之前一致以为索引就是简单的在原表的数据上加了一些编号,让查询更加快捷。后来发现里面还有更深的知识。
索引用于快速查找具有特定列值的行。如果没有索引,MySQL 必须从第一行开始,然后通读整个表以找到相关行。表数据越多,成本就越高。如果表有相关列的索引,MySQL 可以快速确定要在数据文件中间查找的位置,而无需查看所有数据。这比顺序读取每一行要快得多。
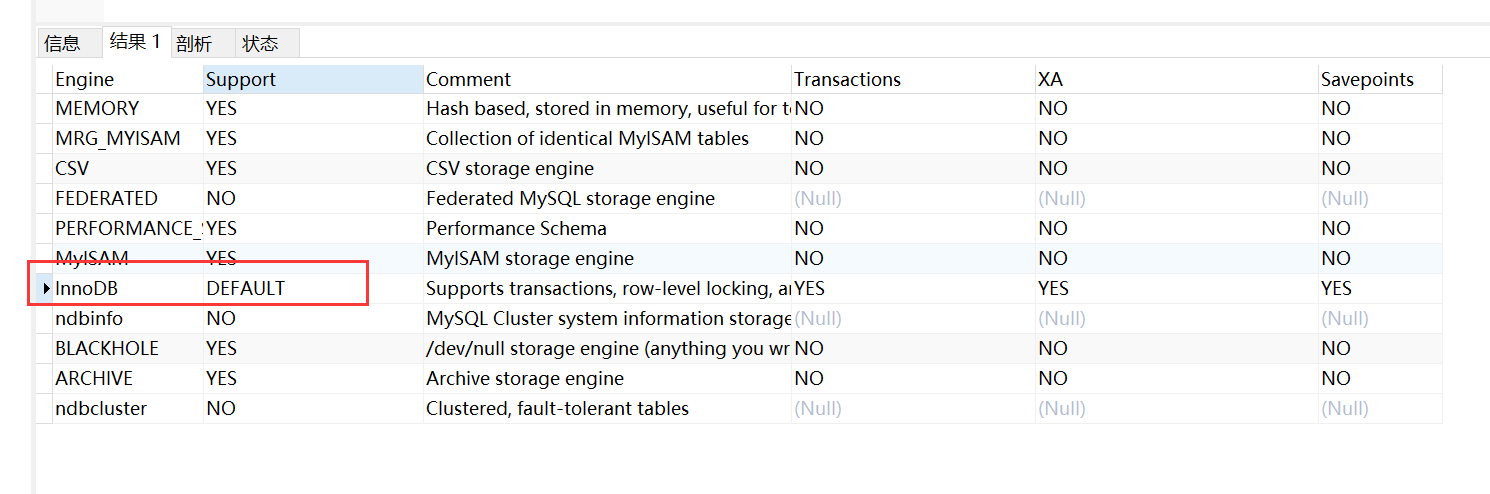
自从MySQL5.5版本之后,MySQL的默认存储引擎就变成了InnoDB。
-- 查看当前数据库支持的搜素引擎
show ENGINES;
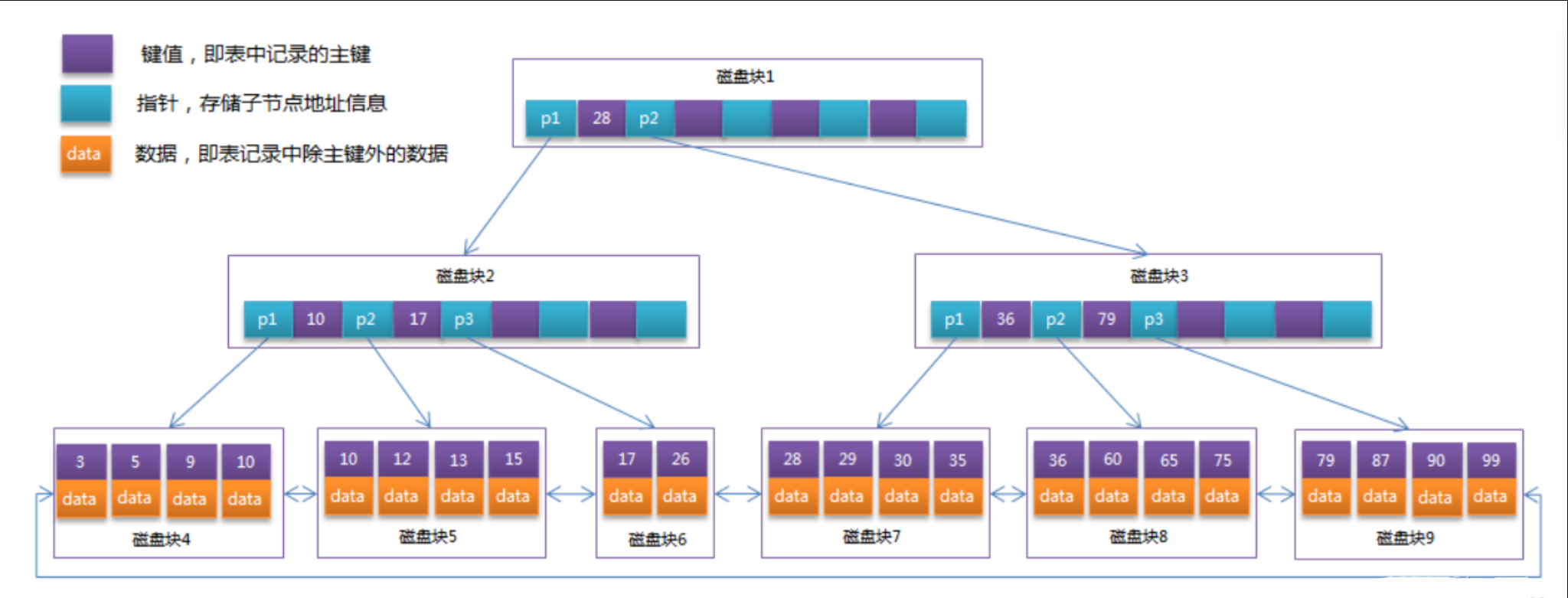
当我们创建一个表时,InnoDB引擎会根据主键给我们创建一个聚簇索引树。
会形成一个只有叶子节【最下面的节点】点存储数据的B+ tree。
除了叶子节点,其余的节点存储的是主键的值以及指向下一个节点的指针信息。
先看官方说明:


简而言之:
InnoDB默认会给创建一个根据主键id的聚簇索引的B+ tree,如果没有主键就根据下面的规则:
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了主键,则主键就是聚集索引;
(2)如果表没有定义主键,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
后面我们再创建的索引统一被称之为二级索引(非主键索引、辅助索引),当然也会创建一个B+ tree。
只不过相较于聚簇索引的B+ tree来说,二级索引叶子节点上存储的为数据为主键的值,聚簇索引的叶子节点上存储的为真正的一条数据。
好处:
避免了当数据发生修改的时候,大量B+ tree跟着修改。
那二级索引被触发后,是怎么查询到数据的?
答:
这涉及到了两个概念:
回表
通过二级索引(辅助索引)树查询索引数据,然后再通过聚集索引树查询完整数据的过程称为回表。
覆盖
select字段已经包含在用到的索引中的时候称为覆盖索引。
比如说:我们创建了一个关于name字段的索引,当我们查询name的时候就会触发覆盖索引
可以通过EXPLAIN关键字查看时候出发了覆盖:
执行计划中出现Using index 字样,表示用到了覆盖索引,没有产生回表的操作。
-- 创建一个组合索引
create index idx_name_sex on t_user(name,sex);
-- 触发了覆盖索引
EXPLAIN SELECT name,sex from t_user where name = 'name4999008'
-- 触发了覆盖索引
EXPLAIN SELECT name from t_user where name = 'name4999008' and sex = '男'
-- 没有触发覆盖索引
EXPLAIN SELECT * from t_user where name = 'name4999008'

?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5
我发现自己需要这个。假设cart是一个包含用户列表的模型。defindex_of_itemcart.users.each_with_indexdo|u,i|ifu==current_userreturniendend获取此类关联索引的更简单方法是什么? 最佳答案 indexArray上的方法与您的index_of_item方法相同,例如cart.users.index(current_user)返回数组中第一个对象的索引==给obj。如果未找到匹配项,则返回nil。 关于ruby-on-
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A