目录
之前我们初步的讲解了二叉树并且实现了堆这种特殊的二叉树,本次我们将实现链式二叉树的遍历(链式二叉树中非常重要的部分),查找等功能。
附初识二叉树链接:http://t.csdn.cn/pMOia
(1)本文采用的二叉树表示方法
①每一个节点都是一个结构体。
②每一个节点除了存储数据,还存储了自己孩子节点的地址(结构体指针)。
③如果节点没有孩子就指向空。
示意图:
代码:
typedef char BTDataType; typedef struct BinaryTreeNode { //存储左孩子的地址 struct BinaryTreeNode* left; //存储右孩子的地址 struct BinaryTreeNode* right; BTDataType data; }BTNode;
(2)手动建立一颗二叉树
①调用malloc( )函数申请空间,插入数据。
②将节点依次链接。
③因为需要多次申请空间,插入数据,我们把这个部分封装成函数BuyNewNode( )。
代码:
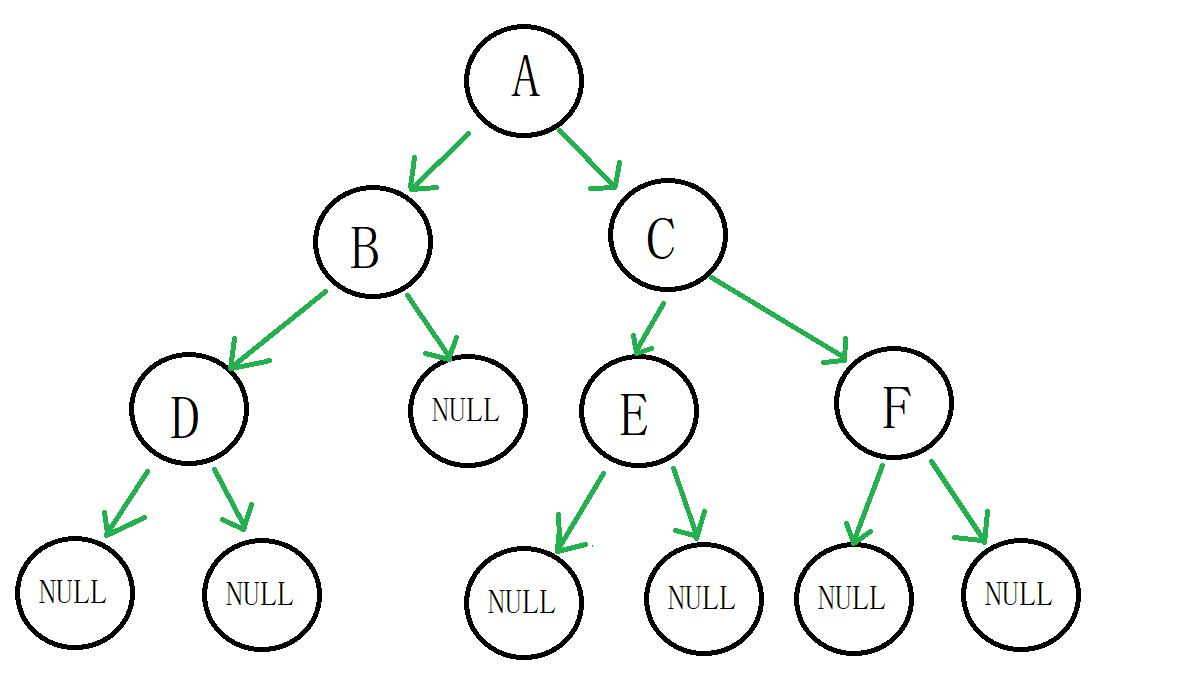
//申请新节点 BTNode* BuyNewNode(BTDataType x) { BTNode* newnode = (BTNode*)malloc(sizeof(BTNode)); if (newnode == NULL) { printf("malloc error\n"); exit(-1); } newnode->data = x; newnode->left = newnode->right = NULL; return newnode; } void test1() { //手动建立一个二叉树 BTNode* nodeA = BuyNewNode('A'); BTNode* nodeB = BuyNewNode('B'); BTNode* nodeC = BuyNewNode('C'); nodeA->left = nodeB; nodeA->right = nodeC; BTNode* nodeD = BuyNewNode('D'); BTNode* nodeE = BuyNewNode('E'); BTNode* nodeF = BuyNewNode('F'); nodeB->left = nodeD; nodeC->left = nodeE; nodeC->right = nodeF; }这个二叉树的图:
(1)二叉树的三种遍历方式
1. 前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点的操作发生在遍历其左右 子树之前。 2. 中序遍历(Inorder Traversal)——访问根结点的操作发生在遍历其左右子树之中 (间)。 3. 后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。 (2)分治思想
分治就是分而治之,大概意思就是将一个看似复杂的问题化成一个个简单的小问题,最后解决问题的思想,也是本文的核心。 好比一个学校要统计学生人数,可以让校长一个个去数,也可以让校长告诉年级主任,主任告诉班主任,班主任告诉宿舍长。 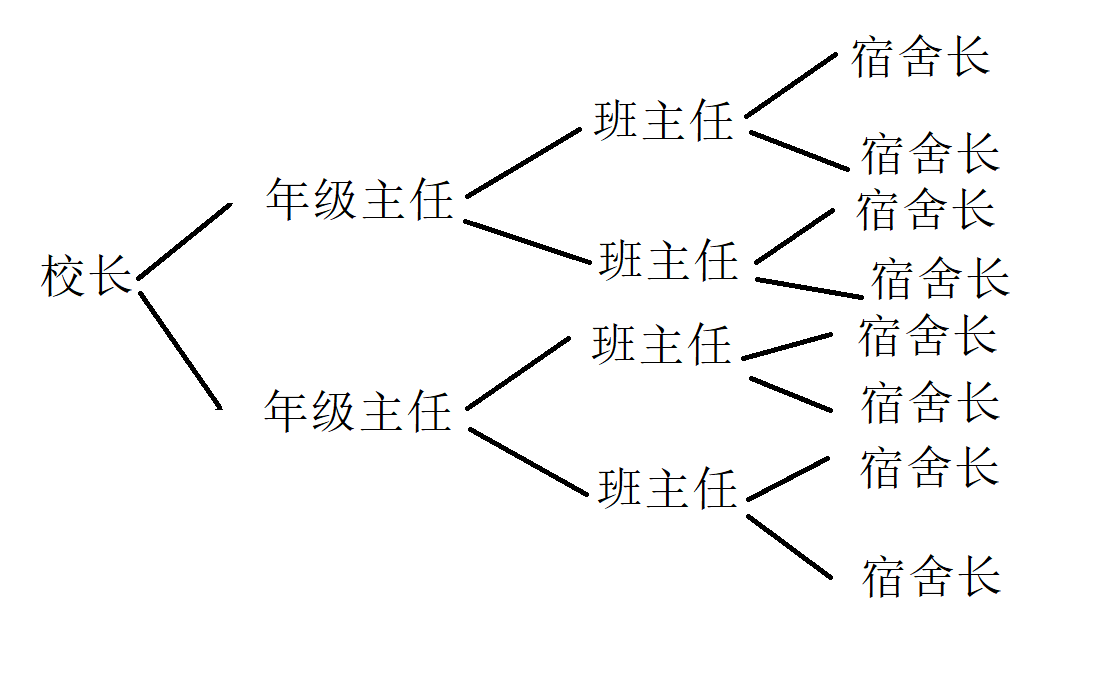
(3)前序遍历
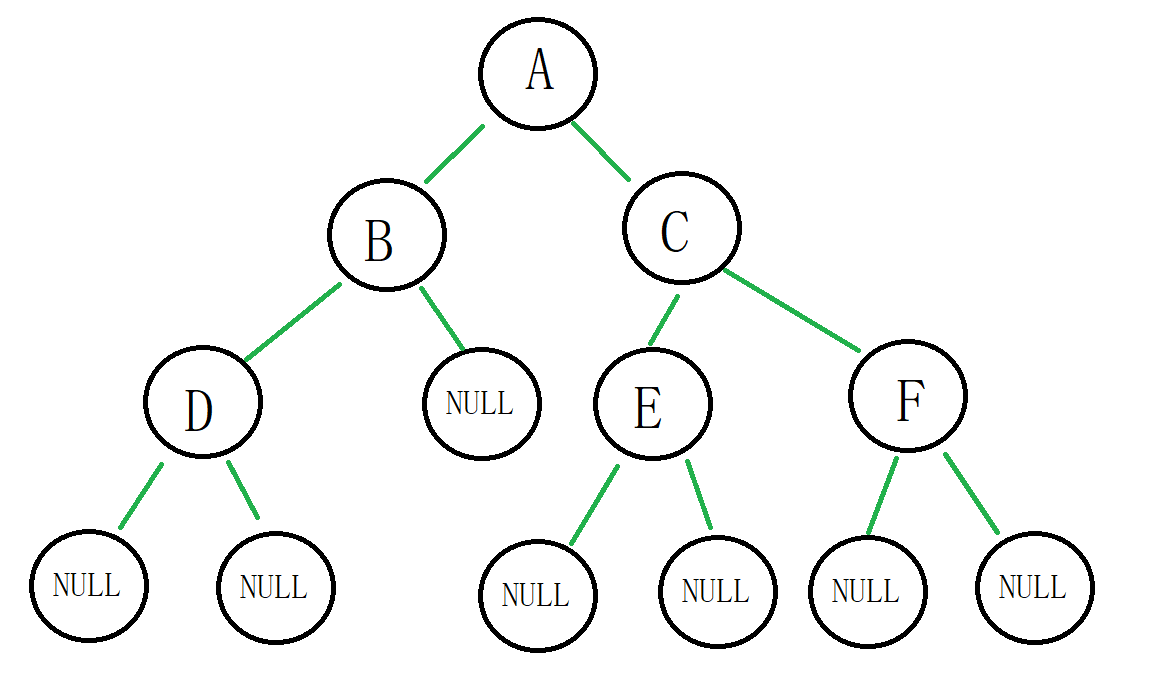
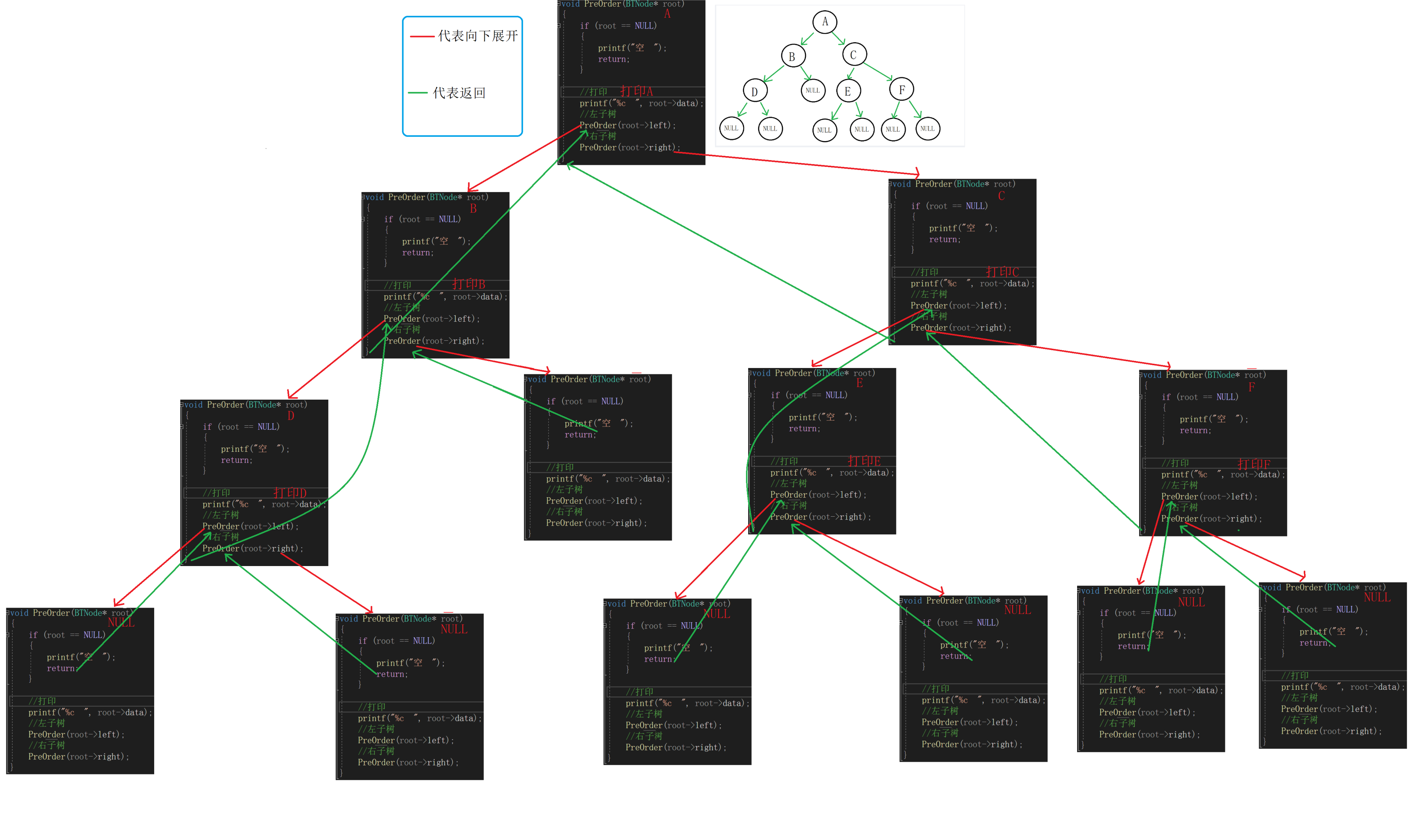
① 我们看这颗二叉树,如果要进行前序遍历。
先打印A,然后遍历A左子树。
打印B,遍历B左子树。
打印D,遍历D左子树。
为空,遍历D右子树。
为空,B的左子树遍历结束,遍历B的右子树。
为空,A的左子树遍历结束,遍历A的右子树。
……………………
②我们不难发现,如果要前序遍历整棵树,
可以转化为先访问A后前序遍历A的左子树和右子树,
前序遍历A的左子树可以转化为先访问B后前序遍历B的左子树和右子树,
前序遍历B的右子树又可以转化为先访问D后前序遍历D的左子树和右子树,这样可以把一个较大的问题转化为一个个极小的问题。
代码:
//前序遍历 void PreOrder(BTNode* root) { if (root == NULL) { printf("空 "); return; } //打印 printf("%c ", root->data); //左子树 PreOrder(root->left); //右子树 PreOrder(root->right); }大家遇到这种递归不理解的话可以画一下递归展开图:
(4)中序遍历
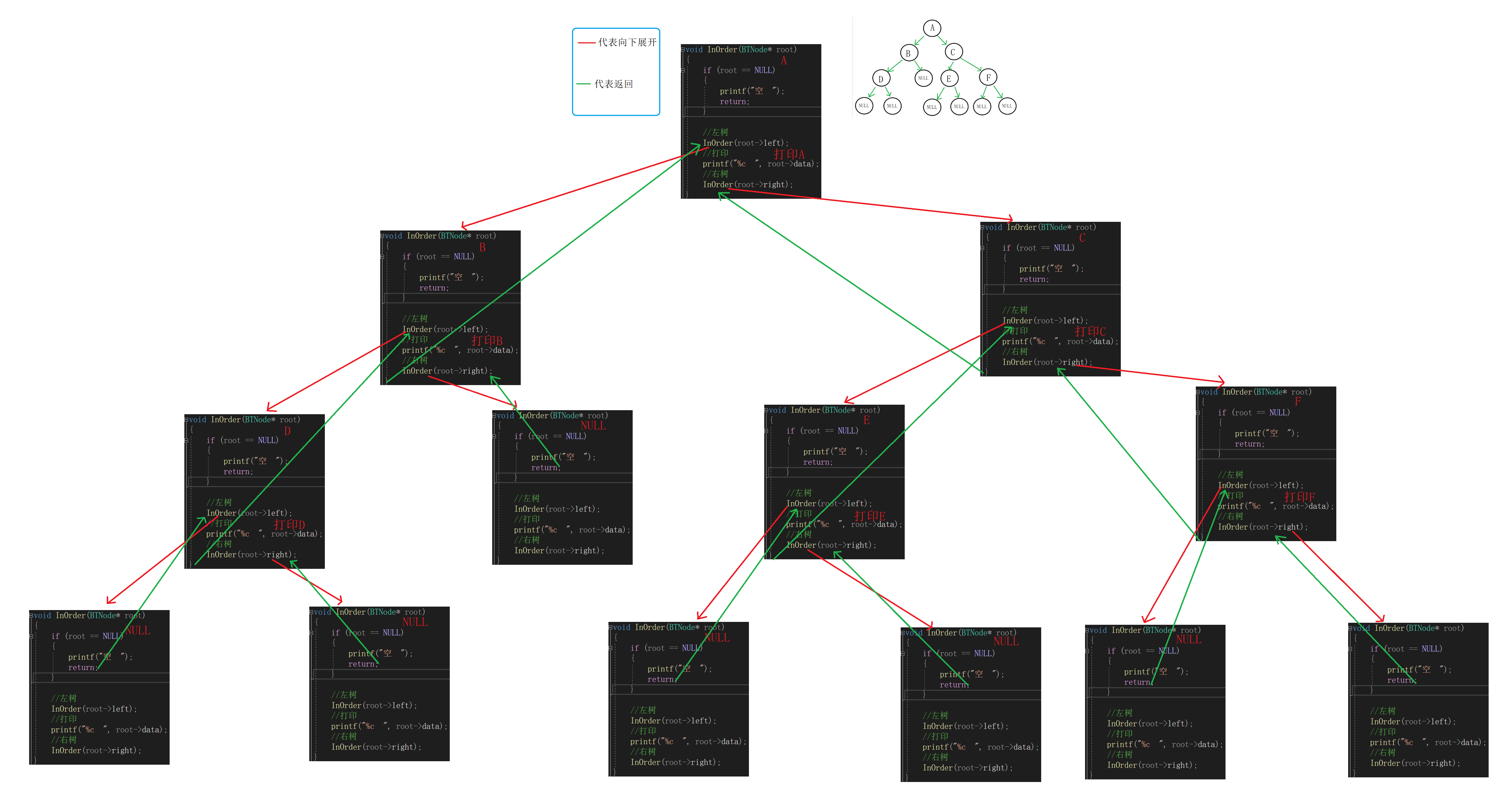
①如果要对这颗二叉树进行中序遍历。
先遍历A左子树。
遍历B左子树。
遍历D左子树。
空,打印D,遍历D右子树。
空,打印B,遍历B右子树。
空,打印A,遍历A右子树。
………………
②中序遍历整颗树,
可以转化为中序遍历A的左子树后访问A,然后中序遍历右子树,
中序遍历A的左子树可以转化为中序遍历B的左子树后访问B,然后中序遍历右子树,
中序遍历B的右子树又可以转化为中序遍历D的左子树后访问D,然后中序遍历右子树,这样可以把一个较大的问题转化为一个个极小的问题。
代码:
//中序遍历 void InOrder(BTNode* root) { if (root == NULL) { printf("空 "); return; } //左树 InOrder(root->left); //打印 printf("%c ", root->data); //右树 InOrder(root->right); }递归展开图:
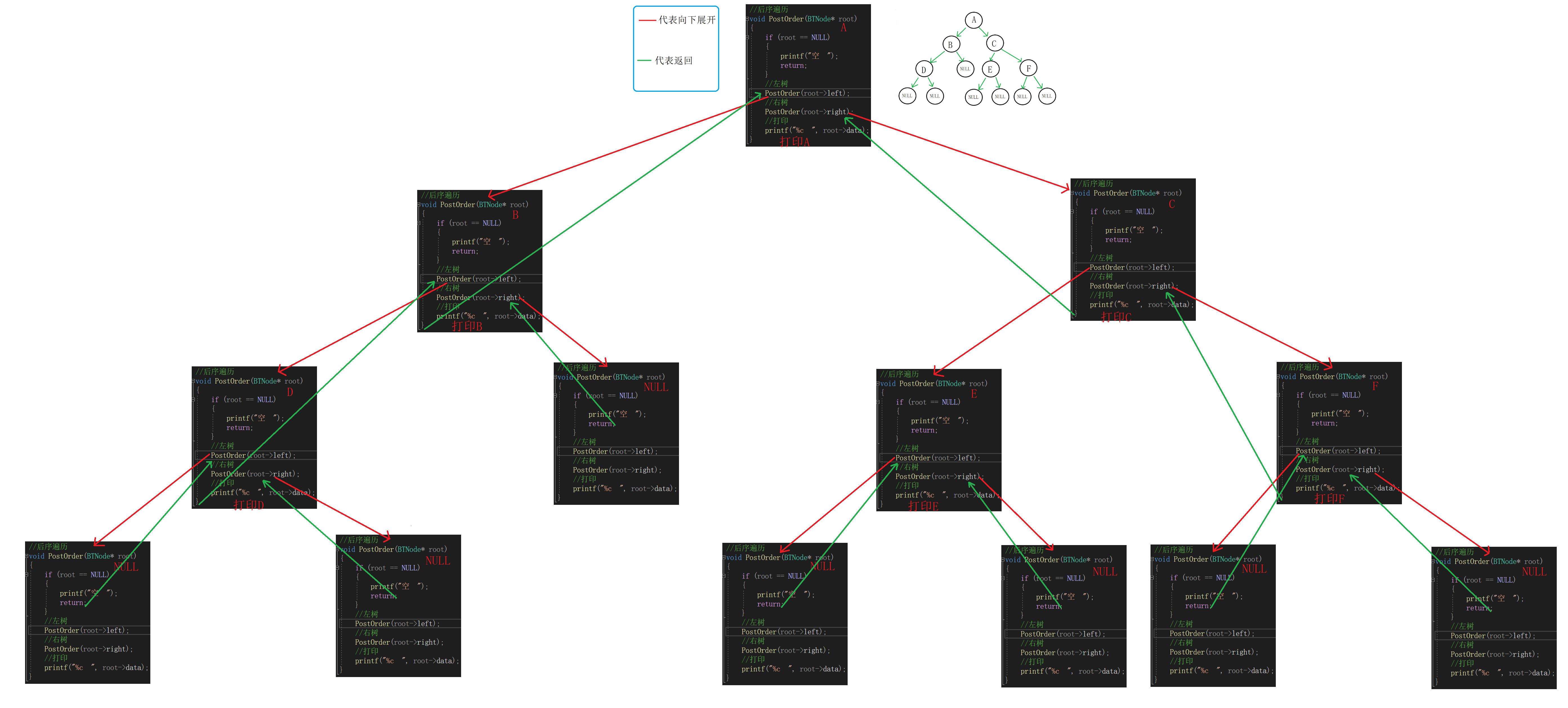
(5)后序遍历
①如果要对这颗二叉树进行后序遍历。
先遍历A左子树。
遍历B左子树。
遍历D左子树。
空,遍历D右子树。
空,打印D,遍历B右子树。
空,打印B,遍历A右子树。
……………………
②后序遍历整颗树,
可以转化为后序遍历A的左子树和右子树后访问A,
后序遍历A的左子树可以转化为后序遍历B的左子树和右子树后访问B,
后序遍历B的右子树又可以转化为后序遍历D的左子树和右子树后访问D,这样可以把一个较大的问题转化为一个个极小的问题。
代码:
//后序遍历 void PostOrder(BTNode* root) { if (root == NULL) { printf("空 "); return; } //左树 PostOrder(root->left); //右树 PostOrder(root->right); //打印 printf("%c ", root->data); }递归展开图:
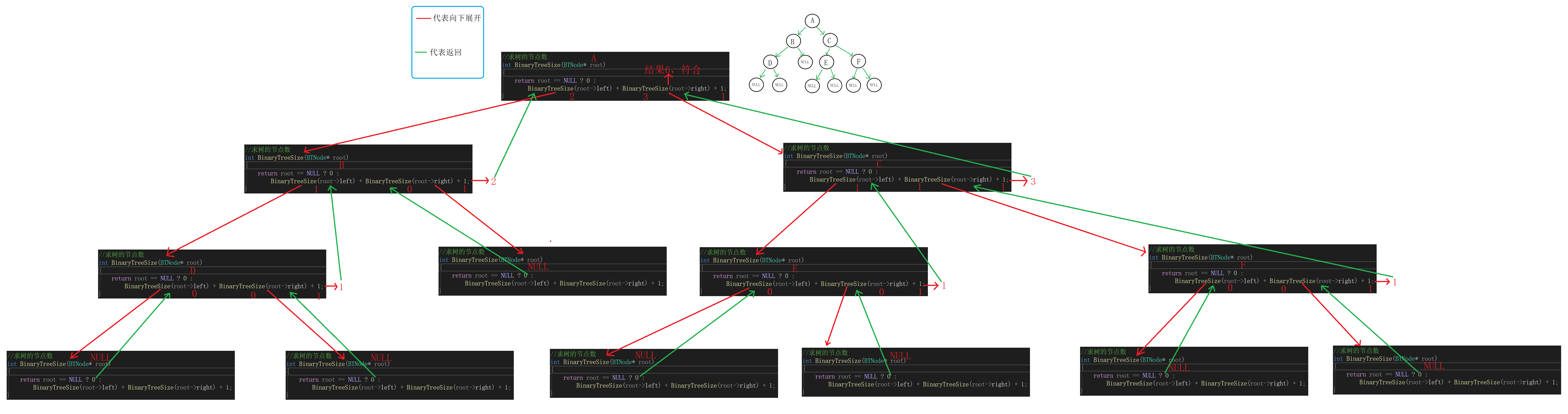
(1)求二叉树节点
①求二叉树的全部节点
思路:
①只有节点地址不为空就算一个节点。
②求整颗树节点,可以转化为A的左子树节点数加A的右子树节点数加1。
A的左子树节点数可以转化为B的左子树节点数加B的右子树节点数加1。
B的左子树节点数可以转化为D的左子树节点数加D的右子树节点数加1。
D的左右子树都是空,B的左子树节点数为1。
………………………………
代码:
//求树的节点数 int BinaryTreeSize(BTNode* root) { /*if (root == NULL) { return 0; } return BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;*/ //更加简洁的写法 return root == NULL ? 0 : BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1; }递归展开图:
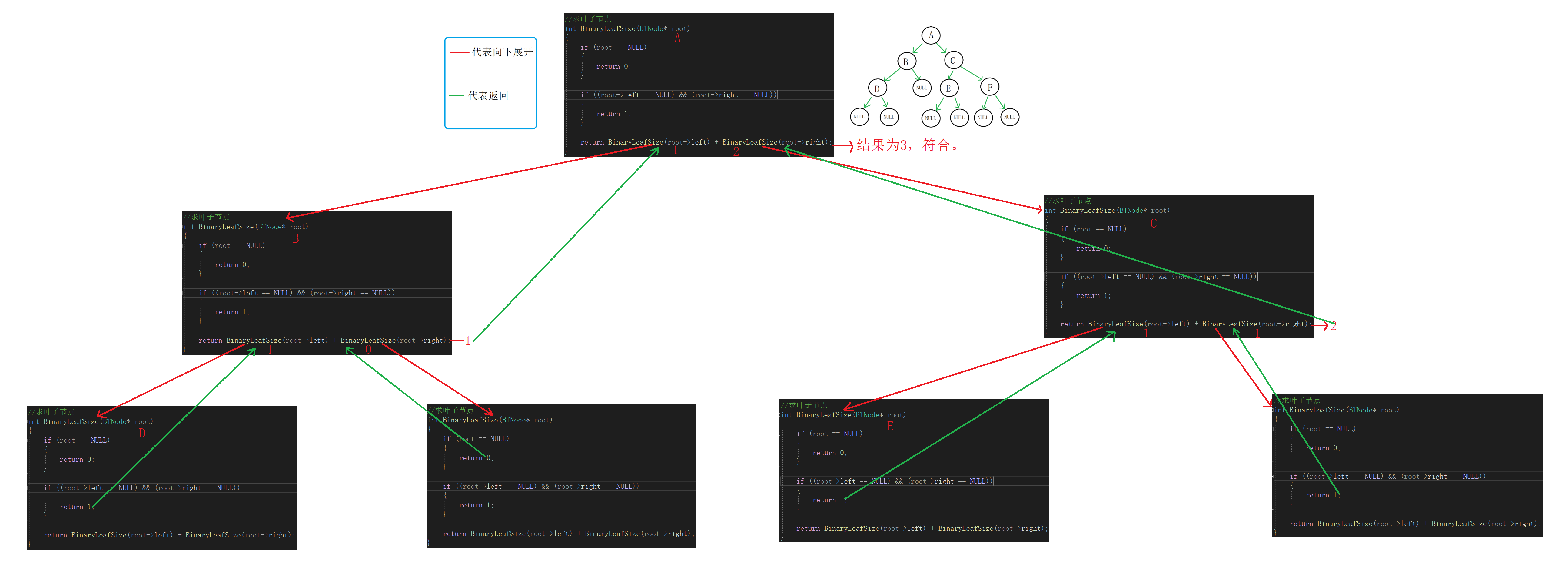
②求二叉树的叶子节点
思路:
①左右孩子都为空的节点算作一个叶子节点。
②求整颗树的叶子节点,可以转化为求A的左子树叶子节点和A的右子树叶子节点。
求A的左子树叶子节点可以转化为求B的左子树叶子节点加B的右子树叶子节点。
D的左右孩子都为空,B的左子树叶子节点为1。
…………………………
代码:
//求叶子节点 int BinaryLeafSize(BTNode* root) { if (root == NULL) { return 0; } if ((root->left == NULL) && (root->right == NULL)) { return 1; } return BinaryLeafSize(root->left) + BinaryLeafSize(root->right); }递归展开图:
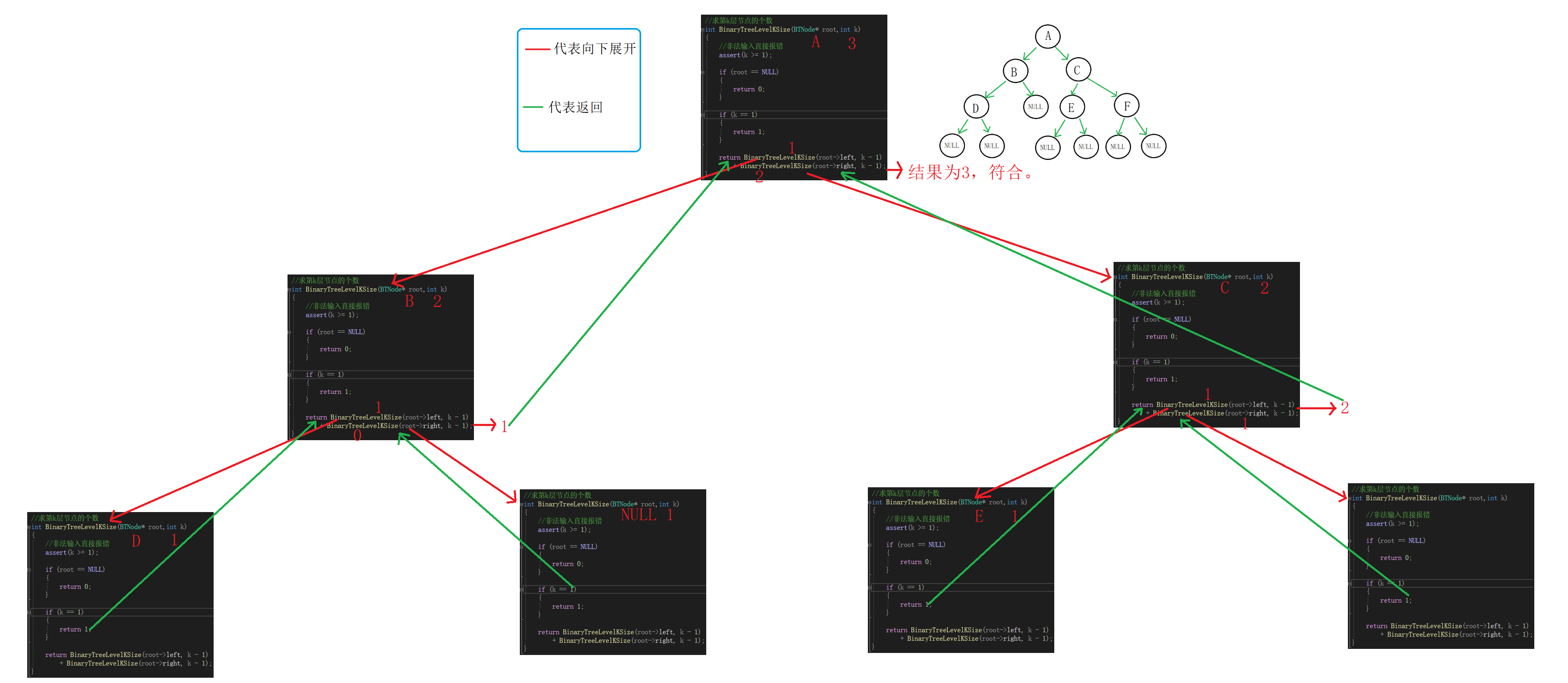
③求二叉树第k层节点的个数
思路:
假设k为3。
①一颗树第一层节点数为1。
②空节点代表节点数为0。
③求整颗树第3层的节点数,可以转化为求A的左子树以及右子树的第2层节点数之和。
求A的左子树第2层节点数,可以转化为求B的左子树以及右子树的第1层节点数之和。
B左子树不为空,层数为1,节点数为1。
B的右子树为空,节点数为0。
………………………………
代码:
//求第k层节点的个数 int BinaryTreeLevelKSize(BTNode* root,int k) { //非法输入直接报错 assert(k >= 1); if (root == NULL) { return 0; } if (k == 1) { return 1; } return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1); }
递归展开图:
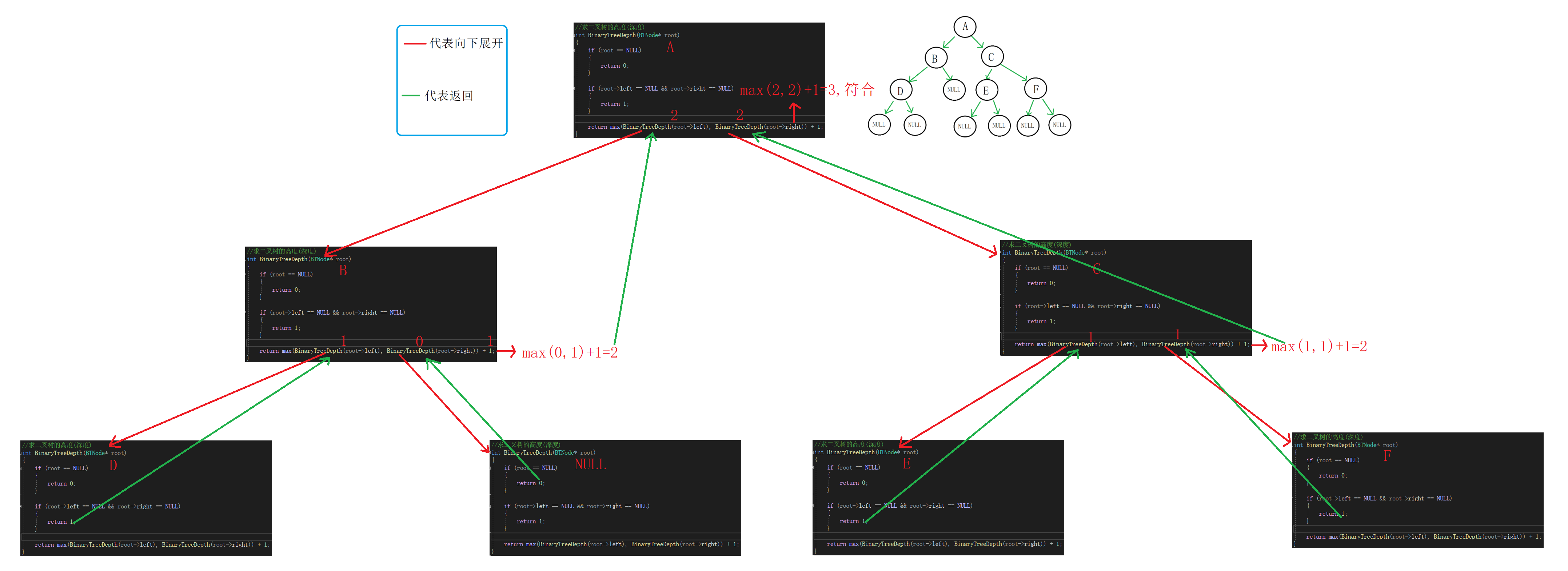
(2)求二叉树的高度(深度)
思路:
①空树高度为0。
②一颗树根节点左右孩子均为空,高度为1。
③一颗树最终的高度为左右子树中深度较大的一方加1。
④求整颗树的高度可以转化为A的左右子树中高度较大的一方加1。
求A的左子树高度可以转化为B的左右子树中高度较大的一方加1。
求B的左子树高度可以转化为D的左右子树中高度较大的一方加1。
D的左右孩子均为空,B的左子树高度为1。
B的右子树为空树,B的右子树高度为0。
取大的一方加1,A的左子树高度为2。
代码:
//求二叉树的高度(深度) int BinaryTreeDepth(BTNode* root) { if (root == NULL) { return 0; } if (root->left == NULL && root->right == NULL) { return 1; } return max(BinaryTreeDepth(root->left), BinaryTreeDepth(root->right)) + 1; }
递归展开图:
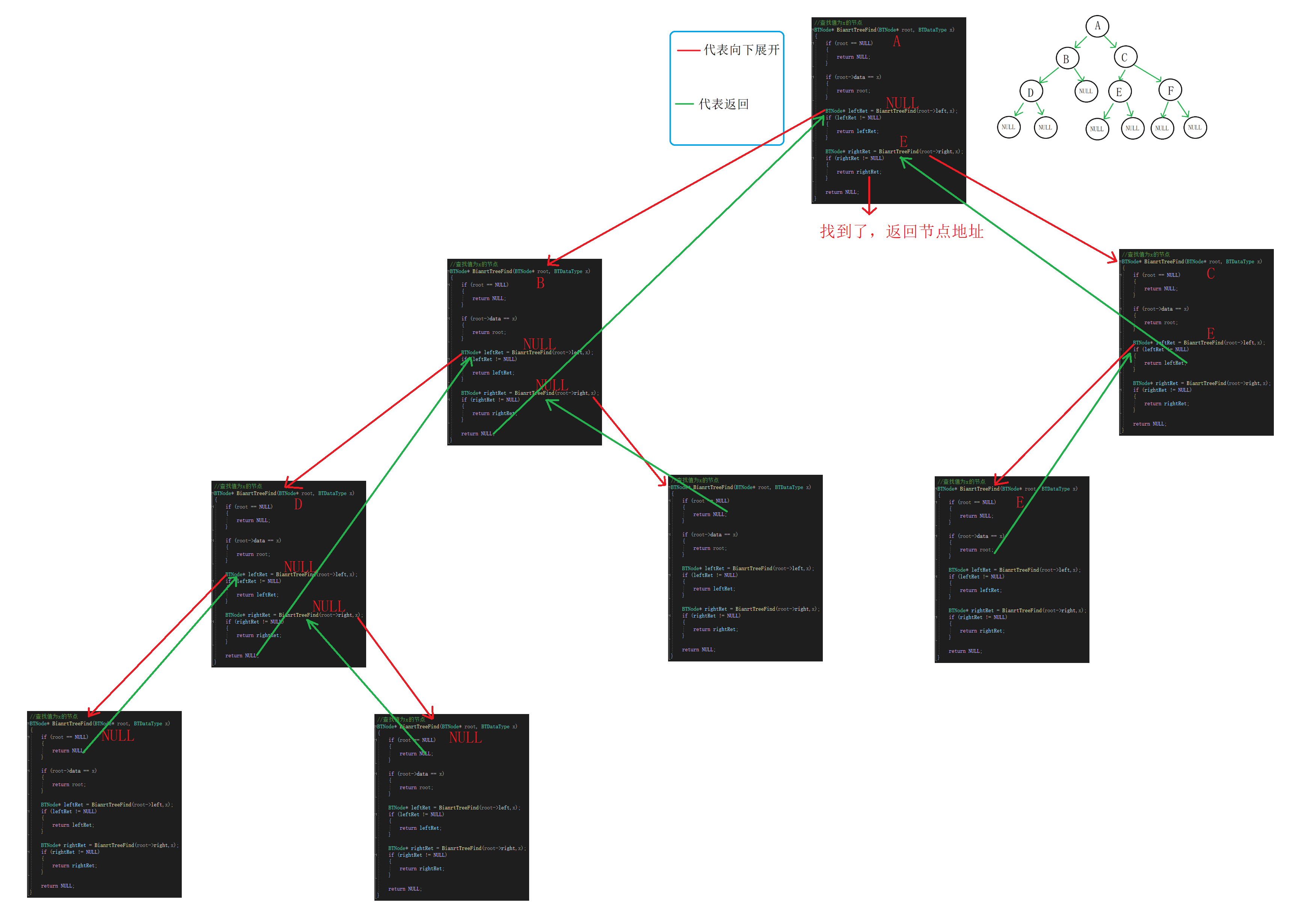
功能:输入要查找的数据x,返回节点的地址。
思路:
假设要查找E
①如果找到返回节点地址,没找到返回空。
②递归调用的时候要根据返回值来判断是否找到,
如果不为空代表找到了,不需要继续查找,返回节点地址。
③在整颗树查找E,先看根部是否为E,不是在A的左右子树中查找。
先看A的左子树根部是否为E,不是在B的左右子树中查找。
先看B的左子树根部是否为E,不是在D的左右子树中查找。
D的左右子树为空,返回空。
B的右子树为空,返回空。
A的左子树查找完毕,没找到,查找A的右子树。
先看A的右子树根部是否为E,不是在C的左右子树查找。
………………………………
代码:
//查找值为x的节点 BTNode* BianrtTreeFind(BTNode* root, BTDataType x) { if (root == NULL) { return NULL; } if (root->data == x) { return root; } BTNode* leftRet = BianrtTreeFind(root->left,x); if (leftRet != NULL) { return leftRet; } BTNode* rightRet = BianrtTreeFind(root->right,x); if (rightRet != NULL) { return rightRet; } return NULL; }
递归展开图(查找E):
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
所以这可能有点令人困惑,但请耐心等待。简而言之,我想遍历具有特定键值的所有属性,然后如果值不为空,则将它们插入到模板中。这是我的代码:属性:#===DefaultfileConfigurations#default['elasticsearch']['default']['ES_USER']=''default['elasticsearch']['default']['ES_GROUP']=''default['elasticsearch']['default']['ES_HEAP_SIZE']=''default['elasticsearch']['default']['MAX_OP