 IDLE(集成开发学习环境Integrated Development and Learning Environment)是一个 Python IDE,由 Python 语言本身编写,在 Windows 中通常作为 Python 安装 的一部分而安装。它是初学者的理想选择,使用起来很简单。对于那些正在学习 Python 的人,比如学生,它可以作为一个很好的 IDE 来开始使用。语法高亮、智能识别和自动补全等基本功能是这个 IDE 的一些特点。你可以随时在官方 文档 中了解更多关于 IDLE 的功能。
IDLE(集成开发学习环境Integrated Development and Learning Environment)是一个 Python IDE,由 Python 语言本身编写,在 Windows 中通常作为 Python 安装 的一部分而安装。它是初学者的理想选择,使用起来很简单。对于那些正在学习 Python 的人,比如学生,它可以作为一个很好的 IDE 来开始使用。语法高亮、智能识别和自动补全等基本功能是这个 IDE 的一些特点。你可以随时在官方 文档 中了解更多关于 IDLE 的功能。sudo apt updatesudo apt install idle3Yes。命令完成后,IDLE 将被安装在你的 Ubuntu 系统中。对于 Fedora、RHEL、CentOS,使用下面的命令来安装它:sudo dnf updatesudo dnf install idle3sudo pacman -S python tk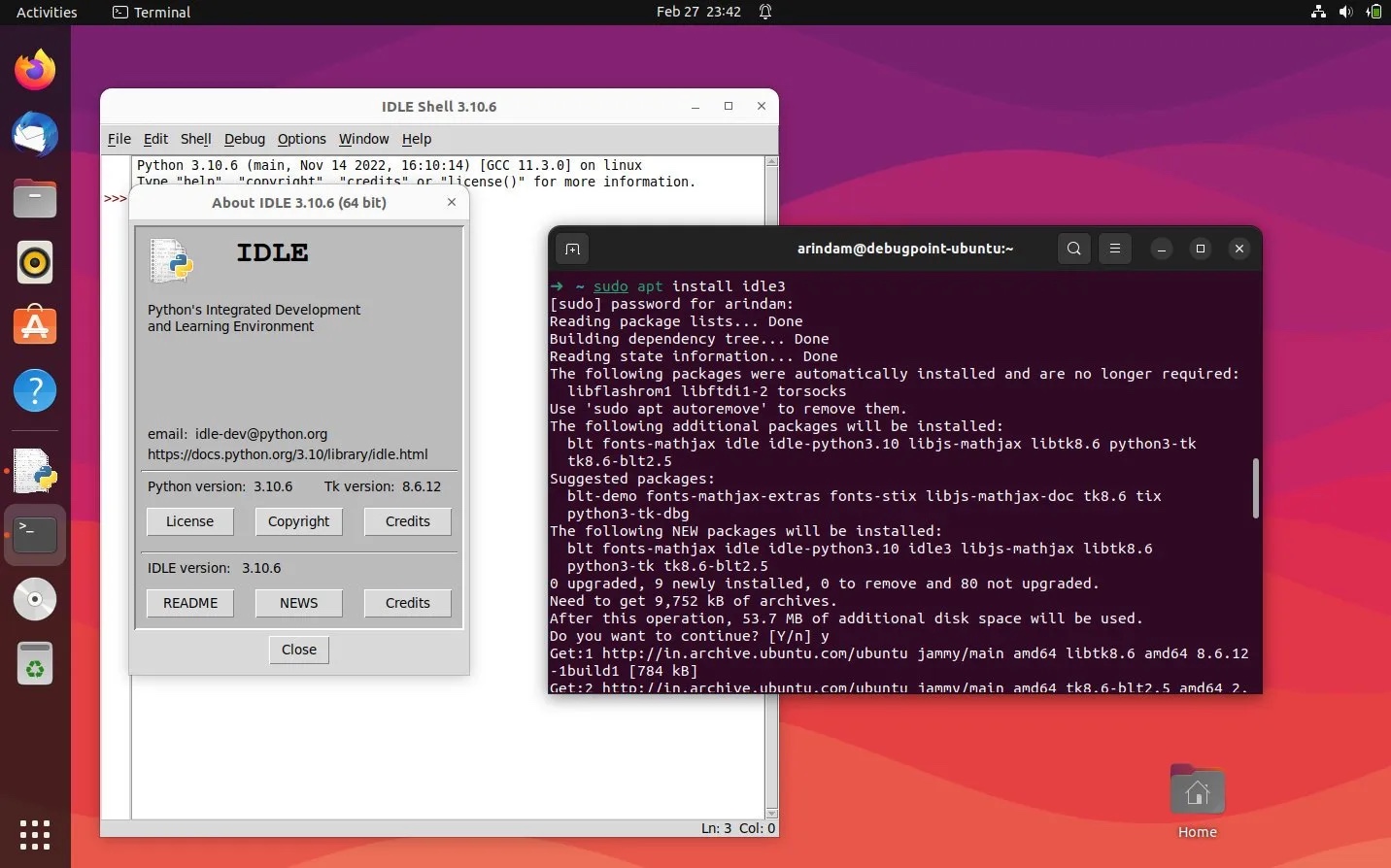 IDLE 在 Ubuntu 的安装和运行
IDLE 在 Ubuntu 的安装和运行 应用菜单中的 IDLE 图标如果你使用的是 Arch Linux,你需要在命令行中运行以下内容来启动 IDLE:
应用菜单中的 IDLE 图标如果你使用的是 Arch Linux,你需要在命令行中运行以下内容来启动 IDLE:idle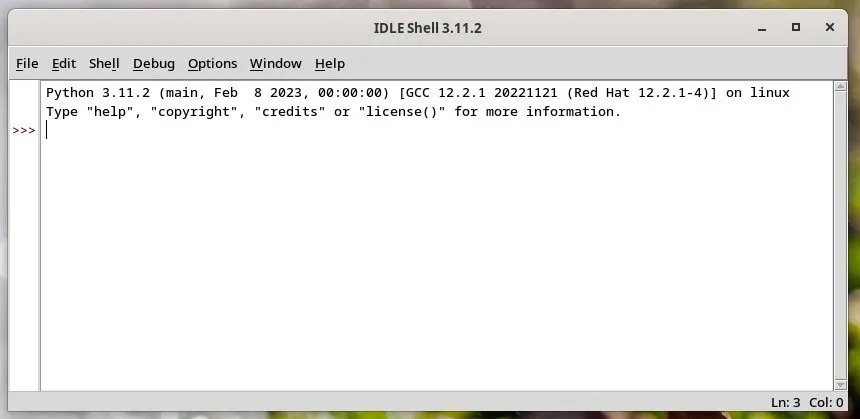 IDLE 编辑器主窗口默认情况下,它会显示一个 交互界面Shell,你可以直接在每一行中执行 Python 代码。它的工作方式和任何 Shell 解释器一样。而当你点击回车键时,你会得到输出,还有三个
IDLE 编辑器主窗口默认情况下,它会显示一个 交互界面Shell,你可以直接在每一行中执行 Python 代码。它的工作方式和任何 Shell 解释器一样。而当你点击回车键时,你会得到输出,还有三个 > 符号进入下一行,执行下一个命令。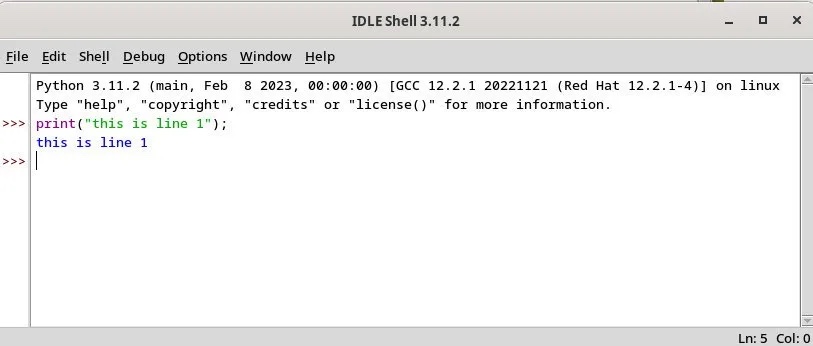 在 IDLE 中运行一个简单的 Python 语句IDLE 也允许你从它的文件菜单中打开任何 .py 文件。它将在一个单独的窗口中打开该文件,在那里你可以进行修改并直接运行它。你可以使用
在 IDLE 中运行一个简单的 Python 语句IDLE 也允许你从它的文件菜单中打开任何 .py 文件。它将在一个单独的窗口中打开该文件,在那里你可以进行修改并直接运行它。你可以使用 F5 或者从选项 “运行Run > 运行模块Run Module” 来运行。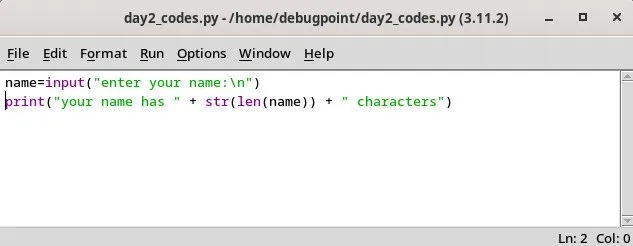 从 IDLE 中打开的一个 Python 文件
从 IDLE 中打开的一个 Python 文件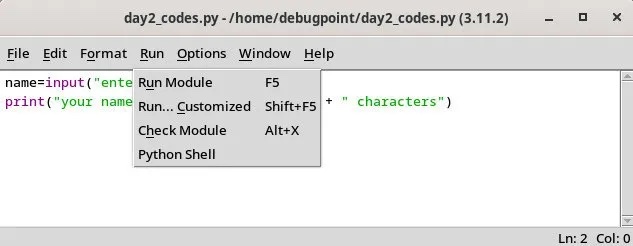 使用菜单运行该文件的选项输出会显示在一个单独的输出窗口中。在输出窗口中,你可以开始调试,进入一行或文件,查看堆栈跟踪和其他选项。
使用菜单运行该文件的选项输出会显示在一个单独的输出窗口中。在输出窗口中,你可以开始调试,进入一行或文件,查看堆栈跟踪和其他选项。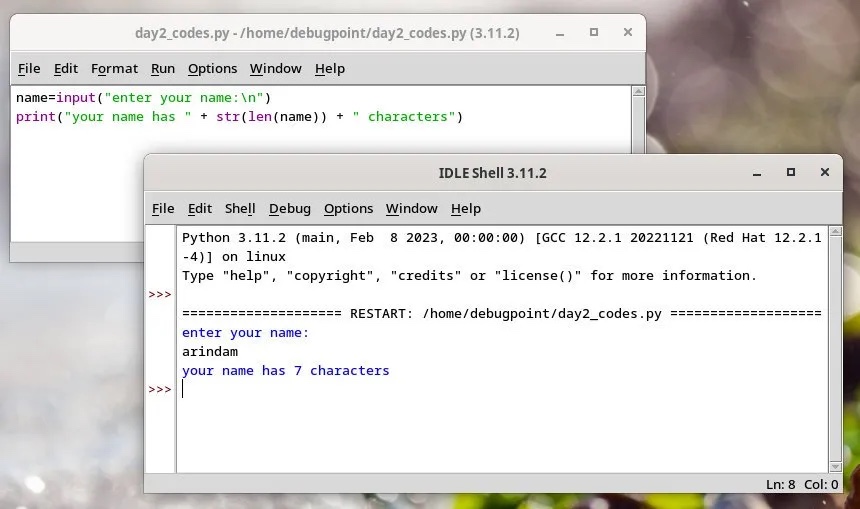 输出显示在 IDLE 的一个单独的输出窗口中
输出显示在 IDLE 的一个单独的输出窗口中我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs