LVI-SAM是一种基于平滑化和映射实现的激光雷达-视觉-IMU紧耦合SLAM方法,能够实现高精度、高鲁棒性地实时状态估计和地图构建。
LVI-SAM建立于包含两个子系统的因子图上:视觉-IMU子系统(VIS)和激光-IMU子系统(LIS),两个子系统采用紧耦合设计方式。其中VIS利用LIS进行初始化,利用LiDAR测量的深度信息提高精度,LIS利用VIS的估计结果作为扫描匹配初始值。回环检测首先由VIS识别,再由LIS进一步确认。
两个子系统中任意一个失效了,LVI-SAM仍可以正常工作,这说明它在无纹理和无特征环境下仍然具有高鲁棒性。
https://github.com/TixiaoShan/LVI-SAM
主要贡献:
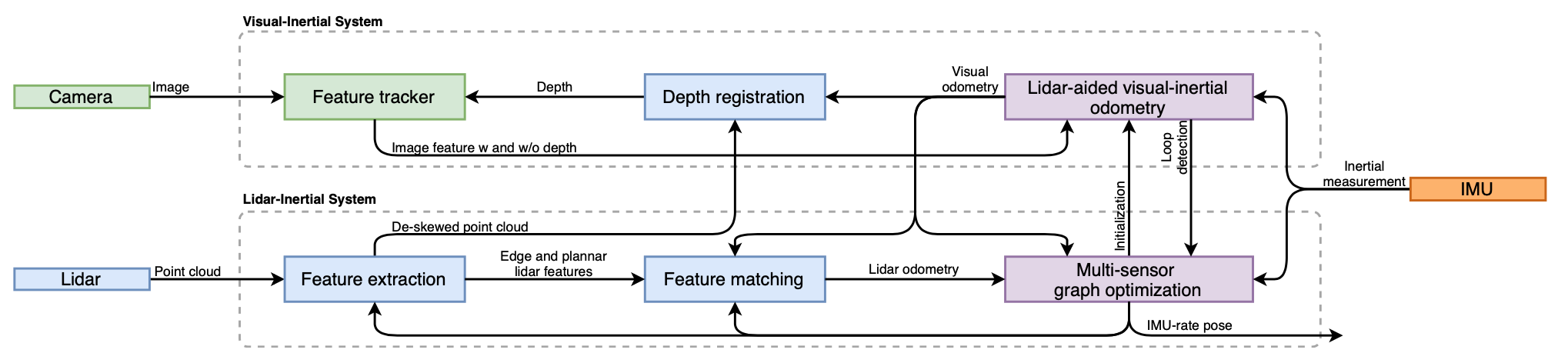
VIS处理图像、IMU的测量结果和激光雷达测量结果(可选),最小化视觉和IMU测量结果的联合残差实现视觉里程计。LIS通过特征与特征地图的匹配来提取特征并执行激光雷达里程计,特征地图以滑动窗口的方式进行维护,从而提高实时性。最后利用ISAM2,联合优化因子图中的IMU预积分约束、视觉里程计约束、激光雷达里程计约束、和回环约束,解决状态估计问题(上述过程也可以表示为最大后验概率问题)。LIS中的多传感器图优化的目的是减少数据交换并提高系统效率。
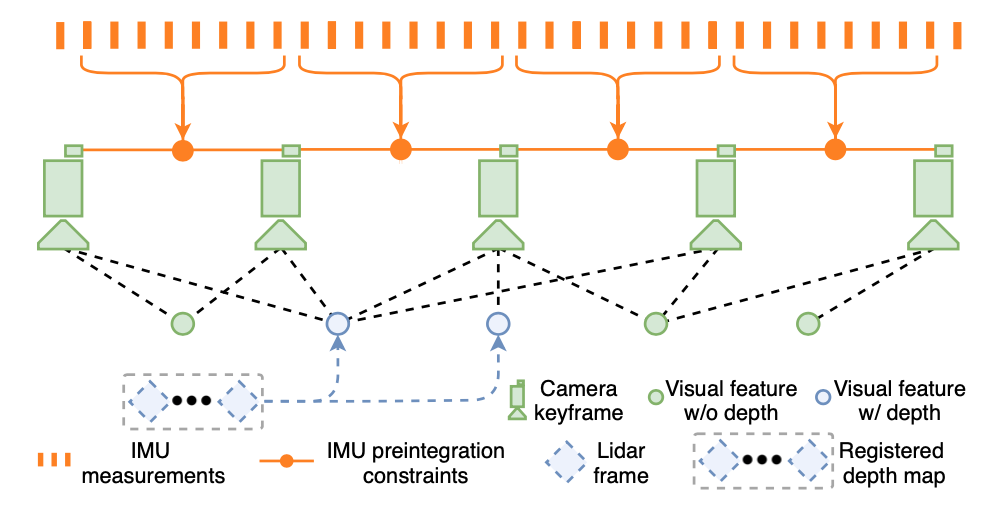
VIS模块基于VINS-MONO,视觉特征点采用角点检测器提取,并采用KLT光流法追踪。VIS初始化以后,我们利用视觉里程计对激光雷达帧进行配准,并且获取稀疏的深度图用于特征点深度估计。系统在滑动窗口中执行光束法平差,系统状态x可以表示为:
其中R是旋转矩阵,p为平移向量,v为速度,b是包含加速度计零偏和陀螺仪零偏的IMU的零偏向量。从传感器到世界坐标系的位姿转换用表示。
基于优化的VIO初始化阶段总是会发散,其原因是初始化是一个高度非线性的总是。初始化的质量主要依赖于两个因素:初始化化时传感器的运行和IMU的参数精度。在实际测试中,当传感器运动很小或者常速运动时就会初始化失败。这是因为加速度激励较小的时候尺度是不可观的。IMU含有缓慢变化的偏置和白噪声,这同时影响加速度和角速度的测量。在初始化时,更好的参数有益于更快收敛。
为了提高VIS初始化的鲁棒性,首先初始化LIS获得系统状态x和IMU的零偏,然后基于图像帧的时间戳将它们插值并关联到图像帧(注意到此处假定两个相邻的图像关键帧之间的零偏值是不变的),最后用关联值初始化VIS,从而提高VIS初始化的速度和鲁棒性。
在初始化的基础上,利用已经估计好的视觉里程计把激光雷达帧配准到视觉帧。一般激光雷达单帧是比较稀疏的,所以叠加多帧以获得稠密的深度图。
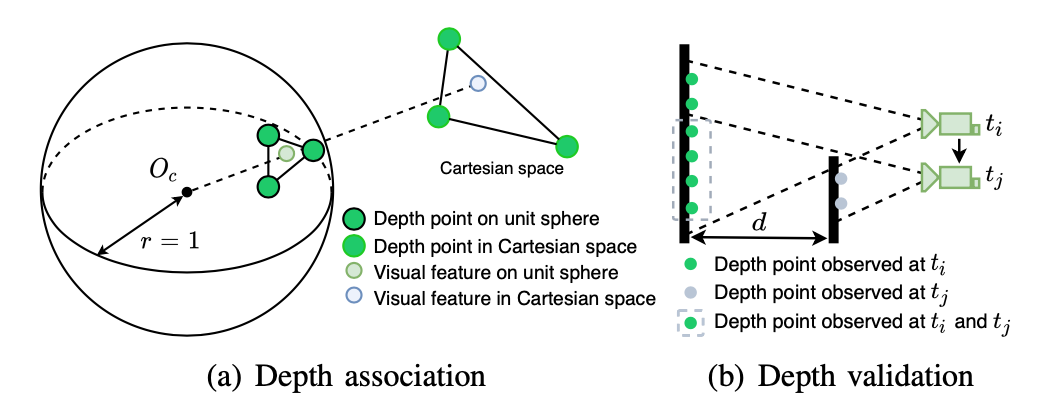
为了把视觉特征和深度值关联起来,首先将视觉特征点和点云点投影到以相机为球心的单位球上,用极坐标形式表示点的位置,进行下采样。在极坐标空间用二维kd-tree搜索每个视觉特征点附近的三个临近点云点,认为从相机光心到特征点(归一化平面上)的直线在笛卡尔空间与三个激光点确定的平面之间的交点的深度值就是特征点的深度值。
检查三个最近邻激光点之间的距离以进一步验证关联信息的有效性。这是因为使用不同时刻的激光帧叠加到一起会导致源自不同物体的深度模糊。如下图所示,时刻观测到的点用绿色表示,
时刻相机移动到了新的位置,观测到的新的点用灰色表示,但是图中用灰色虚线框框起来的点,因为激光点云叠加的原因,却会被误认为是
时刻也能观测到的点。所以需要使用距离阈值来剔除掉这种情况。
 视觉特征和深度图关联的一个证明如下图所示。图中a和c是利用视觉里程计把激光点云投影到图像中,在b和d中成功关联的结果用绿色表示。
视觉特征和深度图关联的一个证明如下图所示。图中a和c是利用视觉里程计把激光点云投影到图像中,在b和d中成功关联的结果用绿色表示。 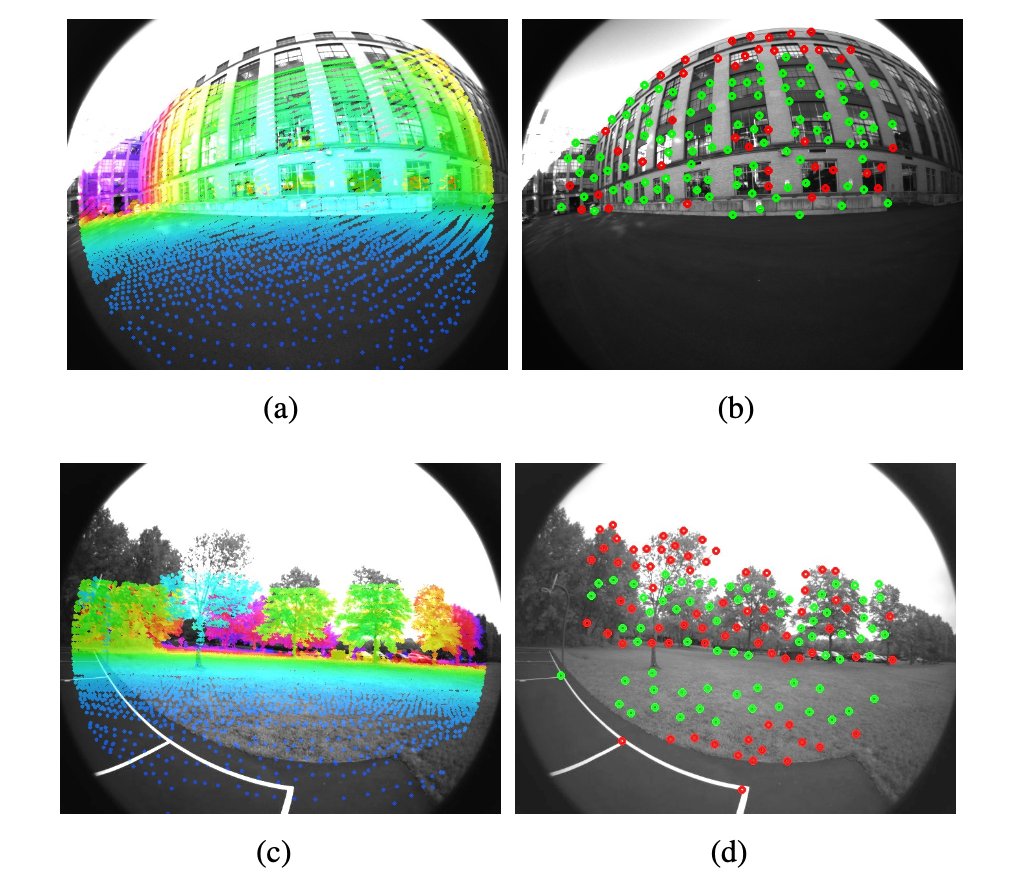
遇到剧烈运动、光照变化和无纹理环境时,VIS跟踪的特征点急剧减少,进而导致优化发散,VIS系统失效。VIS失效时,估计的IMU零偏会变大。因此在特征点数量小于一定的阈值时,或估计的IMU零偏超过一定阈值时,则报告VIS子系统失效。
失效检测是必要的,这样可以保证VIS失效不会影响LIS的功能,一旦检测到VIS失效,VIS将重新初始化并通知LIS。
采用词袋模型DBoW2进行回环检测,对于每个新图像关键帧,提取BRIEF描述子,与之前的描述子进行词袋匹配。把DBoW2返回的回环帧时间戳发送给LIS,由LIS进行进一步的回环验证。
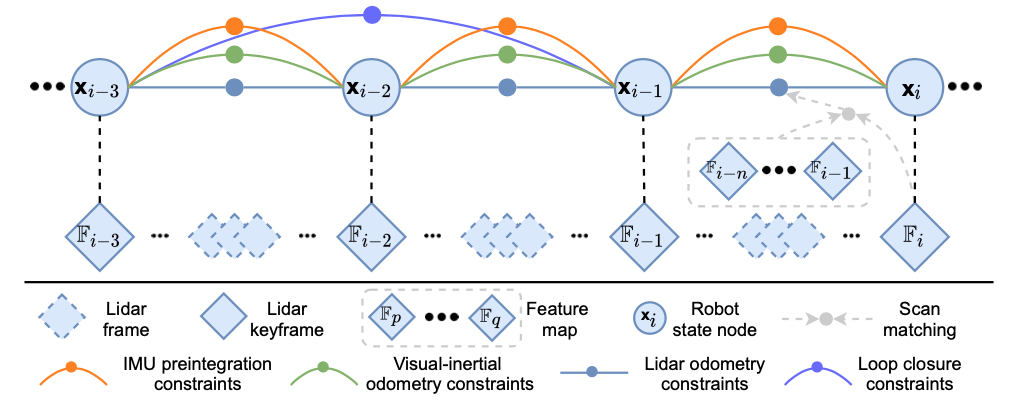
LIS部分是由LIO-SAM改造而来,维护一个全局位姿优化的因子图。因子图中包含四种约束:IMU预积分约束,视觉里程计约束,激光里程计约束,回环约束,因子图会对这几种约束进行联合优化。
激光里程计约束源于激光扫描匹配,该匹配是把当前帧和全局特征地图匹配起来。候选的回环约束首先由VIS检测到,然后再进行激光扫描匹配优化。系统维护一个激光雷达关键帧的滑窗用以限制计算复杂度。当位姿变化超过一定阈值时才会产生新的关键帧。夹杂在关键帧之间的帧会变抛弃。一个新关键帧的产生时,相应的一个新的状态变量也会被添加到因子图中。以此种方式添加关键帧不仅实现了地图密度和内存占用的平衡,也有助于维护一个相对稀疏的因子图以便于实时优化。
剧烈运动时,激光雷达帧匹配选取的初值(预测值)十分重要。LIS初始化之前与之后预测来源是不同对的。
LIS初始化之前,假设机器人从某位置启动,初速度为0。假设零偏和噪声均为0,对IMU测量值积分,计算两个激光雷达关键帧之间的平移和旋转以作为预测。在速度小于10m/s且角速度小于180°/s时,此方法可以成功初始化LIS。LIS初始化以后,在因子图优化IMU零偏、位姿、速度,并发送给VIS帮助VIS初始化。
LIS初始化以后,预测的来源有两个:校正后的IMU预积分值和VIS的估计结果。VIS结果可用时,优先采用VIS的估计结果。如果VIS失效,则利用IMU获取预测。这种双来源的预测方法提高了多纹理环境和无纹理环境的预测准确性和鲁棒性。

激光雷达遇到像上面一样的几何特征丢失的场景下会产生退化。
在扫描匹配过程中非线性优化问题可以表达为迭代地求解线性问题。当
的最小特征值小于第一次优化迭代是的阈值时,认为LIS失效。(可以这样想,A的奇异值特别小的时候,
接近于病态矩阵或奇异矩阵,导致得到的解不可信)LIS失效后,就不在因子图中添加激光里程计约束了。

由粗到精学习LVI-SAM:论文原文解析_3D视觉工坊-商业新知
【SLAM】LVI-SAM解析——综述_iwander。的博客-CSDN博客_lvi-sam
LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我有这样的HTML代码:Label1Value1Label2Value2...我的代码不起作用。doc.css("first").eachdo|item|label=item.css("dt")value=item.css("dd")end显示所有首先标记,然后标记标签,我需要“标签:值” 最佳答案 首先,您的HTML应该有和中的元素:Label1Value1Label2Value2...但这不会改变您解析它的方式。你想找到s并遍历它们,然后在每个你可以使用next_element得到;像这样:doc=Nokogiri::HTML(