目录
什么是面向过程编辑呢?
举一个例子,我们去实现玩一个下棋游戏的项目,那么我们需要对下棋的所有功能进行实现,从游戏角色,进入游戏,游戏游玩,游戏输赢的判断,退出游戏等所有的过程我们都需要一步步实现。我们需要去分析每一步是如何实现的,这个过程就是面向过程的编译。
那什么是面向对象编程?
面向对象是相对于面向过程一步步实现的特点,面向对象更倾向于模块化的实现,对于’’对象‘‘,是系统中用来描述客观事物的一个实体,它是用来构成系统的一个基本单位,对象是由一组属性与一组行为构成的。
在此之前我们先提一个在C++比较重要的运算符
#include <iostream>
using namespace std;
int a = 100;
void test01()
{
int a = 10;
cout << a << endl;//输出局部变量a
cout << ::a << endl;//输出全局变量a
}
int main()
{
test01();
return 0;
}可以看到这里的::a是一个全局变量了。
创建名字是程序设计中一项基本的活动,当一个项目很大时,他会不可避免地包含大量名字,c++允许我们对名字的产生和名字的可见性进行控制。我们之前学习c语言可以通过static静态修饰全局变量使丢掉了外部连接属性,只对内部产生作用,在c++中我们可以定义一个作用域来控制对名字的访问。
在c++中,名称可以是符号常量,变量,函数,结构,枚举,类和对象等等。我们所创建的工程越大,名字的访问就越有可能发生冲突,其次在使用多个厂商的类库时,也可能会名字冲突。为了避免这样的冲突,引入关键字namespace给出作用空间,能更好的使用名称。
利用namespace我么们可以定义一片区间,其本质是作用域,为的是可以更好的控制标识符的作用域,其次编译器能通过空间名能快速地找到该数据。
namespace 空间名称
{
存放在该空间的各种数据
}
其次命名空间是有许多特点的:
举一个实例,创建两个命名空间 A B分别在里面创建一个名字相同变量,计算机仍可以识别。
#include<iostream>
using namespace std;
namespace A
{
int a = 10;
}
namespace B {
int a = 20;
}
void test()
cout << "A::a :" << A::a << endl;//10
cout << "B::a :" << B::a << endl;//20
}
int main()
{
test();
return 0;
}错误写法

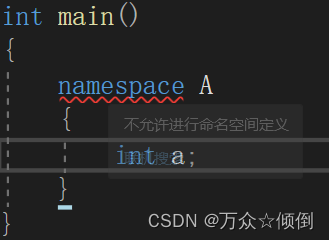
这里会报错,不允许在这里命名,必须在全局范围内,在函数内部也是错误写法。
namespace A
{
int a = 20;
namespace B
{
int a = 10;
}
}
void test()
{
cout << "A::a :" << A::a << endl;//20
cout << "B::a :" << A::B::a << endl;//10
}
int main()
{
test();
return 0;
}可以嵌套命名空间,但在访问名字时注意作用域。
namespace A
{
int a = 20;
}
namespace A
{
int b = 10;
}
void test()
{
cout << "A::a :" << A::a << endl;//20
cout << "A::a :" << A::b << endl;//10
}
int main()
{
test();
return 0;
}在定义新成员时,编译器会自动将之前的成员与现在定义的合并在一起。
namespace A
{
int b = 10;
void test2();
/* void test2()
{
cout << "A::b :" << A::b << endl;
}
*/
}
void A::test2()
{
cout << "A::b :" << A::b << endl;
}
int main()
{
A::test2();//10
return 0;
}这里注意必须要使用作用域符号,否则该函数是被认为未在该空间的。
定义无名的命名空间这里编译器默认为只在该源文件内部可以使用,相当于c中static修饰只能在内部链接,失去了外部连接属性。
但再在定义变量时注意不能与无命名空间里的重命名,否则无法判断,认为是重定义了。
namespace verylongname
{
int a = 10;
void fun()
{
cout << "haha" << endl;
}
}
namespace A = verylongname;
int main()
{
A::fun();
cout << "A::a :" << A::a << endl;
return 0;
}#include <iostream>
using namespace std;
namespace A
{
int a = 10;
void out()
{
cout << "haha" << endl;
}
}
int main()
{
using namespace A;
cout << "A::a为" <<a<< endl;//10
out();//haha
return 0;
}我么也可以声明各个成员再使用:
namespace A
{
int a = 10;
void out()
{
cout << "haha" << endl;
}
}
int main()
{
using A::a;
using A::out;
cout << "A::a为" <<a<< endl;//10
out();//haha
return 0;
}#include <iostream>
using namespace std;
namespace nameA
{
int a = 10;
void foo()
{
cout << "hello using" << endl;
}
}
void test01()
{
//注意: 当using声明的标识符和其他同名标识符有作用域的冲突时,会产生二义性
int a = 100;
using nameA::a;
using nameA::foo;
cout << a << endl;
cout << a << endl;
cout << a << endl;
foo();
}
int main()
{
test01();
return 0;
}编译器不知道该变量a到底是属于哪一个a,编译器会报错using声明导致多次声明该变量。
因此最安全的方法是通过作用符号来访问命名空间成员。
namespace A
{
void func()
{
}
void func(int x)
{
}
int func(int x, int y)
{
}
}
void test()
{
using A::func;
//因为它们重名,这里访问了空间里的所有函数
//编译器根据参数或类型,返回来行等看是哪一个函数
}这里不会产生二义性,但函数一定是有区别的。
这里需要总要说明两点:
void foo(x,y)
{
return 100;
}
void test01()
{
foo(1);
foo(1, 2);
foo(1,2,3);
}
void foo(x, y) // 编译器报错 形参没有类型
{
return 100; //编译器报错 没有返回值但是返回了
}
void test01()
{
foo(1);//实参的个数和形参的个数不一致
foo(1, 2);
foo(1, 2, 3);//实参的个数和形参的个数不一致
}我们在c++中函数名可以重复,编译器会根据函数的返回类型,参数的类型,参数的个数来确定你是其中那一个函数,因此必须要写。
void test02()
{
char * p = malloc(100);
}void test02()
{
char * p = (char*)malloc(100);
}
struct student
{
int age;
string name;
char sex;
};
int main()
{
student A={10,"zhansan",'nan'};
cout << "A学生的年龄为:" << A.age << endl;//10
return 0;
}其次还有不同
struct student
{
int age;
string name;
char sex;
void setname(string newname)
{
name = newname;
}
void steage(int newage)
{
age = newage;
}
};
int main()
{
student A={10,"zhansan",'nan'};
cout << "A学生的年龄为:" << A.age << endl;//10
A.setname("lisi");
cout << "A学生的姓名为:" << A.name << endl;
return 0;
}这里我们可以学习到关于string函数的一个认识,
string str:生成空字符串
string s(str):生成字符串为str的复制品
string s(str, strbegin,strlen):将字符串str中从下标strbegin开始、长度为strlen的部分作为字符串初值
string s(cstr, char_len):以C_string类型cstr的前char_len个字符串作为字符串s的初值
string s(num ,c):生成num个c字符的字符串
string s(str, stridx):将字符串str中从下标stridx开始到字符串结束的位置作为字符串初值
eg:
string str1; //生成空字符串
string str2("123456789"); //生成"1234456789"的复制品
string str3("12345", 0, 3);//结果为"123"
string str4("012345", 5); //结果为"01234"
string str5(5, '1'); //结果为"11111"
string str6(str2, 2); //结果为"3456789"void test04()
{
// bool类型的变量只有两个值 true false
//true 和false 可以直接当成常量来用
bool flag = true;
)
c++中返回变量,可以被修改,c语言返回常量无法被修改。//三目运算符
void test05()
{
int a = 10;
int b = 20;
printf("%d\n", a < b ? a : b);
//在c语言中三目运算符返回的是表达式的值,是一个常量
//(a < b ? a : b) = 100; 编译报错
*(a < b ?&a :&b) = 100;
}//三目运算符
void test05()
{
int a = 10;
int b = 20;
printf("%d\n", a < b ? a : b);
//在c++语言中三目运算符返回的是变量
(a < b ? a : b) = 100;//编译可通过
}
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我想这样组织C源代码:+/||___+ext||||___+native_extension||||___+lib||||||___(Sourcefilesarekeptinhere-maycontainsub-folders)||||___native_extension.c||___native_extension.h||___extconf.rb||___+lib||||___(Rubysourcecode)||___Rakefile我无法使此设置与mkmf一起正常工作。native_extension/lib中的文件(包含在native_extension.c中)将被完全忽略。
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
这个问题有两个部分。在RubyProgrammingLanguage一书中,有一个使用模块扩展字符串对象和类的示例(第8.1.1节)。第一个问题。为什么如果您使用新方法扩展类,然后创建该类的对象/实例,则无法访问该方法?irb(main):001:0>moduleGreeter;defciao;"Ciao!";end;end=>nilirb(main):002:0>String.extend(Greeter)=>Stringirb(main):003:0>String.ciao=>"Ciao!"irb(main):004:0>x="foobar"=>"foobar"irb(main):
假设我们有A、B、C类。Adefself.inherited(sub)#metaprogramminggoeshere#takeclassthathasjustinheritedclassA#andforfooclassesinjectprepare_foo()as#firstlineofmethodthenrunrestofthecodeenddefprepare_foo#=>prepare_foo()neededhere#somecodeendendBprepare_foo()neededhere#somecodeendend如您所见,我正在尝试将foo_prepare()调用注入
显然在Test::Unit中没有assert_false。您将如何通过扩展断言并添加文件config/initializers/assertions_helper.rb来添加它?这是最好的方法吗?我不想修改test/unit/assertions.rb。顺便说一句,我不认为这是多余的。我使用的是assert_equalfalse,something_to_evaluate。这种方法的问题是很容易意外使用assertfalse,something_to_evaluate。这将始终失败,不会引发错误或警告,并且会在测试中引入错误。 最佳答案
这个问题在这里已经有了答案:Unabletoinstallgem-Failedtobuildgemnativeextension-cannotloadsuchfile--mkmf(LoadError)(17个答案)关闭9年前。嘿,我正在尝试在一台新的ubuntu机器上安装rails。我安装了ruby和rvm,但出现“无法构建gemnative扩展”错误。这是什么意思?$sudogeminstallrails-v3.2.9(没有sudo表示我没有权限)然后它会输出很多“获取”命令,最终会出现这个错误:Buildingnativeextensions.Thiscouldtakeawhi
我在引擎样式插件中有一些代码,其中包含一些模型。在我的应用程序中,我想扩展其中一个模型。通过在初始值设定项中包含一个模块,我已经设法将实例和类方法添加到相关模型中。但是我似乎无法添加关联、回调等。我收到“找不到方法”错误。/libs/qwerty/core.rbmoduleQwertymoduleCoremoduleExtensionsmoduleUser#InstanceMethodsGoHere#ClassMethodsmoduleClassMethodshas_many:hits,:uniq=>true#nomethodfoundbefore_validation_on_crea
我正在尝试将Ruby1.9.3应用程序升级到2.0,除了一个小问题外,一切似乎都很顺利。我写了一个模块,我将其包含在我的模型中以覆盖activerecorddestroy。它将现有的destroy方法别名为destroy!,然后覆盖destroy以更改记录上的deleted_at时间戳。仅当我升级到ruby2.0时,destroy!不再破坏记录,但其行为就像我的新覆盖方法一样。知道为什么会这样吗?下面是更相关的代码部分。完整要点here.defself.included(base)base.class_evaldoalias_method:destroy!,:destroyalia