最近看了好多关于暴力破解的博客,其中用的最多的工具就是bp了,但是好多都是一上来给了执行步骤,却没有对爆破的这几个模式选择进行解释,所以今天萌新写个纪录,来阐明这四个模式的区别和作用
单字典(只有一个字典)
1.Sniper:按顺序一个一个参数依次遍历,一个参数遍历完,然后恢复成原数据,再遍历下一个参数。
2.Battering ram:每个参数同时遍历同一个字典。
一个相当于单挑,一个相当于群殴。
多字典(有多少参数就有多少字典)
1.Pitchfork:多个参数同时进行遍历,只是一个选字典1,一个选字典2(相当于50m赛跑同时出发,只是赛道不同)
2.Cluster bomb:有点像两个嵌套的for循环,参数i和参数j,i=0,然后j要从0-10全部跑完,然后i=1,然后j再从0-10跑完,一对多,多次遍历
作为比较常用的模式,Sniper的作用是对其中选定的参数一个一个依次遍历字典并且替换然后测试

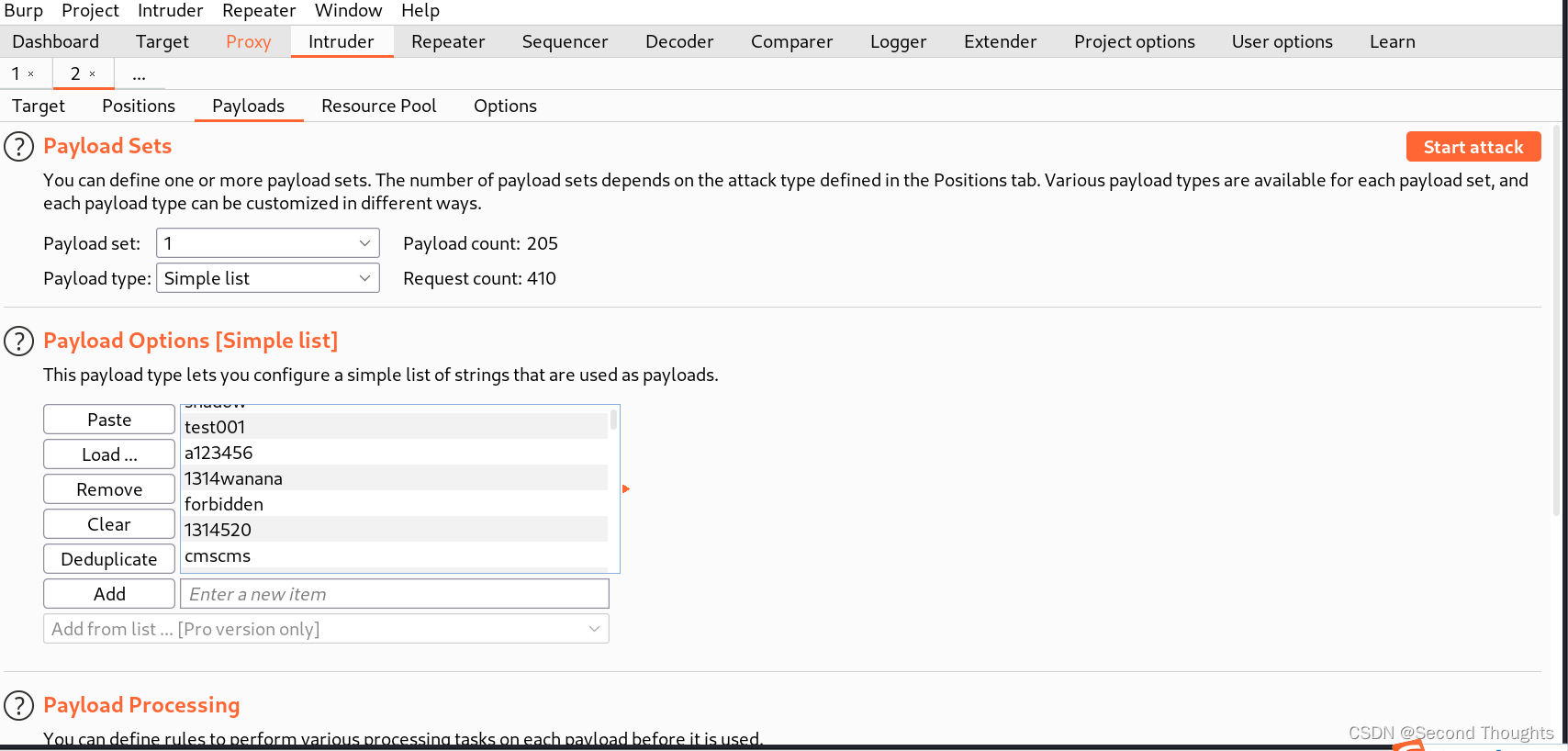
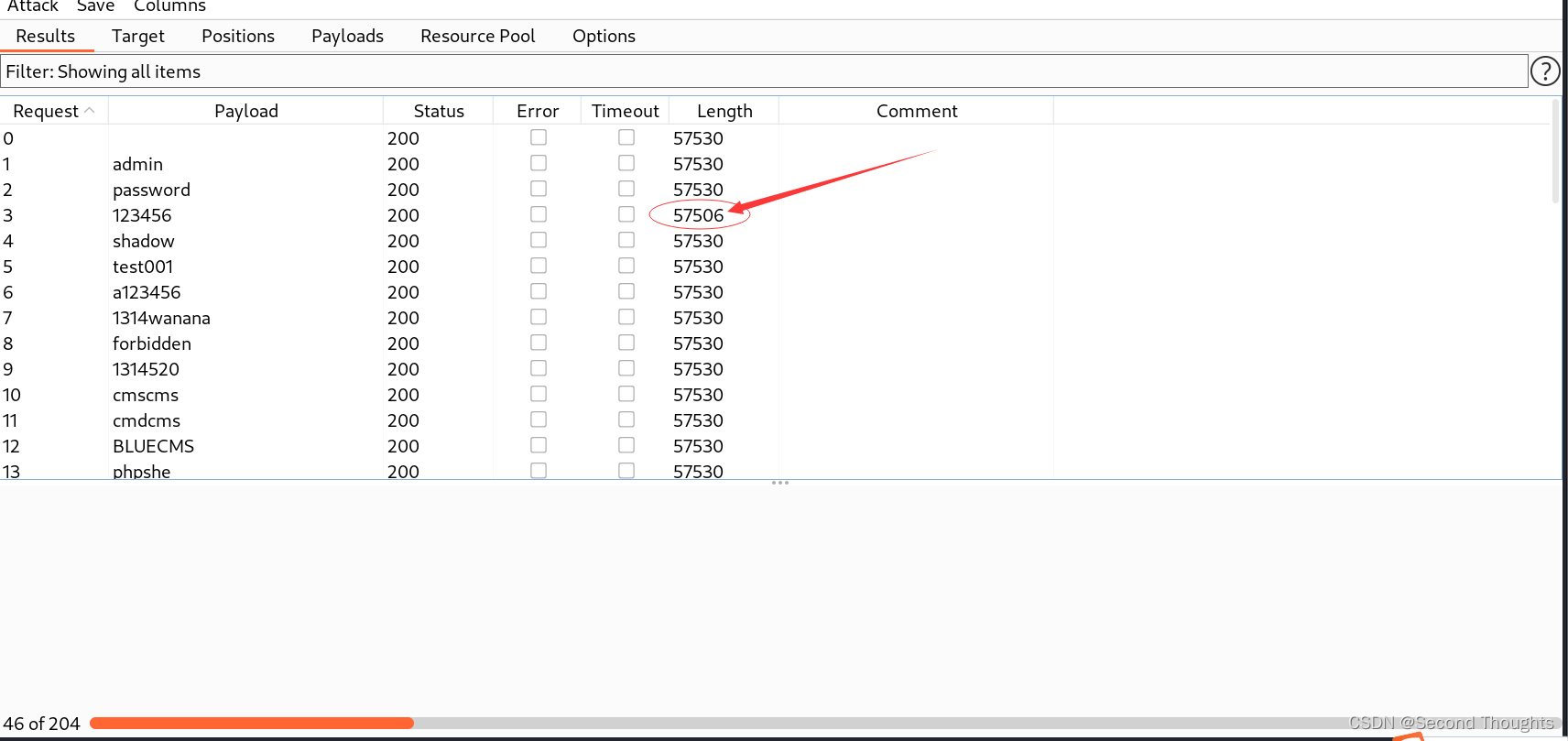
不同于sniper,Battering ram是两个参数同时进行遍历一个字典的
1.首先选择Battering ram模式,然后选择username和password两个参数。
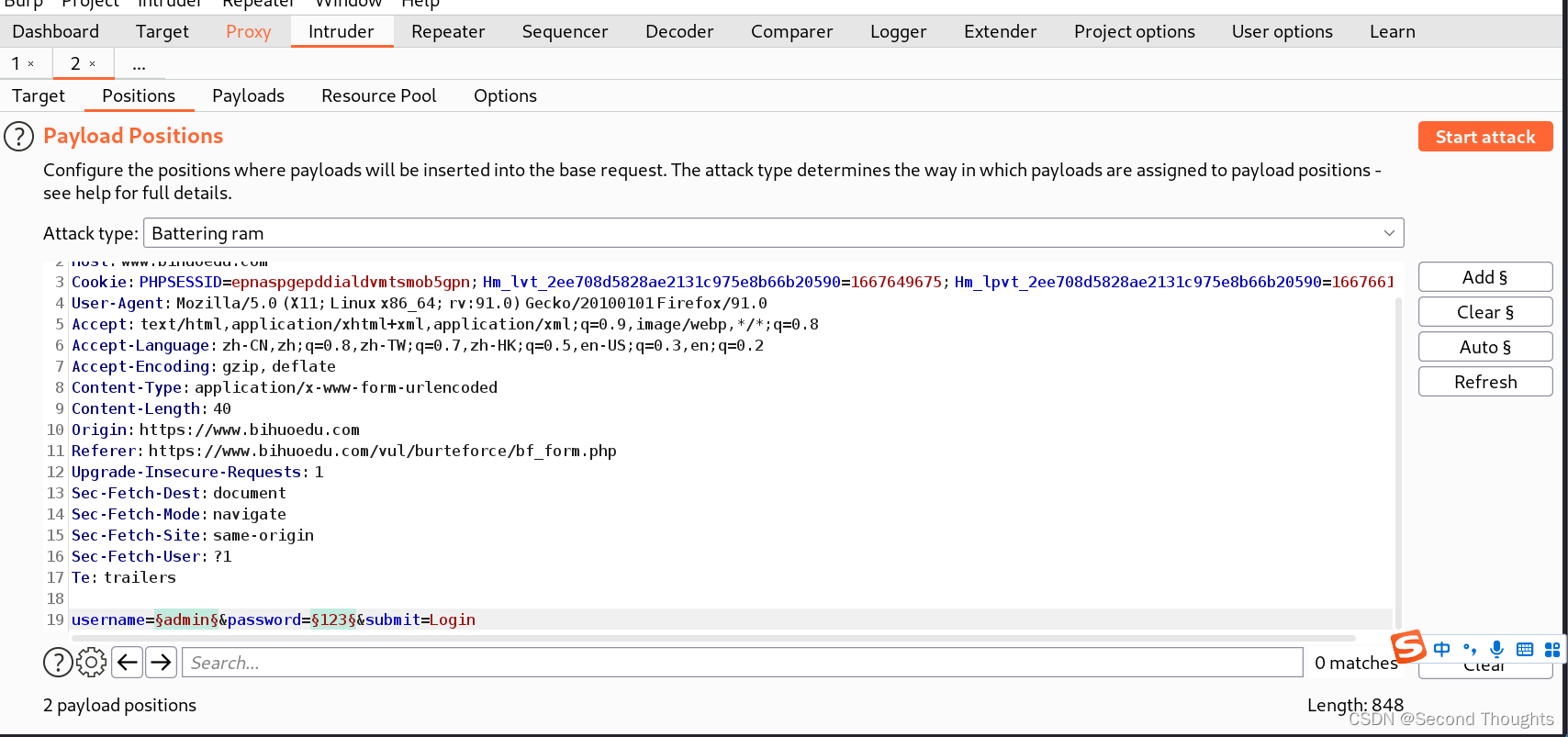
2.然后字典还是之前的字典,然后start attack,我们不难发现,username和password都变成一样的了。
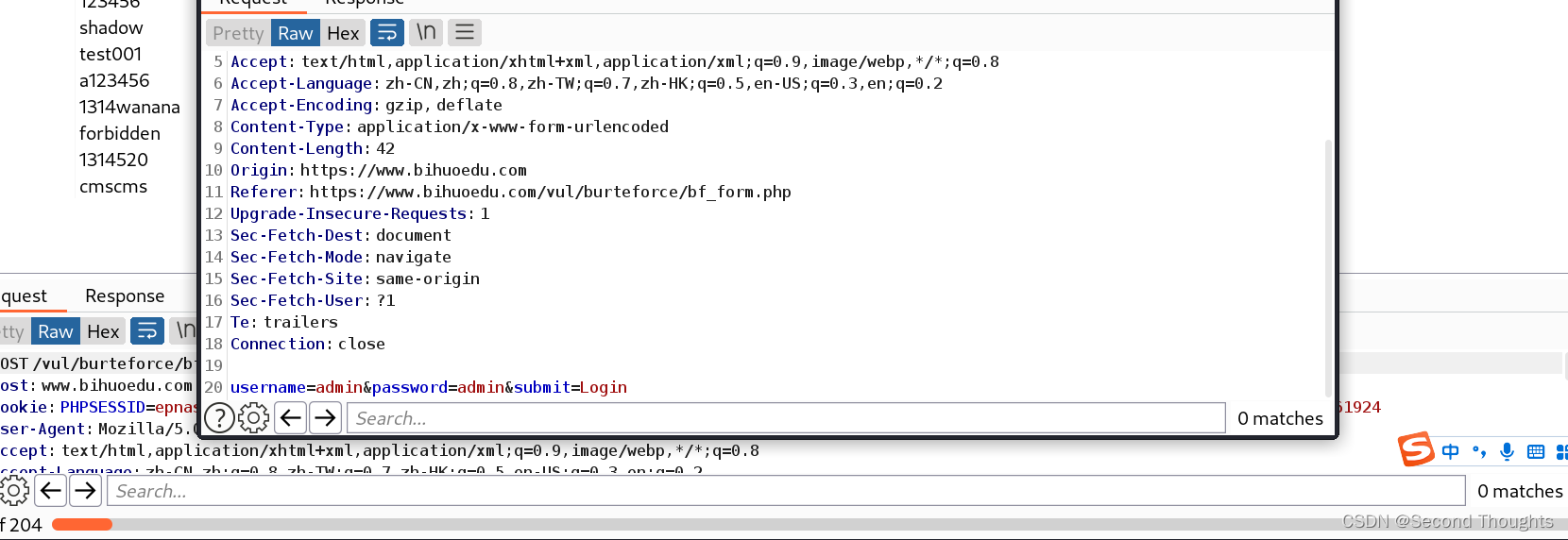
但是这种爆破在实际过程中是很不合理的,应为基本不会有人将用户名和密码设置成一样的,就像大多数人不会将qq密码设置成qq号一样。
Pitchfork作为多字典,他的特点也非常明显,就是多个字典同时进行,与Battering ram有些相似之处,但是一个是多个人跑一个赛道,而一个是多个人,各有各的赛道。
1.这里我们选择Pitchfork模式,标记username和password两个参数
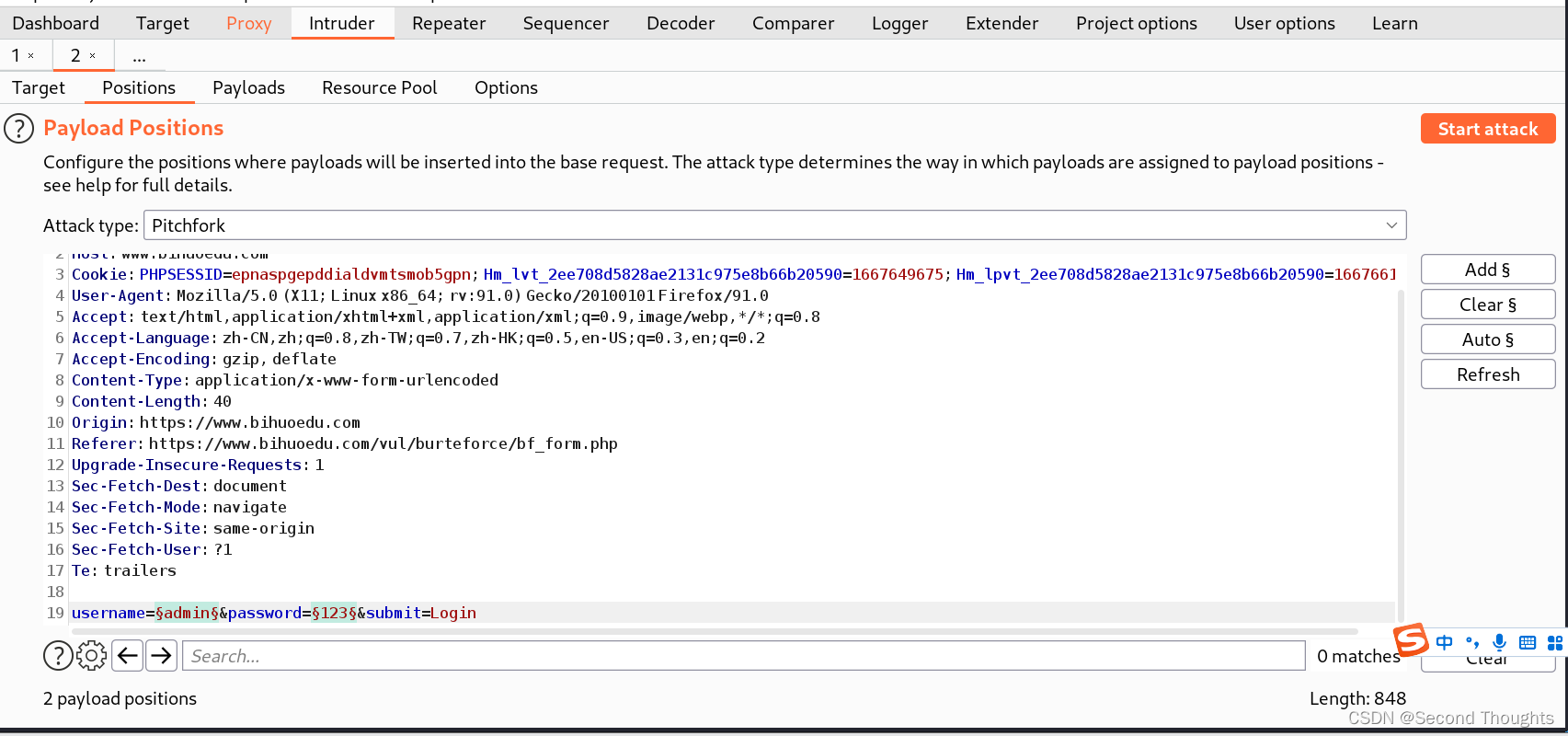
2.发现payload set有两个字典了,我们一开始对字典1已经进行了设置,所以这里我们要对字典二进行设置,但是注意两个字典不能是一样的,否则那就和Battering ram模式一样了。
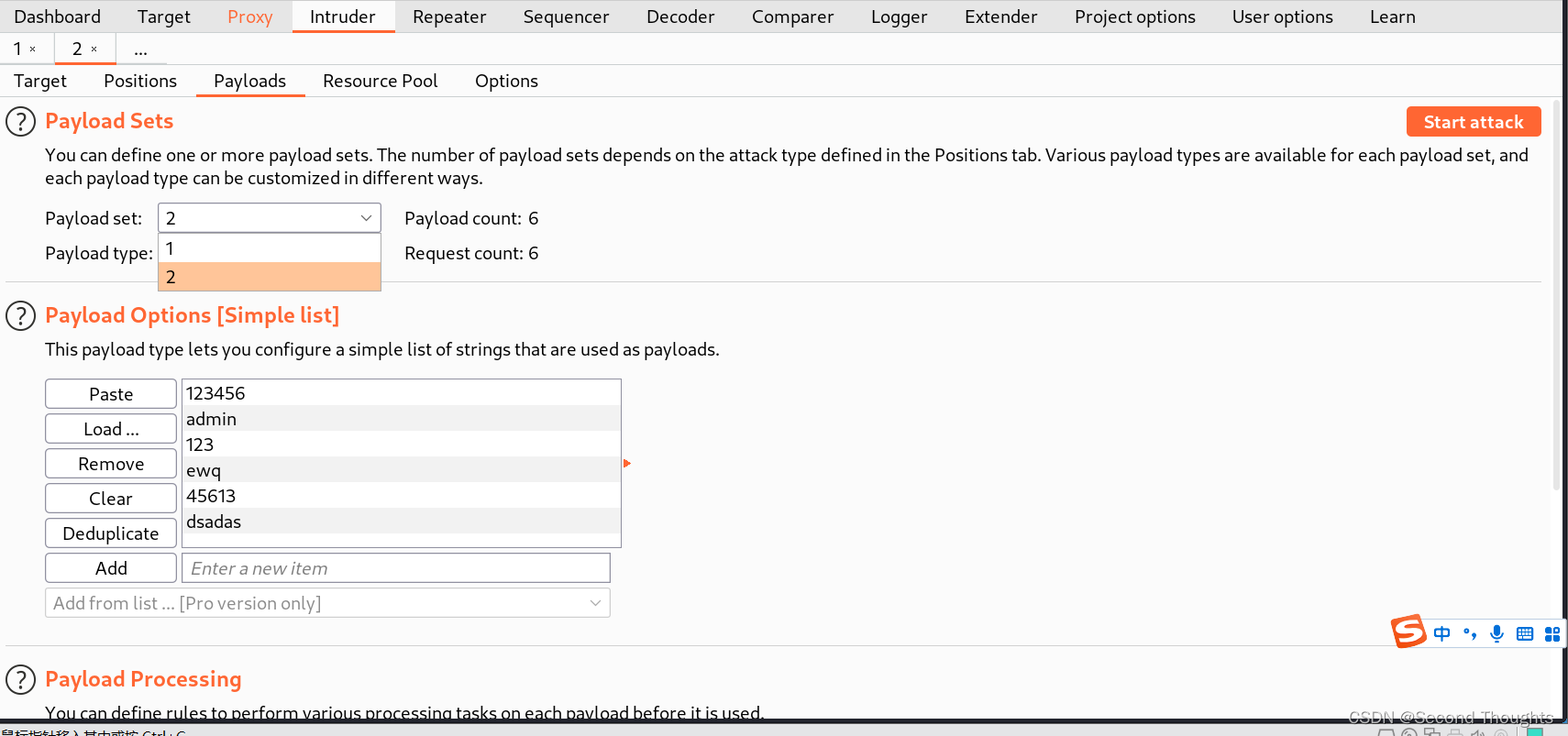
3.然后start attack,回显成功
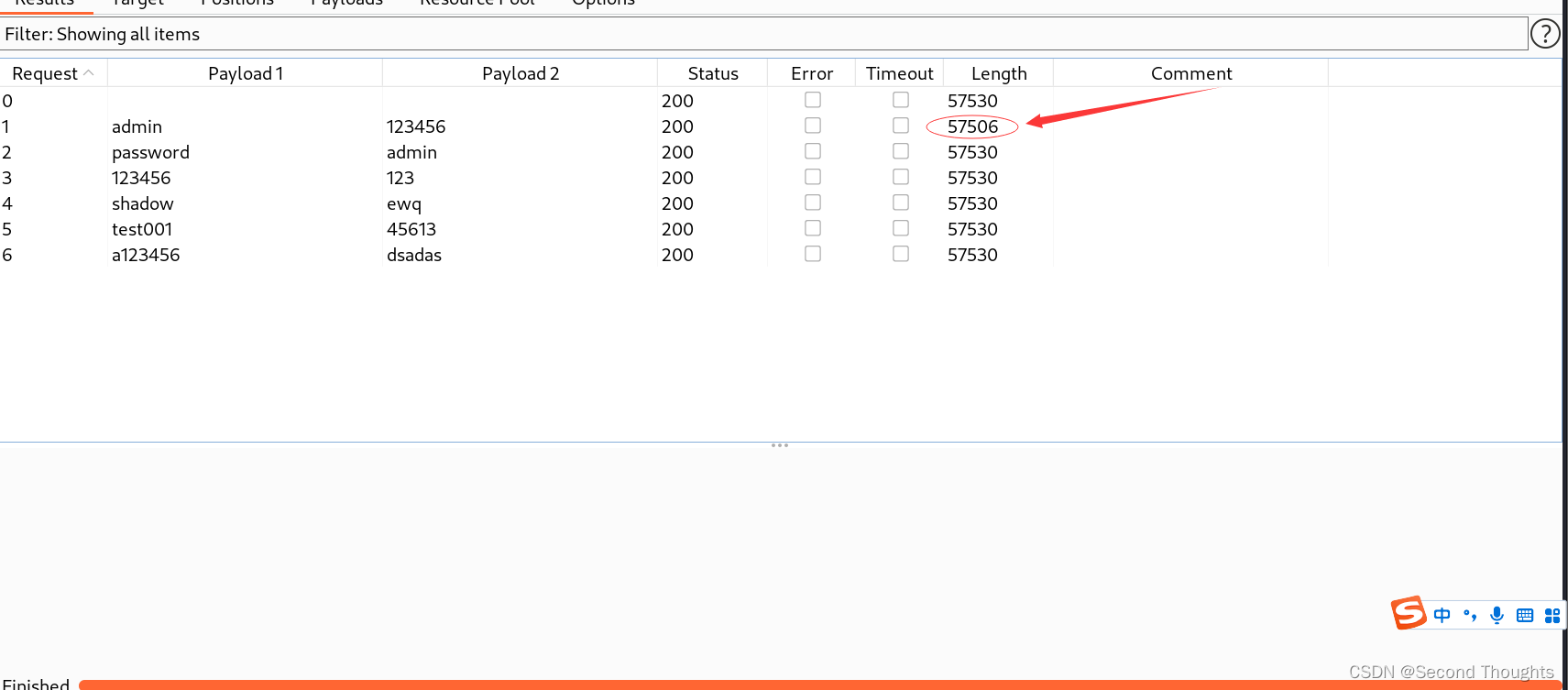
在实际的情况中,这种也依然不是很科学,因为大部分爆破爆破都只是会回显username or password error,这种一对一的爆破依然是意义不大的。
看了前面的三种模式,大伙儿是不是都觉得能够解决的破解情景都很局限呢,而Cluster bomb兼备了前面三种模式的所有的功能,那就是全部遍历,不放过所有情况,但是在超大字典的情况下,运算能力就限制了Cluster bomb模式的发挥,所以只要算力足够,那爆破出密码就不是问题。
1.选定参数,选择Cluster bomb模式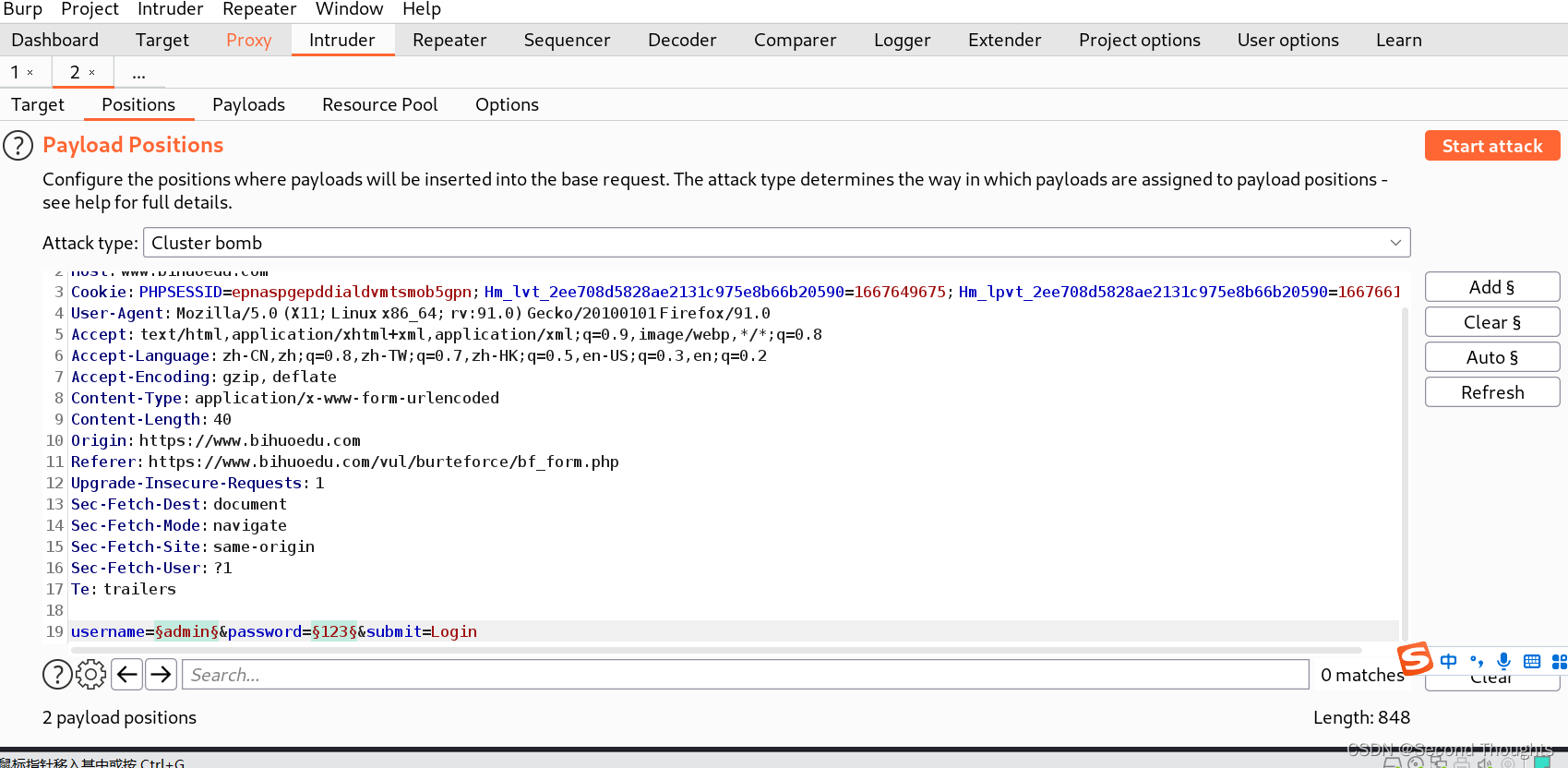
2.这里的字典2我就选择与字典一样的,因为会全部遍历,这里我删减了一下字典,主要演示一下这个模式的遍历方式
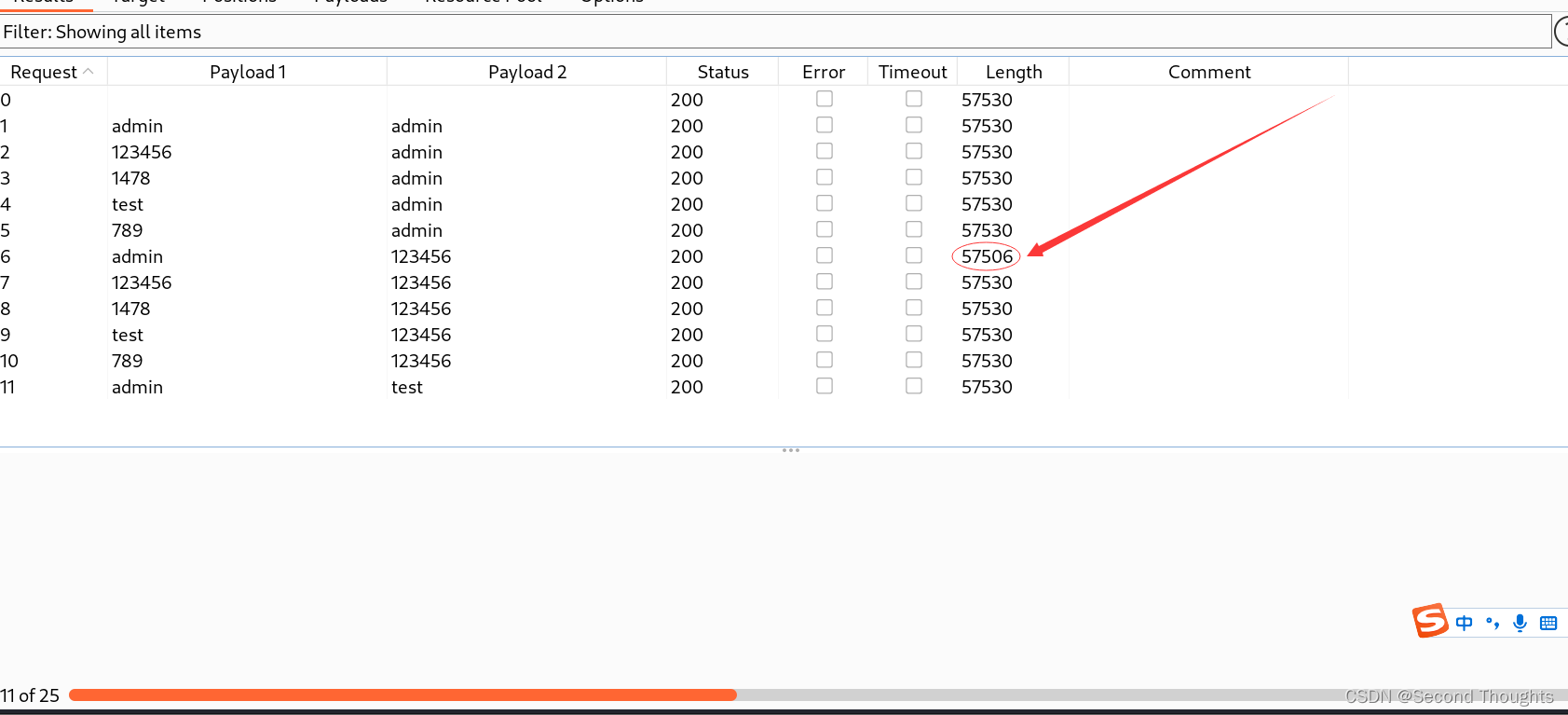
这就是所有的模式解析,萌新才开始学,大佬勿喷QAQ
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah