公司,第二个集群中有 16 个公司。如果我们需要三个簇就可以将第二个簇进一步拆分为 11 个和 5 个公司。如果需要的更多可以依次类推。
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform bottom-up clustering
clustering = sch.linkage(dist_mat, method='ward')
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Bottom-Up Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()
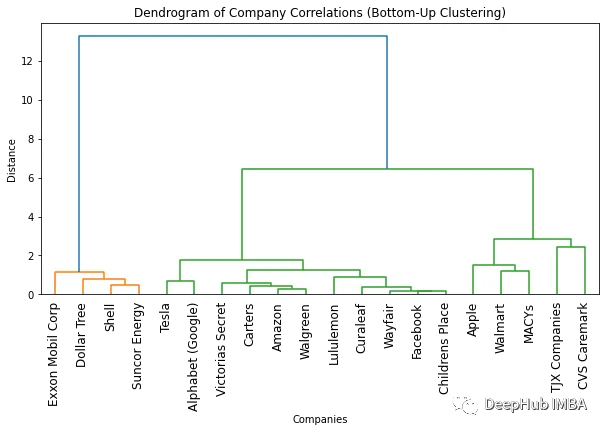
我们为自下而上的聚类获得的树状图类似于自上而下的聚类。最佳簇数仍然是两个(基于颜色数和“拐点”方法)。但是如果我们需要更多的集群,就会观察到一些细微的差异。这也很正常,因为使用的方法不一样,导致结果会有一些细微的差异。
树状图是可视化复杂数据结构和识别具有相似特征的数据子组或簇的有用工具。在本文中,我们使用层次聚类方法来演示如何创建树状图以及如何确定最佳聚类数。对于我们的数据树状图有助于理解不同公司之间的关系,但它们也可以用于其他各种领域,以理解数据的层次结构。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po