简历看到吐是什么感觉?
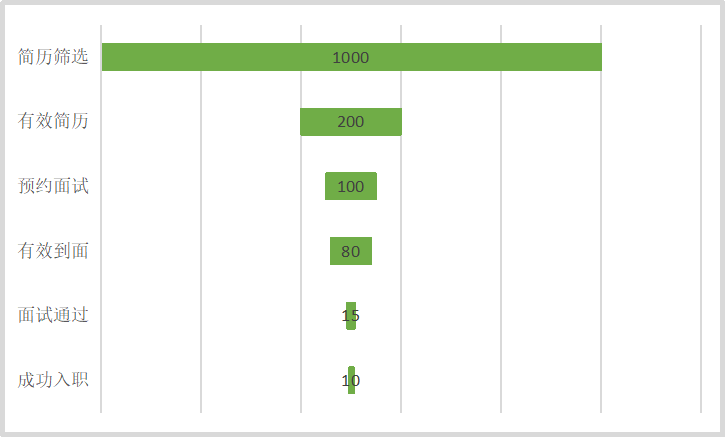
业务增长,伴随着人员规模的扩张,由于需求比较紧急,两个月的时间筛选了近千份简历。
粗略测算了一下,每个环节的转化率基本在10-20%之间。
不知道在HR眼中,这个转化率是高是低了,直接上漏斗图:
简历来源一般有以下渠道:
猎头公司、人事推荐、自己检索、朋友推荐、自荐等。
常用第三方平台:
BOSS/猎聘/51Job/智联/拉勾/脉脉等
从上述数据看,简历筛选阶段我们大概过滤掉了80%的简历,有哪些原因呢?
1、学历
不同岗位的起始要求不一样,一般统招本科起,本科以下、非统招等条件可能会筛选掉一部分。
另外也会有一些学历造假的简历,学校查不到,官网不带edu,学校网站提供学历查询入口等。
2. 专业
最好是与岗位相关的专业,不相关的一般是转行到此行业,比较容易筛选掉。
3、年龄/性别/婚姻情况
隐性要求,IT行业一般35岁是个坎。
4、户籍与居住地
户籍:不得不说,一方水土养一方人,性格还是很有地域特色的。
现居住地:主要考虑通勤时间。
5、薪资
个人期望与公司支出的匹配度
6、稳定性
跳槽频率,离职动机等。
7、自我认知
对岗位对个人的认知与定位。
8、上家公司信息
了解上家公司业务方向,另外一些明显就是外包性质的公司会过滤掉。
1、技术
使用的技术与招聘岗位的匹配度,是否涉及必须的一些核心能力。
比如工具应用、专项测试技术等。
2、业务
是否有同行业或相关行业经验,偏差较大的话,后期转化成本也较大。
特别是一些跨度较大的,比如软件测试与硬件测的差异。
3、个人成长
学习能力,岗位晋升,资格证书,工作质量,同事评价,沟通协作。
1、简历整洁性
相比于word,pdf版的简历的视觉更好些,word经常会有一些兼容问题,导致排版异常不直观。
2、细心程度
错别字、语言表达不顺畅、英语专有名字首字母未大写等。
3、时间基线
工作成长是否符合客观规律。
从简历筛选到成功入职,中间有很长一段路,如果想走得更远,就要用心准备,不做无准备的面试。
另外,与能力相比,诚实更重要,所以,一定不要造假:
公司能够接受你沟通表达、工作能力有瑕疵,但对弄虚作假,所有公司都是零容忍。
ChatGPT掀起了AI股历史上最疯狂的一轮市值狂飙。自春节后至今,ChatGPT概念股开始了暴走模式,短短半月时间,海天瑞声、开普云等ChatGPT概念股市值累计增加了近1400亿。如此的爆炸效应,得益于ChatGPT所展现出商业化落地的巨大潜力。要知道,在此之前,无论是十年AI投入超千亿的百度,还是困在硬件化里的AI四小龙,都在重复着AI商业化难落地的故事。ChatGPT的出现,让AI从生产力的赋能者直接成为一种创造生产力的工具。随着订阅模式的推出,ChatGPT已经成为第一个以AI技术为核心直接变现的消费者应用。本文持有以下核心观点:1、ChatGPT是AI技术迭代的受益者。过去受限技术
我正在尝试使用ProjectEuler中的Ruby解决数学问题。Here是我尝试的第一个:Ifwelistallthenaturalnumbersbelow10thataremultiplesof3or5,weget3,5,6and9.Thesumofthesemultiplesis23.Findthesumofallthemultiplesof3or5below1000.请帮助我改进我的代码。total=0(0...1000).eachdo|i|total+=iif(i%3==0||i%5==0)endputstotal 最佳答案
前言以下为网络安全各个方向涉及的面试题,星数越多代表问题出现的几率越大,祝各位都能找到满意的工作。注:本套面试题,已整理成pdf文档,但内容还在持续更新中,因为无论如何都不可能覆盖所有的面试问题,更多的还是希望由点达面,查漏补缺。一、渗透测试方向:如何绕过CDN找到真实IP,请列举五种方法(★★★)redis未授权访问如何利用,利用的前提条件是?(★★★)mysql提权方式有哪些?利用条件是什么?(★)windows+mysql,存在sql注入,但是机器无外网权限,可以利用吗?(★)常用的信息收集手段有哪些,除去路径扫描,子域名爆破等常见手段,有什么猥琐的方法收集企业信息?(★★)SRC挖掘与
我有两个包含用户ID的数组,我想检查其中的不同项目。arr1=[123,456,789];arr2=[123,456,789,098];问题是:这些数组可以有10或2000万个项目。我正在尝试使用underscore.difference()但需要10分钟才能完成。有没有更快的方法来做到这一点? 最佳答案 如何将数组转换为对象以降低排序的复杂性:vararr1=[123,456,789],arr2=[123,456,789,098];functiontoObject(arr){returnarr.reduce(function(o,
我正在构建一个销售事件门票的系统。目前大约有1000个不同的座位可供游客选择。也许有一天它会达到5000。现在我有一个div用于每个位置,然后是一些jQuery以使用ajax保留位置。所以这意味着我有大约1000个div,更令人担忧的是我的jQuery选择器在每个div上设置了一个点击事件。在这方面有更好的方法吗?我想在按下div时触发ajax,而不是重新加载页面。 最佳答案 使用.delegate():$("#container").delegate(".child","click",function(){alert("Click
我在下面使用以下函数来确定用户在记分牌中的排名。Parse.Cloud.define("getUserGlobalRank",function(request,response){varusernameString=request.params.username;varscoreAmount=request.params.score;varglobalRankQuery=newParse.Query("scoreDB");globalRankQuery.greaterThanOrEqualTo("score",scoreAmount);globalRankQuery.descendin
在将htmlblock插入dom之前,我对在dom外构建htmlblock很感兴趣,因此我使用dynatrace进行了一些测试。我使用了bobince的方法:IsthereanywaytofindanelementinadocumentFragment?我发现它慢了将近1000倍(在IE7中),这让我很惊讶。由于功能非常基础,我想知道sizzle等引擎使用的策略。我想知道是否有一些更有效的方法来进行基于上下文的节点选择? 最佳答案 框架选择器引擎通常是右手优先评估的,所以我希望上下文ID选择器document.getElementB
我正在尝试通过collectionFS中的gm进行一些图像处理,因为我需要读取一个流并将其写回同一个文件,我必须使用一个临时文件-如下所示。我想检查图像是否大于1000像素。在这种情况下,它的大小应重新调整为1000像素。不幸的是,这不起作用,因为我收到错误TypeError:Object[objectObject]hasnomethod'pipe'和Error:gm().stream()orgm().write()带有不可读流。varfs=Npm.require('fs'),file=Images.findOne({_id:fileId}),read=file.createReadS
这个问题在这里已经有了答案:Howtosortanarrayofintegerscorrectly(32个答案)关闭7年前。我有以下问题,我的函数接受一个包含4个数组的数组,每个元素都是一个数字。这些函数必须返回每个数组的最大元素。functionlargestOfFour(arr){varlargest=[];for(vari=0;i结果:Array[5,27,39,857]显然它有效,但是当我尝试使用最后一个数组[1000,1001,857,1],其中1000和1001大于857我得到857。为什么会这样?
我正在努力完成三件事-我想缩短大数字并添加K/M/B后缀我希望能够强制小数位数我希望能够强制将数千表示为百万的小数只需缩短,四舍五入到小数点后两位1200000---->>>120万1248000---->>>125万248000---->>>248K缩短,强制保留2位小数1200000---->>>120万1248000---->>>125万248000---->>>248.00K缩短,强制小数点后3位,强制几千到几百万1200000---->>>1.200M1248000---->>>1.248M248000---->>>0.248M我有一个javascript函数,我发现它可以做