kafka官网:http://kafka.apache.org/
中文文档:https://www.orchome.com/511
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue)
高吞吐量、低延迟
kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
可扩展性
kafka集群支持热扩展
持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。默认最多保存时长 为7天
容错性
允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发
支持数千个客户端同时读写
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题实现高性能,高可用,可伸缩和最终一致性 .
常见的消息队列产品有ActiveMQ,RabbitMQ, RocketMQ ,Kafka,ZeroMQ,MetaMQ
ActiveMQ: 很老了,已被市场淘汰了。
RabbitMQ:用于传统企业项目(erp,oa,crm…)。erlang, 速度快,消息存放在内存中
RocketMQ: 用于电商、金融。速度快,支持亿级别消息堆积,模拟了kafka。
Kafka: 主要用海量数据,高吞吐量。用于日志收到与传输上。
选择MQ优点适合自己项目的才是真的
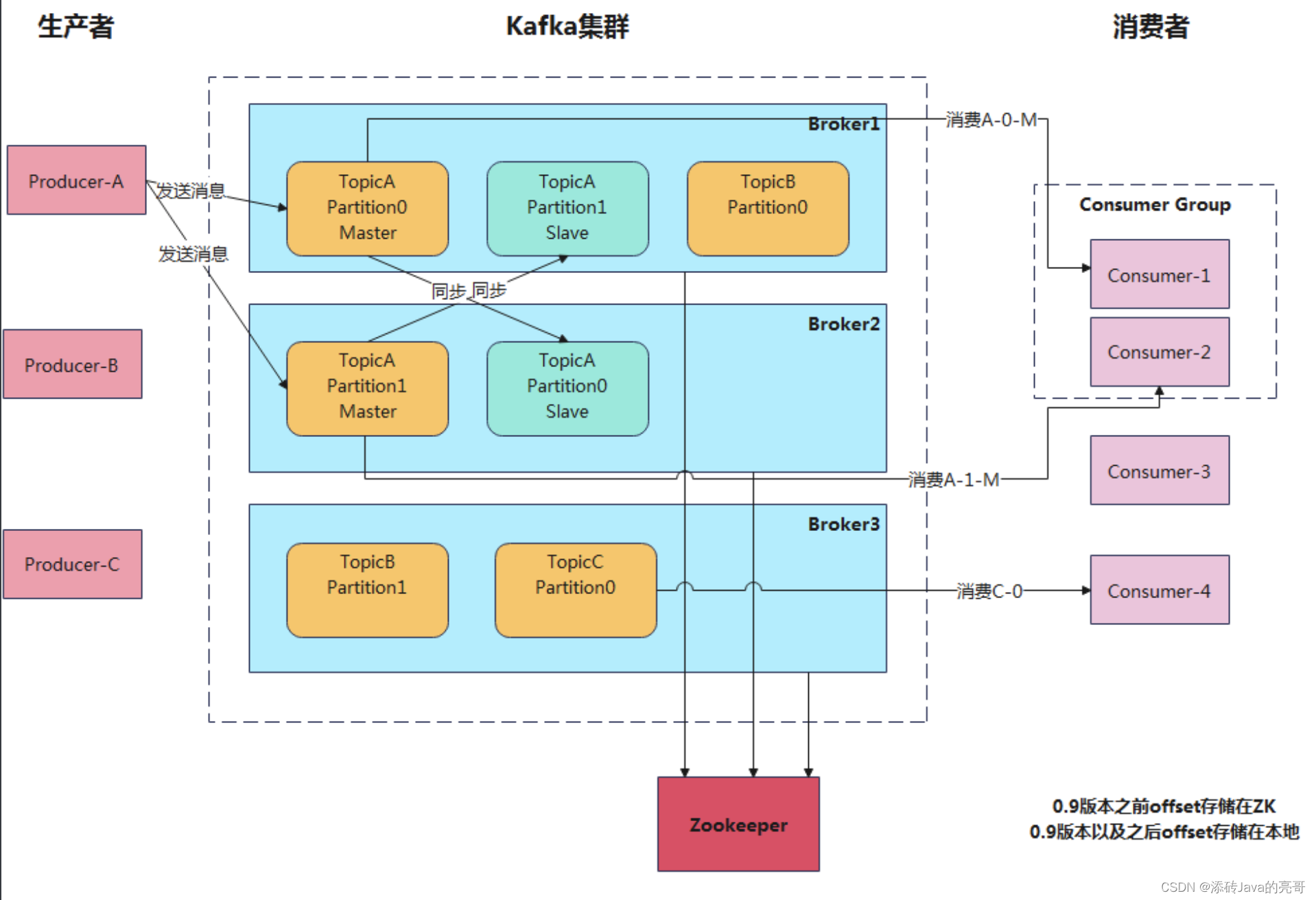
1)Producer :消息生产者,就是向 kafka broker 发消息的客户端;
2)Consumer :消息消费者,向 kafka broker 取消息的客户端;
3)Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消者组是逻辑上的一个订阅者。可以提高消费者的能力(并发最好的时候: 消费者组里面消费者的个数=Topic里面的分区数)。
4)Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker可以容纳多topic。
5)Topic :可以理解为消息的分类,生产者和消费者面向的都是同一个 topic;
6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;(往同一个主题发送的消息不会同时发给多个分区),存放消息的地方
7)Replica(slave):副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 Master和若干个 Slave(Replica)。
8)leader[master]:每个分区(针对Patition)多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
9)follower[slave]:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 leader。
生产者 -> kafka broker(1个topic有多个partition(消息存储))
消费者->kafka broker上的topic下的分区,一个分区只能被同一消费者组中的1个消费者消费
注册中心:zookeeper 注册 集群维护
(1) 容器下载,看博客资料
docker pull wurstmeister/zookeeper
docker pull wurstmeister/kafka
docker pull obsidiandynamics/kafdrop:3.30.0
docker run -d --name zookeeper --restart=always -p 2181:2181 wurstmeister/zookeeper
docker volume create kafka-log
docker run -d --name kafka -p 9092:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=172.16.147.129:2181/kafka \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.16.147.129:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-e KAFKA_HEAP_OPTS="-Xmx512M -Xms256M" \
-v kafka-log:/kafka \
wurstmeister/kafka
docker run -d -p 9100:9000 --name=kafdrop \
-e KAFKA_BROKERCONNECT=172.16.147.129:9092 \
-e JVM_OPTS="-Xms32M -Xmx64M" \
-e SERVER_SERVLET_CONTEXTPATH="/" \
obsidiandynamics/kafdrop:3.30.0
# 启动成功后访问
http://172.16.147.129:9100
————————————————
版权声明:本文为CSDN博主「添砖Java的亮哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_51262858/article/details/127596051
# 参数说明
KAFKA_BROKER_ID: 分区id, 如果不指定,默认也是从0开始
KAFKA_ZOOKEEPER_CONNECT: zookeeper所在
KAFKA_ADVERTISED_LISTENERS: 客户端连接地址与端口 可对外公网
KAFKA_LISTENERS:内网使用 客户端连接地址与端口
KAFKA_HEAP_OPTS:使用堆大小配置
访问页面如下:

(2)官网下载
下载地址:http://kafka.apache.org/downloads
下载的安装包上传到公司服务器,解压
(3)修改参数
修改config目录下的server.properties文件,效果如下
注意:
安装Kafka之前先需要安装JDK
启动kafka之前,必须先启动zookeeper
创建kafka-demo工程,引入依赖信息
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.8.RELEASE</version>
</parent>
<dependencies>
<!-- kafka依赖 begin -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.3</version>
</dependency>
</dependencies>
做一个java普通的生产者和消费者只需要依赖kafka-clients即可
创建类:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.junit.jupiter.api.Test;
import java.util.Properties;
/**
* @version 1.0
* @description 说明
* @package
*/
public class ProducerTest {
@Test
public void testSend(){
//1. 创建配置信息
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.211.128:9092");
// key的序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
// 内容的序列化器
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
// 重试次数
properties.put(ProducerConfig.RETRIES_CONFIG,10);
//2. 创建生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
//3. 创建消息对象
// 构建参数1:主题, 2:消息内容
ProducerRecord<String,String> msg = new ProducerRecord<String,String>("myTopic", "Hello kafka...");
//4. 发送消息
producer.send(msg);
producer.close();
}
}
创建消费者类:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* @version 1.0
* @description 说明
* @package
*/
public class ConsumerDemo {
private static final String TOPIC = "myTopic";
public static void main(String[] args) {
//1.创建配置对象
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.211.128:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group1");//设置分组
//2.创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
//3.订阅主题
consumer.subscribe(Collections.singletonList(TOPIC));
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
System.out.println(record.key());
}
}
}
}
使用步骤:
创建配置信息Properties:
创建生产者对象|或消费者对象
生产者,创建消息(指定主题,[指定key], 消息内容),发送
消费者订阅主主题(是一个集合,可以多个主题),拉取消息,消费
相关参数:
到目前为止,我们只介绍了生产者的几个必要参数(bootstrap.servers、序列化器等)
生产者还有很多可配置的参数,在kafka官方文档中都有说明,大部分都有合理的默认值,所以没有必要去修改它们,不过有几个参数在内存使用,性能和可靠性方法对生产者有影响
http://kafka.apache.org/23/documentation.html#producerconfigs
https://www.orchome.com/511
幂等:不管执行多少次,结果都一样
Get, Put, Delete, 幂等
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.8.RELEASE</version>
</parent>
<dependencies>
<!-- kafka依赖 begin -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
spring:
kafka:
# 配置连接到服务端集群的配置项 ip:port,ip:port
bootstrapServers: 172.16.147.129:9092
producer:
# 当多个消息要发送到相同分区的时,生产者尝试将消息批量打包在一起,以减少请求交互。这样有助于客户端和服务端的性能提升。该配置的默认批次大小(以字节为单位)
batchSize: 16384
# 生产者用来缓存等待发送到服务器的消息的内存总字节数。如果消息发送比可传递到服务器的快,生产者将阻塞max.block.ms之后,抛出异常
bufferMemory: 33554432
# 发送失败则会重新发送,间隔100ms
retries: 0
keySerializer: org.apache.kafka.common.serialization.StringSerializer
valueSerializer: org.apache.kafka.common.serialization.StringSerializer
测试发送消息
/**
* @author zengfl
* @Date 上午12:05
* @User 添砖Java的亮哥
*/
@SpringBootTest
public class SendMsgTest {
@Autowired
private KafkaTemplate kafkaTemplate;
@Test
public void testSendMsg(){
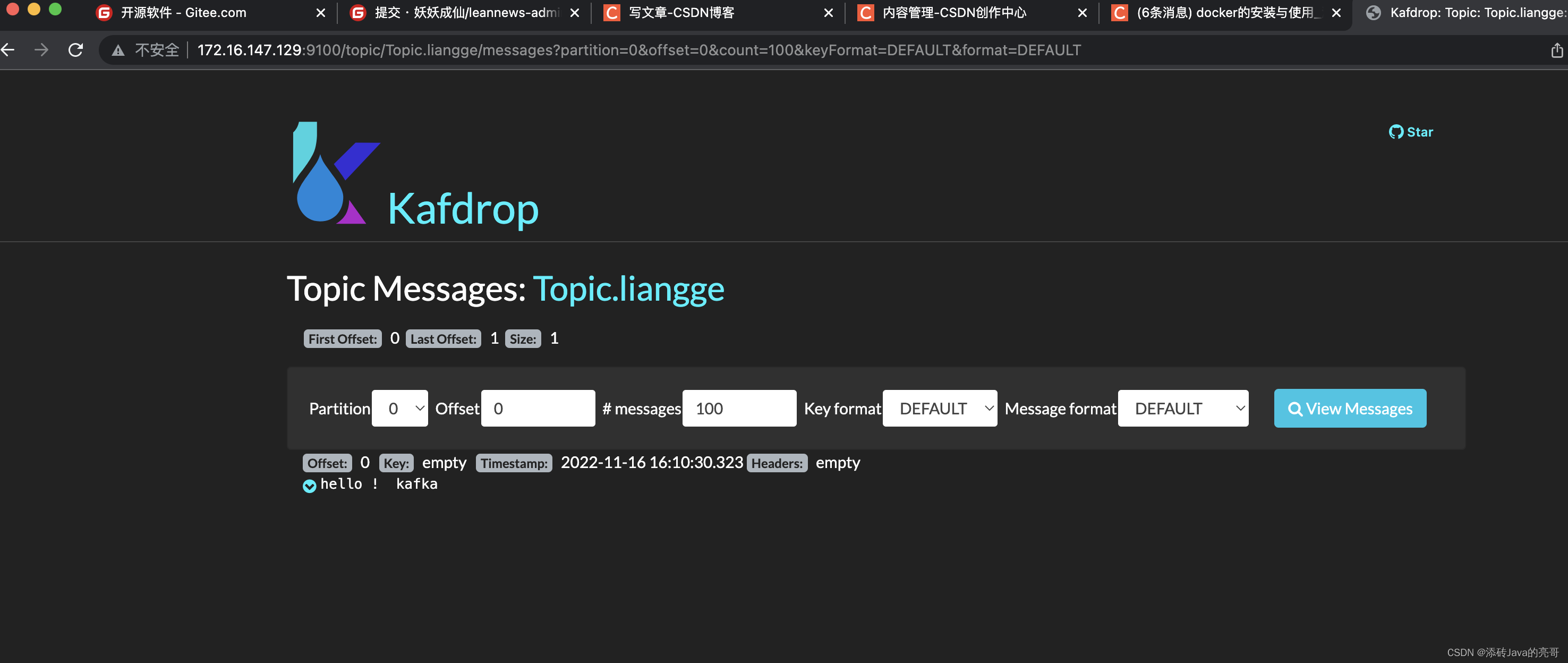
kafkaTemplate.send("Topic.liangge","hello ! kafka");
}
}
配置消费者的yml
spring:
kafka:
consumer:
# autoCommitInterval: 100
autoOffsetReset: earliest
# 是否自动提交偏移量,默认为true自动提交,false为手工提交
# enable-auto-commit: false
groupId: test-consumer-group
# 默认值即为字符串
keyDeserializer: org.apache.kafka.common.serialization.StringDeserializer
# 默认值即为字符串
valueDeserializer: org.apache.kafka.common.serialization.StringDeserializer
# 配置连接到服务端集群的配置项 ip:port,ip:port
bootstrap-servers: 172.16.147.129:9092
创建消费者的监听类,消费消息
/**
* @author zengfl
* @Date 上午12:24
* @User 添砖Java的亮哥
*/
@Component
public class TestListener {
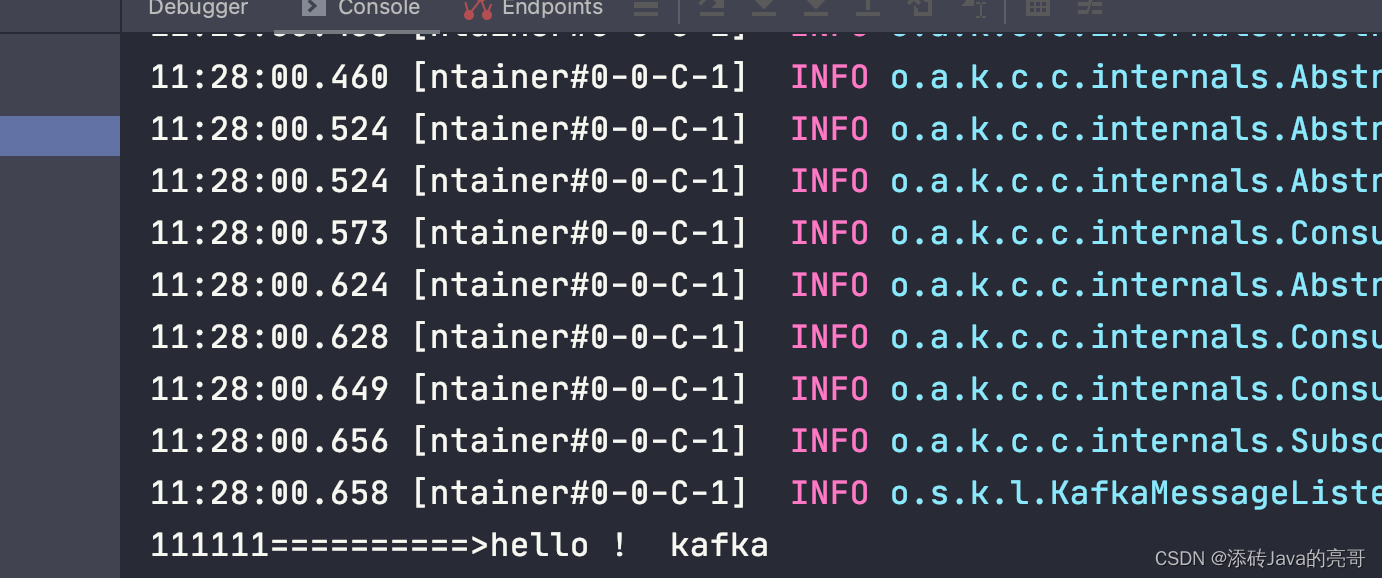
@KafkaListener(topics = "Topic.liangge",groupId = "group_01")
public void consumeMsg(String msg){
System.out.println("111111==========>" + msg);
}
@KafkaListener(topics = "Topic.liangge",groupId = "group_02")
public void consumeMsg2(ConsumerRecord<String, String> record){
System.out.println("=================2222222==================");
System.out.println(String.format("==> key=%sd value=%s offset=%d",record.key(),record.value(),record.offset()));
System.out.println("==========================================");
}
}
消费者可以看到监听到Kafka的消息
在试试
@SpringBootTest
public class SendMsgTest {
@Autowired
private KafkaTemplate kafkaTemplate;
@Test
public void testSendMsg(){
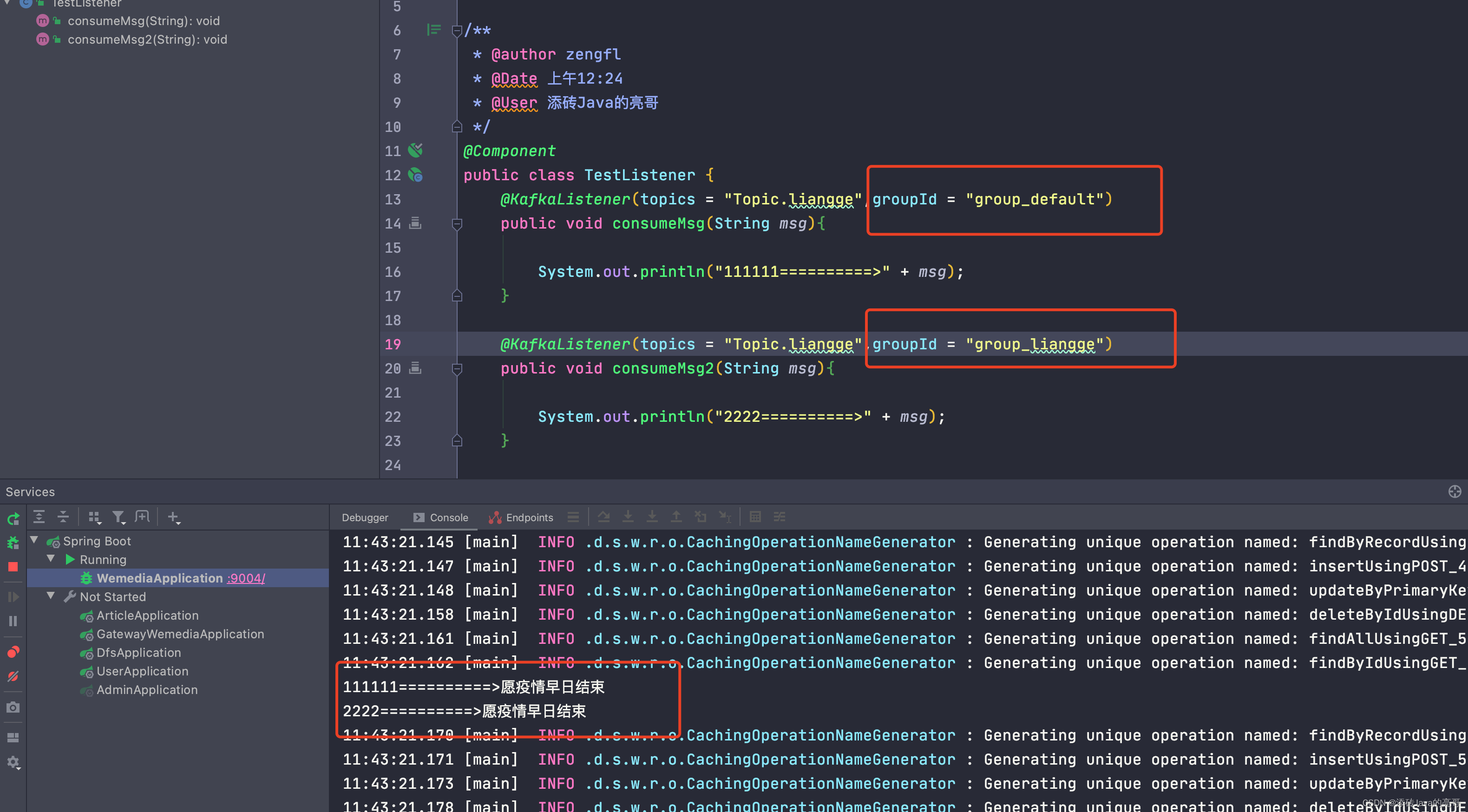
kafkaTemplate.send("Topic.liangge","愿疫情早日结束");
}
}
我是rails的新手,想在form字段上应用验证。myviewsnew.html.erb.....模拟.rbclassSimulation{:in=>1..25,:message=>'Therowmustbebetween1and25'}end模拟Controller.rbclassSimulationsController我想检查模型类中row字段的整数范围,如果不在范围内则返回错误信息。我可以检查上面代码的范围,但无法返回错误消息提前致谢 最佳答案 关键是您使用的是模型表单,一种显示ActiveRecord模型实例属性的表单。c
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
我正在使用Ruby,我正在与一个网络端点通信,该端点在发送消息本身之前需要格式化“header”。header中的第一个字段必须是消息长度,它被定义为网络字节顺序中的2二进制字节消息长度。比如我的消息长度是1024。如何将1024表示为二进制双字节? 最佳答案 Ruby(以及Perl和Python等)中字节整理的标准工具是pack和unpack。ruby的packisinArray.您的长度应该是两个字节长,并且按网络字节顺序排列,这听起来像是n格式说明符的工作:n|Integer|16-bitunsigned,network(bi
如果我在模型中设置验证消息validates:name,:presence=>{:message=>'Thenamecantbeblank.'}我如何让该消息显示在闪光警报中,这是我迄今为止尝试过的方法defcreate@message=Message.new(params[:message])if@message.valid?ContactMailer.send_mail(@message).deliverredirect_to(root_path,:notice=>"Thanksforyourmessage,Iwillbeintouchsoon")elseflash[:error]
RSpec似乎按顺序匹配方法接收的消息。我不确定如何使以下代码工作:allow(a).toreceive(:f)expect(a).toreceive(:f).with(2)a.f(1)a.f(2)a.f(3)我问的原因是a.f的一些调用是由我的代码的上层控制的,所以我不能对这些方法调用添加期望。 最佳答案 RSpecspy是测试这种情况的一种方式。要监视一个方法,用allowstub,除了方法名称之外没有任何约束,调用该方法,然后expect确切的方法调用。例如:allow(a).toreceive(:f)a.f(2)a.f(1)
我以为它们存储在cookie中-但不,检查cookie没有任何结果。session也不存储它们。那么,我在哪里可以找到它们?我需要这个来直接设置它们(而不是通过flashhash)。 最佳答案 它们存储在inyoursessionstore.自rails2.0以来的默认设置是cookie存储,但请检查config/initializers/session_store.rb以检查您是否使用默认设置以外的东西。 关于ruby-on-rails-闪存消息存储在哪里?,我们在StackOverf
我正在尝试在ruby脚本中连接到服务器https://www.xpiron.com/schedule。但是,当我尝试连接时:require'open-uri'doc=open('https://www.xpiron.com/schedule')我收到以下错误消息:OpenSSL::SSL::SSLError:SSL_connectreturned=1errno=0state=SSLv2/v3readserverhelloA:sslv3alertunexpectedmessagefrom/usr/local/lib/ruby/1.9.1/net/http.rb:678:in`conn
我想知道我应该如何着手这个项目。我需要每周向人们发送一次电子邮件。但是,这必须在每周的特定时间自动生成并发送。编码有多难?我需要知道是否有任何书籍可以提供帮助,或者你们中的任何人是否可以指导我。它必须使用rubyonrails进行编程。因此有一个网络服务和数据库集成。干杯 最佳答案 为什么这么复杂?您只需安排工作。您可以使用Delayed::Job例如。Delayed::Job让您可以使用run_at符号在特定时间安排作业,如下所示:Delayed::Job.enqueue(SendEmailJob.new(...),:run_
我正在验证rubyonrails中的输入字段。我检查用户是否输入或填写了这些字段。如果假设name字段未填写,则向用户发送一条错误消息,指示name字段未填写。其他错误也是如此。我如何使用rubyonrails在json中发送这种消息。这是我现在正在做的。这个模型validates:email,:name,:company,:presence=>truevalidates_format_of:email,:with=>/\A[a-z0-9!#\$%&'*+\/=?^_`{|}~-]+(?:\.[a-z0-9!#\$%&'*+\/=?^_`{|}~-]+)*@(?:[a-z0-9
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su