文章目录
静态内存分配
当你声明数组时,你必须用一个编译时常量指定数组的长度(c99前)。但是,数组的长度常常在运行时才知道,这是由于它所需要的内存空间取决于输入数据。例如,一个用于计算学生等级和平均分的程序可能需要存储一个班级所有学生的数据,但不同班级的学生数量可能不同。在这些情况下,我们通常采取的方法是声明一个较大的数组,它可以容纳可能出现的最多元素。
这样声明的数组有3个缺陷
- 这种声明引入了认为的限制,如果使用的长度超过了声明的长度,计算机无法处理这种情况
- 如果程序使用的元素较少时,这样会导致多余的空间被浪费
- 如果输入的数据超过了数组的容纳范围,那么程序不得不做出一种合理的相应
int main()
{
int val = 20;//在栈上开辟4个字节
int arr[10] = { 0 };//在栈上开辟40个字节的连续空间
return 0;
}
上述开辟空间的方式有2个特点
上述开辟空间的方式称为静态内存开辟
动态内存分配
在计算机科学中, 动态内存分配(Dynamic memory allocation)又称为堆内存分配,是指计算机程序在运行期中分配使用内存。它可以当成是一种分配有限内存资源所有权的方法。
动态分配的内存在被程序员明确释放或被垃圾回收之前一直有效。与静态内存分配的区别在于没有一个固定的生存期。这样被分配的对象称之为有一个“动态生存期”。
以下动态内存函数均包含头文件stdlib.h
动态内存函数开辟的空间都在堆上

malloc的参数是开辟空间的字节数
NULL指针,因此malloc的返回值一定要做检查。void* ,所以malloc函数并不知道开辟空间的类型,具体在使用的时候使用者自己来决定。
malloc,calloc,realloc动态开辟的空间NULL指针,那么调用free函数什么也不会做int main()
{
int i, n;
char* buffer;
printf("How long do you want the string? ");
scanf("%d", &i);
buffer = (char*)malloc(i + 1);//需要留一个空间给结束符
if (buffer == NULL) exit(1); //分配空间失败
for (n = 0; n < i; n++) buffer[n] = rand() % 26 + 'a';
buffer[i] = '\0';
printf("Random string: %s\n", buffer);
free(buffer);//释放动态开辟的内存
return 0;
}

calloc函数的第一个参数是要开辟的元素个数,第二个参数是每一个元素的字节数
NULL指针NULL指针),这个返回的指针不能够被解引用int main()
{
int* pa = (int*)calloc(5, sizeof(int)); //申请5个连续存储int的空间并初始化为0
if (pa!=NULL)
for (int i = 0; i < 5; i++) printf("%d ", pa[i]);
free(pa);//释放动态开辟的内存
return 0;
}
realloc函数让动态内存管理更灵活,我们可以通过realloc对动态开辟的内存进行更改(扩大/缩小)
realloc函数的第一个参数是待扩容内存起始地址,第二个参数是扩容后的字节数
NULL指针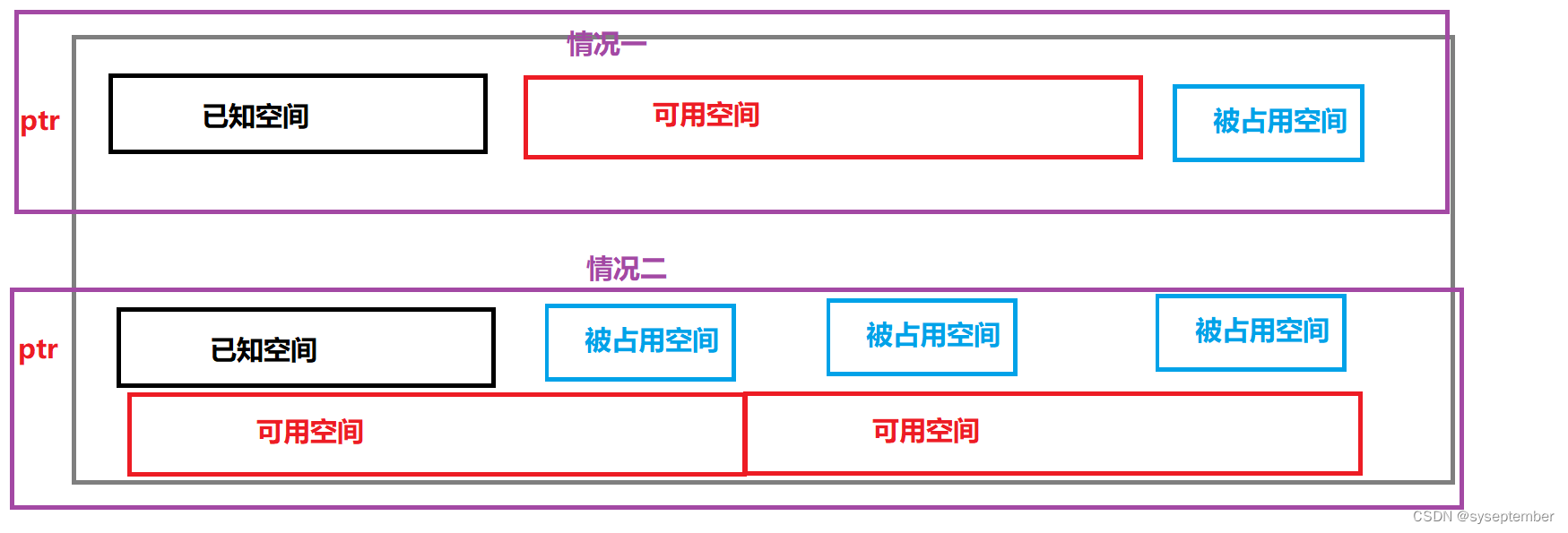
对于情况一:直接返回已知空间的起始地址
对于情况二:
free已知空间int main()
{
int input, n;
int count = 0;
int* numbers = NULL;
int* more_numbers = NULL;
do {
printf("Enter an integer value (0 to end): ");
scanf("%d", &input);
count++;
more_numbers = (int*)realloc(numbers, count * sizeof(int));//没输入一个数申请一个多空间
if (more_numbers != NULL)
{
numbers = more_numbers;
numbers[count - 1] = input;
}
else perror("realloc失败->\n");
} while (input != 0);
printf("Numbers entered: ");
for (n = 0; n < count; n++) printf("%d ", numbers[n]);
free(numbers);
return 0;
}
从这个例子中可以很好的体现动态开辟的优势,即使我事先不知道用户要输入多少个数(甚至用户也不知道),我也可以将用户输入的数字记录下来
注意:调用realloc时最后用临时变量接受返回值,不然返回值如果为NULL时原来已知空间中的地址找不到了,因为原本记录那个地址的变量现在变成了NULL
对NULL指针解引用
//1.对空指针解引用
int main()
{
int* p = (int*)malloc(INT_MAX);
*p = 20;
free(p);
return 0;
}

malloc开辟失败返回空指针,没有检查是否开辟成功就直接解引用,有可能解引用空指针,程序崩溃
对动态开辟空间的越界访问
//2.对动态开辟的内存进行越界访问
int main()
{
int* p = (int*)malloc(sizeof(int) * 5);
assert(p);
for (int i = 0; i <= 5; i++)
{
p[i] = i + 1;
}
return 0;
p指向的是5个int的空间,但是当i等于5时,程序访问了未定义的位置,这样会越界访问,越界访问有可能会时程序崩溃,有可能不会(不代表问题不严重)
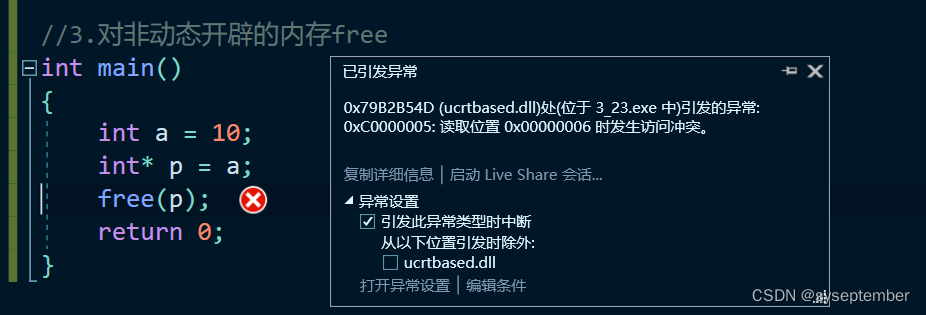
对非动态开辟内存使用free释放
int main()
{
int a = 10;
int* p = a;
free(p);
return 0;
}
使用free释放动态开辟内存的一部分
//4.使用free释放动态开辟内存的一部分
int main()
{
int* p = (int*)malloc(sizeof(int) * 5);
free(++p);
return 0;
}
对用一块内存多次释放
//5.对同一块内存多次释放
int main()
{
int* p = (int*)malloc(sizeof(int) * 5);
free(p);//释放一次后p指向的空间不在是动态开辟的了
free(p);//此时释放非动态开辟的内存报错
return 0;
}
动态开辟的内存忘记释放(内存泄漏)
void test()
{
int* p = (int*)malloc(100 * sizeof(int));
}
int main()
{
while (1)
{
test();
}
return 0;
}
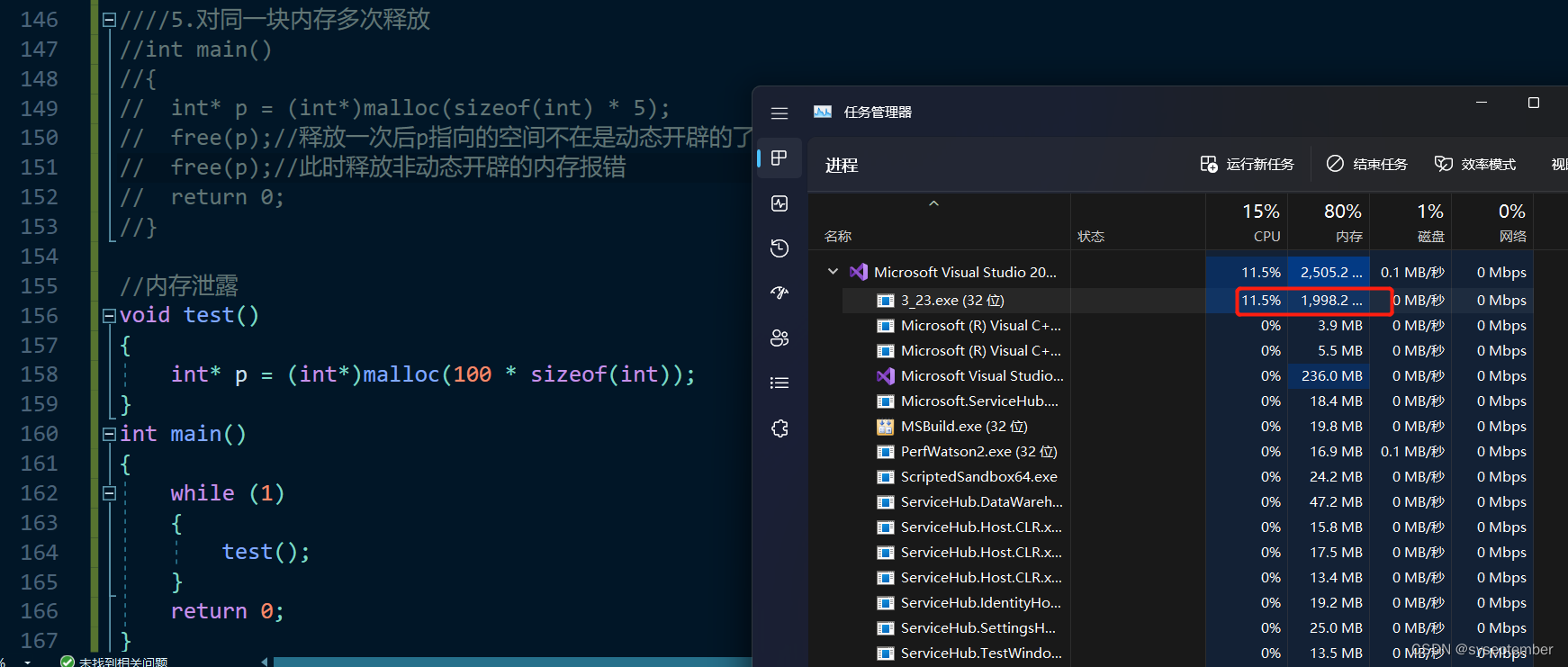
当内存大量泄漏时,程序会吃掉大部分内存,这样操作系统没有过多的内存分配给其他应用,因此内存泄漏可能会导致操作系统崩溃
切记:动态开辟的内存一定要释放,并且保证正确释放
为了避免这种情况,我们应该保证自己申请的内存自己释放,自己不释放的应当写文档告诉别人来释放
//1.下面程序会打印什么?
void GetMemory(char* p)
{
p = (char*)malloc(100);
}
int main()
{
char* str = NULL;
GetMemory(str);
strcpy(str, "hello world");
printf(str);
}

可以通过函数返回开辟的地址和传二级指针修正程序
//修正1
char* GetMemory()
{
char* tmp = (char*)malloc(100);
return tmp == NULL ? NULL : tmp;
}
int main()
{
char* str = GetMemory();
strcpy(str, "Hello world");
printf(str);
free(str);//释放动态分配的内存
str = NULL;
return 0;
}
//修正2
void GetMemory(char** pp)
{
*pp = (char*)malloc(100);
}
int main()
{
char* str = NULL;
GetMemory(&str);
strcpy(str, "Hello world");
printf(str);
free(str);
str = NULL;
return 0;
}
//2.输出结果是什么?
char* GetMemory(void)
{
char p[] = "hello world";
return p;
}
void Test(void)
{
char* str = NULL;
str = GetMemory();
printf(str);
}

//3.输出什么
void GetMemory(char** p, int num)
{
*p = (char*)malloc(num);
}
int main()
{
char* str = NULL;
GetMemory(&str, 100);
strcpy(str, "hello");
printf(str);
return 0;
}
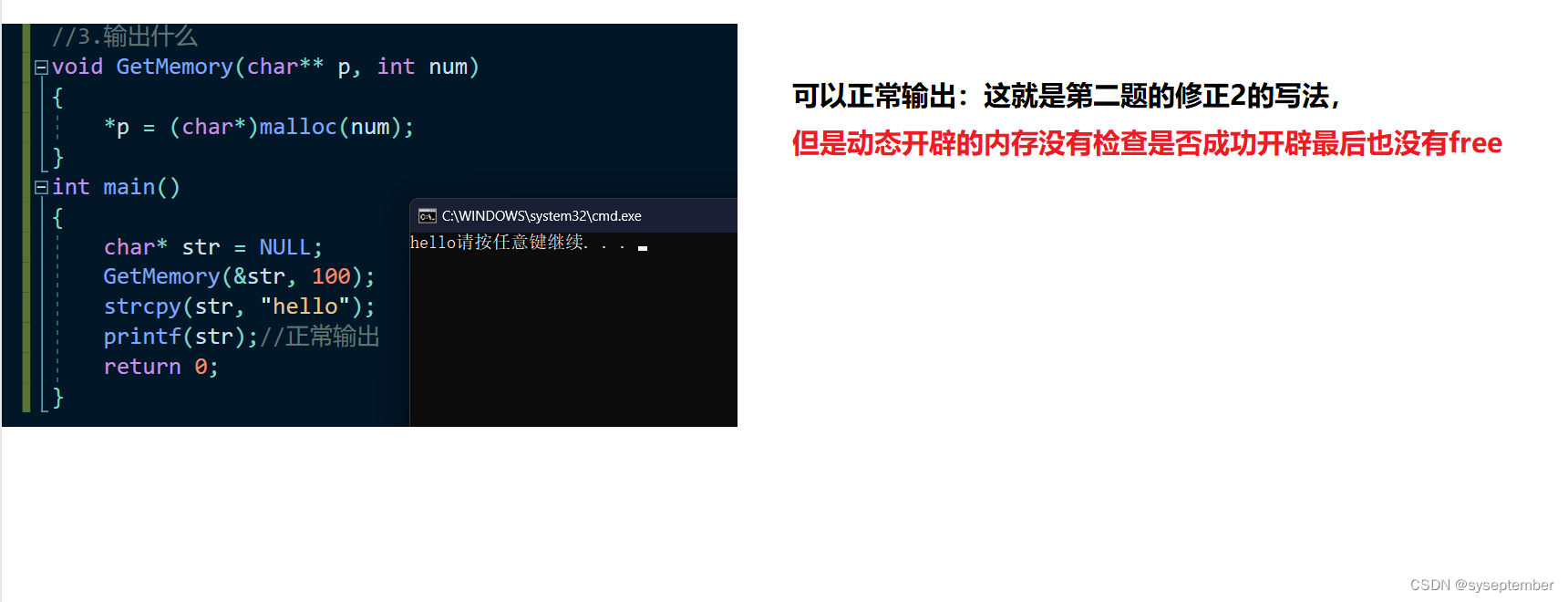
//4.输出什么?
int main()
{
char* str = (char*)malloc(100);
strcpy(str, "hello");
free(str);
if (str != NULL)
{
strcpy(str, "world");
printf(str);
}
}
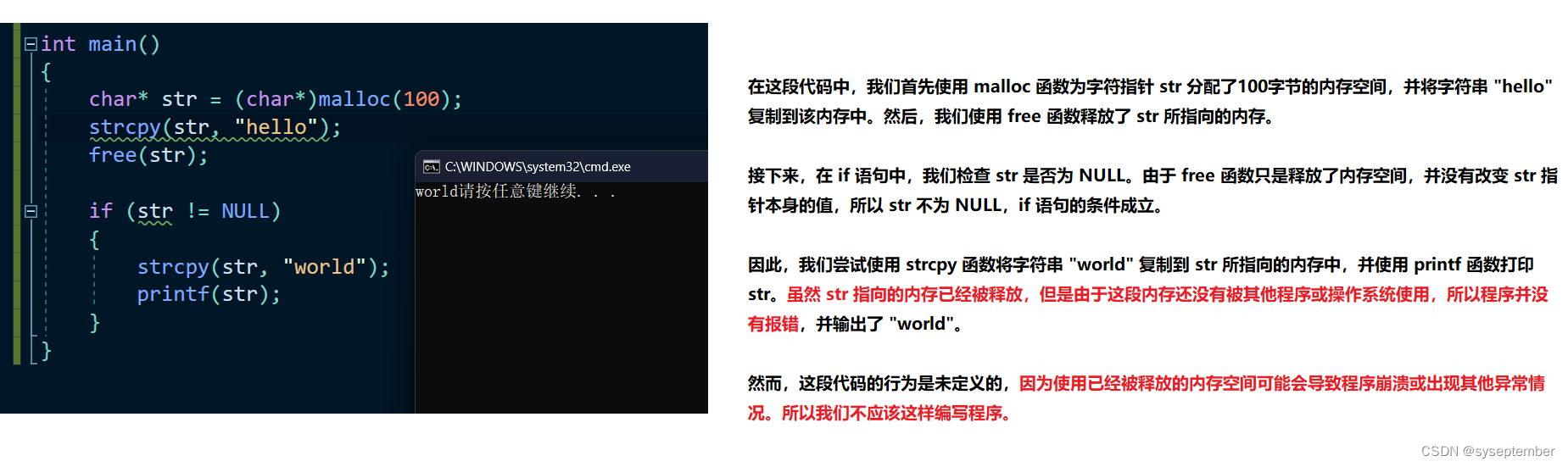
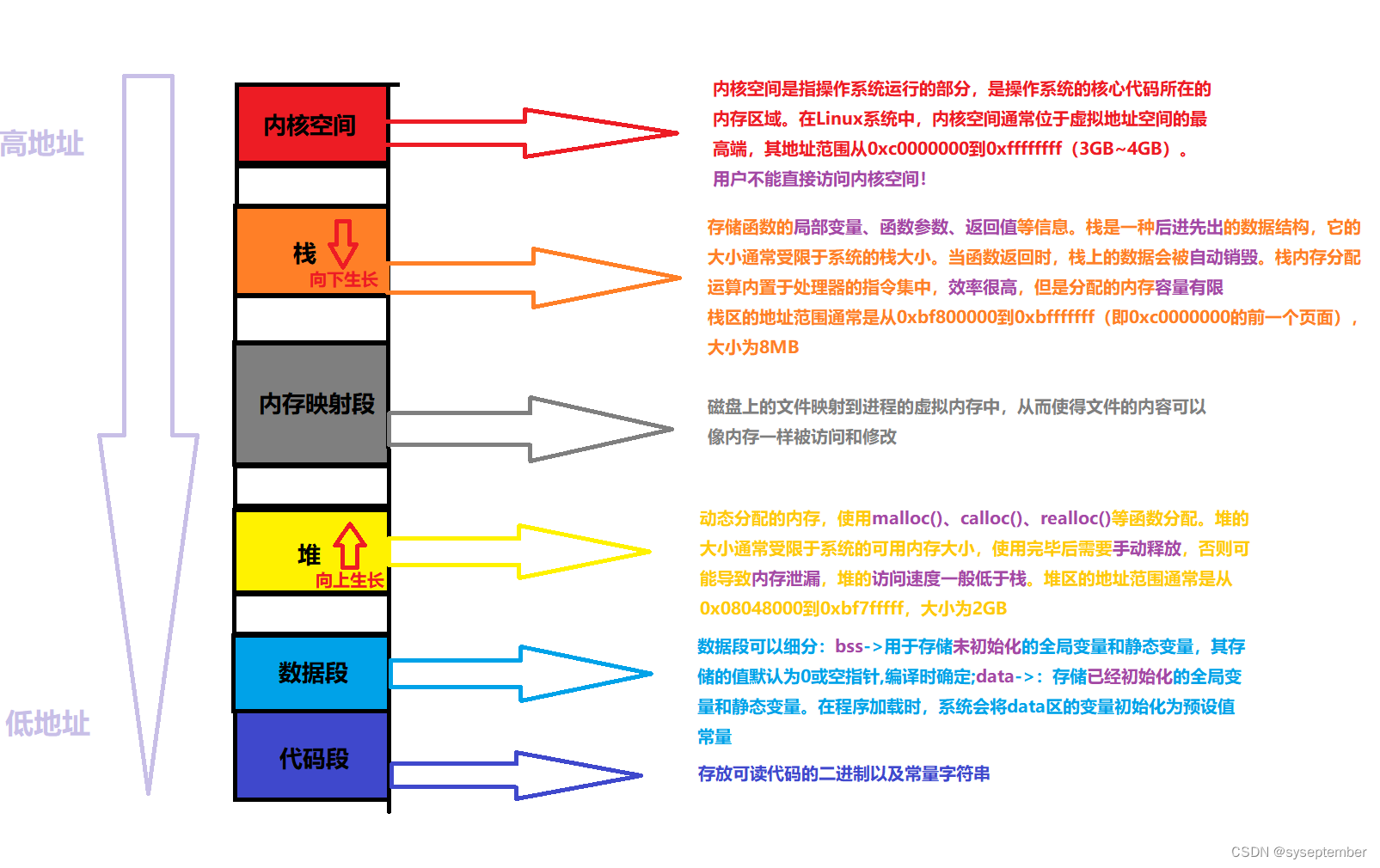
看见这个图,相比就会大致了解C/C++的内存区域规划了吧😼😼😼hhh~
想必不少人一开始听到这个词比较陌生,什么叫做柔性数组?变长数组我知道,数组的长度可以是变量嘛,柔性数组是什么鬼嘛😵💫
柔性数组和变长数组都是在C99中加上的
C99 中,结构中的最后一个元素允许是未知大小的数组,这就叫做『柔性数组』成员。
1.柔性数组不占结构体的大小
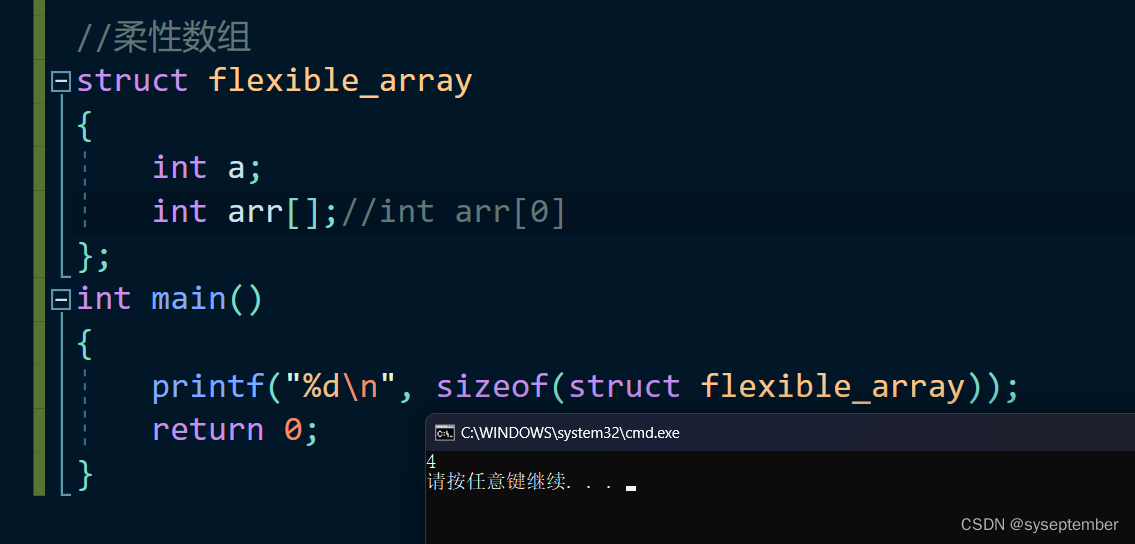
2.柔性数组只能是结构体中最后一个成员并且结构体除柔性数组外至少有一个其他成员
//定义柔性数组的两种错误写法
struct flexible_array
{
int arr[];
};
struct flexible_array
{
int arr[];
int i;
};
3.包含柔性数组成员的结构用malloc()函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小
//malloc分配结构的大小,分配的空间必须大于结构的大小
typedef struct flexible_array
{
int i;
int arr[];
}flexible_array;
int main()
{
//给柔性数组分配10个int大小
flexible_array* pa =
(flexible_array*)malloc(sizeof(flexible_array) + sizeof(int) * 10);
assert(pa);
for (size_t i = 0; i < 10; i++) pa->arr[i] = i;
for (size_t i = 0; i < 10; i++) printf("%d ", pa->arr[i]);
free(pa);
return 0;
}
更改数组的大小
int main()
{
flexible_array* pa =
(flexible_array*)malloc(sizeof(flexible_array) + sizeof(int) * 10);//给柔性数组分配10个int大小
assert(pa);
for (size_t i = 0; i < 10; i++) pa->arr[i] = i;
for (size_t i = 0; i < 10; i++) printf("%d ", pa->arr[i]);
puts("");
//数组扩容成20个int大小
flexible_array* tmp = (flexible_array*)realloc
(pa, sizeof(flexible_array) + sizeof(int) * 20);
assert(tmp);
pa = tmp;
for (size_t i = 10; i < 20; i++) pa->arr[i] = i;
for (size_t i = 0; i < 20; i++) printf("%d ", pa->arr[i]);
puts("");
free(pa);
return 0;
}
上述代码可以写成
typedef struct flexible_array
{
int i;
int* arr;
}flexible_array;
int main()
{
flexible_array* pa = (flexible_array*)malloc
(sizeof(flexible_array));
pa->arr = (int*)malloc(sizeof(int) * 10);
for (size_t i = 0; i < 10; i++) pa->arr[i] = i;
for (size_t i = 0; i < 10; i++) printf("%d ", pa->arr[i]);
puts("");
//
flexible_array* tmp = (flexible_array*)realloc
(pa->arr, sizeof(int) * 20);
assert(tmp);
pa->arr = tmp;
for (size_t i = 10; i < 20; i++) pa->arr[i] = i;
for (size_t i = 0; i < 20; i++) printf("%d ", pa->arr[i]);
puts("");
//先释放arr
free(pa->arr);
free(pa);
return 0;
}
对比上述两种写法
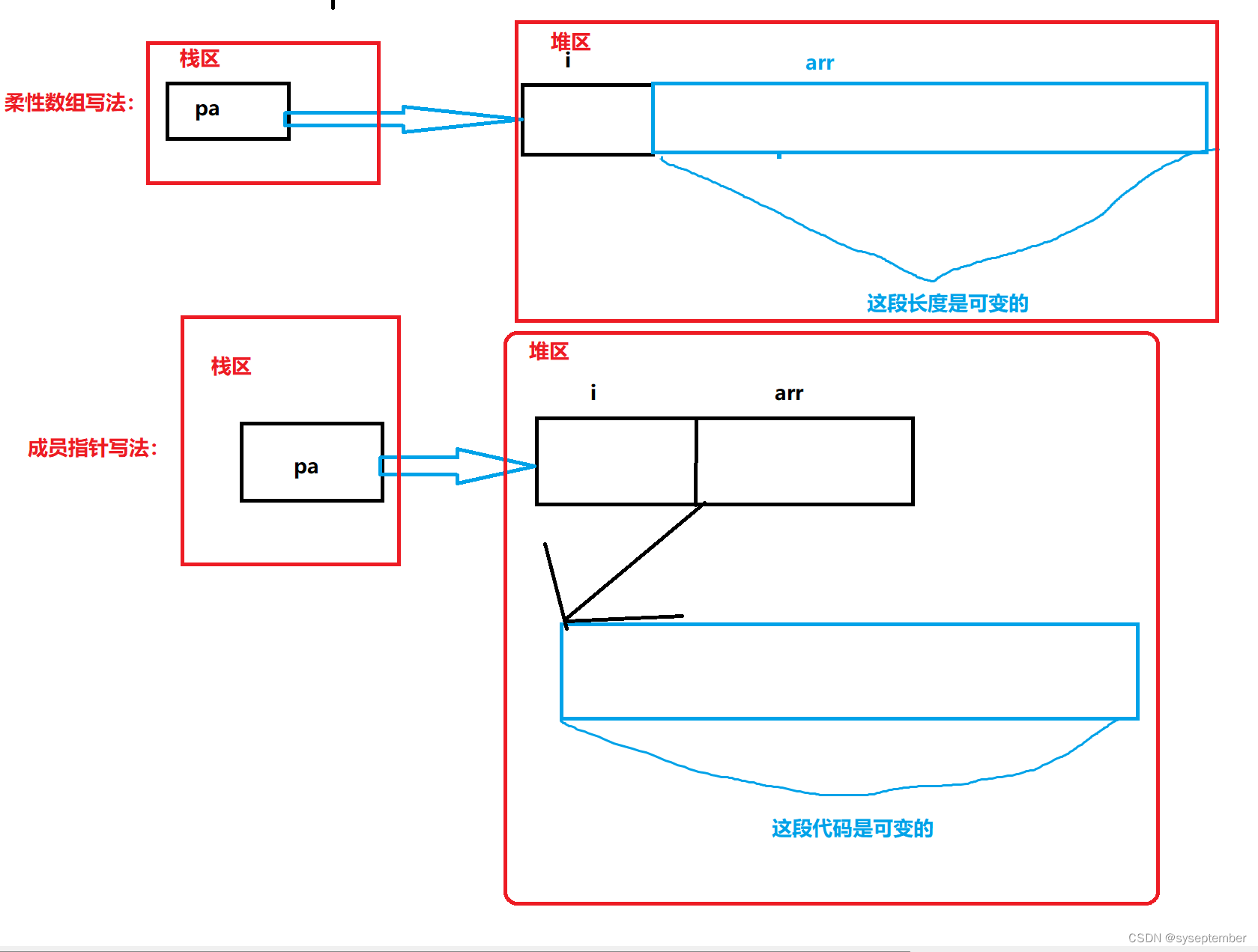
- 第一个好处是:方便内存释放
如果我们的代码是在一个给别人用的函数中,你在里面做了二次内存分配,并把整个结构体返回给
用户。用户调用free可以释放结构体,但是用户并不知道这个结构体内的成员也需要free,所以你不能指望用户来发现这个事。所以,如果我们把结构体的内存以及其成员要的内存一次性分配好了,并返回给用户一个结构体指针,用户做一次free就可以把所有的内存也给释放掉。- 第二个好处:这样有利于访问速度.
连续的内存有益于提高访问速度(计算机在访问当前地址时会默认把当前地址相邻的数据加载到寄存器中),也有益于减少内存碎片(使用柔性数组只调用一次malloc,而指针写法调用了两次malloc)
在了解动态内存函数之后,我们可以将之前的静态通讯录改进为动态通讯录,不会静态通讯录看这里静态通讯录
首先明确一点:静态通讯录是通过一个大小固定的数组来存放联系人的信息,而数组的大小每次都是固定的,所以通讯录的长度不能更改,动态通讯录就是通讯录的容量可以更改,这样的好处有:1. 存多少人的信息就开辟多少空间,不够了随时可以扩容,2. 动态开辟的空间是在堆上的,堆上的空间比栈上的大,所以存储的联系人也比静态通讯录存储的多
将数组换成指针变量即可实现动态通讯录,并且需要增加变量capacity来存储当前通讯录的最大容量
动态通讯录只有在初始化、增加联系人、销毁时和静态通讯录不一样
//动态通讯录
typedef struct Contact
{
PeoInfo* data;//data是一个指针,指向动态开辟的内存
int sz; //当前联系人个数
int capacity;//当前最大容量
}Contact;
//动态通讯录初始化
void InitContact(Contact* con)
{
con->data = NULL;
con->capacity = FITST_NUM;//一开始的最大容量
con->sz = 0;
}
添加联系人之前需要检查一下当前最大容量是否满了,如果满了需要扩容
//检查容量是否满了
void CheckContact(Contact* con)
{
if (con->capacity == con->sz || con->sz == 0)
{
PeoInfo* pc =
(PeoInfo*)realloc(con->data, MAGNIFICATION * sizeof(con->capacity));
if (NULL == pc)
{
perror("扩容失败\n");
return;
}
con->capacity *= MAGNIFICATION;//容量扩成当前最大容量的两倍
con->data = pc;
printf("扩容成功!当前容量最大容量%d\n", con->capacity);
}
return;
}
//动态通讯录添加
void AddContact(Contact* con)
{
CheckContact(con);
printf("请输入你需要添加人的姓名:");
scanf("%s", con->data[con->sz].name);
printf("请输出你需要添加人的年龄:");
scanf("%d", &(con->data[con->sz].age));
printf("请输入你需要添加人的性别:");
scanf("%s", con->data[con->sz].sex);
printf("请输入你需要添加人的电话:");
scanf("%s", con->data[con->sz].tele);
printf("请输入你需要添加人的地址:");
scanf("%s", con->data[con->sz].address);
con->sz++;
printf("添加成功!\n");
}
//动态通讯录销毁
void DestroyContact(Contact* con)
{
printf("你确定要清空通讯录吗?(YES/NO)\n");
char selection[MAX] = { 0 };
scanf("%s", selection);
fflush(stdin);
if (strcmp(selection, "YES") != 0) return;
free(con->data);
printf("清空成功!\n");
}
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生
有没有办法在Ruby中动态创建数组?例如,假设我想遍历用户输入的书籍数组:books=gets.chomp用户输入:"TheGreatGatsby,CrimeandPunishment,Dracula,Fahrenheit451,PrideandPrejudice,SenseandSensibility,Slaughterhouse-Five,TheAdventuresofHuckleberryFinn"我把它变成一个数组:books_array=books.split(",")现在,对于用户输入的每一本书,我想用Ruby创建一个数组。伪代码来做到这一点:x=0books_array.
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
这是我在ActiveAdmin中的自定义页面ActiveAdmin.register_page"Settings"doaction_itemdolink_to('Importprojects','settings/importprojects')endcontentdopara"Text"endcontrollerdodefimportprojectssystem"rakedataspider:import_projects_ninja"para"OK"endendend我想做的是,当我单击“导入项目”按钮时,我想在Controller中执行rake任务。但是我无法访问该方法。可能是什