2012年,加拿大多伦多大学的Hinton教授带领他的两个学生Alex和Ilya一起用AlexNet撞开了深度学习的大门,从此人类走入了深度学习时代。
2015年,这个第二作者80后Ilya Sutskever参与创建了openai公司。现在Ilya是openai的首席科学家,带领工程师研发出了可能再次改变世界的chatgpt.

上图中,右面的就是图灵奖获得者,深度学习之父Hinton大牛。中间是AlexNet的第一作者Alex, 左边的就是Ilya Sutskever.
10多年间,从DNN,CNN,RNN为代表的第一代深度神经网络,到以深度Q学习为代表的深度强化学习,再到以Transformer技术为基础以BERT为开创的大规模预训练模型。以及针对大规律预训练模型所需要的人工引导和数据标注等技术支持的chatgpt。
深度学习呈现出理论的东西越来越多,但是应用的难度却越来越低的变化。
深度学习的工具发展主要有以下4个阶段:
此外,还有一些专用工具,比如推理性能优化的AI编译器技术如TVM,比如LLVM的MLIR等。比如支持深度学习后端的各种GPGPU技术,比如OpenGL,OpenCL,Vulkan,WebGPU。比如支持CPU上进行深度学习计算的OpenMP和XLA线性计算库,等等。
人工智能有三要素:算法、算力和数据。
在大规模预训练模型的时候,算法在核心上变化不大,都是堆积了很多层的Transformer模型。
但是其难点在于对于算力需求越来越庞大,而且随着数据的增加,所生成的数据的质量的保证也是重要的问题。
所以目前的主线就有两条:一条是如何堆积更多的算力,用更大的模型去进行突破,比如gpt3和gpt4就都是大力出奇迹的成果;另外一条是如何提升数据的准确性,并不是说模型大了就自然正确了。目前很多模型都很大,但是效果好的只有openai一家,就说明了这第二条主线的重要性。
另外,光堆算力对于更多人参与研究是不利的,如何实现用较小的算力,实现更好的效果,也是热门的主题。
所以,这个时候的教程,如果还从PyTorch实现MNIST入手的话,离使用chatgpt这样的突破性成果之间的gap就太大了。我们的教程就从chatgpt开始。
大规模预训练模型的是为了解决自然语言处理NLP问题而产生的。比如机器翻译就是自然语言处理中的一个重要问题。
用神经网络来处理自然语言,早在深度学习出现之前就有了。那时候还没有深度学习,神经网络还存在着梯度爆炸等困难。
1997年,循环神经网络的重要模型,长短时记忆网络LSTM就被研究出来了。
2014年,另外一种改进的循环神经网络-门控循环单元LRU也被发明出来。
2014年,Ilya Sutskever作为第一作者发明了seq2seq模型,基本上解决了使用循环神经网络进行机器翻译的问题。
也是在2014年,为了提升RNN的效果,《Neural Machine Translation by Jointly Learning to Align and Translate》论文开始引入了注意力机制。
2017年,Google人民发现,注意力机制并不一定要依附于循环神经网络,只用注意力模块自己就可以了。他们提出了只用注意力编码器和解码器的结构,就是著名的Transformer模型。这篇论文叫做《Attention is all you need》,不用RNN啦,Attention自己就够用了。
2018年,Google人民研究出了Transformer模型的真正组合方法,正式提出了预训练模型这个概念。从此又开始了一个新的时代。
同年,openai推出了第一代的gpt,论文名叫《Improving language understanding by generative pre-training》。gpt的名称就来自generative pre-training,生成立的预训练模型。
真正开始传奇故事的是从gpt2开始的。openai的大神们发现,通过预训练一个大型语言模型,在无监督的情况下学习多个任务,就可以在很多任务上取得另人惊讶的效果。
gpt2引入了两个重要的东西:一个是零样本学习,就是一个大模型只要训练得足够大,就可以对于很多未知的任务有很强的泛化性,这正是机器学习追求的终极梦想;另一个是微调fine-tune,就是可以站在巨人的肩膀上,基于自己的少量数据的加强训练,就可以让gpt2和自己独特的业务结合起来。
这一下子就点燃了各种大模型,大家纷纷沿着这条路前进,参数不断翻新。从BERT到gpt2这些模型也都是开源的,这时诞生了Hugging face库,将各种预训练模型集成在一个框架内。
gpt2的论文叫做《Language Models are Unsupervised Multitask Learners》,多任务同时也引发多模态的支持,除了文本之外,各大模型对于代码、图像之类的也不放过。这一传统也沿用至今。
微调虽然已经相对容易了,但是openai人民仍不满足。他们认为,人类只用很少的几个样例就能学会的东西,为什么微调需要提供大量的数据才可以做到。最终他们发现,gpt2虽然可以支持多任务学习,但是还需要很多微调的原因是,模型还不够大。于是他们训练了1750亿参数的GPT-3.
GPT-3开始,openai决定不开源了。再想像用gpt2一样通过hugging face库调用没办法了,从此进入了编程的第三范式,只能调用openai的API。
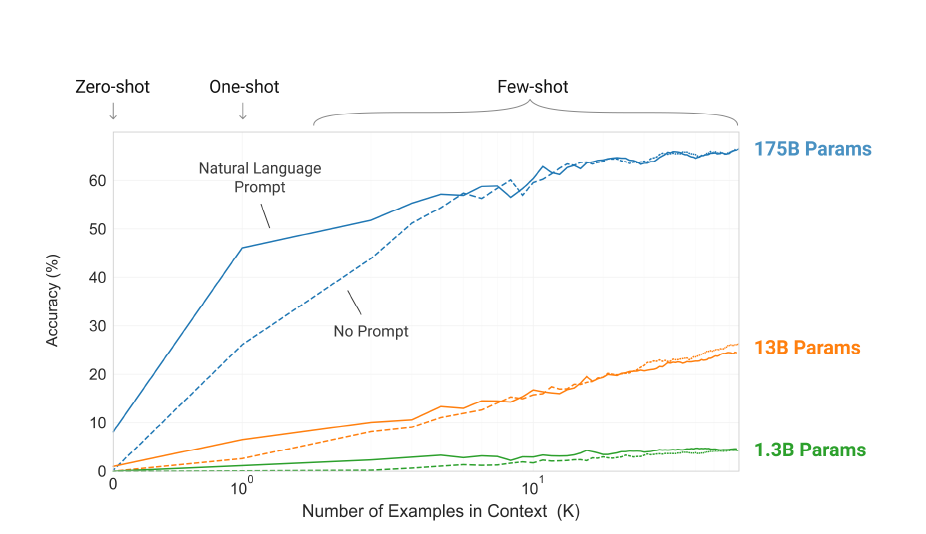
不过,正如gpt3的论文名字《Language Models are Few-Shot Learners》字面所说的,因为gpt3是一个支持few-shot,也就是少样本的学习。所以,不用微调,只用少量的提示就可以让gpt3学习。这就是在现在发挥光大形成一个学科的prompt engineer的“提示工程”或者叫“引导工程”。
目前有一种鄙视链,就是觉得用PyTorch等库自己搭建才是技术,微调不是技术,引导工程更不是技术。我不知道他们是否读过论文原文。
深度学习从一开始就没追求成功理论的严谨性,而是靠易用性流行起来的。
可解释性当然是好的,我们也要学习Anthropic等机构的成果。但是这跟我们搞好引导工程和微调并不矛盾。
上面一节我们看到,这上面4句话是Transformer, gpt, gpt2和gpt3的论文的标题名。他们连在一起就是用无监督的大规模预训练的模型来实现各种任务的总纲。
总结起来,就是大力出奇迹。当模型足够大,就能涌现出少样本学习的强大能力。
这在GPT-3得到了很好的验证。但是,最终火起来的是chatgpt,而非强调few-shot的GPT3。它缺少什么呢?我们看一个论文题目就知道了:《Training language models to follow instructions with human feedback》。
没错,无监督的大规模预训练模型还不行,还需要人类的反馈。这也是chatgpt现目前为止还领先不少参数更多的大模型的原因。比如13亿参数的chatgpt的效果就可以强于1750亿参数的gpt3.
像gpt3这么强大的模型,哪怕是像更强的gpt4,虽然有较强的少样本学习的能力,但是它们都会生成一些编造的事实,生成一些有偏见的事实,甚至是不知所云的或者是有害的信息。
比如,有篇叫做《On the Dangers of Stochastic Parrots: Can Language Models be too Big?》题目就直接质疑,语言模型不能做太大。否则有伦理问题、法律问题、社会公平问题,甚至引发大量碳排放影响环境等。
许多研究人员还制作了有偏见的或者有害的数据集来供模型评估自己的效果,比如Realtoxicityprompts数据集。
而如何通过人类反馈来改进语言模型,也并不是openai的原创,而是借用了强化学习的思想。这种技术被称为reinforcement learning from human feedback - RLHF,人类反馈强化学习。
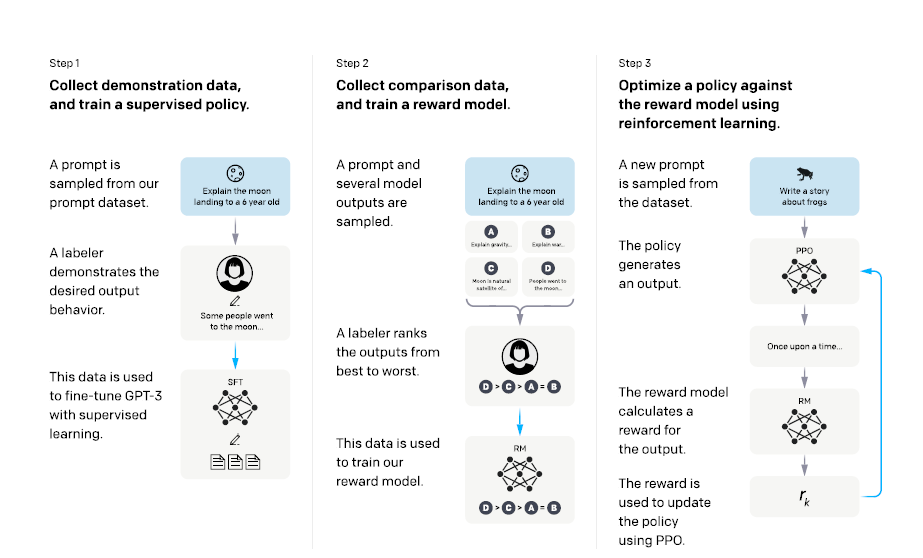
RLHF这种技术最初是用在玩游戏的强化学习中。如果用深度强化学习做过Atari游戏的同学都会知道,很多游戏太复杂了,想让算法找到成功的路径需要花费大量时间,甚至经常退化找不到。这时候,如果有玩通关过的人来指导一下,就会节省大量的试错时间。
但是这也是个技术活,如果让哪一种情况下人都指导,那人也受不了。所以要将人类的反馈数据也加工成模型。后来,这种技术在自然语言处理中也遍地开花。
经过人类反馈强化学习的方法进行微调之后,chatgpt竟然惊奇地发现,它对于代码的总结能力、对回答代码问题的能力和支持多种编程语言的能力比gpt3有显著的提高。这个结果跨界打击了Codex等专门为编程语言研发的模型。
不过,不管是论文还是实测结果都证明了,chatgpt仍然会犯简单低级的错误,需要在理论和实践上都进一步的改进。
从目前看来,chatgpt和gpt4是领先的。但是,其它的方向我们也需要保持关注和敏感度。比如更小算力的方向是否可能有突破,或者是下一步的线索是否已经在悄悄地成长中。
开源的解决方案仍然是一个值得关注的方向。 抱openai的大腿并且搞好引志工程是目前是最现实的解决方案,但是我们永远不能忽视开源的力量。哪怕开源的走错了方向,这个错误也更容易被学习到。
以Meta AI推出的LLaMA为例,他们的关注点不是人类反馈强化学习,而是坚持由《Scaling laws for neural language models》一文提出的缩放定律:
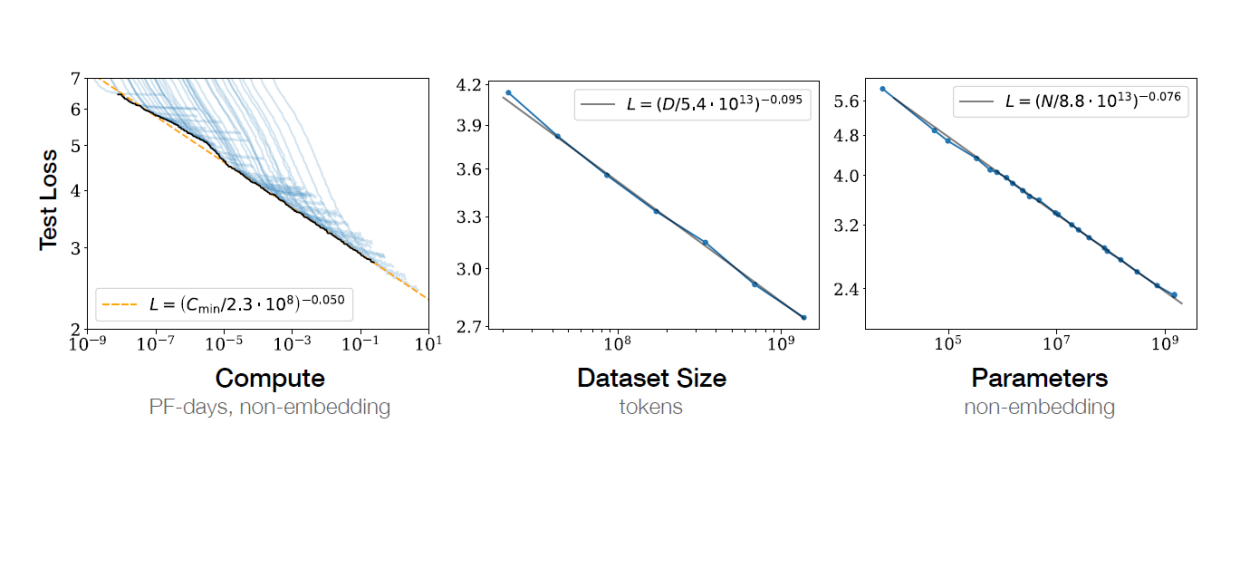
也就是说,沿着缩放定律的方向,few-shot的能力就还会进一步提升。这一过程,只与数据量、计算量和参数量三者有关。
而据Deepmind的一项研究《Training Compute-Optimal Large Language Models》,模型和训练数据量等比例缩放才会获取更好的训练效果。现有的大模型参数加上去了,但是数据量没有跟上,所以浪费了资源。
所以LLaMA也尝试依据Deepmind的这项研究,通过增加训练数据来对较小的模型进行训练,可以得到比更大模型更好的效果。
这里不得不再八卦一下,缩放定律这篇论文,恰恰是也是来自研究gpt3的openai团队。团队的leader是Dario Amodei。

在gpt3面临选择的关头,Dario Amodei对于gpt3这样的黑盒也很不满,他认为能够解释清楚黑盒比做更大的gpt4更重要,于是他带领很多openai同事创建了Anthropic。无论最终结果如何,Anthropic所代表的思路是值得我们一直关注的。
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/