链接: JVM垃圾收集—垃圾收集算法
上一篇介绍了垃圾收集算法及分区,这篇我们来学习垃圾收集器
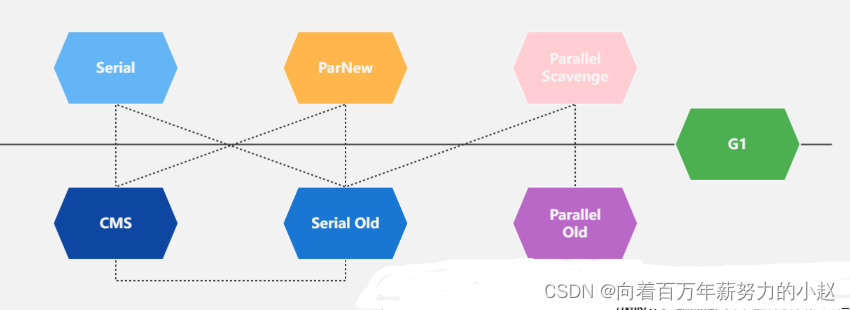
串行收集器 Serial 和 Serial Old
只能有一个垃圾回收线程执行,用户线程暂停。(适用于内存较小的嵌入式设备)
并行收集器[吞吐量优先] Paraller Scanvenge、Parallel Old
多条垃圾收集线程并行工作,但此时用户线程仍然处于等待阶段。(适用于科学计算、后台处理等若干交互场景)
并发收集器[停顿时间优先] CMS、G1
用户线程和垃圾收集线程同时执行(但并不一定是并行的,可能是交替执行的),垃圾收集线程在执行的时候不会停顿用户线程的运行。(适用于相对时间有要求的场景,比如WEB)
我按照发展顺序给大家介绍一下:

特点:它只会使用一个CPU或者一条收集线程去完成垃圾收集工作,更重要的是其在垃圾收集的时候需要暂停其他线程。
优点:简单高效
缺点:收集过程需要暂停所有线程。
应用:Client模式下的默认新生代收集器(Serial收集器是最基本、发展历史最悠久的收集,之前(JDK1.3.1之前)是虚拟机新生代收集器的唯一选择。)
特点:ParNew收集器实质上是Serial收集器的多线程并行版本,除了同时使用多条线程进行垃圾收集之外,其余的行为包括Serial收集器可用的所有控制参数(例如:-XX:SurvivorRatio、-XX: PretenureSizeThreshold、-XX:HandlePromotionFailure等)、收集算法、Stop The World、对象分配规 则、回收策略等都与Serial收集器完全一致,在实现上这两种收集器也共用了相当多的代码。
优点:多CPU时,比Serial效率更高。
缺点:收集过程暂停所有的应用程序,单CPU核心时比Serial效率差。
应用:运行在Server模式下的虚拟机中首选的新生代收集器。
此收集器与吞吐量关系密切,故也称为吞吐量优先收集器。
特点:多线程
Parallel Scavenge收集器使用两个参数控制吞吐量:
控制最大的垃圾收集停顿时间 XX:MaxGCPauseMillis
直接设置吞吐量的大小 XX:GCTimeRatio
吞吐量 = 运行用户代码时间 / 运行用户代码时间 + 运行垃圾收集时间。
如果虚拟机完成某个任务,用户代码加上垃圾收集器总共耗时100分钟,其中垃圾收集器花费了1分钟,那吞吐量就是 99 / 100= 99%。
吞吐量越大,意味着垃圾收集的时间更短、则用户代码可以充分利用CPU资源,尽快完成程序的运算任务。
这里不是你设置了就一定有效,虚拟机会尽可能的靠近你设置的数值,并不是绝对一致
Serial Old 是Serial 收集器的老年代版本
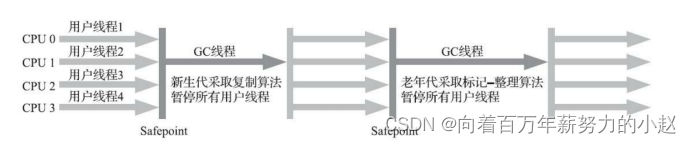
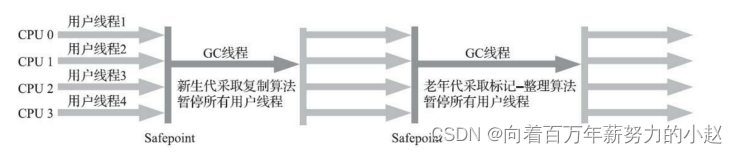
特点:多线程,采用标记-整理算法。
应用场景:注重高吞吐量以及CPU资源敏感的场合
是一种以获取最短回收停顿时间为目标的收集器
应用场景:适用于注重服务的响应速度,希望系统停顿时间最短,给用户带来良好的体验。比如web服务,b/s结构。
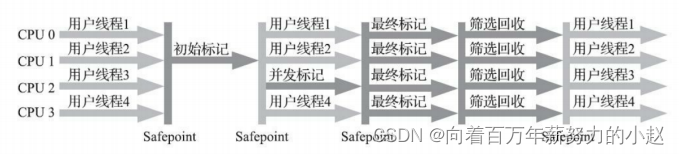
工作分为四步:
第一步、初始标记(STW),标记GC Roots能直接关联到的对象,速度非常快。
第二步、并发标记,进行GC Roots Tracing ,就是从GC Roots开始找到它能引用的所有对象的过程。
第三步、重新标记(STW),为了修成并发标记期间因用户程序继续运作导致标记产生变动的一部分对象的标记记录。这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间要短。
第四步、并发清除,在整个过程中耗时最长的并发标记和并发清除过程,收集器线程都可以与用户线程一起工作,因此,从总体上看,CMS收集器的内存回收过程与用户线程一起并发执行的

优点:并发收集、并发清除、低停顿。
缺点:对CPU要求高,无法处理浮动垃圾、产生大量空间碎片、并发阶段会降低吞吐量。
这里有一个刁钻的面试问题:
CMS默认晋升老年代为6的原因: 简单来说,CMS对内存尤其敏感,且会导致单线程Serial FullGC 这个是非常严重的后果,而从结果上说越大的MaxTenuringThreshold会更快的导致heap的碎片化(不光old 区,首先要明白对于内存的分配并不是真的一个对象一个对象紧密排列的),所以历代CMS 默认这个值都会比较小(JDK8以前是4,之后调整为6)
工作也是分为四步:
第一步、初始标记(STW),标记GC Roots能直接关联到的对象(速度很快)。
第二步、并发标记,进行 GC Roots Tracing,就是从GC Roots开始找到它能引用的所有其他对象的过程。
第三步、最终标记(STW),为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分的标记记录。这个阶段的停顿时间一般会比初始标记阶段稍微长,但是要比并发标记要短。
第四步、筛选回收(STW),对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间指定回收计划。
G1 总结:
JDK 7 开始使用,JDK8非常成熟,JDK9默认的垃圾收集器。
如果停顿时间过短,会造成频繁垃圾回收,会导致OOM:GC overhead limitexceeded (超过98%的时间用来做GC并且回收了不到2%的堆内存时会抛出此异常)
虚拟机怎么判断是否需要使用G1收集器?
答:50%以上的堆被存活对象占用、对象分配和晋升的速度变化非常大、垃圾回收时间较长。
停顿时间 = 垃圾收集器进行垃圾回收的执行时间
吞吐量 = 运行用户代码时间 / 运行用户代码时间 + 运行垃圾收集时间。
如果虚拟机完成某个任务,用户代码加上垃圾收集器总共耗时100分钟,其中垃圾收集器花费了1分钟,那吞吐量就是 99 / 100= 99%。
吞吐量越大,意味着垃圾收集的时间更短、则用户代码可以充分利用CPU资源,尽快完成程序的运算任务。
停顿时间越短就越适合需要和用户交互的程序,良好的响应速度能提升用户体验; 高吞吐量则可以高效地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不 需要太多交互的任务。
吞吐量和停顿时间是衡量垃圾回收器的标准,我们进行调优也是观察这两个变量。
这个准则只能参考,因为性能取决于堆的大小,应用程序维护的实时数据量以及可用处理器的数量和速度。
大白话:牛逼哄哄的硬件设备不怎么需要调优,垃圾设备才考验你的调优技能。
如果应用程序的内存在100M左右,使用串行收集器 -XX:+UseSerialGC。
如果是单核心,并且没有停顿要求,默认收集器,或者选择带有选项的-XX:+UseSerialGC
如果允许停顿时间超过1秒或者更长时间,默认收集器,或者选择并行-XX:+UseParallelGC
如果响应时间最重要,并且不能超过1秒,使用并发收集器 -XX:+UseConcMarkSweepGC or -XX:+UseG1GC
1.8默认的垃圾回收:PS + ParallelOld
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g