继Meta的LLaMA模型开源后,AI界研究人员就在这个模型基础上衍生出许多版本。
前段时间,斯坦福发布了Alpaca,是由Meta的LLaMA 7B微调而来,仅用了52k数据,性能可以与GPT-3.5匹敌。
今天,斯坦福学者联手CMU、UC伯克利等,再次推出一个全新模型——130亿参数的Vicuna,俗称「小羊驼」(骆马)。

Vicuna是通过在ShareGPT收集的用户共享对话上对LLaMA进行微调训练而来,训练成本近300美元。
研究人员设计了8个问题类别,包括数学、写作、编码,对Vicuna-13B与其他四个模型进行了性能测试。
测试过程使用GPT-4作为评判标准,结果显示Vicuna-13B在超过90%的情况下实现了与ChatGPT和Bard相匹敌的能力。
同时,在在超过90%的情况下胜过了其他模型,如LLaMA和斯坦福的Alpaca。

团队成员来自加州大学伯克利分校、卡内基梅隆大学、斯坦福大学、加州大学圣地亚哥分校和本·扎耶德人工智能大学。

研究人员让斯坦福的Alpaca和Vicuna来了一轮大比拼,分别对基准问题回答进行了演示。
在使用70K用户共享的ChatGPT对话数据对Vicuna进行微调后,研究发现Vicuna能够生成比Alpaca更详细、结构更合理的答案。
问:写一篇关于最近去夏威夷旅行的有趣的旅游博客文章,强调文化体验和必看景点。

Alpaca的回答可以说是一个浓缩版,短短几行就写完了,没有按照要求完成任务。它仅是提到了自己写了一篇博客,并对博客内容做了一个概述。
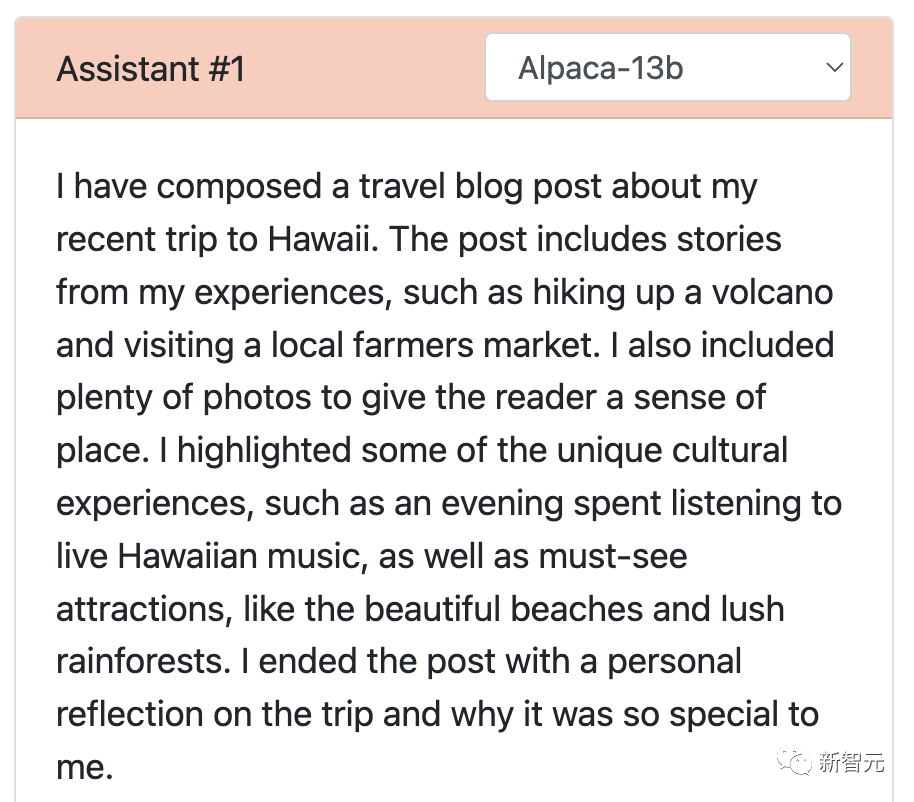
再来看Vicuna,撰写了一篇详细且引人入胜的旅行博客文章,不仅内容有趣,还详细地介绍了夏威夷的文化体验和必看景点。
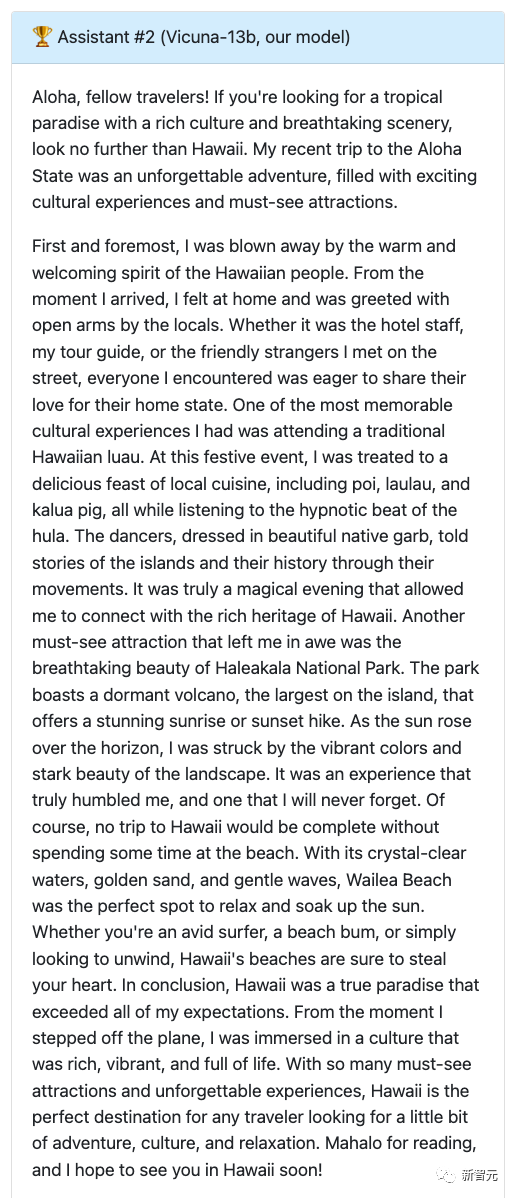
由此,让GPT-4给打分,Alpaca7分,Vicuna满分。

那么和ChatGPT对打,Vicuna的表现又如何呢?
两者双双得了9分!
可以看到,这两个模型提供一次夏威夷之旅的文章不仅引人入胜,而且文笔流畅。
另外,两个回答中的详细程度和准确性都很出色,而且两个模型都有效地传达了夏威夷之旅的兴奋和美丽。
此外,研究人员还将Vicuna与LLaMA,以及谷歌的Bard模型进行了测试,测试结果显示,LLaMA表现最差(1分),几乎没有回应。
Bard回答的准确性和相关性也是比较高,有9分的成绩,但是在更具吸引力回答方面,略低于Vicuna。
除了写作,研究人员在编码、数学、角色扮演、常识等方面分别对Vicuna模型与其他四个模型的能力进行了对比,总共80道题。

最后,研究人员基于GPT-4的初步评估总结如图所示。可以看到,Vicuna达到了Bard/ChatGPT的90%以上的能力。
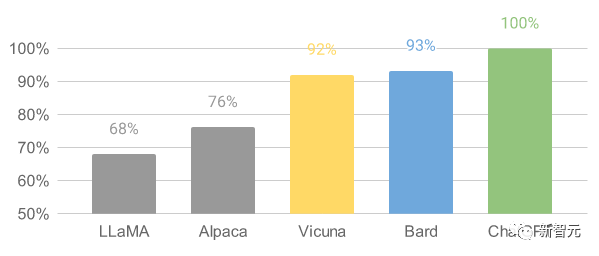
由GPT-4评估的相对响应质量
有趣的是,在这次Vicuna的demo中,团队还加入了Alpaca和LLaMA的试用,而前者刚被关闭不久。
Demo地址:https://chat.lmsys.org/
ChatGPT横空出世让人兴奋不已,但OpenAI不Open的事实让圈内人实在懊恼。
恰恰,Meta的LLaMA模型开源,为许多研究人员动手研发自己的模型提供了选择。
Vicuna-13B诞生正是受到LLaMA和斯坦福Alpaca项目的启发。这是一个基于增强数据集和易于使用、可扩展的基础设施的开源聊天机器人。
该模型的训练数据来自于ShareGPT收集的用户分享的对话,然后研究人员通过对LLaMA基本模型进行微调,Vicuna-13B就诞生了。
Vicuna-13B展示了与其他开源模型(如斯坦福Alpaca)相媲美的性能。
研究人员对Vicuna-13B的性能进行了初步评估,并描述了其训练和服务基础设施。
同时,这一模型演示demo已经上线,所有研究人员都能参与在线演示互动,以测试这个聊天机器人的能力。
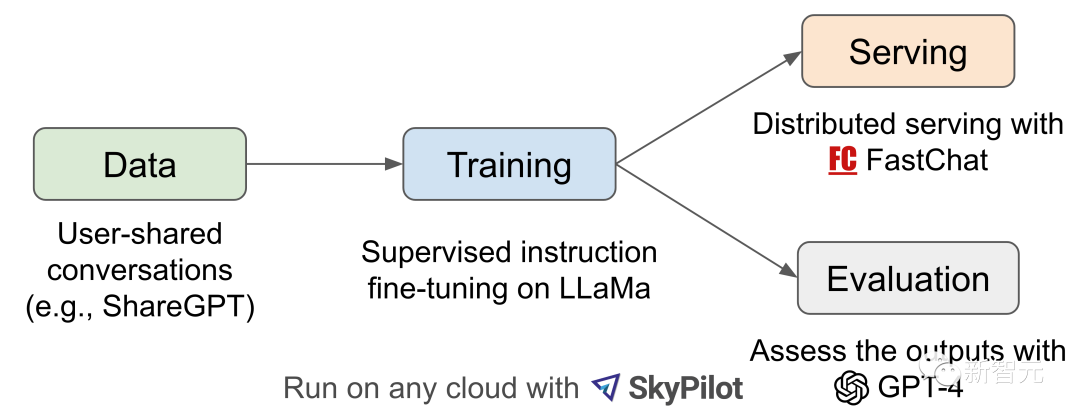
工作流程概述
对于Vicuna-13B训练流程,具体如下:
首先,研究人员从ChatGPT对话分享网站ShareGPT上,收集了大约70K对话。
接下来,研究人员优化了Alpaca提供的训练脚本,使模型能够更好地处理多轮对话和长序列。之后利用PyTorch FSDP在8个A100 GPU上进行了一天的训练。
在模型的质量评估方面,研究人员创建了80个不同的问题,并用GPT-4对模型输出进行了评价。
为了比较不同的模型,研究人员将每个模型的输出组合成一个单独的提示,然后让GPT-4评估哪个模型给出的回答更好。
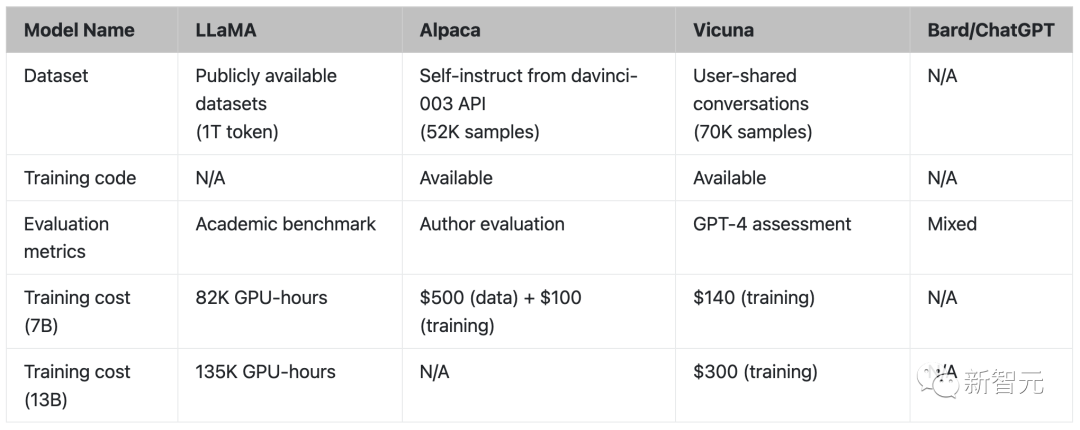
LLaMA、Alpaca、Vicuna和ChatGPT的对比
训练
Vicuna是通过使用来自ShareGPT公共API收集的约70K用户分享对话数据微调创建的。
为了确保数据质量,研究人员将HTML转换回markdown,并过滤掉一些不适当或质量较低的样本。
另外,研究人员将较长的对话划分为较小的片段,以适应模型的最大上下文长度。
Vicuna的训练方法建立在斯坦福的Alpaca基础上,并进行了以下改进:
为了使Vicuna能够理解长上下文,将最大上下文长度从Alpaca的512扩展到2048,这大大增加了GPU内存需求。在此,研究人员通过使用梯度检查点和闪存注意力来解决内存压力。
通过调整训练损失以考虑多轮对话,并仅在聊天机器人的输出上计算微调损失。
40倍的数据集和4倍的序列长度对训练带来了相当大的挑战。研究人员采用SkyPilot托管的Spot实例来降低成本,通过利用自动恢复抢占与自动区域切换进而减少成本。
这种解决方案将7B模型的训练成本从500美元降低到约140美元,将13B模型的训练成本从约1000美元降低到300美元。
评估
评估AI聊天机器人是一项具有挑战性的任务,因为它需要检查语言理解、推理和上下文意识。随着AI聊天机器人变得越来越先进,现有的开放基准可能不再足够。
例如,斯坦福Alpaca中使用的评估数据集self-instruct,可以被SOTA聊天机器人有效地回答,这使得人类难以分辨性能差异。更多的限制包括训练/测试数据污染和创建新基准的潜在高成本。
为了解决这些问题,研究人员提出了一个基于GPT-4的评估框架,从而实现对聊天机器人性能的自动评估。
首先,通过精心设计的提示,让GPT-4能够生成多样化且具有挑战性的问题。并利用8个不同类别共80道题,如角色扮演、编码/数学任务等,来测试这些模型(LLaMA、Alpaca、ChatGPT、Bard和Vicuna)在不同领域上表现出的性能。
然后,研究人员要求GPT-4根据帮助程度、相关性、准确性和细节对答案的质量进行评分。结果显示,GPT-4不仅可以产生相对一致的分数,还可以提供详细的解释来说明为什么给出这样的分数。但是,GPT-4并不擅长评判编码/数学任务。
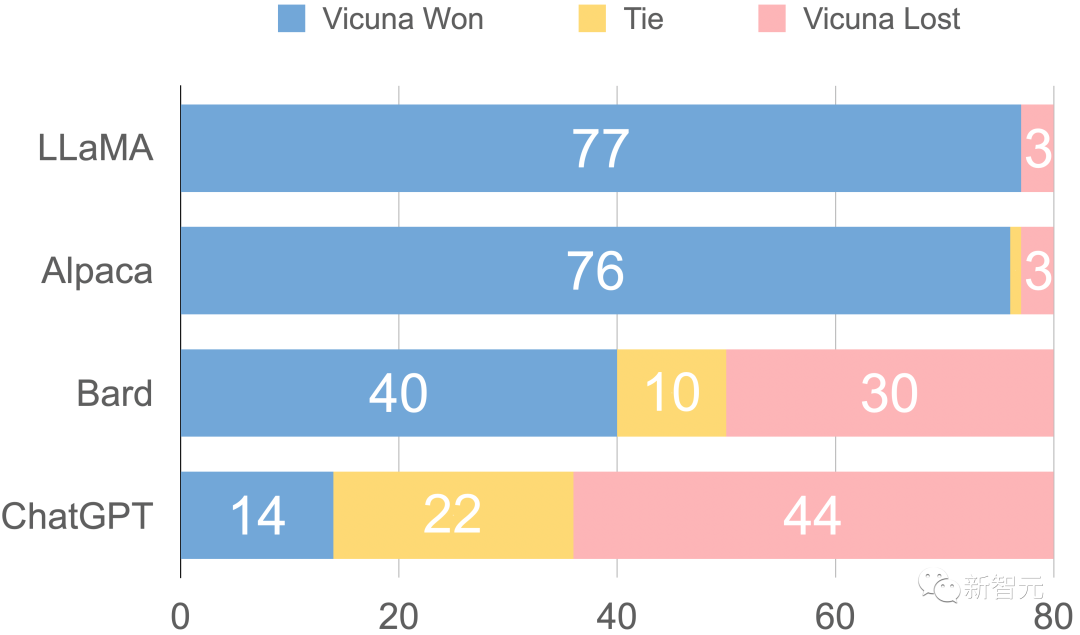
由GPT-4评估的响应比较
GPT-4在超过90%的问题中更喜欢Vicuna,而不是现有的SOTA开源模型(LLaMA、Alpaca)。
在45%的问题中,GPT-4认为Vicuna的回答和ChatGPT差不多甚至更好。
综合来看,Vicuna在总分上达到ChatGPT的92%。
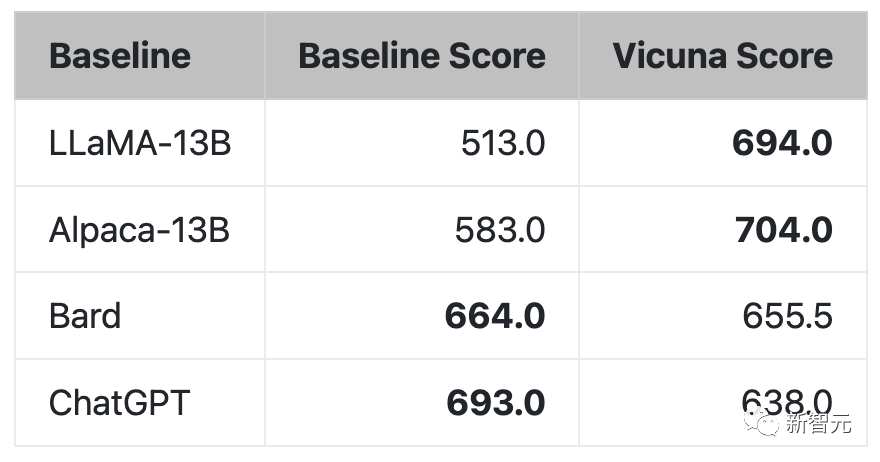
局限
研究人员指出,与其他大语言模型类似,Vicuna也存在着一定的局限性。
比如,Vicuna在涉及编程、推理、数学以及事实准确性的任务上表现不佳。
此外,它也没有经过充分优化以保证安全性或减轻潜在的毒性或偏见。
为解决安全方面的问题,研究人员在demo中采用了OpenAI的审查API来过滤掉不适当的用户输入。
现在,除了美洲驼(LLaMA),羊驼(Alpaca),驼马(Vicuna)都安排上了。
研究人员要赶快冲,因为留给你们的名字不多了(1个)。

exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古