Error: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=2)
整理了网上找到的一些解决方法,希望对大家有所帮助:
在运行sql命令前运行以下命令
set hive.support.concurrency=false;
yarn资源不足,修改hadoop配置文件yarn-site.xml,参数不固定
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<description>default value is 1024</description>
</property>
修改配置文件yarn-site.xml ,参数不固定
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
数据量太大,内存溢出,在运行sql命令前设置参数,参数不固定,根据自身需要修改
# map阶段内存不足
set mapreduce.map.memory.mb=10150;
set mapreduce.map.java.opts=-Xmx6144m;
# reduce阶段内存不足
set mapreduce.reduce.memory.mb=10150;
set mapreduce.reduce.java.opts=-Xmx8120m;
各个节点时间不同步
# 查看集群时间
date
# 同步时间
ntpdate cn.pool.ntp.org
# 或者使用这一条指令
ntpdate -u ntp.api.bz
hadoop版本与hive版本不兼容,建议查一下兼容表确认。
修改配置文件yarn-site.xml
#Yarn可使用的物理内存总量,该值不能大于节点的内存
yarn.nodemanager.resource.memory-mb
#单个任务可申请的物理内存
yarn.scheduler.maximum-allocation-mb
分区数量太多
# 是否允许动态分区
hive.exec.dynamic.partition=true;
# 允许最大的动态分区
hive.exec.max.dynamic.partitions=1000;
# 单个节点允许最大分区
hive.exec.max.dynamic.partitions.pernode=100;
关闭自动装载
set hive.auto.convert.join= false;
hive启动堆栈内存不足
修改配置文件hadoop-env.sh
export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS"
hive下的bin目录下的配置文件hive-config.sh
export HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-2048}
hive执行内存不足
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.dynamic.partition=true;
set hive.exec.parallel=true;
set hive.support.concurrency=false;
set mapreduce.map.memory.mb=4128;
关闭集群,重启虚拟机。
运行hive程序后出现报错,先去查看了hive的日志
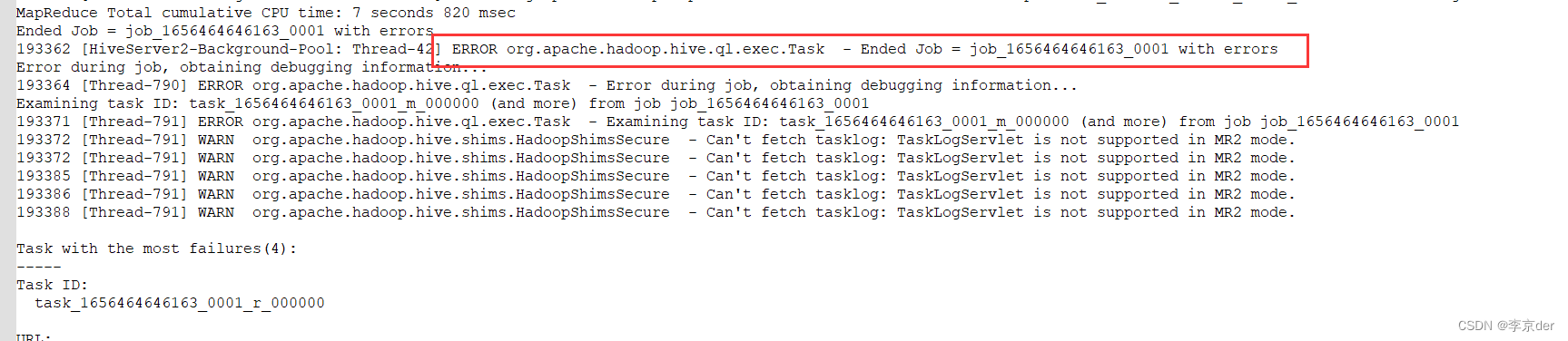
貌似是这个地方出了问题,然后又到ui界面查看job_1656464646163_0001进程
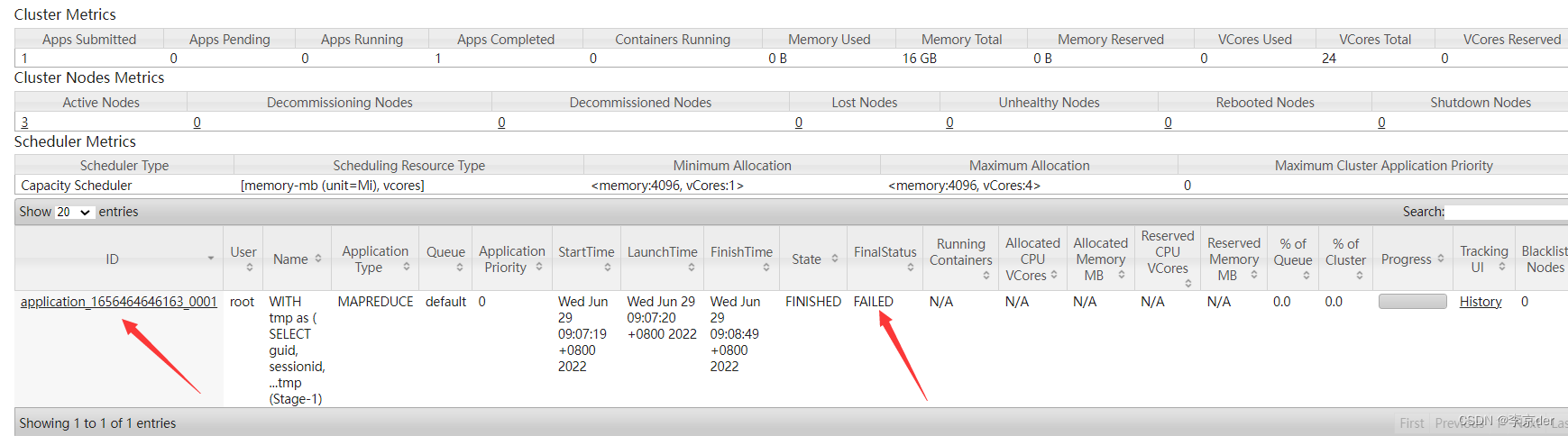
查看他的日志,发现了新问题
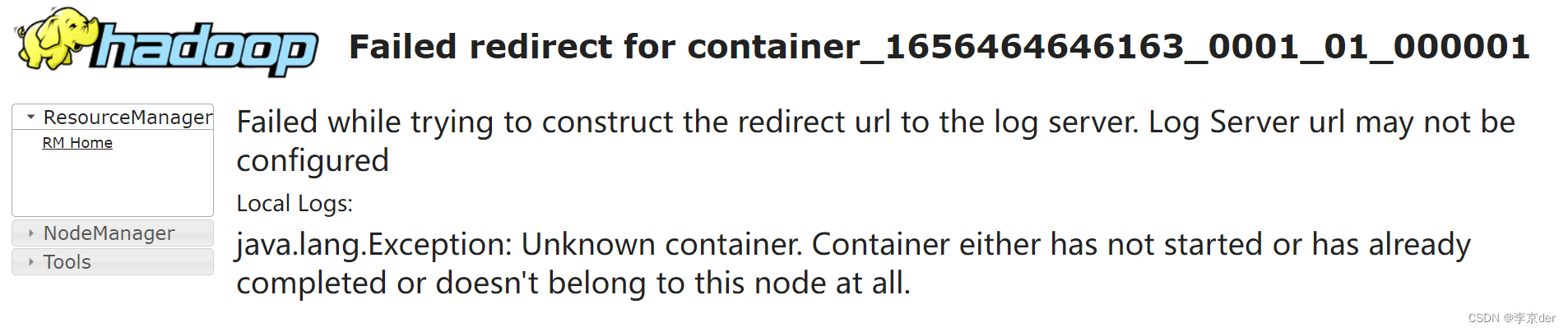
想到了利用命令行查看日志错误
yarn logs -applicationId application_1656464646163_0002
发现问题

导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
更新:当输入“passenger-memory-stats”时,我显示:---Passengerprocesses---Processes:0我该如何解决这个问题?为什么即使我在httpd.conf中添加它并重新启动apache,passenger也不会启动?我无法让PhusionPassenger在服务器上运行RubyonRails。我已经按照Phusion网站上的所有说明安装了passenger并修改并创建了ApacheVirtualHost以指向新目录并验证所有.conf文件都已成功加载。还加载了httpd-Mpassenger_module。我还在本地主机上成功运行了Passe
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
我的带有apache+passenger的Rails应用程序一开始工作得很好。但是,运行一段时间后,遇到如下错误:Theapplicationspawnerserverexitedunexpectedly:Unexpectedend-of-filedetected.我查看了apache的错误日志,发现了这个错误:../gems/passenger-3.0.7/lib/phusion_passenger/utils.rb:716:[BUG]Segmentationfault似乎乘客有内存问题。有人可以帮忙吗?谢谢。 最佳答案 最可能的
虽然我们可以用webrick或mongrel部署它 最佳答案 大多数Ruby应用程序服务器只会运行一个Ruby进程(Ruby有一个全局解释器锁,这使得多线程变得毫无意义),这意味着它一次只能处理一个请求。至少可以说,这不会给你很好的表现。有两种解决方法:运行多个Ruby应用程序服务器并在它们前面放置一个负载平衡器或反向代理,例如Nginx或Apache在一堆Mongrels或瘦服务器前面(您运行的进程数反射(reflect)了您将能够并行处理的请求数)。或者你运行Passenger,它是一个Apache或Nginx模块,管理一个应用
云计算实验中要求我们在Linux系统安装Hadoop,故来做一个简单的记录。· 注:我的操作系统环境是Ubuntu-20.04.3,安装的JDK版本为jdk1.8.0_301,安装的Hadoop版本为hadoop2.7.1。(不确定其他版本是否会出现版本兼容问题)Hadoop安装步骤如下: 一、更新apt和安装vim编辑器 二、配置本机无密码登录SSH 三、安装JAVA环境 四、下载安装Hadoop 五、伪分布式搭建一、更新apt和安装vim编辑器1、更新aptsudoapt-getupdate2、安装vim
我对这个架构有点困惑。在我正在进行的一个项目中,Unicorn被选为Rails服务器。它放在Nginx网络服务器后面。据我了解,Unicorn是功能齐全的Web服务器,我们不打算在同一服务器实例上托管任何其他Rails应用程序。所以我的问题是:在链中添加附加层有什么好处:client->nginx->unicorn->unicornworker 最佳答案 Unicorn不是为处理“慢客户端”而设计的。您可以在PHILOSOPHY中阅读更多相关信息帮助文件:Mostbenchmarkswe’veseendon’ttellyouthis
我正尝试着手编写一些RubyonRails应用程序并在Mongrel上取得了成功,但是,我想将我的应用程序部署到Windows上的Apache2.2实例吗?我发现的所有教程似乎都已过时,并且适用于旧版本的Apache/Rails。有人知道为RubyonRails应用程序配置Apache2.2的最新好教程吗? 最佳答案 编辑:至少在Win出现PhusionPassenger之前,Apache+Mongrel是可行的方法。您可以在没有Mongrel的情况下使用Apache+FastCGI,但在实际负载下您会遇到(更多)僵尸进程和(更多)