时光荏苒,这个故事发生在4年前,那时候我头发可真厚,坐地铁也不用戴口罩。
友圈一位要做毕设的小姐姐在求助postman怎么用,我就帮她解答了一下。
我知道她并非计算机相关专业,所以很奇怪为什么要用postman。
原来她的毕设是要基于微博上最近10年关于房价的话题数据,来做分析,做未来房价的走势预测,训练模型。
她经过一番调研之后决定用某平台的「语言处理技术」,实现基础数据的语义分析,即:情感极性分类结果,0负向、1中性、2正向。

官方提供的是基于postman的演示demo,虽然对咱们专业人士来讲很简答,但是对学文科的小姐姐还是有一定门槛的。
我教会小姐姐怎么用postman之后,问了她一个问题:
你虽然知道了postman怎么用,能查询每条数据的语义分析结果。
但是微博关于房价的数据有几十万条,你总不能用postman一条一条来操作吧!?
小姐姐蒙了

我告诉小姐姐不用担心,可以用编程轻松解决,比如Go、Python、Java、PHP都是可以的。
但是沟通下来发现小姐姐对编程并不感冒,虽然之前有学过,但是短时间内实现需求恐怕很困难。
是时候展示真正的技术了:
于是,我帮她搭建了基于某平台AI开放平台的批量语义识别的系统,也算进行了某平台【语言处理技术】的开箱测试。
考虑到小姐姐并不是很懂编程,所以要以最简单的方式来实现需求:
尽量减少代码,能使用工具软件的尽量使用工具软件。
开发语言使用简单易学的PHP
数据库工具使用开箱即用的Navicat
开发环境使用一键安装工具「LNMP一键安装包」
(别问我为啥没用Go,毕竟这个故事起码3年前,哈哈哈)

说干就干,马上开始搞
小姐姐已经通过某宝拿到了20W+关于房价的微博数据,现在需要做的就是基于语义分析来获得这20W+数据集对房价走势的判断。
小姐姐也是思路广啊~

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jiIMBTll-1670227296931)(https://files.mdnice.com/user/36414/190edd7d-87c7-44f1-9e7d-eade1aab115e.png)]
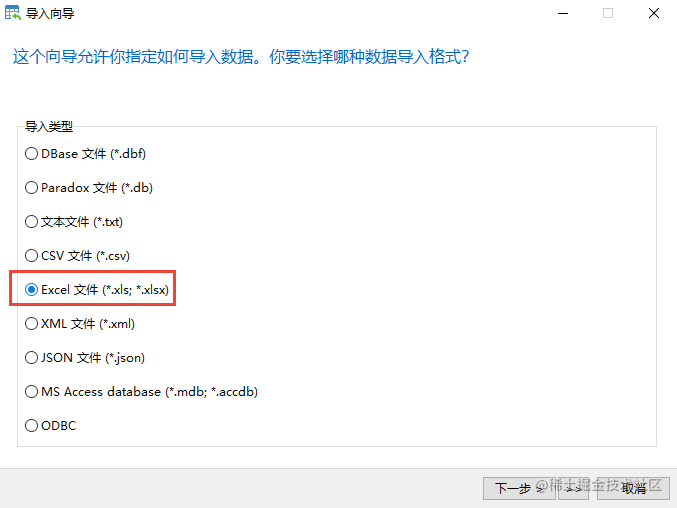
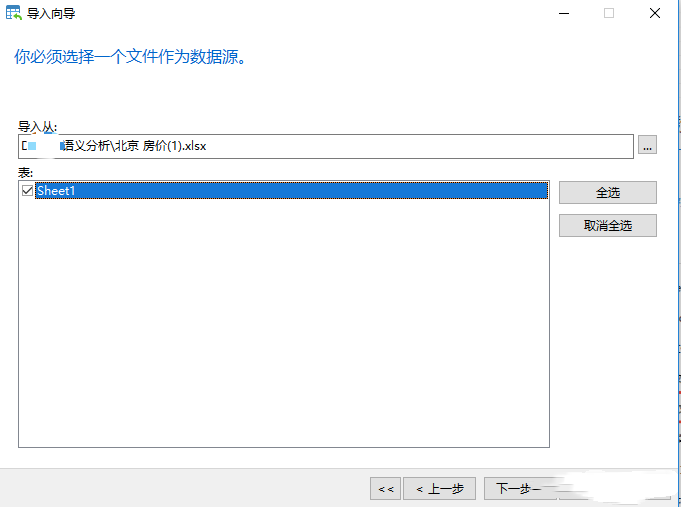
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iSHpg3OZ-1670227296937)(https://files.mdnice.com/user/36414/73de9796-256a-4f4d-ae5f-1757984feb6b.png)]
注意:要做好表格源字段和目标字段的匹配
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qK46T0MF-1670227296939)(https://files.mdnice.com/user/36414/cf553546-c652-48ca-ac5c-c87c352eb9ee.png)]
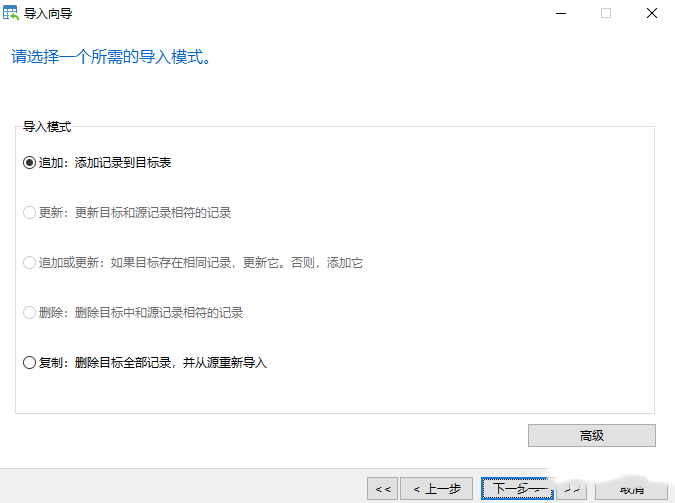
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-67j1lf05-1670227296943)(https://files.mdnice.com/user/36414/121ee80b-68f1-4bec-b489-ee72a3743d69.png)]
考虑到小姐姐最终目的是训练模型,而非学习编程,所以搭建开发环境就怎么简单怎么来了。
所以我就推荐她使用「LNMP一键安装包」,10几分钟左右就把LNMP环境搭建好了
mysql语句中 liuXX 是数据库名 semantic_analysis是表名
使用do while循环,批量循环请求某平台AI语义分析接口,查询positive_prob=0的数据(即未进行语义分析的数据)。
当查询不到数据时,说明所有数据已经成功请求某平台语义分析接口,且将返回结果更新到数据表中。
每次查询之后都会休眠1秒,因为免费版的某平台语义分析接口有QPS限制,避免出现无效请求
查询条件是 positive_prob=0(代表本条数据未请求某平台接口)
查询排序: 根据id倒序
查询翻页: 每次查询10条
异常处理:当某平台返回的error_code为282131时,表示文本内容过长,超过了某平台语义分析的字数限制。
mysql会将不符合某平台语义分析的数据源删除,不再重复请求
输出返回结果,方便查询信息,定位问题
当某平台的返回结果 positive_prob 字段的值不为0时,表示语义分析成功,已返回结果
将返回的结果更新到mysql数据表中
文件名:batchProcessing.php
<?php
ini_set('memory_limit', '256M'); //内存管理
include '../include/ConfigLiuxx.php'; //引入数据配置文件
include '../include/Db.php';//引入db数据库
include '../include/Logger.php';//引入log文件
include '../include/Request.php';//引入 http请求文件
define('Index_table', 'semantic_analysis'); //设置数据表名 语义分析
$db_liuxx = new Db($db_liuxx); //引入db配置文件
/**
* 某平台语义分析脚本
*/
$access_token = "xxxxxxxxxxx"; //某平台提供的token
$url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token=' . $access_token; //按某平台要求拼接请求url
$limit = 10;
$offset = 0;
do {
$datas = $db_liuxx->get_all('select * from liuxx.semantic_analysis WHERE positive_prob = 0 order by id desc limit ' . $offset . ',' . $limit);
foreach ($datas as $key => $value) {
$id = $value['id'];
$text = $value['text'];
$params = ['text' => $text];
$bodys = json_encode($params);
$response = request_post($url, $bodys);
$res_data = json_decode($response, true);
if ($res_data['error_code'] == 282131) {
$db_liuxx->query('delete from liuxx.semantic_analysis WHERE id = ' . $id);
var_dump($id . ' 文本过长 删除');
}
echo 'id:';
var_dump('某平台返回:');
var_dump($res_data);
$data = [
'positive_prob' => $res_data['items'][0]['positive_prob'],
'confidence' => $res_data['items'][0]['confidence'],
'negative_prob' => $res_data['items'][0]['negative_prob'],
'sentiment' => $res_data['items'][0]['sentiment'],
'ctime' => time(),
];
if ($data['positive_prob']) {
var_dump($data);
//更新条件
$condition = 'id = ' . $id;
$res = $db_liuxx->query('update liuxx.semantic_analysis set positive_prob = ' . $data['positive_prob'] . ', confidence = ' . $data['confidence'] . ', negative_prob = ' . $data['negative_prob'] . ', sentiment = ' . $data['sentiment'] . ' where id = ' . $id);
var_dump($res);
} else {
var_dump('某平台未返回结果');
};
}
sleep(1);
} while (!empty($datas)); //能查到数据就一直循环
?>
/**
* 发起http post请求(REST API), 并获取REST请求的结果
* @param string $url
* @param string $param
* @return - http response body if succeeds, else false.
*/
function request_post($url = '', $param = '')
{
if (empty($url) || empty($param)) {
return false;
}
$postUrl = $url;
$curlPost = $param;
// 初始化curl
$curl = curl_init();
// 抓取指定网页
curl_setopt($curl, CURLOPT_URL, $postUrl);
// 设置header
curl_setopt($curl, CURLOPT_HEADER, 0);
// 要求结果为字符串且输出到屏幕上
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);
// post提交方式
curl_setopt($curl, CURLOPT_POST, 1);
curl_setopt($curl, CURLOPT_POSTFIELDS, $curlPost);
// 运行curl
$data = curl_exec($curl);
curl_close($curl);
return $data;
}
nohup:表示脚本生成的log日志和打印信息输出到nohup.log文件中
&:表示脚本后台运行
nohup php batchProcessing.php &
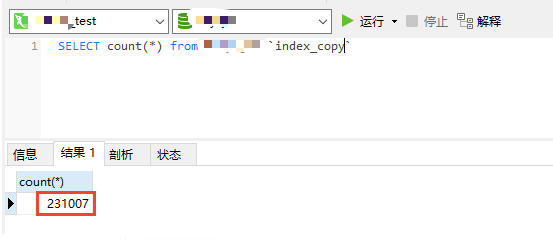
脚本运行完毕后,即可在mysql中查询到经某平台语义分析接口处理过的数据,结果示例如下图:

通过Navcat工具,小姐姐就可以方便的将mysql数据结果导出到Excel。
以上操作,花了大概2个小时,成就感爆棚。

当年的总结是:编程真的太有用了,帮了小姐姐大忙,收到了一大波赞,这种精神鼓励和涨工资差不多吧,哈哈哈。
今天的总结是:不管PHP还是Java、GO,更不用管什么框架。
“黑猫白猫,能抓耗子才是好猫”,“这个语言好,那个框架土,能帮你解决问题才是好工具。”

这篇文章也算回应一下最近有意和我讨论语言高下、框架优劣的朋友。
我确实无意在这类事情上花时间。
想起了“霍元甲”说的一句话:天下武功没有高下之分,只是习武之人有强弱之别。
感谢我群大佬,真是卧虎藏龙。
我们搞了一个有门槛的学编程专属群,大家一起学习打卡,互相督促,欢迎加入我们:
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
