如何用 AI 解决声音传输&处理中的三大问题?三大问题又是哪三大问题?
在「RTE2022 实时互联网大会」中,思必驰研发总监 @周强以《AI 和传统信号技术在实时音频通话中的应用》为题进行了主题演讲。
本文内容基于演讲内容进行整理,为方便阅读略有删改。

大家好我是 AIspeech 的研发总监周强,主要从事音频相关的研究开发工作。今天分享的内容主要包含下述四部分:
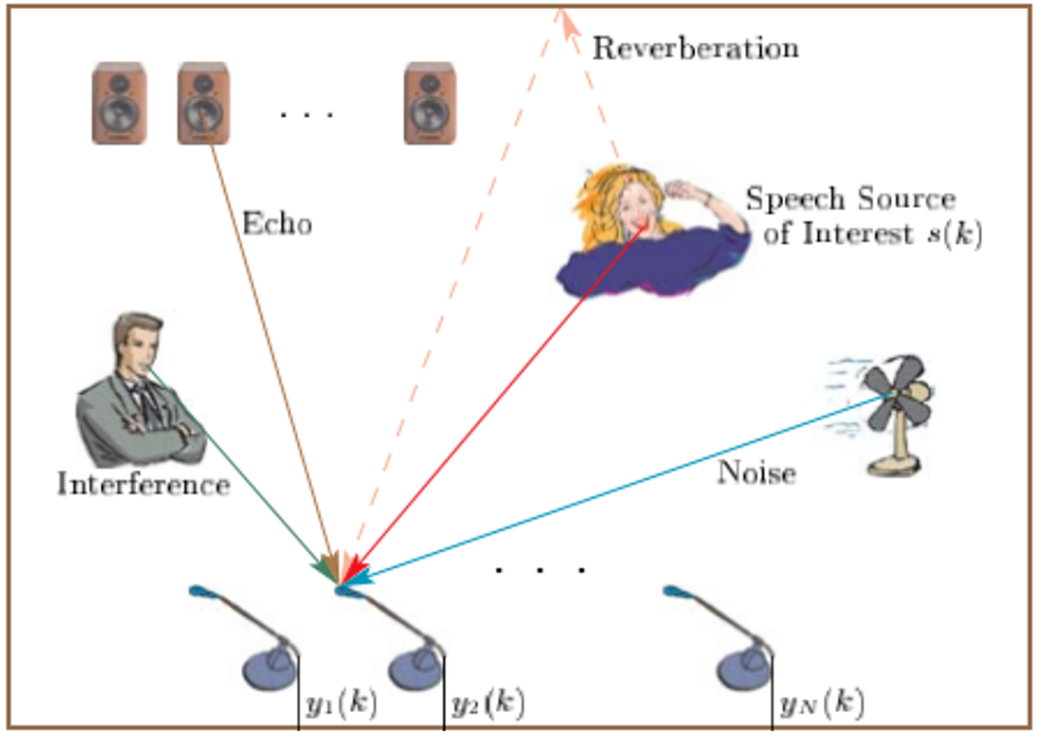
从贝尔发明电话开始,我们就面临着如何采用电声解决日常生活中客观存在的建筑声学的问题。比如房间构造和建筑材料造成的空间回响、环境噪音,以及很多通讯设备间的声音干扰,信号处理就是用来解决这类问题。
行业将信号处理面临的问题归位三个比较典型的类别,一般称作 3A 问题,3A 也是音频实时处理中较为关键的技术点,具体的分类与详情大致如下:
回声问题
° 信回比低,扬声器离 mic 比较近,结构内串音,分贝比较高,信回比可达到-45db
° 扬声器失真,扬声器 THD 以及结构震动带来的失真
° 回声路径变化,系统延时抖动,以及设备的移动
° 回声混响拖尾,空间混响,RT60 可达 1.2s
噪声问题
° 噪声谱多样性,冲击噪声,粉色噪声,类人声的噪声
° 噪声空间特性多样,强反射,散射场,点干扰
增益问题
° 多目标声源来回切换,增益速度和稳定性之间均衡
° 声源动态范围比较大
上文我们介绍了 3A 问题的常见场景与分类,下面我们对 3A 算法的基础原理做下介绍。
AEC 算法面临的主要问题是如何有效的分理处近端声音,目标是提升回声抑制,改善近端声音保真度。典型情况是假设当我在说话的时候,远端的扬声器也在播放音频,这时候我需要把远端扬声器播放的声音进行消除,尽量用算法来保真我的说话声音。
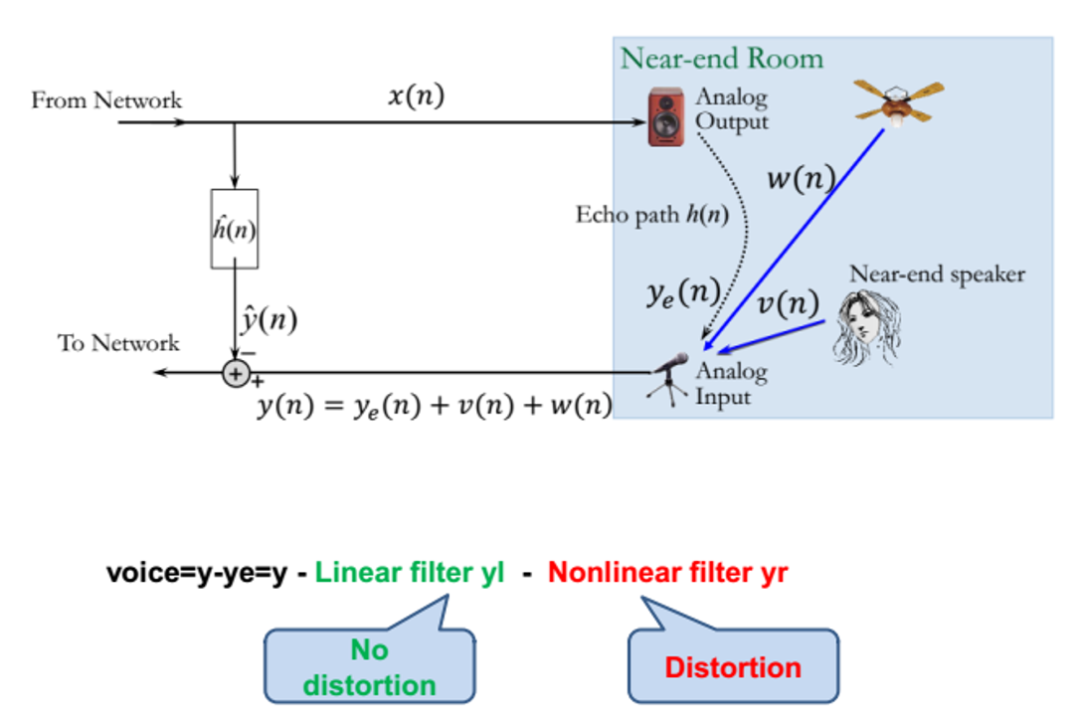
上图比较形象的描述了回声产生的数学原理以及数学处理机理。
扬声器播放音频,通过空间传播。这里的空间传播包括直达声和反射声的叠加,外部风扇的噪声以及目标说话人的人声,这些声音都被麦克风收集到。
我们目标是有效地去除扬声器的声音。它的关键点是如何有效地分离出近端的声音,并且保真人说话的声音。行业内一般比较主流也都是如图中方式来处理,采用线性滤波器和非线性的处理,通过这两部分来抑制扬声器播出来的声音,其中线性滤波器是无失真的,非线线滤波器是有失真的。
AEC 关键点中比较重要评价指标有三个:
稳态误差可以用来很好的评估滤波器本身对回声路径空气的误差,自适应滤波器会有收敛的过程,一旦收敛以后会有和标准答案之间有误差,误差越小说明系统性能越好。
收敛时间也是一个很重要的关键点,因为在线学习的过程总会有学习收敛的过程。
第三点是当双方同时说话的时候,因为加了带失真非线性滤波器会带来失真,所以失真的量也是我们比较在乎的关键点,也就是双讲时语音的衰减。
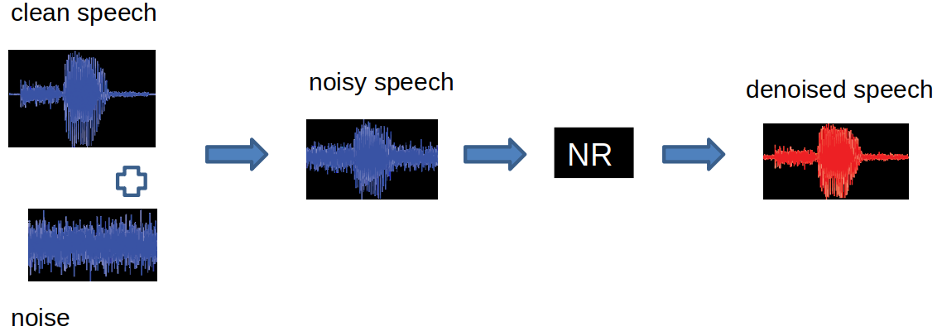
ANS 算法面临的问题是如何从被噪声污染的麦克风信号中恢复期望信号,这当中的难点是希望能把噪声去掉的同时,尽可能高保真的恢复干净纯洁的语音信号。
所有的算法都会客观存在估计信号和真实信号之间的偏差,因此总会存在一些失真。一般情况下我们的目标是尽量地去改善语音听感质量和一些客观指标(比如可懂度和语音信噪比等),改善后端系统的性能(语音识别,语音编码)。
我们刚才讲到,降噪的本质是从被污染信号中恢复原始信号的过程,这个过程不可避免的会存在一定量的失真。但在同一框架中降噪量和语音失真是互斥的过程,行业内对这两点做了很多研究,会在不同系统中做权衡。
AGC 算法解决的主要问题是如何统一不同源的音量大小。
不同说话者的声音大小不一,所以到达麦克风中的分贝也是不一样的。如何规范化不同源的音量大小,让远端的声音听起来不至于特别难受,需要进行更大范围的语音压缩。业内一般是借助动态压缩算法保证语音压缩在相对更小的 DB 范围内。
既然是压缩肯定就会涉及语音失真,失真的程度和压缩自身动态范围的大小、快慢,以及语音本身的稳定性、保真度都有关。压缩的原理相对也比较简单,声音小一点的把声音提高一点,声音大一点的把声音压小一点,一般会有标准分贝压缩曲线,类似下图所示。
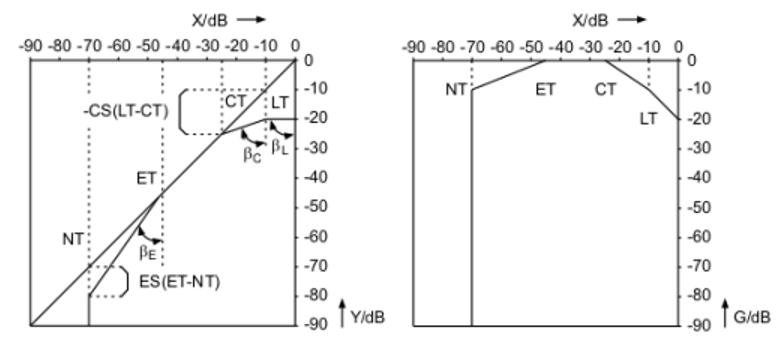
因为 AGC 算法处理一般放在整个系统的末端,如果前端的模块中存在噪声、回声一类的问题,会对 AGC 造成比较大的影响,造成一定程度的挑战。
接下来我会重点介绍一下 AI 在语音信号处理中的应用。
最近这波 AI 火了十几年了,在图像和语音中已经有了广泛地应用,在音频信号处理领域最近几年也越来越火,因为确实带来了比较好的结果以及让人期待的展望。下面我们展开来讲一讲。
AEC 算法模块一般情况下分为四个模块:
AEC 中比较重要的是线性滤波模块,行业中比较典型的是 AEC-NLMS 算法。
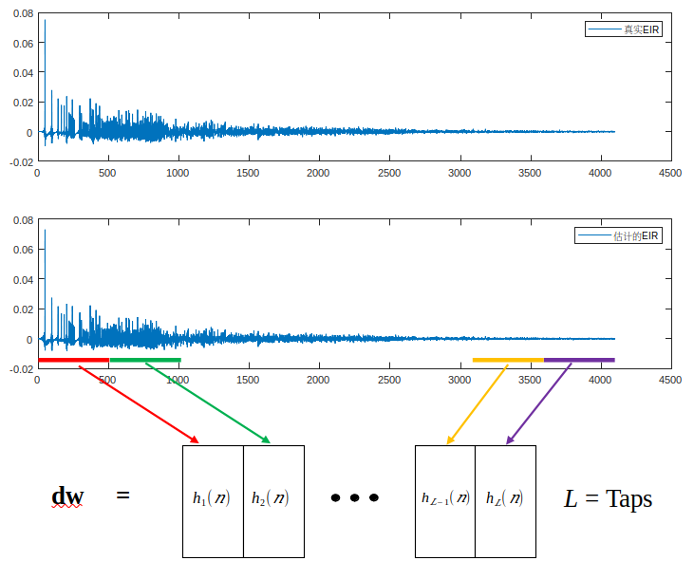
如上图所示,它的原理是通过线性滤波器去模拟去估计扬声器传播到麦克风之间的路径,把传播过来回声全部减掉,行业内一般情况是在频率分块去做处理。
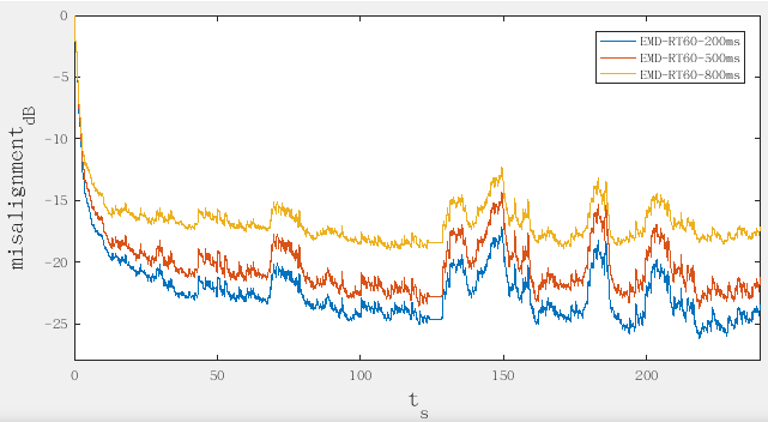
上图则给大家演示了一下,三个混响时间情况下滤波器的收敛过程,大家可以看一下随着混响时间变长,本身滤波器性能就在下降,200 毫秒混响的时候滤波器误差在-25db 左右,达到 800 毫秒基本上是负十几 db,两者有 10db 的差别。
滤波器为什么会存在波动呢?主要原因是当有人说话的时候,双讲滤波器存在发散,导致滤波器收敛发生问题,导致了 misalignment 变大,这是目前 AEC NLMS 滤波过程中存在的典型问题。
另外一个问题是因为是线性过程,很难学习扬声器的非线性过程,所以需要解决非线性的问题。这时我们自然而然会想到神经网络,因为神经网络本身具备学习的能力,它可以对非线性进行比较好的建模。
那么神经网络可以加持在 AEC 哪些模块呢?我们可以看到神经网络本身对线性滤波会有一些指导作用,我们可以比较一下红色和蓝色部分,可以看出神经网络对线性滤波学习收敛过程进行了一些指导,可以看出本身收敛稳态误差相对来说更稳定,在双讲过程中没有出现剧烈地波动。
另外一个模块是可以放在替代传统非线性抑制,比较好抑制噪声的残留。这个噪声残留包含了 misalignment 残留以及非线性残留,神经网络都可以比较好地去学习。
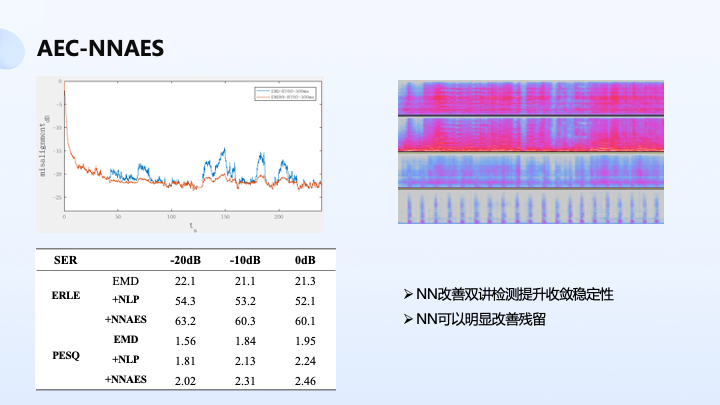
上图是我们的一些测试结果。线性滤波基本达到 20db 的消除量,ERLE 达到 20db 的消除量,加了一些传统非线性滤波可以达到 50db,加上神经网络可以再提升 10 个 db 的抑制量。
另外是语音感知质量,它可以比较好地评估双讲情况下的语音性能,大家可以看一下本身有了神经网络的加持,对双讲性能改善还是比较明显的,PESQ 在 20db 有 0.2 左右的提升。
降噪是希望从被污染麦克风信号中把噪声处理掉,得到 clean speech。目前行业内比较主流的方案是基于 Wiener 框架,统计噪声统计量或者是目标声音统计量。接下来给大家详细介绍一下具体怎么操作的。

单通道降噪相对比较成熟了。其中非常经典的一个是基于 OMSA 算法,采用 MCRA 去估噪声,采用幅度谱上的操作估噪声的运动函数,用来去估计先验信噪比、后验信噪比、语音存在概率,再采用 Wiener 方案做一些 Wiener 滤波,得到目标信号。它的建模只是用到了幅度谱,相位谱直接采用含噪相位。
单通道降噪本身在神经网络中应用比较多,有的是纯神经网络,比如说 wav to wav 这种,还有谱上的操作,有的是估计mask,有的直接估计谱,包括相位谱。
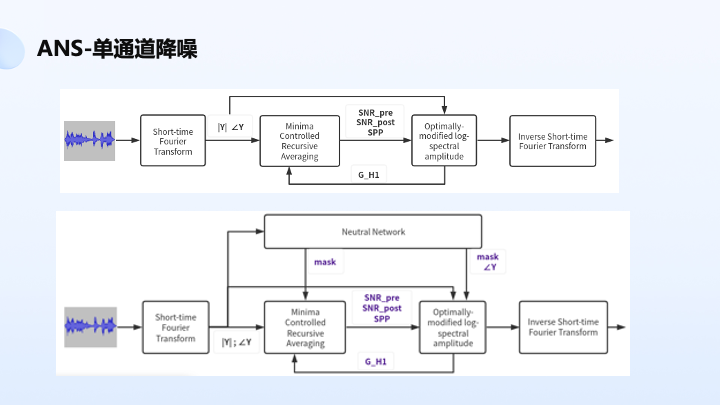
现在主要在研究如何结合传统去做,特别是受限的神经网络,当模型不是特别强的时候,比如说 size 比较小、算力比较小的情况是否能发挥一定的作用,在没有特别完美的情况下结合着传统去做还能得到不错的效果。它的思想是可以用神经网络去调整 MCRA 节奏,用来得到幅度谱以及得到相位谱 mask,用来和传统 OMLSA 结合得到语音降噪的处理。
多通道降噪比单通道降噪可做的空间大的多了,因为麦克风多了,有了额外的信息,比如说相位差信息、幅度差信息都被有效地利用起来,多通道信号处理比较典型的是播出形成方案,简单地思想是通过采用麦克风阵列空间滤波方案实现对目标声音的提取,抑制非目标方向的声音。
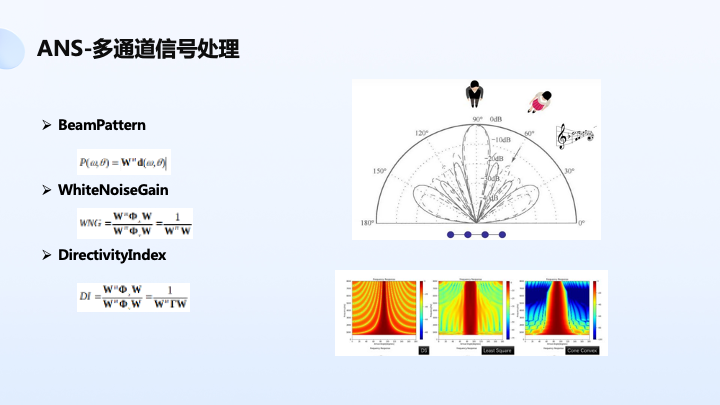
如上图显示,我们能有效地抑制 60 度人声干扰,而保持 90 度人目标声音不失真。其中比较重要指标是 BeamPattern,以及白噪声增益和指向性因子。白噪声增益描述系统鲁棒性,如果空间滤波器范数比较大的话,它会带来系统不稳定。因为我们知道麦克风是电学器件,会有白噪声存在,如果范数特别大的话,会把电路底噪带大,另外指向性因子描述指向性效果,如果指向性越好,说明对旁边声音抑制能力越强。
另外一块是比较典型 MVDR ,也就是最小失真响应。它是自适应波束形成的方案,它的思想是让输出信号能量最小,但保证目标方向不失真,典型约束准则是在最下面两行,保证 输出 最小同时保证目标方向完全无失真。

经过数学推导,一般情况下会得到比较经典的公式,可以获得噪声协方差矩阵以及导向矢量,可以得到空间滤波器系数,用来对麦克风阵列进行滤波,实现刚才提到的降噪作用,比较好地保留目标声音,比较好地去除噪声。
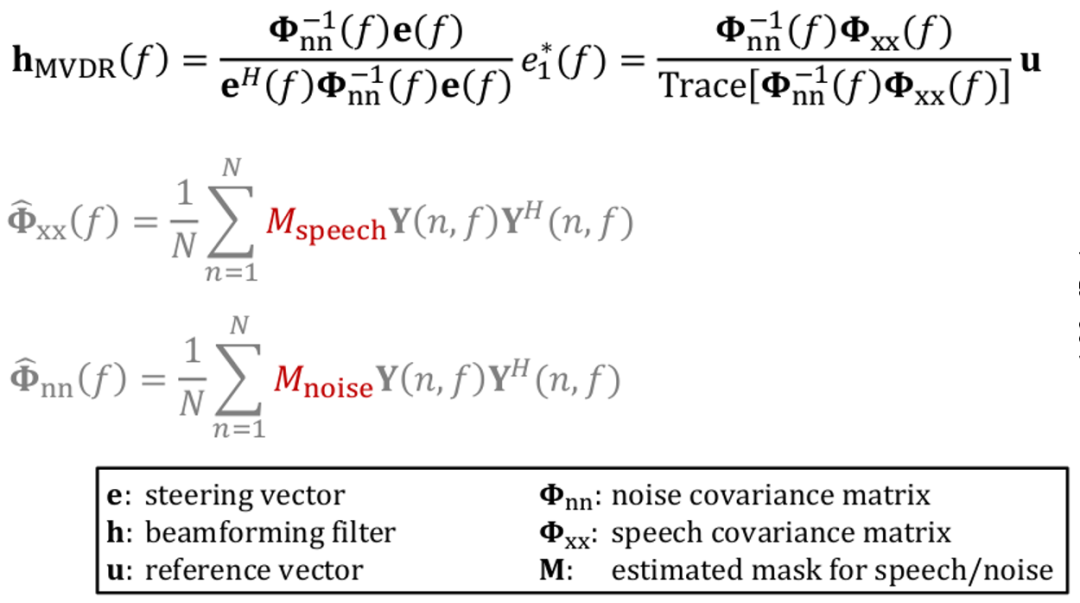
而如何去估噪声协方差矩阵以及导向矢量,是需要做的事情。一般情况下神经网络在这块有操作空间了,它可以比较好地去判断是不是语音,比较好去估噪声协方差矩阵,一般情况下上图中标红的 Mnoise 主流会用神经网络去做。
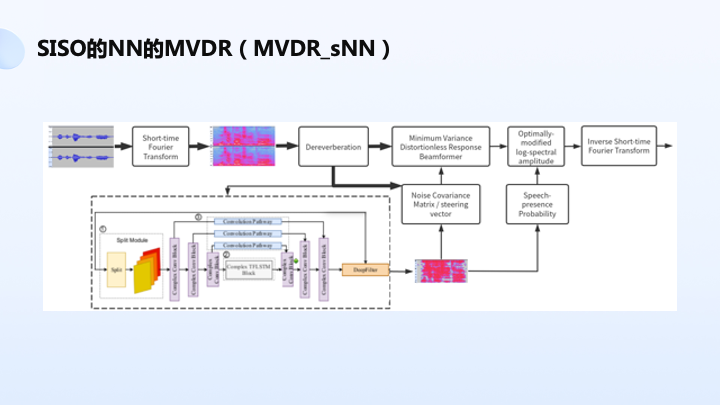
如上图所示,双路输入麦克风阵列音频经过 FFT 得到频率信号,经过去回响,抽取其中的一路送到神经网络,典型的 unet 结构,得到一个 mask,mask 以后可以估计 MVDR 其中两个关键统计量,噪声矩阵和导向矢量,用来得到 MVDR 滤波器系数,后面再接一个传统 OMLSA 降噪算法,神经网络语音存在概率可以帮助 OMLSA 做一些辅助处理,提升整个系统的性能。
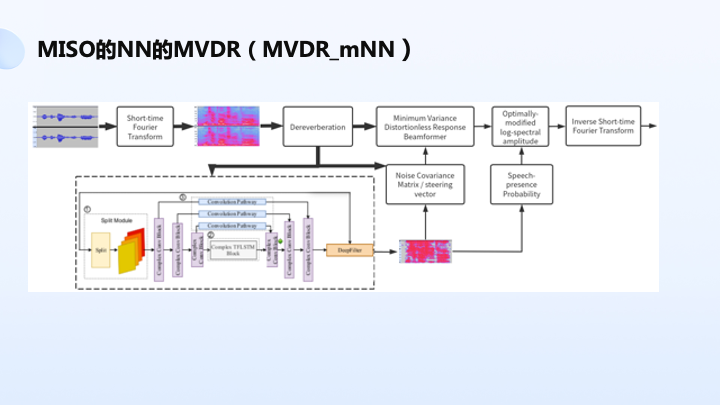
另一种方案,刚才讲到如果输入多路音频,因为去混响后的音频包含了原始阵列的信息,它可以有效地反映阵列的空间特性,所以说它在送到神经网络里面输入的是两路音频,可以比较好地去学习空间信息,比前一个方案的好处是空间信息可以拿来用,可以比较好地去估噪声语音存在概率,从而得到 MVDR 滤波器,估计效果会更准一点。
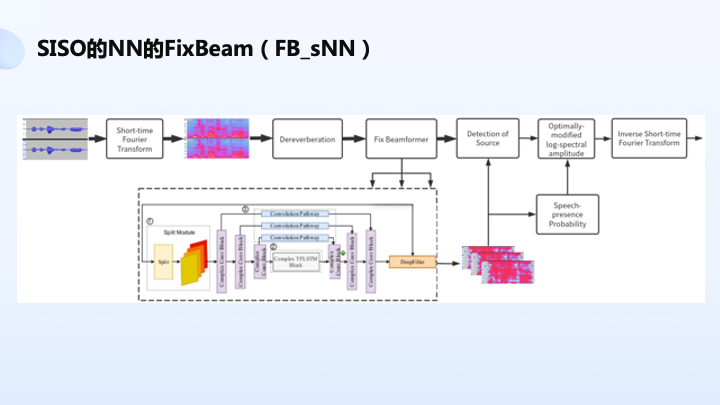
另外一个方案可以采用固定约束的方案,把空间 0-180 度分成三个方向或五个方向,分别对五个方向进行固定波束的设计,分别对每个方向的声音送到神经网络,得到每个方向本身语音存在概率,再决策每个方向上哪个目标是真说话概率最大,选取这个方向的声音用来做后面降噪处理,这也是一个典型的处理方案。
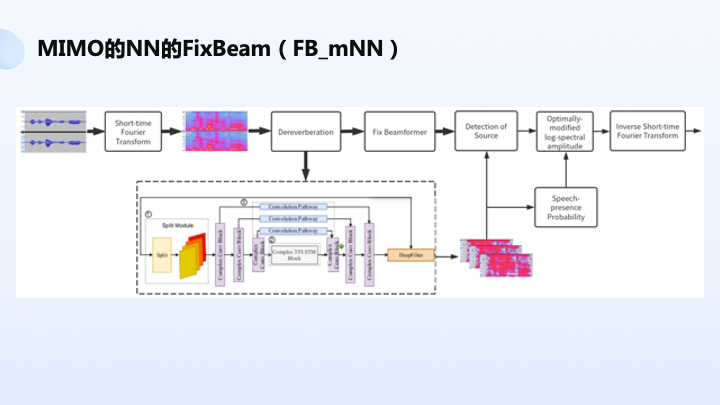
同样还有多输出的方案,输入的是两路去方向的音频信号,输出的是带方向的 mask,本身神经网络有能力估方位 mask,而不是估语音的 mask。我们去估三个方向或五个方向的 mask,从而用来去决策哪个方向是目标声音,从而比较好地获得方向语音存在概率,从而得到更好的估计,得到更好的降噪处理。
我要提一下,本身这个链路包含了去混响、固定波束设计和神经网络 mask 估计,其中固定波束设计是固定方向的波束设计,可以采用自适应的方案,这时候神经网络本身也能对整个学习过程做一些指导。
另外我们知道去混响本来会受一些噪声的干扰,因为解决的是卷积噪声,如果有加性噪声会对去混响性能大打折扣,本身波束出来的声音或者神经网络的声音可以有效对去混响做一些引导,比较好地改善本身去混响的性能,这块工作我相信很多团队都在做,也有一些比较好的结果。但这时候会带来一些问题,整个链路会变的相对来说复杂一点,因为前后有相互的耦合。
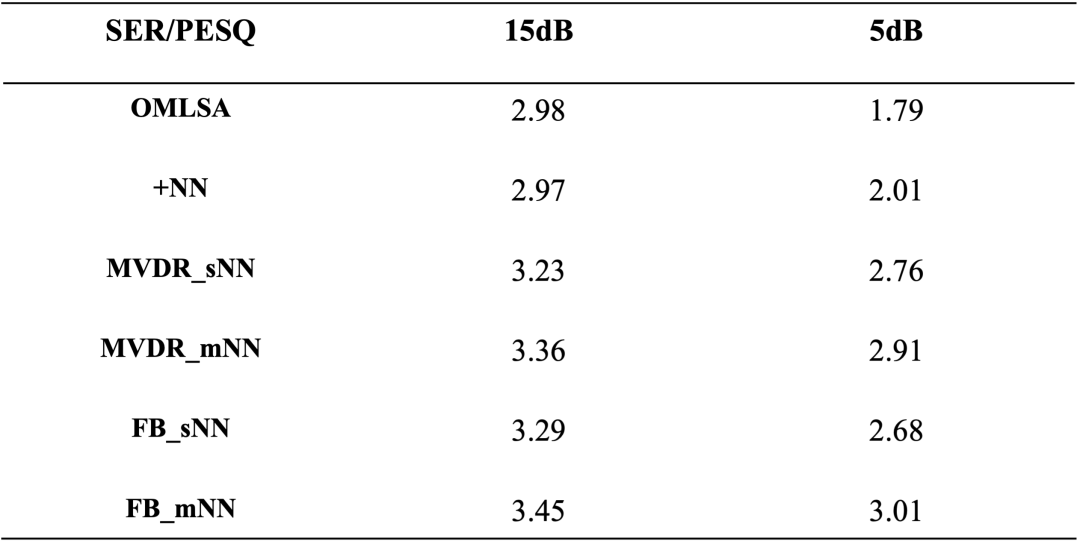
上图是 ANS 算法方案的对比。
我们可以看一下,上面两个是单通道,本身 PESQ 不太理想,但有了麦克风阵列的加持,它的提升还是比较明显的,因为它带来了一些可能,包括去混响、降低失真的可能性。
多输入神经网络还是比单输入神经网络有一些优势,因为单输入神经网络学到的是语音和噪声谱之间的信息,而有了多输入神经网络除了噪声谱和语音谱之间的不同,还有麦克风拓谱之间的关系,可以去学习,去更好地估计承接量。在 15db 情况下,平均有 0.1 左右 PESQ 的提升,在 5db 情况下提升的更多一点。
接下来给大家介绍一下我们这边的产品方案。

我们在做一款会议级的麦克风全向麦,配合着摄像头和转写一体机可以有效地解决大型会议室的沟通问题。这个方案中采用了 12 颗麦克风加神经网络降噪的技术,可以支持 5 台的集联,可以比较好地覆盖面积比较大的会议室,比较清晰的识取整个会议室的声音。
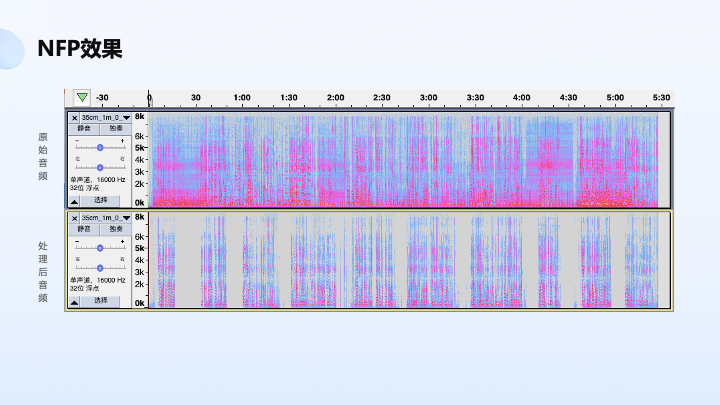
另外一个我们做比较有意思是 NFP 方案,解决的是可以有效地去除说话目标区域以外的声音,比如扇形区以外的声音,左面、右面和后面的声音,主要面向的是个人办公产品,可以有效去除嘈杂环境下的声音。
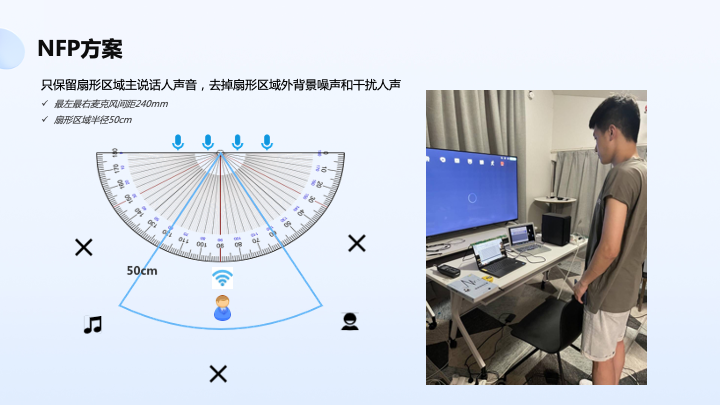
下图是原始音频和处理后音频,信噪比改善还是比较明显的。
另外我们还做了多模态的方案,如下图所示。多模态方案是说除了刚才讲到音频链路,还有了视频加持,比如说有视频人方位的加持,有了唇动的加持,可以有效地指导整个音频链路处理准确性。比如说精确人的方位信息,以及唇动 DOA 信息、唇动 VAD 信息,可以用来指导波束形成和神经网络的算法处理。
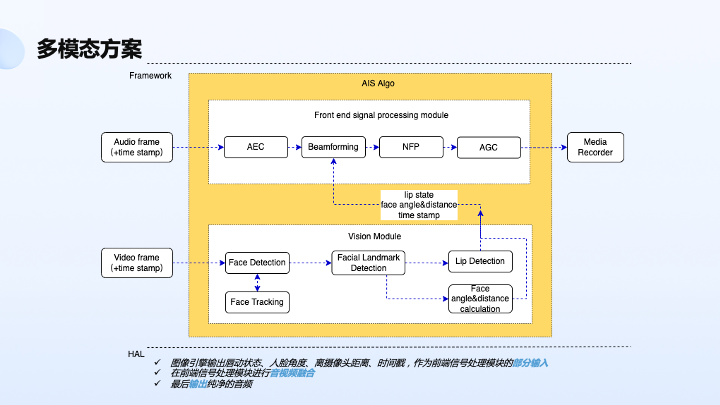
反过来,因为音频本身有 DOA 估计,相对来说是稍微粗糙一点的 DOA 估计,可以进行视频传输,让摄像头进行转动,因为摄像头覆盖角度毕竟还是受限的,可以用来辅助摄像头转动。
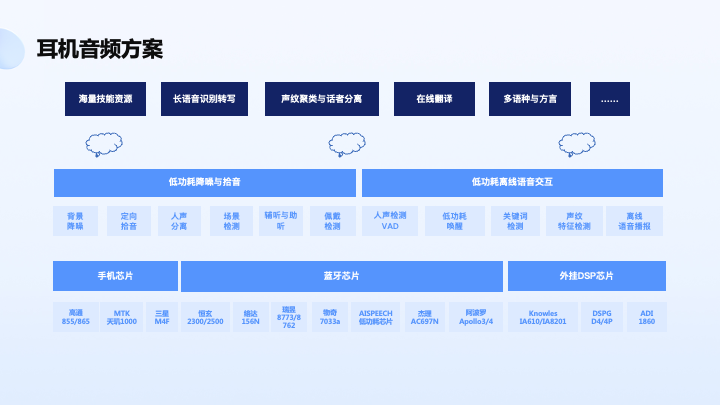
上图是我们做的耳机音频方案。耳机里面临着场景比较复杂的问题,而且设计比较难,包括芯片算力比较受限,我们除了降噪分离还做了场景检测,助听以及辅听的功能,以及基于麦克风佩戴检测、离散性的语音交互,比如语音唤醒之类的解决方案。
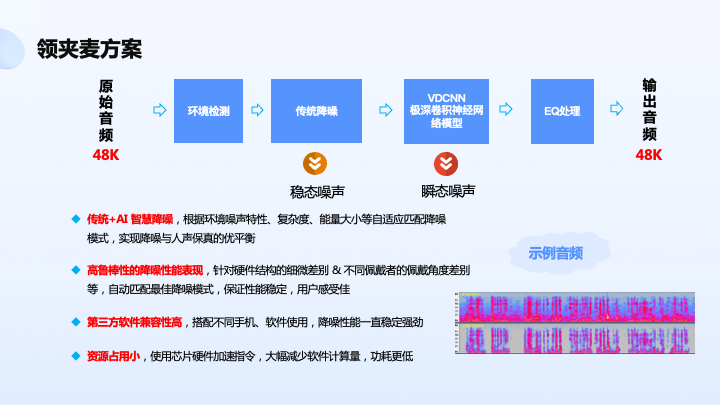
因为最近直播比较火,我们还做了领夹麦 48K 高清采样的方案,可以用来适配不同主播的需求,比如一些稳态噪声和顺带噪声抑制可以有不同降噪模式,因为有的主播希望只收取人的声音,另外一些主播希望把环境噪声也收进去,这样可以做到用户本身可配可选。
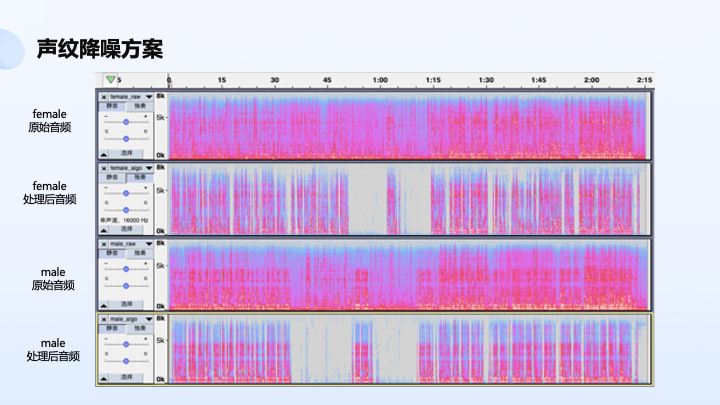
上图则是我们做的声纹降噪方案。声纹降噪是基于声纹信息对目标声音进行增强,降除环境噪声和非目标声音,它的机理是希望通过语音注册能比较好地实现声音保留,剔除非目标人的声音,这时候一般采用的是神经网络处理技术,主要是通过声纹的做本身增强。
我们尝试结合着麦克风阵列做,可以实现更好的效果,用拓谱信息 + 声纹信息联合进行优化。这个事例大家可以看一下,本身信噪比比较低,经过处理以后还是比较好的,还原目标声音的人声。
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
我正在使用active_admin,我在Rails3应用程序的应用程序中有一个目录管理,其中包含模型和页面的声明。时不时地我也有一个类,当那个类有一个常量时,就像这样:classFooBAR="bar"end然后,我在每个必须在我的Rails应用程序中重新加载一些代码的请求中收到此警告:/Users/pupeno/helloworld/app/admin/billing.rb:12:warning:alreadyinitializedconstantBAR知道发生了什么以及如何避免这些警告吗? 最佳答案 在纯Ruby中:classA