免责声明:
严禁利用本文章中所提到的工具和技术进行非法攻击,否则后果自负,上传者不承担任何责任。
工具下载:
Burp 链接:https://pan.baidu.com/s/16mp0BhUt6edZBx7evDnl6A
提取码:tian
环境下载:
JAVA环境 链接:https://pan.baidu.com/s/1d-RScNZuQYzw0FoUD1ExHg
提取码:tian
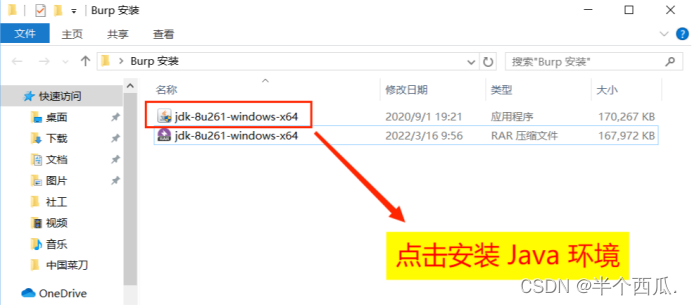






(1)如果你没有对安装路径进行更改的话,那么默认路径就是:C:\Program Files\Java\jdk1.8.0_261
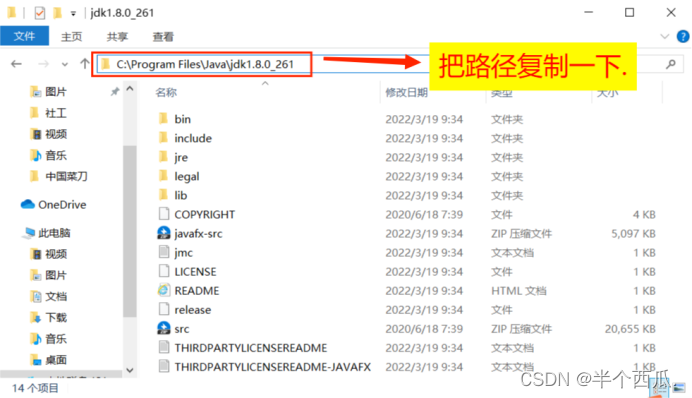
(2)在 此电脑右击 ---> 属性 --> 高级系统设置 --> 环境变量 --> 在系统变量里面(点击新建.)





(3)再回到安装的路径下:C:\Program Files\Java\jdk1.8.0_261 点击 bin 目录


(4)然后回到 环境变量 --> 在系统变量里面(点击 Path 变量,然后点击编辑. )


(5)查看环境变量是否 配置完成,按 win+r 输入 cmd

再命令行里输入:JAVAC

(1)解压 之后.
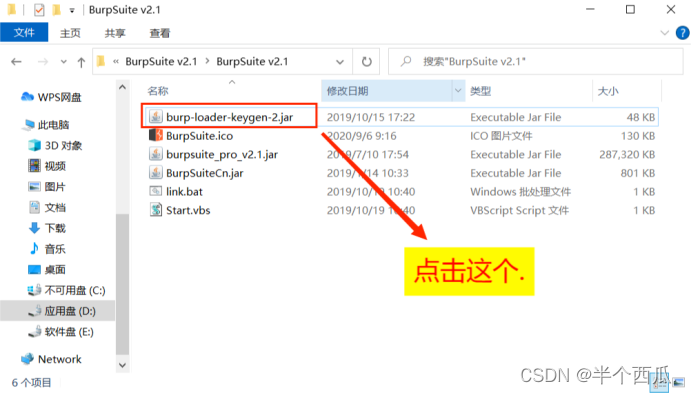

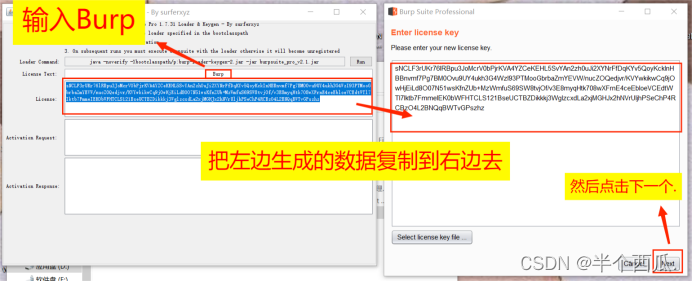
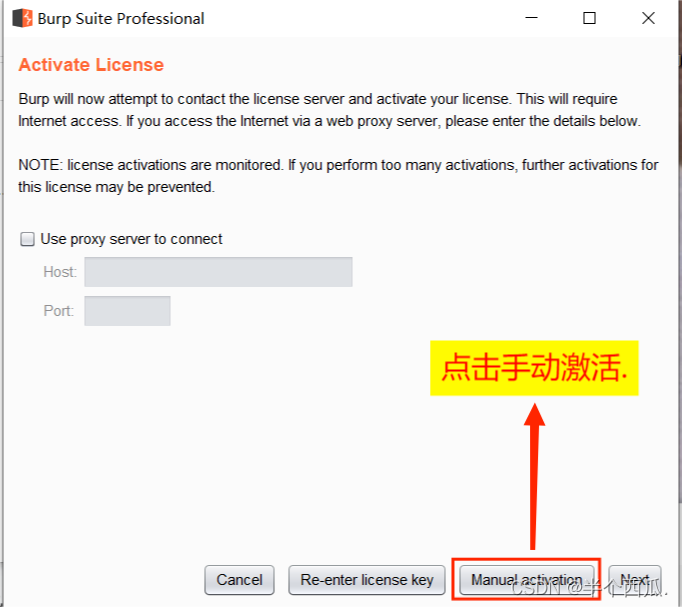
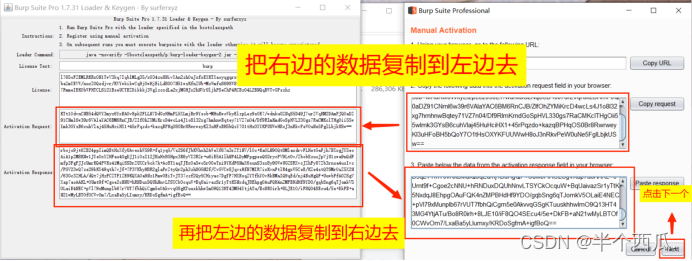
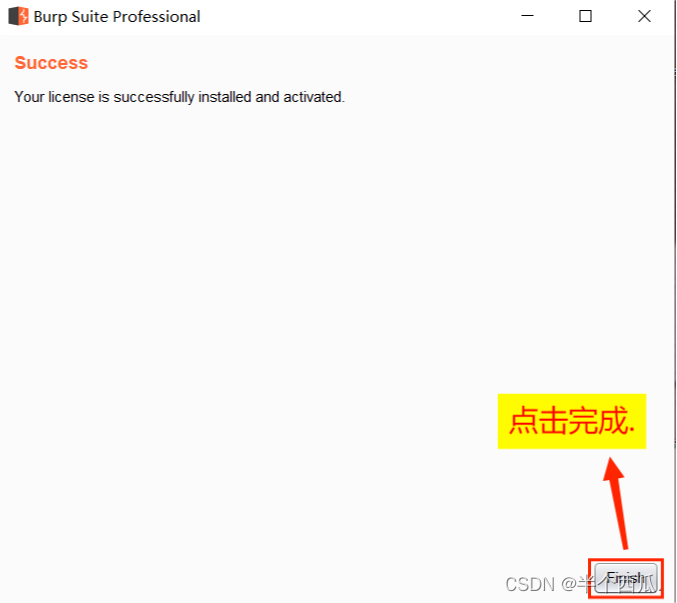
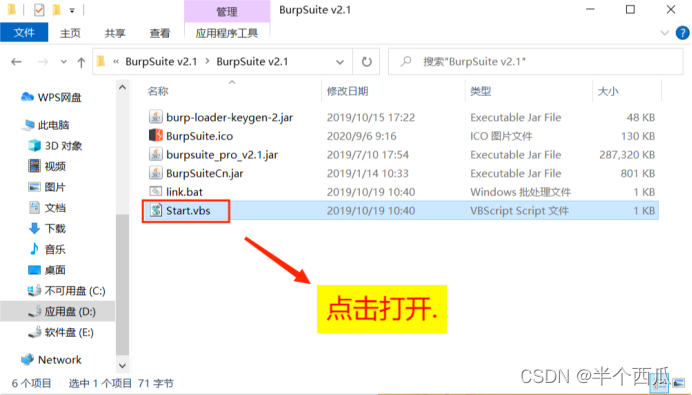
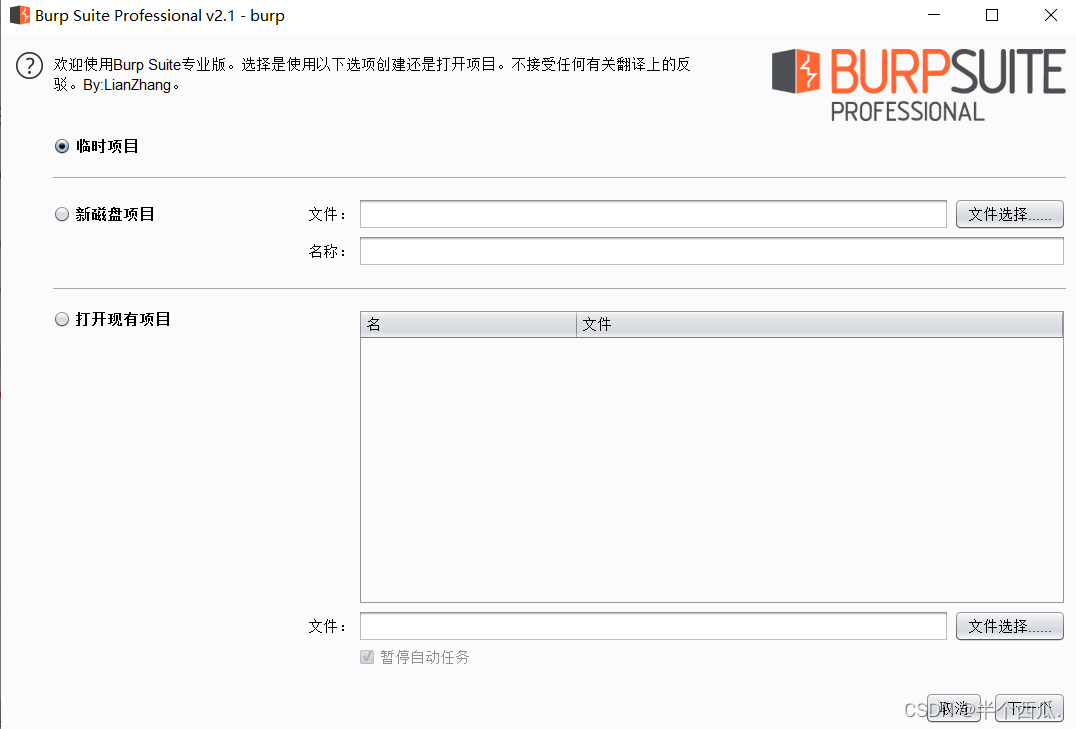
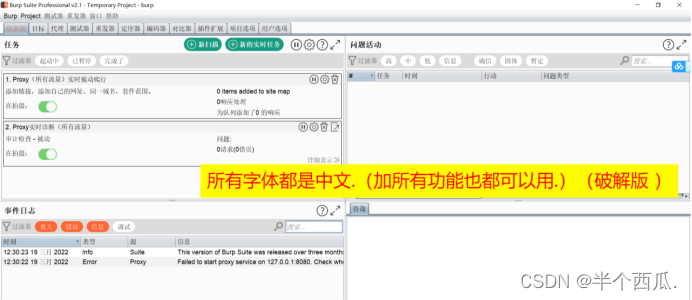
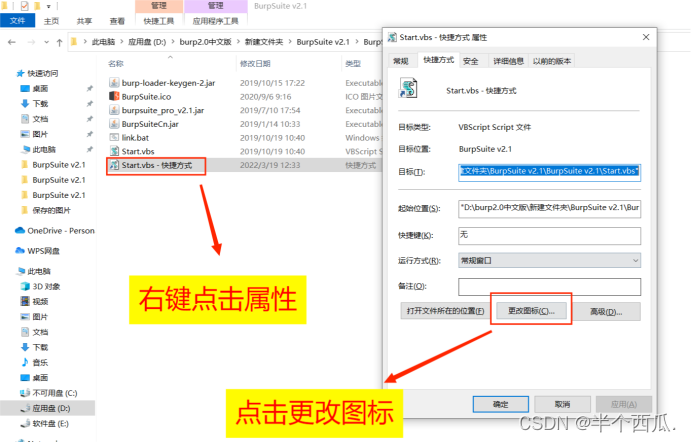
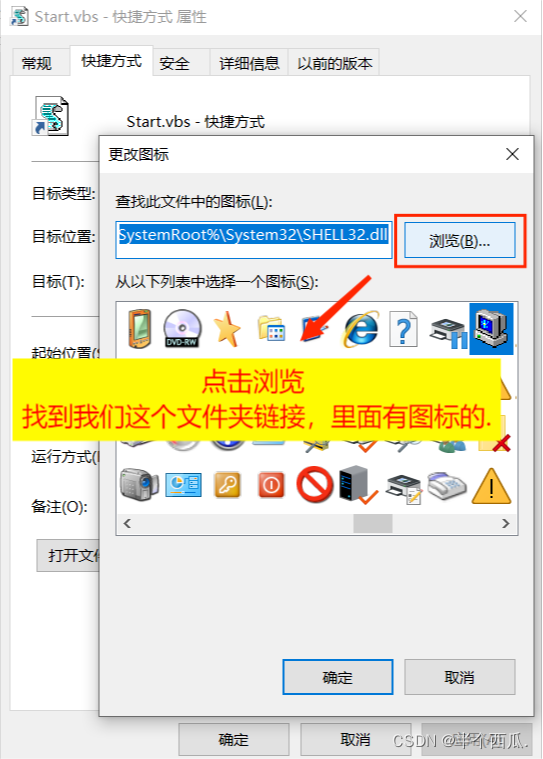
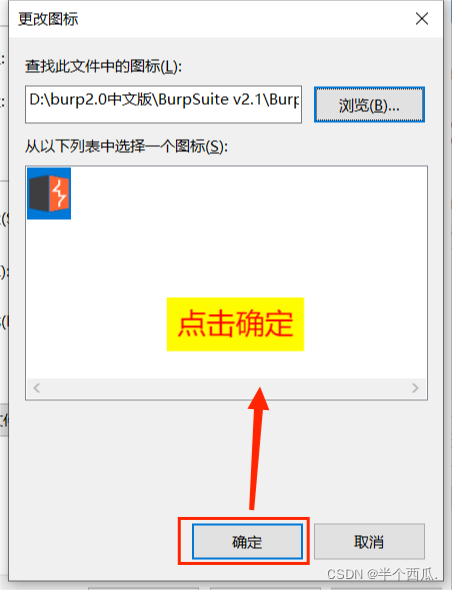
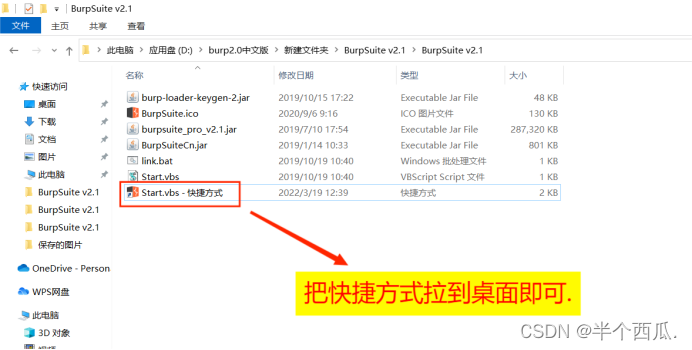
(2)打开 Burp.(中文版 加 破解版)
在Ruby中可以使用哪些替代方法来ping一个ip地址?标准库“ping”库的功能似乎非常有限。我对在这里滚动我自己的代码不感兴趣。有没有好的gem?我应该接受它并忍受它吗?(我在Linux上使用Ruby1.8.6编写代码) 最佳答案 net-ping值得一看。它允许TCPping(如标准rubyping),但也允许UDP、HTTP和ICMPping。ICMPping需要root权限,但其他则不需要。 关于ruby-Pingruby网站?,我们在StackOverflow上找到一个类
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe
在Rails自动生成的功能测试(test/functional/products_controller_test.rb)中,我看到以下代码:classProductsControllerTest我的问题是:方法调用products()在哪里/如何定义?products(:one)到底是什么意思?看代码,大概意思是“创建一个产品”,但是它是如何工作的呢?注意我是Ruby/Rails的新手,如果这些是微不足道的问题,我深表歉意。 最佳答案 如果您查看test/fixtures文件夹,您会看到一个products.yml文件。这是在您创建
在我的一些Controller中,我有一个before_filter检查用户是否登录?用于CRUD操作。application.rbdeflogged_in?unlesscurrent_userredirect_toroot_pathendendprivatedefcurrent_user_sessionreturn@current_user_sessionifdefined?(@current_user_session)@current_user_session=UserSession.findenddefcurrent_userreturn@current_userifdefine
我需要从站点抓取数据,但它需要我先登录。我一直在使用hpricot成功地抓取其他网站,但我是使用mechanize的新手,我真的对如何使用它感到困惑。我看到这个例子经常被引用:require'rubygems'require'mechanize'a=Mechanize.newa.get('http://rubyforge.org/')do|page|#Clicktheloginlinklogin_page=a.click(page.link_with(:text=>/LogIn/))#Submittheloginformmy_page=login_page.form_with(:act
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
如何使用rubyonrails获取网络上某处其他网站的页面数据? 最佳答案 您可以使用httparty只是获取数据示例代码(来自example):requireFile.join(dir,'httparty')require'pp'classGoogleincludeHTTPartyformat:htmlend#google.comredirectstowww.google.comsothisislivetestforredirectionppGoogle.get('http://google.com')puts'','*'*7
我想扫描未知数量的行,直到扫描完所有行。我如何在ruby中做到这一点?例如:putreturnsbetweenparagraphsforlinebreakadd2spacesatend_italic_or**bold**输入不是来自"file",而是通过STDIN。 最佳答案 在ruby中有很多方法可以做到这一点。大多数情况下,您希望一次处理一行,例如,您可以使用whileline=getsend或STDIN.each_linedo|line|end或者通过使用-n开关运行ruby,例如,这意味着上述循环之一(在每次迭代中将
require'pp'p*1..10这会打印出1-10。为什么这么简洁?您还可以用它做什么? 最佳答案 它是“splat”运算符。它可用于分解数组和范围并在赋值期间收集值。这里收集赋值中的值:a,*b=1,2,3,4=>a=1b=[2,3,4]在此示例中,内部数组([3,4])中的值被分解并收集到包含数组中:a=[1,2,*[3,4]]=>a=[1,2,3,4]您可以定义将参数收集到数组中的函数:deffoo(*args)pargsendfoo(1,2,"three",4)=>[1,2,"three",4]