文章目录
随着微信防爬技术的再度升级,之前Python+mitmproxy利用网络代理这种中间人的方式已经爬取不到微信小程序的数据了。俗话世上无难事只要肯放弃,本以为已经无计可施了,在某天不经意间发现一个神器依然可以抓到小程序的包,于是开始研究如何实现自动爬取。
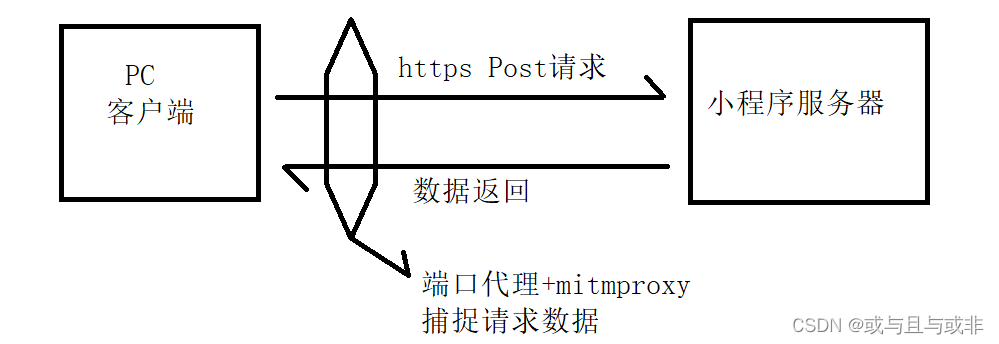
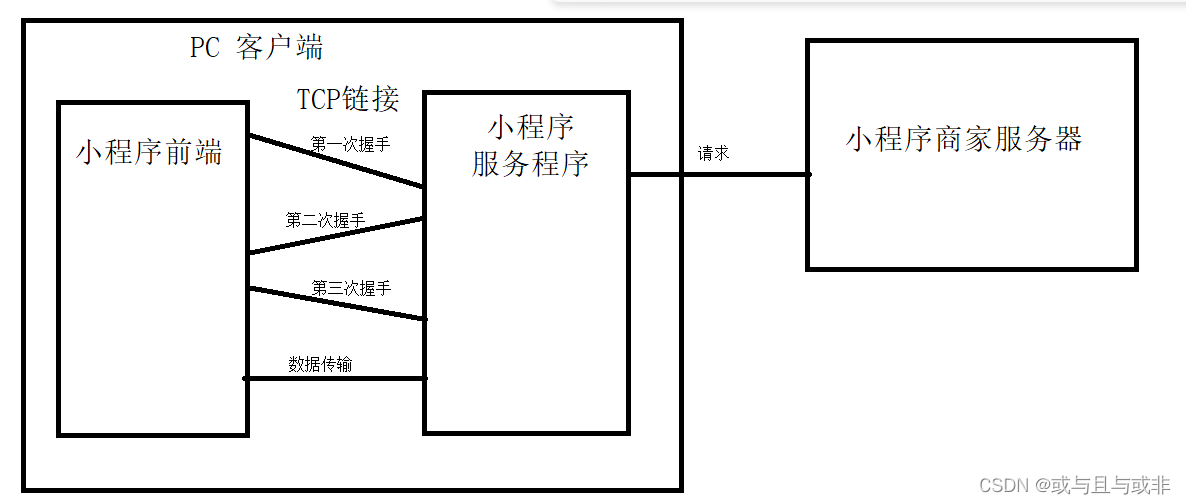
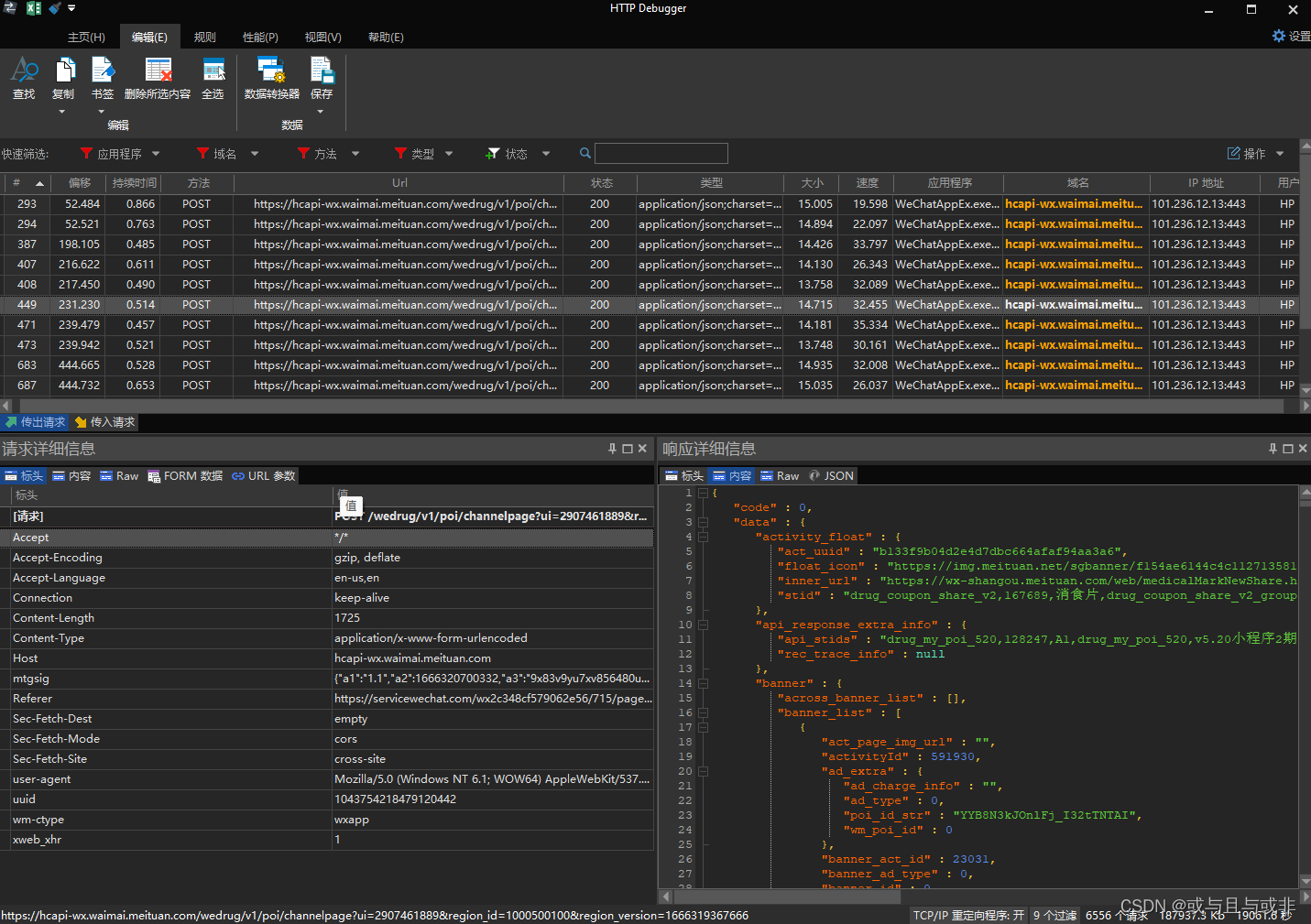
它是直接扫描进程池,通过进程监听实现抓包。
直接使用python控制鼠标点击,就像按键精灵一样把JSON复制粘贴出来然后进行数据分析
import pyWinhook as pyHook
import pythoncom
from pymouse import PyMouse
import win32api
import win32con
import time
import json
import re
import pymongo
myMouse = PyMouse()
#开启数据库连接
collection = pymongo.MongoClient()['美团外卖']['药店']
collection2 = pymongo.MongoClient()['美团外卖']['药店_shop_info']
collection3 = pymongo.MongoClient()['美团外卖']['药店_spuList']
# 存储门店id
def static_vars(**kwargs):
def decorate(func):
for k in kwargs:
setattr(func, k, kwargs[k])
return func
return decorate
@static_vars(soterid = '')
#获取当前的鼠标位置
def getcoord():
nowP = myMouse.position()
return nowP
# 监听爬取
def response(flow):
target_url = 'poi/sputag/products'
shop_info_url = 'poi/food'
if shop_info_url in flow.request.url:
item = {}
item['data'] = json.loads(flow.response.text)['data']
item['id'] = item['data']['poi_info']['id']
response.soterid=item['id']
item['shop_name'] = item['data']['poi_info']['name']
pageCategoryDict = {}
for cate in item['data']['food_spu_tags']:
tag = cate['tag']
pageCategoryDict[tag] = cate
item['pageCategoryDict'] = pageCategoryDict
print('shop_name:',item['shop_name'])
if not collection2.find_one({'id': item['id']}):
collection2.insert_one(item)
else:
collection2.update({'id': item['id']}, item)
if target_url in flow.request.url:
shop_id = response.soterid
print('>>>>>>店铺id:',shop_id)
data = json.loads(flow.response.text)['data']
tag_id = data['product_tag_id']
nextPageIndex = data['current_page']
id = f'{shop_id}_{tag_id}_{nextPageIndex}'
spuList = data['product_spu_list']
item = {}
item['shop_id'] = shop_id
item['tag_id'] = 1
item['id'] = 2
item['spuList'] = spuList
if spuList:
for spu in spuList:
spu_name = spu['name']
print('>>>>>>插入:',spu_name)
item1={}
item1["shopid"] = shop_id
spu_id= spu["id"]
sputableid = f'{shop_id}_{tag_id}_{spu_id}'
print('>>>>>>插入:',sputableid)
item1["id"] = sputableid
item1["name"] = spu_name
item1["minprice"] =spu["min_price"]
item1["promotioninfo"] =spu["promotion_info"]
item1["monthsale"] =spu["month_saled_content"]
goods=spu['skus']
if goods:
for sku in goods:
item1["stock"]=sku['stock']
item1["status"] =sku["status"]
collection3.insert_one(item1)
if not collection.find_one({'id':id}):
collection.insert_one(item)
else:
collection.update({'id':id},item)
#初次进入门店鼠标坐标
x=1121
y=389
# 进入门店
def enterStore(x,y):
time.sleep(2)
myMouse.click(x,y,1,1)
# 退出门店
def exitStore(x,y):
time.sleep(2)
myMouse.click(776,147,1,1)
print("已退出门店")
#移会门店列表
myMouse.move(x,y)
FirestStore=True
storenum=0;
def nextStore(FirestStore,storenum,x,y):
exitStore(x,y)
time.sleep(2)
print("准备进入下一个门店")
if FirestStore==True:
win32api.mouse_event(win32con.MOUSEEVENTF_WHEEL,0,0,-400)
FirestStore=False
print(FirestStore)
else:
if storenum<=3:
storenum=storenum+1
y=y-30
myMouse.move(x,y)
else:
print(FirestStore)
win32api.mouse_event(win32con.MOUSEEVENTF_WHEEL,0,0,-50)
enterStore(x,y)
nowP=getcoord()
print(nowP)
#鼠标移动到坐标(x,y)处
#myMouse.move(600,800)
#鼠标点击,x,y是坐标位置 button 1表示左键,2表示点击右键 n是点击次数,默认是1次,2表示双击
myMouse.click(1123,387,1,1)
print("点击事件完成")
time.sleep(3)
win32api.mouse_event(win32con.MOUSEEVENTF_WHEEL,0,0,-300)
print("滚动事件完成")
nowP=getcoord()
#进入第一个门店
enterStore(nowP[0],nowP[1])
nextStore(FirestStore,storenum,nowP[0],nowP[1])
nextStore(FirestStore,storenum,nowP[0],nowP[1])
nextStore(FirestStore,storenum,nowP[0],nowP[1])
反编译程序或者找到抓包程序的缓存文件,这些请求记录肯定是会有缓存文件的,找到它的存储位置然后直接读取文件进行数据分析。
(暂时还没有找到)
只要是数据交换那就一定能抓到包。不要轻言放弃有时候换个思考方式就能得到想要的答案。我在用这个神器之前也试过 Proxifier 、Wireshark等相对出名的数据分析程序。但是他们抓到的包都是没有经过任何处理的原始数据,这种数据对于我这种菜鸡来说和天书没啥区别。当时就准备放弃了。
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否