文章目录
训练一个神经网络的时候,中途出现
Killed,然后程序就被终止了。
当系统资源不足时,Linux 内核也可以决定终止一个或多个进程。 一个非常常见的例子是内存不足 (OOM) killer,会在系统的物理内存耗尽时触发。
/dev/kmsg 获得。dmesg 和 journalctl。使用sudo dmesg | tail -7命令(任意目录下,不需要进入log目录,这应该是最简单的一种)
hs@hs:~$ sudo dmesg | tail -7
[4772612.871775] [1125836] 1000 1125836 2539 911 61440 0 0 bash
[4772612.871777] [1126560] 1000 1126560 1787 474 53248 0 0 tmux: client
[4772612.871779] [1138439] 1000 1138439 2029489 1412461 12845056 0 0 python3
[4772612.871781] [1141425] 1000 1141425 1809 38 49152 0 0 sleep
[4772612.871783] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/user.slice/user-1000.slice/session-1549.scope,task=python3,pid=1138439,uid=1000
[4772612.871840] Out of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
[4772612.968800] oom_reaper: reaped process 1138439 (python3), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
可以看到:
oom-kill之后,就是解释那个被killed的程序的pid和uidOut of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB,内存不够
另外,网上还有几种方式,如下:
使用下面的这几行命令
journalctl --list-boots |
awk ‘{ print $1 }’ |
xargs -I{} journalctl --utc --no-pager -b {} -kqg ‘killed process’ -o verbose --output-fields=MESSAGE
就可以直接得到,最关键的信息
hs@hs:~$ journalctl --list-boots | \
> awk '{ print $1 }' | \
> xargs -I{} journalctl --utc --no-pager -b {} -kqg 'killed process' -o verbose --output-fields=MESSAGE
Mon 2022-02-14 08:48:43.684987 UTC [s=ed0a1ecfd36e41bda458e5e111c46e95;i=d4573;b=7bc379f894944dcd81ae32ff54afa009;m=456b0ad36d2;t=5d7f67bdee47b;x=5bfe01f8e2ca9b2c]
MESSAGE=Out of memory: Killed process 1125888 (python3) total-vm:8530488kB, anon-rss:5653404kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12552kB oom_score_adj:0
Mon 2022-02-14 09:29:43.854158 UTC [s=ed0a1ecfd36e41bda458e5e111c46e95;i=d4785;b=7bc379f894944dcd81ae32ff54afa009;m=45743506aa5;t=5d7f70e82184e;x=9b55cfb2e7c081e7]
MESSAGE=Out of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
网上更常见的似乎是:
journalctl -xb | egrep -i 'killed process’
hs@hs:~$ journalctl -xb | egrep -i 'killed process'
Feb 14 08:48:43 hs kernel: Out of memory: Killed process 1125888 (python3) total-vm:8530488kB, anon-rss:5653404kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12552kB oom_score_adj:0
Feb 14 09:29:43 hs kernel: Out of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
Feb 15 03:42:08 hs sudo[1151639]: hs : TTY=pts/0 ; PWD=/home/hs ; USER=root ; COMMAND=/usr/bin/egrep -i -r killed process /var/log
以及
sudo dmesg | egrep -i -B100 'killed process'
# 但是这个会输出非常多的信息。。。
其中-B100,表示 'killed process’之前的100行内容
其中有一部分信息也许有用,如下所示,类似一个表格
oom_score_adj和name[4770152.819134] Tasks state (memory values in pages):
[4770152.819135] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name
[4770152.819138] [ 414] 0 414 70068 4518 90112 0 -1000 multipathd
[4770152.819142] [ 704] 0 704 60330 698 106496 0 0 accounts-daemon
[4770152.819144] [ 708] 0 708 2136 610 57344 0 0 cron
[4770152.819775] [ 734] 0 734 7372 3870 94208 0 0 python3
[4770152.819777] [ 735] 0 735 950 519 49152 0 0 atd
[4770152.819790] [ 1033] 0 1033 82072 5590 131072 0 0 python3
[4770152.819792] [ 1577] 0 1577 3046 915 61440 0 -1000 sshd
[4770152.819795] [ 29492] 1000 29492 4663 1187 73728 0 0 systemd
[4770152.819798] [ 29493] 1000 29493 42531 1196 102400 0 0 (sd-pam)
[4770152.819800] [ 135845] 0 135845 457433 38533 835584 0 0 nebula-metad
[4770152.819802] [ 135908] 0 135908 333667 24936 385024 0 0 nebula-graphd
[4770152.819804] [ 135927] 0 135927 592451 139719 1687552 0 0 nebula-storaged
[4770152.819818] [ 689086] 0 689086 292212 7132 286720 0 -900 snapd
[4770152.819821] [ 694790] 1000 694790 1779 641 61440 0 0 dbus-daemon
[4770152.819823] [ 699514] 1000 699514 407129 5193 1474560 0 0 node
[4770152.819825] [ 699523] 1000 699523 416398 7757 1634304 0 0 node
[4770152.819827] [ 699549] 1000 699549 489317 11361 2494464 0 0 node
[4770152.819830] [ 699555] 1000 699555 488416 10836 2531328 0 0 node
[4770152.819832] [ 699559] 1000 699559 488945 10316 2461696 0 0 node
[4770152.819835] [1102457] 0 1102457 3491 1010 65536 0 0 sshd
[4770152.819837] [1102573] 1000 1102573 3491 428 65536 0 0 sshd
[4770152.819839] [1102574] 1000 1102574 2215 574 57344 0 0 bash
[4770152.819841] [1102636] 1000 1102636 654 122 40960 0 0 sh
[4770152.819843] [1102643] 1000 1102643 403507 180866 3731456 0 0 node
[4770152.819845] [1102681] 1000 1102681 233944 6666 1265664 0 0 node
[4770152.819847] [1102707] 1000 1102707 221411 13611 2768896 0 0 node
[4770152.819849] [1102777] 1000 1102777 2535 952 49152 0 0 bash
[4770152.819851] [1103566] 1000 1103566 207746 13759 720896 0 0 node
[4770152.819853] [1110927] 113 1110927 2395391 627318 8884224 0 0 java
[4770152.819856] [1121028] 1000 1121028 1488563 907652 8630272 0 0 python3
[4770152.819858] [1125835] 1000 1125835 1983 659 49152 0 0 tmux: server
[4770152.819860] [1125836] 1000 1125836 2539 944 61440 0 0 bash
[4770152.819862] [1125888] 1000 1125888 2132622 1413351 12853248 0 0 python3
[4770152.819864] [1126560] 1000 1126560 1787 569 53248 0 0 tmux: client
[4770152.819867] [1137700] 1000 1137700 1809 38 49152 0 0 sleep
另外,还有
egrep -i ‘killed process’ /var/log/messages 或
egrep -i -r ‘killed process’ /var/log
hs@hs:~$ sudo egrep -i -r 'killed process' /var/log
Binary file /var/log/journal/482df032dea642279e0da48fa9dd4a1a/system.journal matches
/var/log/auth.log:Feb 15 03:42:08 hs sudo: hs : TTY=pts/0 ; PWD=/home/hs ; USER=root ; COMMAND=/usr/bin/egrep -i -r killed process /var/log
/var/log/syslog.1:Feb 14 08:48:43 hs kernel: [4770152.820348] Out of memory: Killed process 1125888 (python3) total-vm:8530488kB, anon-rss:5653404kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12552kB oom_score_adj:0
/var/log/syslog.1:Feb 14 09:29:43 hs kernel: [4772612.871840] Out of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
/var/log/kern.log.1:Feb 14 08:48:43 hs kernel: [4770152.820348] Out of memory: Killed process 1125888 (python3) total-vm:8530488kB, anon-rss:5653404kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12552kB oom_score_adj:0
/var/log/kern.log.1:Feb 14 09:29:43 hs kernel: [4772612.871840] Out of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:12544kB oom_score_adj:0
参考:Out of Memory events and decoding their logging
| 参数 | 解释 |
|---|---|
| pid | 进程ID |
| uid | 用户ID |
| tgid | 线程组ID |
| total_vm | 总共使用的虚拟内存 Virtual memory use (in 4 kB pages) |
| rss | 常驻内存使用Resident memory use (in 4 kB pages) |
| nr_ptes | 页表实体Page table entries |
| swapents | 页表实体Page table entries |
| oom_score_adj | 通常为 0。较小的数字表示在调用 OOM 杀手时进程不太可能死亡。(oom会优先kill分数高的进程,分数高表示占用内存资源多) |
参考:
查看系统内存情况:cat /proc/meminfo
hs@hs:~$ cat /proc/meminfo
MemTotal: 14331380 kB
MemFree: 9515720 kB
MemAvailable: 9947704 kB
Buffers: 141952 kB
查看当前空闲内存:free -m(以MB显示内存情况),free -g(以GB显示内存情况)
hs@hs:~$ free -m
total used free shared buff/cache available
Mem: 13995 4000 8308 1 1686 9656
Swap: 0 0 0
hs@hs:~$ free -g
total used free shared buff/cache available
Mem: 13 3 8 0 1 9
Swap: 0 0 0
参考:Linux OOM-killer(内存不足时kill高内存进程的策略)
OOM_killer是Linux自我保护的方式,当内存不足时不至于出现太严重问题,有点壮士断腕的意味
在kernel 2.6,内存不足将唤醒oom_killer,挑出/proc/<pid>/oom_score最大者并将之kill掉
为了保护重要进程不被oom-killer掉,可以:
也可以对把整个系统的OOM给禁用掉:
sysctl -w vm.panic_on_oom=1 (默认为0,表示开启)sysctl -p值得注意的是,有些时候 free -m 时还有剩余内存,但还是会触发OOM-killer,可能是因为进程占用了特殊内存地址
top M 查看最消耗内存的进程,但也不是进程一超过就会触发oom_killer参数/proc/sys/vm/overcommit_memory可以控制进程对内存过量使用的应对策略
overcommit_memory=0 ,允许进程轻微过量使用内存,但对大量过载请求则不允许(默认)overcommit_memory=1 ,永远允许进程overcommitovercommit_memory=2,永远禁止overcommit查看某个用户的内存使用情况
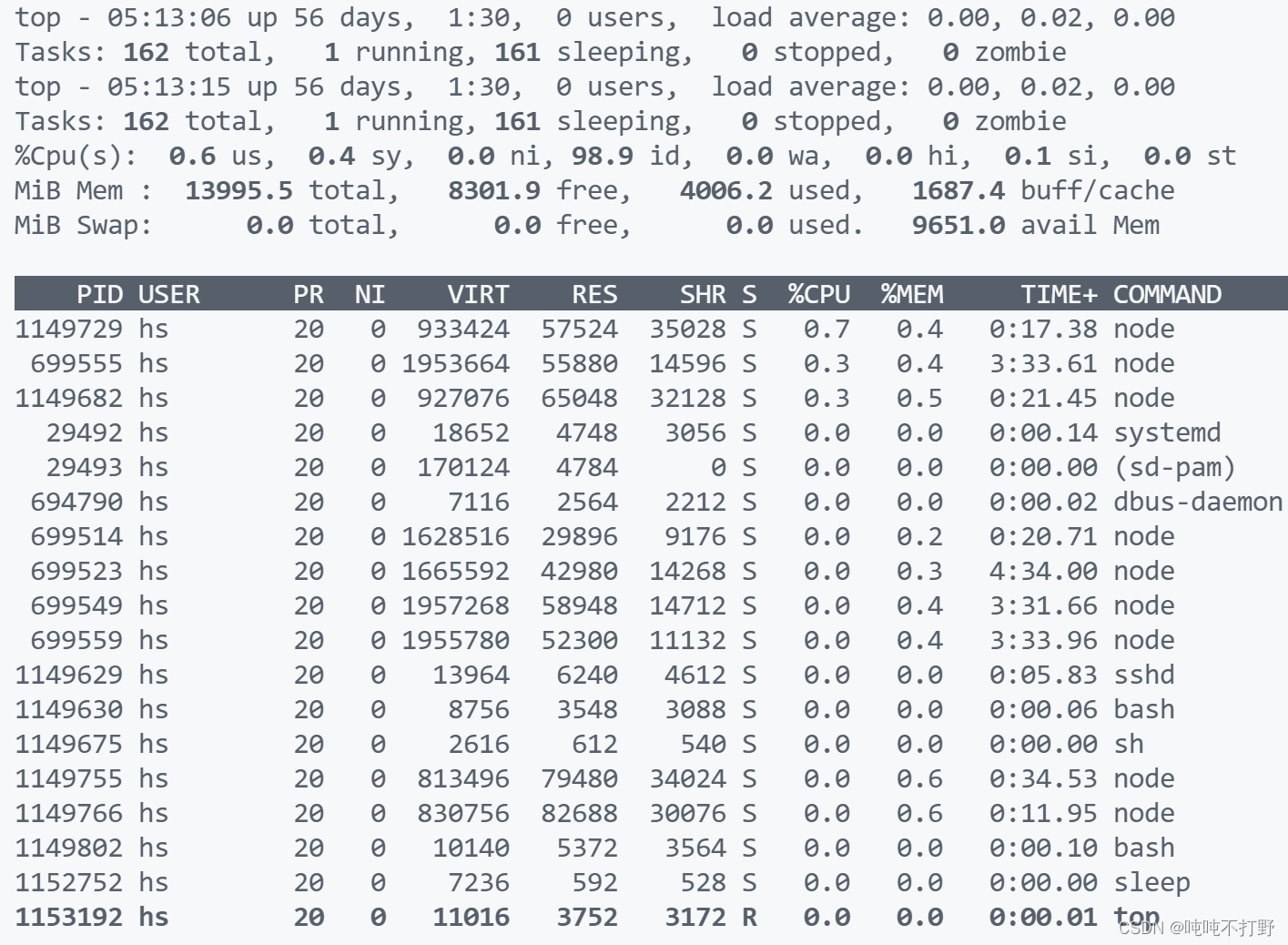
查看当前内存使用情况,使用top命令,如果要查看某个用户的内存使用情况,可以top -u username,例如:
top -u hs # 查看某个用户的内存使用情况
可以使用q退出top界面
查看详细的command内容
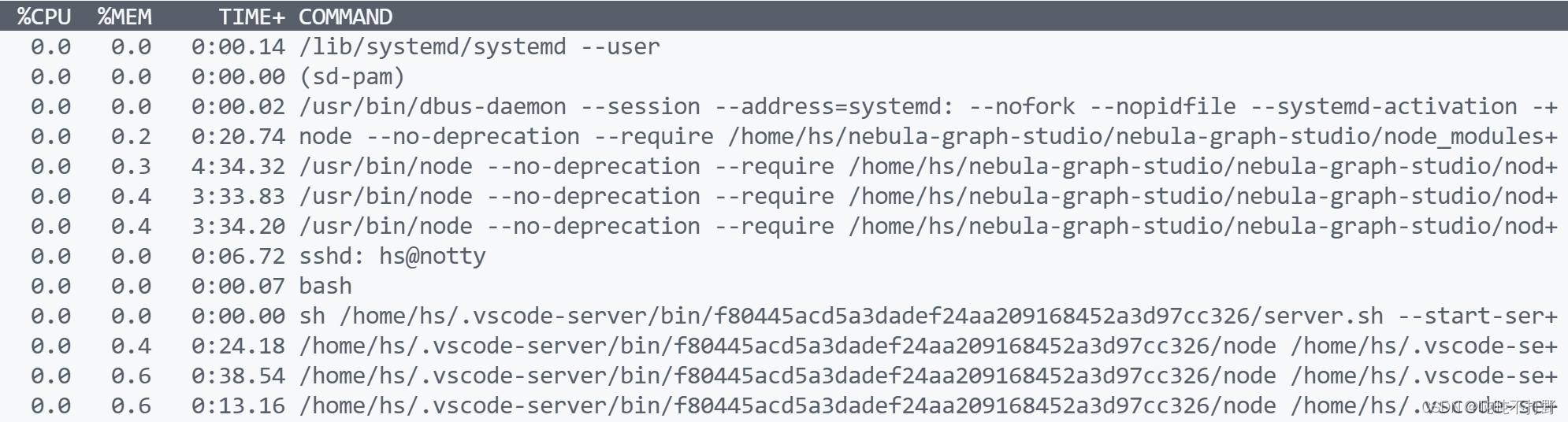
如果想查看详细的command,可以使用-c参数
top -u hs -c
然后就会显示每个command的详细内容,例如:
查看特定PID或进程的资源消耗情况
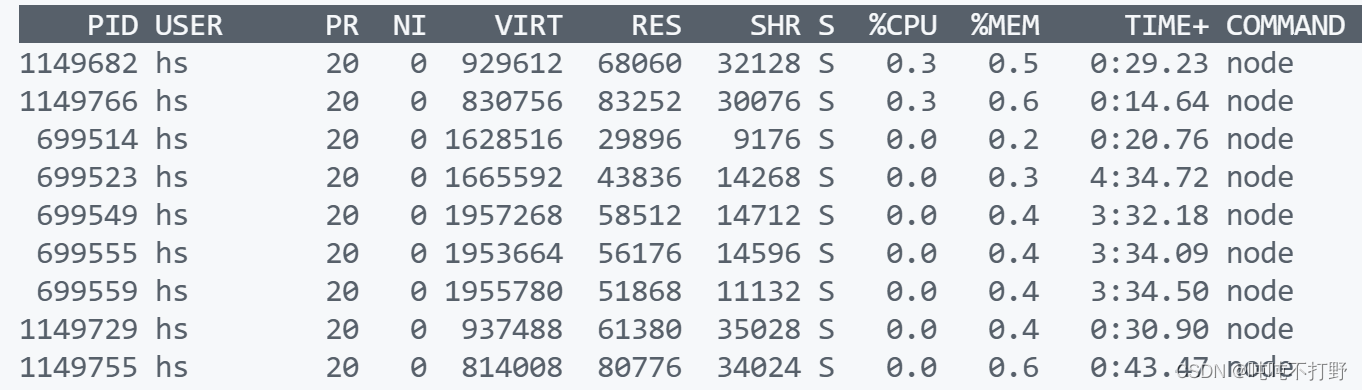
进一步,如果希望查看这个用户下某个特定 command的占用情况,可以使用grep命令来进一步处理top命令的输出,参考:How to view a specific process in top
top -p `pgrep -d "," node` # 正解
top -p pid1,pid2: 展示多个进程信息,PID之间用逗号隔开pgrep -d "," java: 打印出所有含有java词的PID的信息top: -p argument missing这样的提示,说明当前没有在运行的java程序,所以pgrep没有输出输出以下内容:
为什么%MEM大于100%
参考:Sum of memory of few processes in top is greater than 100%
top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下表:
| 参数 | 解释 |
|---|---|
| s | 改变画面更新频率 |
| l | 关闭或开启第一部分第一行 top 信息的表示 |
| t | 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示 |
| m | 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示 |
| N | 以 PID 的大小的顺序排列表示进程列表(第三部分后述) |
| P | 以 CPU 占用率大小的顺序排列进程列表 (第三部分后述) |
| M | 以内存占用率大小的顺序排列进程列表 (第三部分后述) |
| h | 显示帮助 |
| n | 设置在进程列表所显示进程的数量 |
| q | 退出 top |
| s | 改变画面更新周期 |
TBD
参考:
经过上面top命令的查看,其实发现,我系统很干净,只有nebula-graph-studio的4个进程以及使用vscode访问占用了一些资源。
因此,首先不再使用vscode访问服务器,改成xshell。
参考:too much memory for remote-ssh vscode
然后关闭nebula-graph-studio服务。
关闭掉无关进程之后,可以看到,top命令中基本没东西了
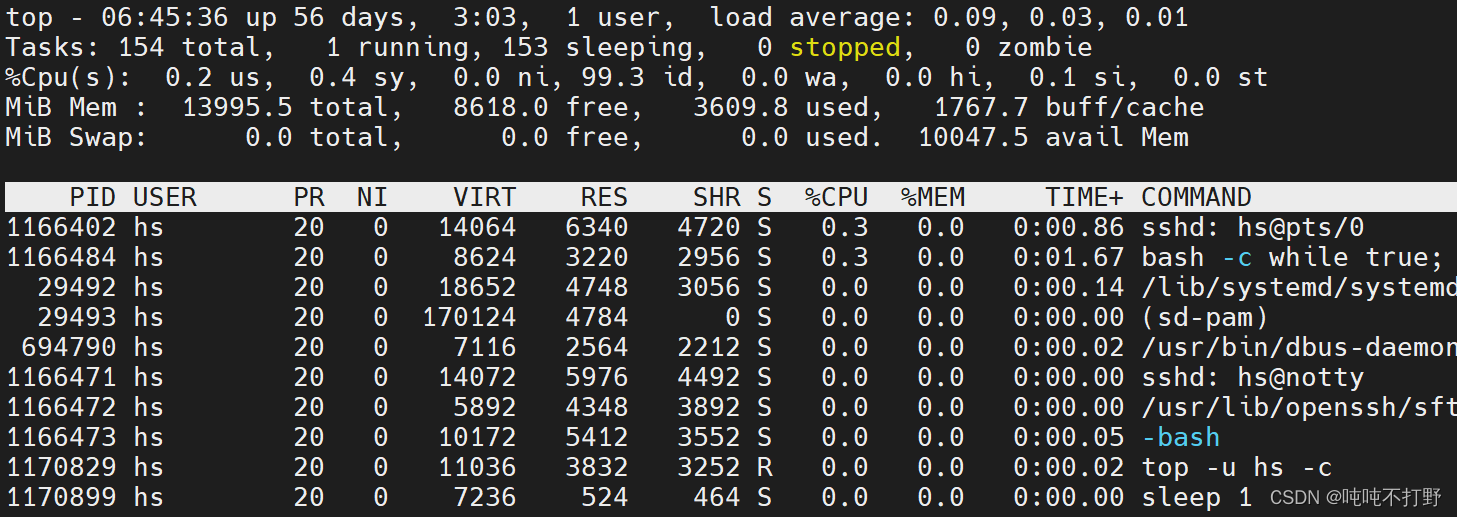
再去查看free -g

似乎没什么用,哎。算了,那只能修改模型的batch_size了,或者把模型参数降低。
这里只记录一些我观察到的情况。
mobaxtem查看系统内存使用情况,为3.83GB。(此时,vscode的连接进程还没有消失)3.94GBexit并关闭vscode,内存使用量变为3.84GB3.77GB
mobaxterm中的openssh等进程,vscode的内存占用确实大很多,但是如果机器比较跟的上时代的话,其实不是很大的问题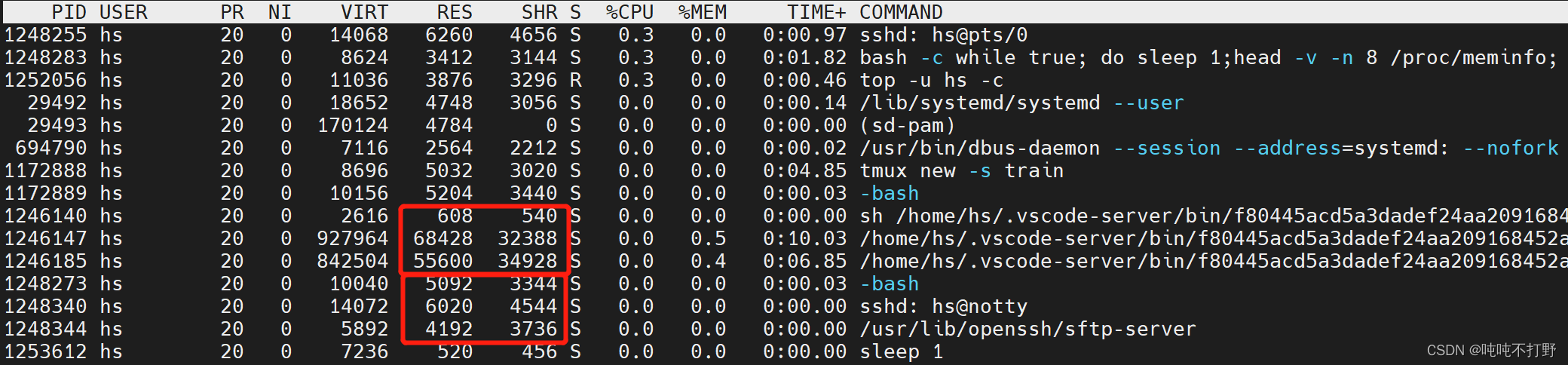
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源