1、掌握使用numpy和pandas库处理数据的基本方法。 2、掌握使用Sklearn库对多元线性回归算法的实现及其评价方法。 3、掌握使用matplotlib结合pandas库对数据分析可视化处理的基本方法。
1、利用python中pandas等库完成对数据的预处理,最后将处理好的文件进行保存。 2、利用pandas、matplotlib等库完成对预处理数据的可视化。 3、结合pandas、matplotlib库对聚类完成的结果进行可视化处理。
(1)导入所需要使用的包
import os
import re
import pandas as pd
import numpy as np(2)读取文件
input_dir='/data/bigfiles/'
files=os.listdir(input_dir)
data_list=[]
for file in files:
data_list.append(pd.read_excel(input_dir +file))(3)查看数据的基本统计信息
data=pd.concat(data_list)
data
(4)删除csv文件中索引列,并重置
data= data.reset_index()
data=data.drop("index",axis=1)
data.head(10)
(5)处理空值
(data.isnull()).sum()
#检查重复值
(data.duplicated()).sum()
#抛弃重复值
data.drop_duplicates(inplace=True)
(6)删除部分数据的中文字符,将数据类型转换为float型
#使用正则表达式查看单价列中含有的中文字符种类
data.总价.map(lambda x: re.sub('[^\u4E00-\u9FA5]','',x)).unique()
print(data.单价.map(lambda x: re.sub('[^\u4E00-\u9FA5]','',x)).unique())
data['单价']=data.单价.map(lambda x : round(float(re.findall(r'单价(.*?)元/平米',x)[0])/10000,2))
#删去字符串“万”,将类型转换float,保留两位小数
data['总价']=data.总价.map(lambda x : round(float(x.replace('万','')),2))
data
#拆分房屋信息所在列
a = data.房屋信息.map(lambda x : len(x.split('|')))
data= data[a == 7]
data.loc[:,'户型'] = data.房屋信息.map(lambda x : x.split('|')[0])
data.loc[:,'面积'] = data.房屋信息.map(lambda x : x.split('|')[1])
data.loc[:,'朝向'] = data.房屋信息.map(lambda x : x.split('|')[2])
data.loc[:,'类型'] = data.房屋信息.map(lambda x : x.split('|')[3])
data.loc[:,'楼层'] = data.房屋信息.map(lambda x : x.split('|')[4])
data.loc[:,'建成时间'] = data.房屋信息.map(lambda x : x.split('|')[5])
data.loc[:,'结构'] = data.房屋信息.map(lambda x : x.split('|')[6])
# data = data.drop('房屋信息',axis = 1)
data['面积']=data.面积.map(lambda x : round(float(x.replace('平米','')),2))
len(data[~data.建成时间.str.contains('年建')])
# data['建成时间']=data.建成时间.map(lambda x:float(x.replace('年建','')))
data.head()

(7)对部分数据进行独热码编码
#对户型进行独热编码
data=data.join(pd.get_dummies(data.户型))
# data = data.drop('户型',axis = 1)
#对区域类型结构
print(data.区域.unique())
data=data.join(pd.get_dummies(data.区域))
data.head()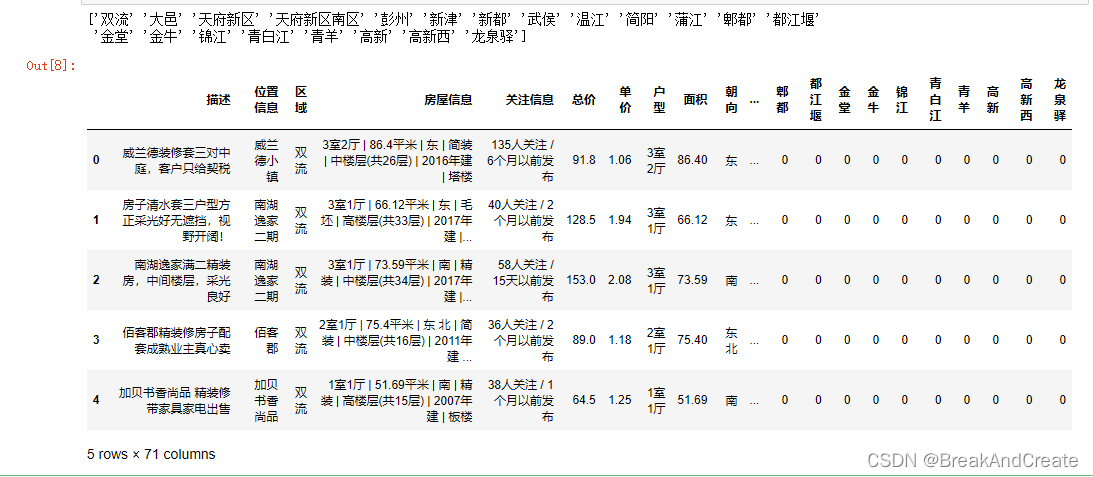
(8)对数据进行标准化处理
# #说白了就是清晰数据
# #去掉字符串前后空格
data.head()
data.类型.unique()
data.结构.unique()
data['类型'] = data.类型.str.strip()
data['结构'] = data.结构.str.strip()
#丢弃无效数据
data=data[(data.类型 != '其他')&(data.结构!='暂无数据')]
#使用独热码编码
data =data.join(pd.get_dummies(data.类型))
data =data.join(pd.get_dummies(data.结构))
# data = data.drop('类型',axis = 1)
#处理朝向列种类
def my_get_dummies(ser):
base_dirt=['东','南','西','北','东北','东南','西南','西北']
base_data=np.zeros((len(ser),),dtype=np.int)
df = pd.DataFrame({'东':base_data,'南':base_data,'西':base_data,'北':base_data,'东北':base_data,'东南':base_data,'西南':base_data,
'西北':base_data})
for irec in ser.index:
rec=ser[irec].strip().split(' ')
for dirt in rec:
#检查是否存在8个基本方位以外的记录
if dirt not in base_dirt:
print(dirt)
else:
df[dirt][irec]=1
return df
data=data.join(my_get_dummies(data.朝向))
#删除原有列
data=data.drop('朝向',axis=1)
data.head()
#检测数据格式一致性
(~data.楼层.str.contains('楼层')).sum()
#舍弃数据
data = data[data.楼层.str.contains('楼层')]
#查看数据唯一值
data.楼层.unique()
#提取所在楼层
data['所在楼层']=data.楼层.map(lambda x:x.split('(')[0])
#对所在楼层进行独热编码
data=data.join(pd.get_dummies(data.所在楼层))
#使用正则表达式提取数据并转换为int类型
data['总楼层'] =data.楼层.map(lambda x: int(re.findall(r'\(共(.*?)\层',x)[0]))
#删除原有列
# data = data.drop('楼层',axis=1)
# data = data.drop('所在楼层',axis=1)
data.head(5)
# #删除发布时间列信息
# data=data.drop('发布时间',axis=1)
#去掉空格
data=data.rename(columns = lambda x:x.strip())(9)存储预处理后的文件
#保存数据,如果服务器挂掉重新跑一边但不要跑这段代码
output_file_path = '/data/bigfiles/房产信息_预处理.xlsx'
data.to_excel(output_file_path,index=False)(1)读取预处理后的文件
#建议不要运行如过服务不挂的话可以运行
input_dir='/data/bigfiles/房产信息_预处(9)存储预处理后的文件理.xlsx'
data=pd.read_excel(input_dir)(2)利用二八原则,划分训练集和测试集
#二分原则为80%为样例数据作为模型训练集20%为样本数据作为测试集检查估计能力
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split #划分测试集与训练集
from sklearn.linear_model import LinearRegression as LR #回归模块
##在ipy中显示图像
%matplotlib inline
#设置绘图显示中文字体
plt.rcParams['font.sans-serif']=['SimHei']
pd.set_option('display.max_columns', None)
print(data.columns)
#特征提取
total_price=data.总价
unit_price=data.单价
house_area=data.面积
house_type=data[['0室0厅', '0室1厅', '1室0厅', '1室1厅', '1室2厅', '2室0厅', '2室1厅',
'2室2厅', '3室0厅', '3室1厅', '3室2厅', '3室3厅', '3室4厅', '4室0厅', '4室1厅', '4室2厅',
'4室3厅', '4室4厅', '5室0厅', '5室1厅', '5室2厅', '5室3厅', '5室4厅', '6室1厅', '6室2厅',
'6室3厅', '6室4厅', '6室5厅', '7室1厅', '7室2厅', '7室3厅', '7室4厅', '7室5厅', '8室2厅',
'8室3厅', '9室2厅']]
region=data[['双流', '大邑' ,'天府新区' ,'天府新区南区', '彭州', '新津', '新都', '武侯' ,'温江', '简阳', '蒲江', '郫都' ,'都江堰',
'金堂' ,'金牛', '锦江', '青白江' ,'青羊' ,'高新', '高新西', '龙泉驿']]
house_class= data[['塔楼','板塔结合','板楼']]
house_layer=data[['低楼层','中楼层','高楼层']]
house_dirt=data[['东','南','西','北','东北','东南','西南','西北']]
total_layer=data.总楼层
# 选择自变量与因变量
X = pd.concat([house_area,house_type,region,house_class,house_layer,house_dirt,total_layer],axis=1)
Y = unit_price
print(type(X))
X = X.fillna(0)
#划分测试集与训练集
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X,Y,test_size=0.2,random_state=420)

(3)建立多元回归模型并训练
reg=LR().fit(Xtrain,Ytrain)#这里其实就是建立模型把训练的值放进去返回一个拟合对象
#预测
Yhat=reg.predict(Xtest)
#查看回归系数
print(list(zip(X.columns,reg.coef_)))
#查看截距
print(reg.intercept_)(4)检验模型效果
from sklearn.metrics import mean_squared_error #MSE
from sklearn.metrics import mean_absolute_error #MAE
from sklearn.metrics import r2_score #R2
mse= mean_squared_error(Ytest,Yhat)
mae= mean_absolute_error(Ytest,Yhat)
r2=r2_score(Ytest,Yhat)
#调整R2
n=Xtest.shape[0]
k=Xtest.shape[1]
(5)计算估计值
adj_r2=1-(1-r2)*((n-1)/(n-k-1))(6)判断模型拟合的好坏程度
print('MSE:'+str(mse))
print('MAE:'+str(mae))
print('R2:'+str(r2))
print('调整后R2:'+str(adj_r2))
(1)将训练集真实值与模型预测值用折线图的形式表现出来
#绘制前50条记录
n=50
#绘制模型预测值
plt.plot(range(len(Yhat[:n])),Yhat[:n])
#绘制模型真实值
plt.plot(range(len(Ytrain[:n])),Ytrain[:n])
#图形设置
plt.xlabel('个例')
plt.ylabel('单价')
plt.title('线性回归预测结果')
plt.legend(["预估","实际"])

(2)将测试集真实值与模型预测值用折线图的形式表现出来
#绘制前50条记录
n=50
#绘制模型预测值
plt.plot(range(len(Yhat[:n])),Yhat[:n])
#绘制模型真实值
plt.plot(range(len(Ytest[:n])),Ytest[:n])
#图形设置
plt.xlabel('个例')
plt.ylabel('单价')
plt.title('线性回归预测结果')
plt.legend(["预估","实际"])

关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit