目录
3.5 扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要删除该文件
3.7 扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
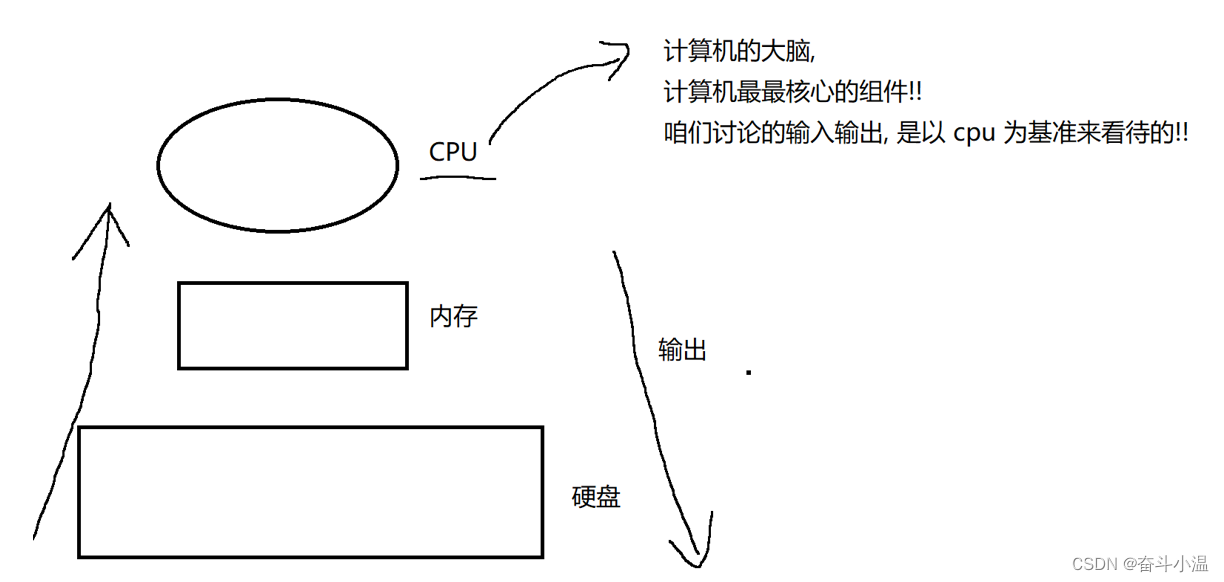
✨平时谈论到“文件”,指的是硬盘上的文件
硬盘(外存) 和内存 相比:
1.速度:内存比硬盘快很多
2.空间:内存空间比硬盘小
3.成本:内存比硬盘贵
4.持久化:内存掉电后数据丢失,外存掉电后数据还在
🌈路径:文件系统上一个文件/目录,具体位置

🍀文件系统是以 树型 结构来组织文件和目录的————N叉数
文件目录:从根结点出发,沿着数叉一路往下走到达目标文件,此时这中间经过的内容就目录

实际表示路径,是通过一个字符串来表示,每一个字符串,每一个目录之间使用 \\ 或者 / 来分割
绝对路径:从盘符开始,一层一层往下找,这个过程,得到的路径
相对路径:从给定的某个目录(一定要明确,基准目录是什么),一层一层往下找,这个过程得到的路径

. 表示相对路径,是一个特殊符号,表示当前目录
.. 表示当前目录的上级目录
相对路径,一定要明确工作目录(基准目录)是什么
文件系统上,任何一个文件对应的路径是唯一的;不会存在两个路径相同,但是文件不同的情况
在 Linux 可能存在一个文件有两个不同的路径能找到它;在 Windows 上不存在, Windows 上可以认为,路径 和 文件 是一一对应的
路径就相当于一个文件的“身份标识”
1️⃣文本文件:存储的是文本(文本文件的内容都是有 ASCII 字符构成的);文本文件里存储的数据,就是遵守 ASCII 或者其他字符集编码(例如 utf8),所得到的文件,本质上存的是字符(不仅仅是 char)
2️⃣二进制文件:存储的是二进制数据(存储没有任何字符集的限制)
例如:文本文件:txt,.java .c 二进制文件:.class .exe jpg mp3
简单粗暴的判定方式:
直接使用笔记本(是按照文本的方式来解析现实的)开某个文件,如果看到的内容能看懂就是文本文件;看不懂,乱糟糟的就是二进制文件
文件系统操作例如创建文件,删除文件,重命名文件,创建文件...
🔥Java 标准库给我们提供了 File 这个类
1️⃣构造 File 对象
构造的过程中,可以使用 绝对路径/相对路径 进行初始化,这个路径指向的文件,可以是真实存在的,也可以是不存在的
//可以通过 File 对象进行操作
File file = new File("d:/cat.jpg");//这个文件可以存在,也可以不存在2️⃣File 提供了一些方法

//可以通过 File 对象进行操作
File file = new File("d:/cat.jpg");//这个文件可以存在,也可以不存在
System.out.println(file.getParent());//d:\
System.out.println(file.getName());//cat.jpg
System.out.println(file.getPath());//d:\cat.jpg
System.out.println(file.getAbsolutePath());//d:\cat.jpg
System.out.println(file.getCanonicalPath());//D:\cat.jpg
public static void main(String[] args) throws IOException {
//在相对路径中,./通常是可以省略
File file = new File("./hello_world.txt");//如果不存在这个路径
System.out.println(file.exists());//false
System.out.println(file.isDirectory());//false
System.out.println(file.isFile());//false
//创建文件
file.createNewFile();
System.out.println(file.exists());//true
System.out.println(file.isDirectory());//false
System.out.println(file.isFile());//true
file.deleteOnExit();
System.out.println(file.exists());//false
} 
IDEA 工作目录就是想录所在目录;写相对路径,就是以 File_IO 这一级为基准,开展开的
import java.io.File;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
File dir = new File("some-dir"); // 要求该目录不存在,才能看到相同的现象
System.out.println(dir.isDirectory());//false
System.out.println(dir.isFile());//false
System.out.println(dir.mkdir());//true
System.out.println(dir.isDirectory());//true
System.out.println(dir.isFile());//false
}
}import java.io.File;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
File dir = new File("some-parent\\some-dir"); // some-parent 和 somedir 都不存在
System.out.println(dir.isDirectory());//false
System.out.println(dir.isFile());//false
System.out.println(dir.mkdir());//false
System.out.println(dir.isDirectory());//false
System.out.println(dir.isFile());//false
}
}mkdir() 的时候,如果中间目录不存在,则无法创建成功; mkdirs() 可以解决这个问题。
import java.io.File;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
File dir = new File("some-parent\\some-dir"); // some-parent 和 somedir 都不存在
System.out.println(dir.isDirectory());//false
System.out.println(dir.isFile());//false
System.out.println(dir.mkdirs());//true
System.out.println(dir.isDirectory());//true
System.out.println(dir.isFile());//false
}
}import java.io.File;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
File file = new File("some-file.txt"); // 要求 some-file.txt 得存在,可以是普通文件,可以是目录
File dest = new File("dest.txt"); // 要求 dest.txt 不存在
System.out.println(file.exists());//true
System.out.println(dest.exists());//false
System.out.println(file.renameTo(dest));//true
System.out.println(file.exists());//false
System.out.println(dest.exists());//true
}
}针对文件内容进行读和写
对文本文件,提供了一组类 统称为 “字符流”(典型代表:Reader,Writer)
针对二进制文件,提供了一组类,统称为“字节流”(典型代表:InputStream,OutputStream)
每种流,又分为两种:1️⃣输入的: Reader, InputStream 2️⃣输出的: Writer, OutputStream
InputStream 只是一个抽象类,要使用还需要具体的实现类
构造方法:

InputStream inputStream = null;
try {
//这个过程相当于 C 中 的 fopen,文件的打开操作
inputStream = new FileInputStream("d:/test.txt");
} finally {
///关闭操作非常重要
//如果忘了,可能会带走年终奖甚至工作
inputStream.close();//稳健执行到关闭
}
//执行中间,出现一些文艺,比如说 return 或者 抛异常,就会导致 close 执行不到,所以使用 finally 来执行❎这样的代码写的很丑,其实是一个很大的问题
✅以下代码是一个正确的选择
try (InputStream inputStream = new FileInputStream("d:/test.txt");) {
}try with resources———带有资源的 try 操作,会在 try 代码块结束,自动执行 close 操作
因为 InputStream 实现了一个特定的 inferface Closeable

1️⃣无参数的 read,相当于一次读一个字节 ,返回 -1 代表已经完全读完了
try (InputStream inputStream = new FileInputStream("d:/test.txt")) {
//读文件
//无参数的 read,相当于一次读一个字节,但是返回类型是 int,返回 -1 代表已经完全读完了
while (true) {
int b = inputStream.read();
if (b == -1) {
//读到末尾了,结束循环即可
break;
}
System.out.println(b);
}
}第一种——输出结果:(假设 txt 里存放 hello world)

使用的是 字节流,每次读的不是字符,而是字节;出的这一串数据,就是每个字符的 ASCII 码
第二种——输出结果:如果存放的是汉字(假设 txt 里存放 你好世界)

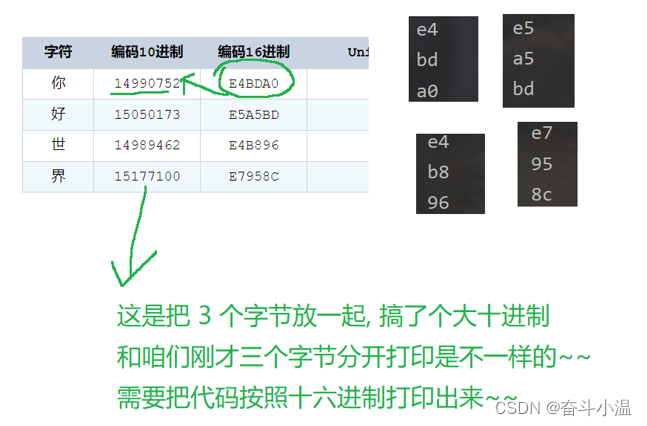
4个汉字,12个字节(每个数字是一个字节);每个汉字3个字节====》utf8 编码的
2️⃣read(byte[] b) ——最多读取 b.length 字节的数据到 b 中,返回实际读到的数 量;-1 代表以及读完了
3️⃣read(byte[] b, int off, int len) ——最多读取 len - off 字节的数据到 b 中,放在从 off 开始,返回实际读到的数量;-1 代表以及读完了
1️⃣write(int b) ——写入要给字节的数据
2️⃣write(byte[] b) ——将 b 这个字符数组中的数据全部写入 os 中
3️⃣write(byte[] b, int off, int len) ——将 b 这个字符数组中从 off 开始的数据写入 os 中,一共写 len 个
try (OutputStream outputStream = new FileOutputStream("d:/test.txt")) {
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
} catch (IOException e) {
e.printStackTrace();
}Reader——FileReader Writer——FileWriter
构造方法打开文件:
read 方法读:一次都一个 char 或者 char[ ]
write 方法写:一次写一个char 或者 char[ ] 或者 String
close 关闭
核心逻辑与字节流相同
try (Reader reader = new FileReader("d:/test.txt")) {
while (true) {
int c = reader.read();
if (c == -1) {
break;
}
char ch = (char)c;
System.out.println(ch);
}
} catch (IOException e) {
e.printStackTrace();
}🚩遍历目录,进行文件查找/删除
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class IODemo1 {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.print("请输入要扫描的根目录(绝对路径 OR 相对路径): ");
String rootDirPath = scanner.next();
File rootDir = new File(rootDirPath);
if (!rootDir.isDirectory()) {
System.out.println("您输入的根目录不存在或者不是目录,退出");
return;
}
System.out.print("请输入要找出的文件名中的字符: ");
String token = scanner.next();
List<File> result = new ArrayList<>();
// 因为文件系统是树形结构,所以我们使用深度优先遍历(递归)完成遍历
// scanDir(rootDir, token, result);
System.out.println("共找到了符合条件的文件 " + result.size() + " 个,它们分别是");
for (File file : result) {
System.out.println(file.getCanonicalPath() + "请问您是否要删除该文件?y/n");
String in = scanner.next();
if (in.toLowerCase().equals("y")) {
file.delete();
}
}
}
private static void scanDir(File rootDir, String token, List<File> result) {
File[] files = rootDir.listFiles();
if (files == null || files.length == 0) {
return;
}
for (File file : files) {
if (file.isDirectory()) {
scanDir(file, token, result);
} else {
if (file.getName().contains(token)) {
result.add(file.getAbsoluteFile());
}
}
}
}
}🚩打开两个文件,逐个字节读第一个文件,在把读到的内容逐个字节写入第二个文件
import java.io.*;
import java.util.*;
public class IODemo2 {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.print("请输入要复制的文件(绝对路径 OR 相对路径): ");
String sourcePath = scanner.next();
File sourceFile = new File(sourcePath);
if (!sourceFile.exists()) {
System.out.println("文件不存在,请确认路径是否正确");
return;
}
if (!sourceFile.isFile()) {
System.out.println("文件不是普通文件,请确认路径是否正确");
return;
}
System.out.print("请输入要复制到的目标路径(绝对路径 OR 相对路径): ");
String destPath = scanner.next();
File destFile = new File(destPath);
if (destFile.exists()) {
if (destFile.isDirectory()) {
System.out.println("目标路径已经存在,并且是一个目录,请确认路径是否正确");
return;
}
if (destFile.isFile()) {
System.out.println("目录路径已经存在,是否要进行覆盖?y/n");
String ans = scanner.next();
if (!ans.toLowerCase().equals("y")) {
System.out.println("停止复制");
return;
}
}
}
try (InputStream is = new FileInputStream(sourceFile)) {
try (OutputStream os = new FileOutputStream(destFile)) {
byte[] buf = new byte[1024];
int len;
while (true) {
len = is.read(buf);
if (len == -1) {
break;
}
os.write(buf, 0, len);
}
os.flush();
}
}
System.out.println("复制已完成");
}
}🚩遍历目录,在里边的文件内容中查找
简单粗暴的方法:
1.先去递归的遍历目录,比如给定一个 d:/ 去递归的把这里包含的所有文件都列出来
2.每次找到一个文件都打开,并读取文件内容(得到 String)
3.在判定要查询的词是否在上述文件内容中存在,如果存在,结果即为所求
import java.io.*;
import java.util.Scanner;
public class IODemo3 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
//1.先让用户指定一个要搜索的根目录
System.out.println("请输入要扫描的根目录:");
//创建目录
File rootDir = new File(scanner.next());
//判断是不是目录
if (!rootDir.isDirectory()) {
System.out.println("输入有误,您输入的目录不存在");
return;
}
//2.让用户输入一个要查询的词
System.out.println("请输入要查询的词:");
String word = scanner.next();
//3.递归地进行目录/文件遍历
//目录结构是“N叉树”,书本身就是递归定义的,通过递归的方式来进行处理
scanDir(rootDir, word);
}
private static void scanDir(File rootDir, String word) {
//列出当前的 rootDir 中的内容,没有内容,直接递归结束
File[] files = rootDir.listFiles();//相当于处理根结点
if (files == null) {
//当前 rootDir 是一个空的目录,这里啥都没有,没必要往里递归了
return;
}
//目录里有内容,就遍历目录中的每个元素
for (File f : files) {
System.out.println("当前搜索到:" + f.getAbsolutePath());
if (f.isFile()) {
//是普通文件:打开文件,读取文件,比较看是否包含上述关键词
String content = readFile(f);
if (content.contains(word)) {
System.out.println(f.getAbsolutePath() + "包含要查找的关键字!");
}
} else if (f.isDirectory()) {
//是目录:进行递归
scanDir(f, word);//以当前 f 这个目录作为起点,在搜索里面的内容
} else {
//不是普通文件,也不是1根目录,直接跳过(例如以 Linux:1.普通文件2.目录文件3.管道文件.....)
continue;
}
}
}
//直接一个字符一个字符的读出来,统一拼装即可
private static String readFile(File f) {
//读取文件的整个内容,返回出来:使用字符流来读,由于匹配的是字符串,此处只能按照字符流处理才有意义
StringBuilder stringBuilder = new StringBuilder();
try (Reader reader = new FileReader(f)) {
//一次读一个字符,把读到的结果给拼装到 StringBuilder 中,统一转换成 String
while (true) {
int c = reader.read();
if (c == -1) {
break;
}
//读到的不是-1,那就是char
stringBuilder.append((char)c);
}
} catch (IOException e) {
e.printStackTrace();
}
return stringBuilder.toString();
}
}我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只