TCP和UDP协议的区别以及原理
最近重新认知了一下TCP和UDP的原理以及区别,做一个简单的总结。
首先,tcp和udp都是工作在传输层,用于程序之间传输数据的。数据一般包含:文件类型,视频类型,jpg图片等。

TCP是基于连接的,而UDP是基于非连接的。
tcp传输数据稳定可靠,适用于对网络通讯质量要求较高的场景,需要准确无误的传输给对方,比如,传输文件,发送邮件,浏览网页等等
udp的优点是速度快,但是可能产生丢包,所以适用于对实时性要求较高但是对少量丢包并没有太大要求的场景。比如:域名查询,语音通话,视频直播等。udp还有一个非常重要的应用场景就是隧道网络,比如:VXLAN
以人与人之间的通信为例:UDP协议就相当于是写信给对方,寄出去信件之后不能知道对方是否收到信件,信件内容是否完整,也不能得到及时反馈,而TCP协议就像是打电话通信,在这一系列流程都能得到及时反馈,并能确保对方及时接收到。如下图:

tcp是如何保证以上过程的?
分为三个步骤:三次握手,传输确认,四次挥手。三次握手是建立连接的过程。
当客户端向服务端发起连接时,会先发一包连接请求数据,过去询问一下,能否与你建立连接?这包数据称之为SYN包,如果对端同意连接,则回复一包SYN+ACK包,客户端收到之后,发送一包ACK包,连接建立,因为这个过程中互相发送了三包数据,所以称之为三次握手。
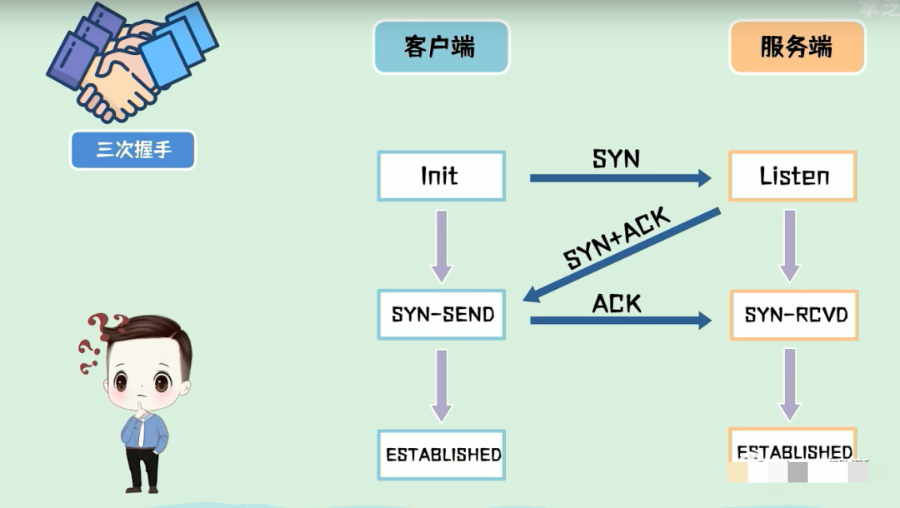
为什么要三次握手而不是两次握手?
这是为了防止,因为已失效的请求报文,突然又传到服务器,引起错误, 这是什么意思?
假设采用两次握手建立连接,客户端向服务端发送一个syn包请求建立连接,因为某些未知的原因,并没有到达服务器,在中间某个网络节点产生了滞留,为了建立连接,客户端会重发syn包,这次的数据包正常送达,服务端发送syn+ack之后就建立起了连接。
但是第一包数据阻塞的网络突然恢复,第一包syn包又送达到服务端,这时服务端会认为客户端又发起了一个新的连接,从而在两次握手之后进入等待数据状态,服务端认为是两个连接,而客户端认为是一个连接,造成了状态不一致,如果在三次握手的情况下,服务端收不到最后的ack包,自然不会认为连接建立成功。
所以三次握手本质上来说就是为了解决网络信道不可靠的问题,为了在不可靠的信道上建立起可靠的连接,经过三次握手之后,客户端和服务端都进入了数据传输状态。
数据传输:
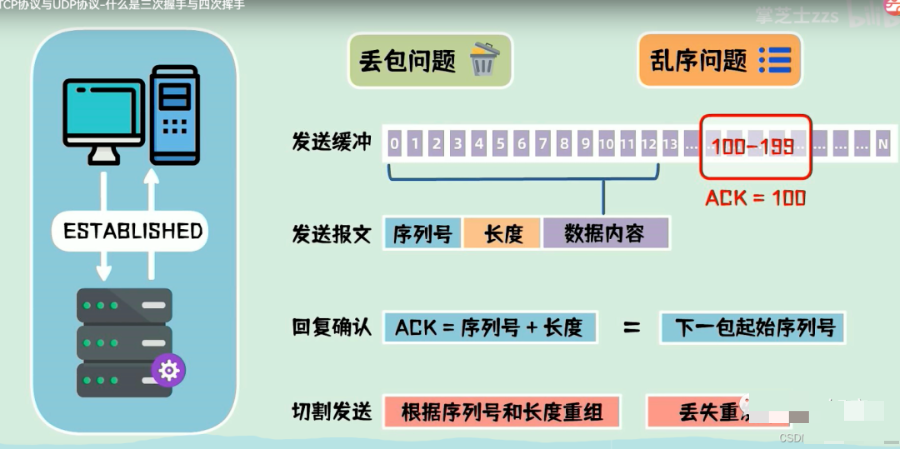
一包数据可能会被拆成多包发送,如何处理丢包问题,这些数据包到达的先后顺序不同,如何处理乱序问题?
针对这些问题,tcp协议为每一个连接建立了发送缓冲区,从建立链接后的第一个字节的序列号为0,后面每个字节的序列号就会增加1,发送数据时,从数据缓冲区取一部分数据组成发送报文,在tcp协议头中会附带序列号和长度,接收端在收到数据后需要回复确认报文,确认报文中的ack等于接受序列号加长度,也就是下包数据发送的起始序列号,这样一问一答的发送方式,能够使发送端确认发送的数据已经被对方收到,发送端也可以发送一次的连续的多包数据,接受端只需要回复一次ack就可以了。如图:
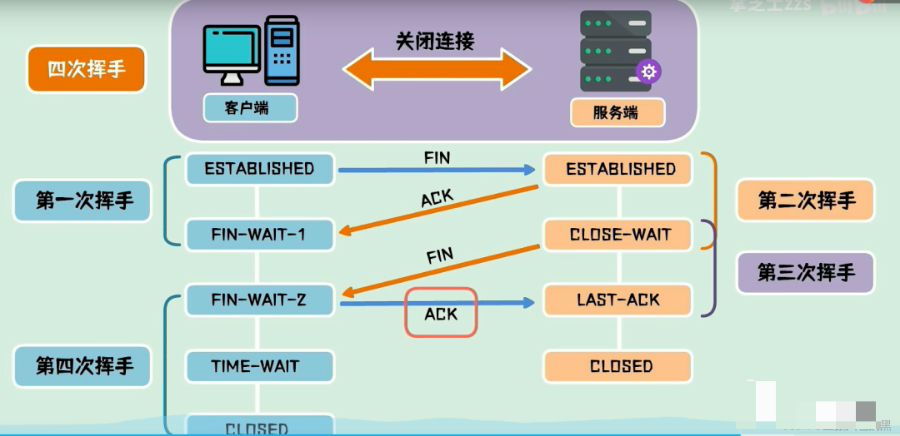
处于连接状态的客户端和服务端,都可以发起关闭连接请求,此时需要四次挥手来进行连接关闭。假设客户端主动发起连接关闭请求,他给服务端发起一包FIN包,标识要关闭连接,自己进入终止等待1装填,服务端收到FIN包,发送一包ACK包,标识自己进入了关闭等待状态,客户端进入终止等待2状态,这是第二次挥手,服务端此时还可以发送未发送的数据,而客户端还可以接受数据,待服务端发送完数据之后,发送一包FIN包,最后进入确认状态,这是第3次挥手,客户端收到之后恢复ACK包,进入超时等待状态,经过超时时间后关闭连接,而服务端收到ACK包后,立即关闭连接,这是第四次挥手。
为什么客户端要等待超时时间?这是为了保证对方已经收到ACK包,因为假设客户端发送完最后一包ACK包后释放了连接,一旦ACK包在网络中丢失,服务端将一直停留在 最后确认状态,如果等待一段时间,这时服务端会因为没有收到ack包重发FIN包,客户端会响应 这个FIN包进行重发ack包,并刷新超时时间,这个机制跟第三次握手一样。也是为了保证在不可靠的网络链路中进行可靠的连接断开确认。
udp:首先udp协议是非连接的,发送数据就是把简单的数据包封装一下,然后从网卡发出去就可以了,数据包之间并没有状态上的联系,正因为udp这种简单的处理方式,导致他的性能损耗非常少,对于cpu,内存资源的占用也远小于tcp,但是对于网络传输过程中产生的丢包,udp并不能保证,所以udp在传输稳定性上要弱于tcp。
所以,tcp和udp的主要区别:tcp传输数据稳定可靠,适用于对网络通讯质量要求较高的场景,需要准确无误的传输给对方。比如,传输文件,发送邮件,浏览网页等等,udp的优点是速度快,但是可能产生丢包,所以适用于对实时性要求较高但是对少量丢包并没有太大要求的场景。比如:域名查询,语音通话,视频直播等。
udp还有一个非常重要的应用场景就是隧道网络,比如:VXLAN.

我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我正在检查一个Rails项目。在ERubyHTML模板页面上,我看到了这样几行:我不明白为什么不这样写:在这种情况下,||=和ifnil?有什么区别? 最佳答案 在这种特殊情况下没有区别,但可能是出于习惯。每当我看到nil?被使用时,它几乎总是使用不当。在Ruby中,很少有东西在逻辑上是假的,只有文字false和nil是。这意味着像if(!x.nil?)这样的代码几乎总是更好地表示为if(x)除非期望x可能是文字false。我会将其切换为||=false,因为它具有相同的结果,但这在很大程度上取决于偏好。唯一的缺点是赋值会在每次运行
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
打印1:defsum(i)i=i+[2]end$x=[1]sum($x)print$x打印12:defsum(i)i.push(2)end$x=[1]sum($x)print$x后者是修改全局变量$x。为什么它在第二个例子中被修改而不是在第一个例子中?类Array的任何方法(不仅是push)都会发生这种情况吗? 最佳答案 变量范围在这里无关紧要。在第一段代码中,您仅使用赋值运算符=为变量i赋值,而在第二段代码中,您正在修改$x(也称为i)使用破坏性方法push。赋值从不修改任何对象。它只是提供一个名称来引用一个对象。方法要么是破坏性