React 作为前端使用最多的框架,必然是面试的重点。我们接下来主要从 React 的使用方式、源码层面和周边生态(如 redux, react-router 等)等几个方便来进行总结。
这里主要考察的是,在开发使用过程中,对 React 框架的了解,如 hook 的不同调用方式得到的结果、函数组件中的 useState 和类组件的 state 的区别等等。
React 组件的 props 变动,会让组件重新执行,但并不会引起 state 的值的变动。state 值的变动,只能由 setState() 来触发。因此若想在 props 变动时,重置 state 的数据,需要监听 props 的变动,如:
const App = props => {
const [count, setCount] = useState(0);
// 监听 props 的变化,重置 count 的值
useEffect(() => {
setCount(0);
}, [props]);
return <div onClick={() => setCount(count + 1)}>{count}</div>;
};
React 的更新都是渐进式的更新,在 React18 中启用的新特性,其实在 v17 中(甚至更早)就埋下了。
createRoot()创建一个 root 节点,然后该 root 节点来调用render()方法;React 中的并发,并不是指同一时刻同时在做多件事情。因为 js 本身就是单线程的(同一时间只能执行一件事情),而且还要跟 UI 渲染竞争主线程。若一个很耗时的任务占据了线程,那么后续的执行内容都会被阻塞。为了避免这种情况,React 就利用 fiber 结构和时间切片的机制,将一个大任务分解成多个小任务,然后按照任务的优先级和线程的占用情况,对任务进行调度。
我们稍微了解下什么是受控组件和非受控组件:
那么如何将非受控组件改为受控组件呢?那就是把上面的这些纯 html 组件数据或状态的变更,交给 React 来操作:
const App = () => {
const [value, setValue] = useState('');
const [checked, setChecked] = useState(false);
return (
<>
<input value={value} onInput={event => setValue(event.target.value)} />
<input type="checkbox" checked={checked} onChange={event => setChecked(event.target.checked)} />
</>
);
};
上面代码中,输入框和 checkbox 的变化,均是经过了 React 来操作的,在数据变更时,React 是能够知道的。
高阶组件通过包裹(wrapped)被传入的 React 组件,经过一系列处理,最终返回一个相对增强(enhanced)的 React 组件,供其他组件调用。
作用:
参考:react 进阶」一文吃透 React 高阶组件(HOC)
官方网站有介绍该原因:使用 Hook 的动机。
这里我们简要的提炼下:
componentDidMount中执行和获取数据,而之后需在 componentWillUnmount 中清除;但在函数组件中,不同的逻辑可以放在不同的 Hook 中执行,互不干扰;this 的使用,如 this.onClick.bind(this),this.state,this.setState() 等,同时,class 不能很好的压缩,并且会使热重载出现不稳定的情况;Hook 使你在非 class 的情况下可以使用更多的 React 特性;useCallback 和 useMemo 可以用来缓存函数和变量,提高性能,减少资源浪费。但并不是所有的函数和变量都需要用这两者来实现,他也有对应的使用场景。
我们知道 useCallback 可以缓存函数体,在依赖项没有变化时,前后两次渲染时,使用的函数体是一样的。它的使用场景是:
主要是为了避免重新生成的函数,会导致其他 hook 或组件的不必要刷新。
useMemo 用来缓存函数执行的结果。如每次渲染时都要执行一段很复杂的运算,或者一个变量需要依赖另一个变量的运算结果,就都可以使用 useMemo()。
参考文章:React18 源码解析之 useCallback 和 useMemo。
useState()的传参有两种方式:纯数据和回调函数。这两者在初始化时,除了传入方式不同,没啥区别。但在调用时,不同的调用方式和所在环境,输出的结果也是不一样的。
如:
const App = () => {
const [count, setCount] = useState(0);
const handleParamClick = () => {
setCount(count + 1);
setCount(count + 1);
setCount(count + 1);
};
const handleCbClick = () => {
setCount(count => count + 1);
setCount(count => count + 1);
setCount(count => count + 1);
};
};
上面的两种传入方式,最后得到的 count 结果是不一样的。为什么呢?因为在以数据的格式传参时,这 3 个使用的是同一个 count 变量,数值是一样的。相当于setCount(0 + 1),调用了 3 次;但以回调函数的传参方式,React 则一般地会直接该回调函数,然后得到最新结果并存储到 React 内部,下次使用时就是最新的了。注意:这个最新值是保存在 React 内部的,外部的 count 并不会马上更新,只有在下次渲染后才会更新。
还有,在定时器中,两者得到的结果也是不一样的:
const App = () => {
const [count, setCount] = useState(0);
useEffect(() => {
const timer = setInterval(() => {
setCount(count + 1);
}, 500);
return () => clearInterval(timer);
}, []);
useEffect(() => {
const timer = setInterval(() => {
setCount(count => count + 1);
}, 500);
return () => clearInterval(timer);
}, []);
};
在 React.StrictMode 模式下,如果用了 useState,usesMemo,useReducer 之类的 Hook,React 会故意渲染两次,为的就是将一些不容易发现的错误容易暴露出来,同时 React.StrictMode 在正式环境中不会重复渲染。
也就是在测试环境的严格模式下,才会渲染两次。
从 16.6.0 开始,React 提供了 lazy 和 Suspense 来实现懒加载。
import React, { lazy, Suspense } from 'react';
const OtherComponent = lazy(() => import('./OtherComponent'));
function MyComponent() {
return (
<Suspense fallback={<div>Loading...</div>}>
<OtherComponent />
</Suspense>
);
}
属性fallback表示在加载组件前,渲染的内容。
若在定时器内直接使用 React 的代码,可能会收到意想不到的结果。如我们想实现一个每 1 秒加 1 的定时器:
const App = () => {
const [count, setCount] = useState(0);
useEffect(() => {
const timer = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(timer);
}, []);
return <div className="App">{count}</div>;
};
可以看到,coun 从 0 变成 1 以后,就再也不变了。为什么会这样?
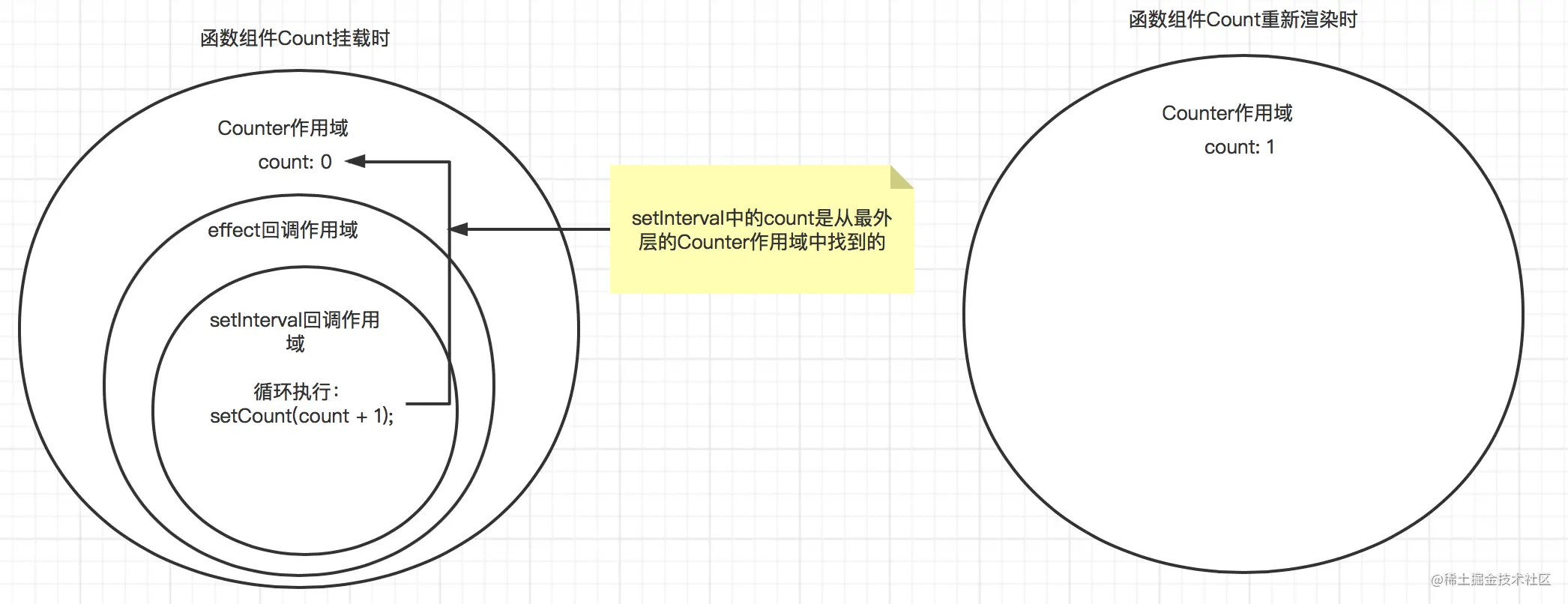
尽管由于定时器的存在,组件始终会一直重新渲染,但定时器的回调函数是挂载期间定义的,所以它的闭包永远是对挂载时 Counter 作用域的引用,故 count 永远不会超过 1。
针对这个单一的 hook 调用,还比较好解决,例如可以监听 count 的变化,或者通过 useState 的 callback 传参方式。
const App = () => {
const [count, setCount] = useState(0);
// 监听 count 的变化,不过这里将定时器改成了 setTimeout
// 即使不修改,setInterval()的timer也会在每次渲染时被清除掉,
// 然后重新启动一个新的定时器
useEffect(() => {
const timer = setTimeout(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(timer);
}, [count]);
// 以回调的方式
// 回调的方式,会计算回调的结果,然后作为下次更新的初始值
// 详情可见: https://www.xiabingbao.com/post/react/react-usestate-rn5bc0.html#5.+updateReducer
useEffect(() => {
const timer = setInterval(() => {
setCount(count => count + 1);
}, 1000);
return () => clearInterval(timer);
}, []);
return <div className="App">{count}</div>;
};
当然还有别的方式也可以实现 count 的更新。那要是调用更多的 hook,或者更复杂的代码,该怎么办呢?这里我们可以封装一个新的 hook 来使用:
// https://overreacted.io/zh-hans/making-setinterval-declarative-with-react-hooks/
const useInterval = (callback: () => void, delay: number | null): void => {
const savedCallback = useRef(callback);
useEffect(() => {
savedCallback.current = callback;
});
useEffect(() => {
function tick() {
savedCallback.current();
}
if (delay !== null) {
const id = setInterval(tick, delay);
return () => clearInterval(id);
}
}, [delay]);
};
useEffect(callback)的回调函数里,若有返回的函数,这是 effect 可选的清除机制。每个 effect 都可以返回一个清除函数。
React 何时清除 effect? React 会在组件卸载的时候执行清除操作。同时,若组件产生了更新,会先执行上一个的清除函数,然后再运行下一个 effect。如
// 运行第一个 effect
// 产生更新时
// 清除上一个 effect
// 运行下一个 effect
// 产生更新时
// 清除上一个 effect
// 运行下一个 effect
// 组件卸载时
// 清除最后一个 effect
这部分考察的就更有深度一些了,多多少少得了解一些源码,才能明白其中的缘由,比如 React 的 diff 对比,循环中 key 的作用等。
Virtual DOM 是以对象的方式来描述真实 dom 对象的,那么在做一些 update 的时候,可以在内存中进行数据比对,减少对真实 dom 的操作减少浏览器重排重绘的次数,减少浏览器的压力,提高程序的性能,并且因为 diff 算法的差异比较,记录了差异部分,那么在开发中就会帮助程序员减少对差异部分心智负担,提高了开发效率。
虚拟 dom 好多这么多,渲染速度上是不是比直接操作真实 dom 快呢?并不是。虚拟 dom 增加了一层内存运算,然后才操作真实 dom,将数据渲染到页面上。渲染上肯定会慢上一些。虽然虚拟 dom 的缺点在初始化时增加了内存运算,增加了首页的渲染时间,但是运算时间是以毫秒级别或微秒级别算出的,对用户体验影响并不是很大。
React 中所有触发的事件,都是自己在其内部封装了一套事件机制。目的是为了实现全浏览器的一致性,抹平不同浏览器之间的差异性。
在 React17 之前,React 是把事件委托在 document 上的,React17 及以后版本不再把事件委托在 document 上,而是委托在挂载的容器上。React 合成事件采用的是事件冒泡机制,当在某具体元素上触发事件时,等冒泡到顶部被挂载事件的那个元素时,才会真正地执行事件。
而原生事件,当某具体元素触发事件时,会立刻执行该事件。因此若要比较事件触发的先后时机时,原生事件会先执行,React 合成事件会后执行。
key 帮助 React 识别哪些元素改变了,比如被添加或删除。因此你应当给数组中的每一个元素赋予一个确定的标识。
当组件刷新时,React 内部会根据 key 和元素的 type,来对比元素是否发生了变化。若选做 key 的数据有问题,可能会在更新的过程中产生异常。
在 React18 中,无论是多个 useState()的 hook,还是操作(dispatch)多次的数据。只要他们在同一优先级,React 就会将他们合并到一起操作,最后再更新数据。
这是基于 React18 的批处理机制。React 将多个状态更新分组到一个重新渲染中以获得更好的性能。(将多次 setstate 事件合并);在 v18 之前只在事件处理函数中实现了批处理,在 v18 中所有更新都将自动批处理,包括 promise 链、setTimeout 等异步代码以及原生事件处理函数;
参考:多次调用 useState() 中的 dispatch 方法,会产生多次渲染吗?
首先声明,我们不应当直接修改 state 的值,一方面是无法刷新组件(无法将新数据渲染到页面中),再有可能会对下次的更新产生影响。
唯一有影响的,就是后续要使用该变量的地方,会使用到新数据。但若其他 useState() 导致了组件的刷新,刚才变量的值,若是基本类型(比如数字、字符串等),会重置为修改之前的值;若是复杂类型,基于 js 的 对象引用 特性,也会同步修改 React 内部存储的数据,但不会引起视图的变化。
通过上面的 diff 对比过程,我们也可以看到,当组件产生比较大的变更时,React 需要做更多的动作,来构建出新的 fiber 树,因此我们在开发过程中,若从性能优化的角度考虑,尤其要注意的是:
参考:React18 源码解析之 reconcileChildren 生成 fiber 的过程
JavaScript 中的 map 不会对为 null 或者 undefined 的数据进行处理,而 React.Children.map 中的 map 可以处理 React.Children 为 null 或者 undefined 的情况。
这部分主要考察 React 周边生态配套的了解,如状态管理库 redux、mobx,路由组件 react-router-dom 等。
api 方面
React-router: 提供了路由的核心 api。如 Router、Route、Switch 等,但没有提供有关 dom 操作进行路由跳转的 api;
React-router-dom: 提供了 BrowserRouter、Route、Link 等 api,可以通过 dom 操作触发事件控制路由。
Link 组件,会渲染一个 a 标签;BrowserRouter 和 HashRouter 组件,前者使用 pushState 和 popState 事件构建路由,后者使用 hash 和 hashchange 事件构建路由。
使用区别
react-router-dom 在 react-router 的基础上扩展了可操作 dom 的 api。 Swtich 和 Route 都是从 react-router 中导入了相应的组件并重新导出,没做什么特殊处理。
react-router-dom 中 package.json 依赖中存在对 react-router 的依赖,故此,不需要额外安装 react-router。
Redux 使用 “Store” 将程序的整个状态存储在同一个地方。因此所有组件的状态都存储在 Store 中,并且它们从 Store 本身接收更新。单一状态树可以更容易地跟踪随时间的变化,并调试或检查程序。
Redux 的优点如下:
React 涉及到的相关知识点非常多,我也会经常更新的。
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我有一个将某些事件写入队列的Rails3应用。现在我想在服务器上创建一个服务,每x秒轮询一次队列,并按计划执行其他任务。除了创建ruby脚本并通过cron作业运行它之外,还有其他稳定的替代方案吗? 最佳答案 尽管启动基于Rails的持久任务是一种选择,但您可能希望查看更有序的系统,例如delayed_job或Starling管理您的工作量。我建议不要在cron中运行某些东西,因为启动整个Rails堆栈的开销可能很大。每隔几秒运行一次它是不切实际的,因为Rails上的启动时间通常为5-15秒,具体取决于您的硬件。不过,每天这样做几
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
只是想更新到最新版本的Ruby。在ruby-lang.org/en/documentation/installation/#homebrew上,我发现你应该可以通过自制软件来完成:brewinstallruby但是,当我在“更新”后列出ruby版本(ruby-v)时,它仍然是旧版本2.0.0。Hermes:~Sancho$ruby-vruby2.0.0p481(2014-05-08revision45883)[universal.x86_64-darwin13]我碰巧列出了/usr/local/bin/的内容,我可以看到一个符号链接(symboliclink):ruby->..
是否可以在单个事件机器中运行多个服务器?我的意思是,多个服务可以由一个客户端连接同时使用。例如,登录服务器对用户进行身份验证,然后用户可以同时使用聊天室和简单的游戏,例如带有单个客户端套接字的跳棋?或者我是否需要为每个服务使用多个事件机器react器? 最佳答案 我试过了,它正在工作:#!/usr/bin/envrubyrequire'eventmachine'moduleEchoServerdefpost_initputs"--someoneconnectedtotheechoserver!"enddefreceive_datad
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
一、相关网址1、官网(可以下载,查看文章)https://skywalking.apache.org/downloads/2、github地址:(可提问题寻求帮助)https://github.com/apache/skywalking二、 实验环境操作系统 centos7.9先安装好 elasticsearch7.16.2操作系统安装好jdk8-17,实验机器jdk11java下载地址:https://www.oracle.com/java/technologies/downloads/#java8IP地址为192.168.24.160三、安装skywalking 1、下载skywalkin