目录
🌳3. Lock(Java api提供的一个锁,后续在锁策略中介绍)
我们目前所知当一个变量n==0,n++了1000次并且 n--了1000次,我们的预期结果为0,但是当两个线程分别执行++和--操作时最后的结果是否为0呢?
看这样一段代码:
public class ThreadSafe {
private static int n = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for(int i = 0;i < 1000;i++){
n++;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for(int i = 0;i < 1000;i++){
n--;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(n);
}
}
看一下分别运行3次的结果:



从结果上看都没有达到我们的预期结果,因为两个线程同时操作一个共享变量时,这其中就涉及到线程安全问题
我们所知单线程下n++和n--同时执行1000次时结果为0,多线程下大部分不为0,所以我们简单定义为在多线程下和单线程下执行相同的操作结果相同时为线程安全
对于多个线程,操作同一个共享数据(堆里边的对象,方法区中的数据,如静态变量):
如果都是读操作,也就是不修改值,这时不存在安全问题
如果至少存在写操作时,就会存在线程安全问题
一组操作(一行或多行代码)是不可拆分的最小执行单位,就表示这组操作是具有原子性的
多个线程多次的并发并行的对一个共享变量操作时,该操作就不具有原子性
看这样一个例子,如下图:

这最终导致的结果是一张票被售卖了两次,这样就具有很大的风险性
注意:我们在写的一行Java代码可能不是原子性的,因为它编译成字节码,或者由JVM把字节码翻译为机器码后就不是一行,也就是多条执行操作
典型的n++,n--操作:

经过一次n++,n--操作后发现结果不为-1,原因是因为一次++或者--操作是分三步执行:
🍁从内存把数据读到CPU
🍁对数据进行更新操作
🍁再把更新后的操作写入内存
多个线程工作的时候都是在自己的工作内存中(CPU寄存器)来执行操作的,线程之间是不可见的
1. 线程之间的共享变量存在主内存
2. 每一个线程都有自己的工作内存
3. 线程读取共享变量时,先把变量从主存拷贝到工作内存(寄存器),再从工作内存(寄存)读取数据
4. 线程修改共享变量时,先修改工作内存中的变量值,再同步到主内存
举例子说明上述问题:
public class Demo {
private static int flag = 0;
public static void main(String[] args) {
Thread t = new Thread(() -> {
while(flag == 0){
}
System.out.println("t线程执行完毕");
});
t.start();
Scanner sc = new Scanner(System.in);
flag = sc.nextInt();
System.out.println("main线程执行完毕");
}
} 结果:flag的值已经不为0,但是t线程还没执行结束,因为t线程读flag读的是寄存器中的0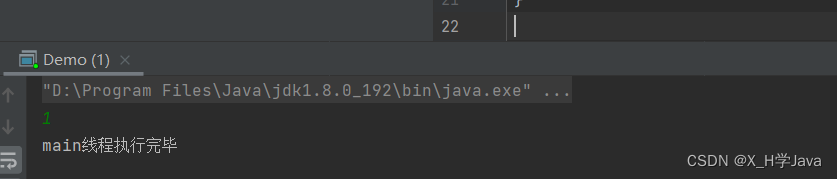
🍬为什么要保证可见性?
把保证每次读取变量的值时都从主存获取最新的值
🍬了解重排序:
JVM翻译字节码指令,CPU执行机器码指令,都可能发生重排序来优化执行效率
比如有这样三步操作:(1) 去前台取U盘 (2) 去教室写作业 (3) 去前台取快递
JVM会对指令优化,也就是重排序,新的顺序为(1)(3)(2),这样来提高效率
1. 线程是抢占式的执行,线程间的调度充满了随机性
2. 多个线程对同一个变量进行修改操作
3. 对变量的操作不是原子性的
4. 内存可见性导致的线程安全
5. 指令重排序也会影响线程安全
1. 修饰普通方法,也叫同步实例方法
public synchronized void doSomething(){
//...
}等同于
public void doSomething(){
synchronized (this) {
//...
}
}2. 修饰静态方法,也叫静态同步方法
public static synchronized void doSomething(){
//...
}等同于
public static void doSomething(){
synchronized (A.class) {
//...
}
}3. 修饰代码块
需要显示指定对哪个对象加锁(Java中任意对象都可以作为锁对象)
synchronized (对象) {
//...
}sychronized是基于对象头加锁的,特别注意:不是对代码加锁,所说的加锁操作就是给这个对象的对象头里设置了一个标志位
一个对象在同一时间只能有一个线程获取到该对象的锁
sychronized保证了原子性,可见性,有序性(这里的有序不是指指令重排序,而是具有相同锁的代码块按照获取锁的顺序执行)
1. 互斥性
synchronized 会起到互斥效果, 某个线程执行到某个对象的 synchronized 中时, 其他线程如果也执行到同一个对象 synchronized 就会阻塞等待
进入 synchronized 修饰的代码块, 相当于 加锁
退出 synchronized 修饰的代码块, 相当于 解锁
看下图理解加锁过程:

阻塞等待:
针对每一把锁, 操作系统内部都维护了一个等待队列. 当这个锁被某个线程占有的时候,其他线程尝试进行加锁, 就加不上了,就会阻塞等待, 一直等到之前的线程解锁之后, 由操作系统唤醒一个新的线程, 再来获取到这个锁
2. 刷新主存
synchronized的工作过程:
🍃获得互斥锁
🍃从主存拷贝最新的变量到工作内存
🍃对变量执行操作
🍃将修改后的共享变量的值刷新到主存
🍃释放互斥锁
3. 可重入性
synchronized是可重入锁
同一个线程可以多次申请成功一个对象锁
可重入锁内部会记录当前的锁被哪个线程占用,同时也会记录一个加“锁次数”,对于第一次加锁,记录当前申请锁的线程并且次数加一,但是后续该线程继续申请加锁的时候,并不会真正加锁,而是将记录的“加锁次数加1”,后续释放锁的时候,次数减1,直到次数减为0才是真的释放锁
可重入锁的意义就是降低程序员负担(使用成本来提高开发效率),代价就是程序的开销增大(维护锁属于哪个线程,并且加减计数,降低了运行效率)
如下情形:

public class ThreadSafe {
private static int n = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for(int i = 0;i < 1000;i++){
synchronized (ThreadSafe.class) {
n++;
}
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for(int i = 0;i < 1000;i++){
synchronized (ThreadSafe.class){
n--;
}
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(n);
}
}
结果:结果为我们预期结果,说明是线程安全的
volatile是用来修饰变量的,它的作用是保证可见性,有序性
注意:不能保证原子性,对n++,n--来说,用volatile修饰n也是线程不安全的
· 代码在写入 volatile 修饰的变量的时候,改变线程工作内存中volatile变量副本的值将改变后的副本的值从工作内存刷新到主内存
· 代码在读取 volatile 修饰的变量的时候,从主内存中读取volatile变量的最新值到线程的工作内存中
从工作内存中读取volatile变量的副本
使用场景:
读操作:读操作本身就是原子性,所以使用volatile就是线程安全的
写操作:赋值操作是一个常量值(写到主存),也保证了线程安全
用volatile修饰变量n看是否线程安全:
public class ThreadSafe {
private static volatile int n = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for(int i = 0;i < 1000;i++){
n++;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for(int i = 0;i < 1000;i++){
n--;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(n);
}
}
结果:也是不是线程安全的

我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
在Ruby中是否有Gem或安全删除文件的方法?我想避免系统上可能不存在的外部程序。“安全删除”指的是覆盖文件内容。 最佳答案 如果您使用的是*nix,一个很好的方法是使用exec/open3/open4调用shred:`shred-fxuz#{filename}`http://www.gnu.org/s/coreutils/manual/html_node/shred-invocation.html检查这个类似的帖子:Writingafileshredderinpythonorruby?