徐蓓,腾讯云容器技术专家,腾讯云异构计算容器负责人,多年云计算一线架构设计与研发经验,长期深耕 Kubernetes、在离线混部与 GPU 容器化领域,Kubernetes KEP Memory QoS 作者,Kubernetes 积极贡献者。
GPU 具备大量核心和高速内存,擅长并行计算,非常适合训练和运行机器学习模型。由于近几年 AI 技术愈发成熟,落地场景越来越多,对 GPU 的需求呈井喷趋势。而在资源管理调度平台上,Kubernetes 已成为事实标准。所以很多客户选择在 Kubernetes 中使用 GPU 运行 AI 计算任务。
Kubernetes 提供 device plugin 机制,可以让节点发现和上报设备资源,供 Pod 使用。GPU 资源也是通过该方式提供。以 nvidia GPU 为例,用户在 Kubernetes 节点部署 nvidia-device-plugin,插件扫描节点 GPU 卡,会以 extended resource 机制将 GPU 资源以类似nvidia.com/gpu: 8的形式注册到节点中。用户创建 Pod 时指定该资源名,经过调度器调度后,Pod 绑定到节点,最终通过 nvidia docker 提供的一系列工具,将所需 GPU 设备挂载到容器里。
Kubernetes device plugin 提供了一种便捷的方式用于集成第三方设备。但应用在 GPU 场景,还是存在以下不足:
集群 GPU 资源缺少全局视角。没有直观方式可获取集群层面 GPU 信息,比如 Pod / 容器与 GPU 卡绑定关系、已使用 GPU 卡数 等
不能很好支持多 GPU 后端。各种 GPU 技术(nvidia docker、qGPU、vCUDA、gpu share、GPU 池化)均需独立部署组件,无法统一调度和管理
现有 Kubernetes 对 GPU 资源的分配调度是通过 extended resource 实现的,它是基于节点上卡数量的加减调度。用户如果想知道集群中 GPU 卡的分配情况,需要遍历节点,拿到并计算这些信息。并且由于这个资源是标量的,所以并无法拿到 Pod / 容器 与卡的绑定关系。这些问题在整卡模式下不是那么凸显,但在细粒度共享模式下,就尤为严重了。
由于 GPU 卡相对昂贵,并且某些 AI 负载吃不满单张 GPU 算力,GPU Sharing 技术应运而生。在 Kubernetes 中,我们会将一些 AI 负载共享同一张 GPU 卡,通过增加业务部署密度,提升 GPU 利用率,从而节省成本。以 TKE qGPU 为例,在 GPU Sharing 方式下,扩展资源从 GPU 卡数量变为百分比的 qGPU Core 与 MB 的 qGPU Memory。也就是说,用户可通过 qGPU 容器虚拟化技术,申请小于一张卡的 qGPU 虚拟设备。这些设备是在单张物理卡上虚拟出来的,资源之间也是强隔离的。除了 qGPU,vCUDA、gpu share 等技术都支持多个 Pod / 容器 共享同一张 GPU 卡。基于现有 Kubernetes 架构,是无法知道 GPU 卡所包含切片资源(我将之定义为 GPU Core 与 Memory 的组合)的分布情况的。集群资源分布对管理员与用户都是黑盒。管理员无法知道整个集群 GPU 切片资源的分配情况,用户也不知道新部署业务有无资源可用。
除分配挂载整卡的方式外,TKE qGPU、vCUDA、gpu share、GPU 池化 等 GPU 共享技术越来越被用户采用。每种方案都有自己独立的一套 Kubernetes 集成实现方式。比如在 TKE qGPU 中,我们自研了 tke-qgpu-scheduler 用于 GPU 细粒度算力与显存分配调度,配套的 tke-qgpu-manager,用于节点初始化、注册上报 qGPU 资源及 qGPU 容器虚拟化。vCUDA、gpu share 也是类似架构,同样是由调度器 + device plugin 组成。这些方案相互独立,没有统一标准,无法共通。这导致用户在单个集群中很难同时使用多种 GPU 后端技术。比如用户集群有些业务是在线推理,吃不满整卡,想申请 TKE qGPU 切片资源。另一部分业务是训练,需要分配单卡。有些仿真和模型调试业务,为了成本和弹性,想要动态从远端 GPU 池申请资源。现有方案很难同时满足以上诉求,这为基于 Kubernetes 构建统一 AI 基础设施平台增加了很多难度。
以上问题均是 TKE 在基于 Kubernetes 帮助客户构建 AI 计算平台时遇到的真实困扰。随着 AI 业务的不断精进,客户已不再仅满足于“能使用 Kubernetes GPU 资源”。对 GPU 成本的关注,对 GPU 资源的整体把控,对 GPU 不同后端的精准使用,都成为了客户能用好 GPU 算力的前提条件。既然现有体系无法满足,那我们就需要另辟蹊径,重新思考 GPU 在 Kubernetes 中的位置。
在 Kubernetes 中,资源一般是围绕 Pod 设计和定义。从重要程度上讲,集群可用资源包含两种类型:核心资源和外部资源。核心资源指维持 Pod 正常运行的必不可少的资源,包括 CPU、内存、临时存储、网卡 等。这些会通过 kubelet 扫描节点并上报到集群中。另一部分是外部资源,多指外挂存储和其他设备等,比如数据盘、GPU、FPGA 等。这些设备可能是本地设备挂载、也可能是远端设备挂载。这类资源的存在可以使得 Pod 更好的运行。比如数据盘增加了 Pod 的存储容量、GPU / FPGA 加速了 Pod 的计算能力。从这个角度看,存储与 GPU 有相似之处。
Kubernetes 在存储上抽象出了一组资源,如 PV / PVC / StorageClass,并为之提供了一组 API 和交互方式,将存储的供给管理和使用标准化和分离了出来。
用户通过 PV 在指定后端创建实际存储,用户通过 PVC 申请已创建的 PV 存储资源,或者指定 StorageClass 动态从后端创建 PV。
参照 Kubernetes 存储的设计方式,我们认为 GPU 也可定义和实现类似抽象。
我们定义了三种全新的 Kubernetes CRD,用于代表 GPU 资源的不同抽象:
type ElasticGPU struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Spec ElasticGPUSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
Status ElasticGPUStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
type ElasticGPUSpec struct {
Capacity v1.ResourceList `json:"capacity,omitempty" protobuf:"bytes,1,rep,name=capacity,casttype=ResourceList,castkey=ResourceName"`
ElasticGPUSource `json:",inline" protobuf:"bytes,2,opt,name=elasticGPUSource"`
ClaimRef v1.ObjectReference `json:"claimRef,omitempty" protobuf:"bytes,3,opt,name=claimRef"`
NodeAffinity GPUNodeAffinity `json:"nodeAffinity,omitempty" protobuf:"bytes,4,opt,name=nodeAffinity"`
NodeName string `json:"nodeName,omitempty" protobuf:"bytes,5,opt,name=nodeName"`
}
type ElasticGPUSource struct {
QGPU *QGPUElasticGPUSource `json:"qGPU,omitempty" protobuf:"bytes,1,opt,name=qGPU"`
PhysicalGPU *PhysicalGPUElasticGPUSource `json:"physicalGPU,omitempty" protobuf:"bytes,2,opt,name=physicalGPU"`
GPUShare *GPUShareElasticGPUSource `json:"gpuShare,omitempty" protobuf:"bytes,3,opt,name=gpuShare"`
}
type ElasticGPUClaim struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Spec ElasticGPUClaimSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
Status ElasticGPUClaimStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
type ElasticGPUClass struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Provisioner string `json:"provisioner" protobuf:"bytes,2,opt,name=provisioner"`
Parameters map[string]string `json:"parameters,omitempty" protobuf:"bytes,3,rep,name=parameters"`
}
下面以 TKE qGPU 为例,描述结合 Elastic GPU 方案的整个资源调度分配流程。
用户在集群中创建 ElasticGPUClass,指定 qGPU 作为 GPU 后端。
apiVersion: elasticgpu.io/v1alpha
kind: ElasticGPUClass
metadata:
name: qgpu-class
provisioner: elasticgpu.io/qgpu
reclaimPolicy: Retain
eGPUBindingMode: Immediate
创建 ElasticGPUClaim 描述对 qGPU 资源的申领,tke.cloud.tencent.com/qgpu-core代表申请 10% 的 GPU 算力,tke.cloud.tencent.com/qgpu-memory代表申请 4GB 显存。
apiVersion: elasticgpu.io/v1alpha
kind: ElasticGPUClaim
metadata:
name: qgpu-egpuc
spec:
storageClassName: qgpu-class
resources:
requests:
tke.cloud.tencent.com/qgpu-core: 10
tke.cloud.tencent.com/qgpu-memory: 4GB
用户在创建 Pod 时指定 ElasticGPUClaim 完成 qGPU 资源申领。
apiVersion: v1
kind: Pod
metadata:
name: qgpu-pod
annotations:
elasticgpu.io/egpuc-<container-name>: qgpu-egpuc
spec:
containers:
- name: test
考虑到 out-tree 的设计,qGPU 资源发现、上报和调度,还是依赖原有 device plugin 与 extended resource 机制。
我们通过 elastic-gpu-admission-hook 在 Pod 创建时识别 annotations elasticgpu.io/egpuc-<container-name>,将申请资源正确设置到 containers 中。
apiVersion: v1
kind: Pod
metadata:
name: qgpu-pod
annotations:
elasticgpu.io/egpuc-test: qgpu-egpuc
spec:
containers:
- name: test
resources:
requests:
tke.cloud.tencent.com/qgpu-core: 10
tke.cloud.tencent.com/qgpu-memory: 4GB
limits:
tke.cloud.tencent.com/qgpu-core: 10
tke.cloud.tencent.com/qgpu-memory: 4GB
qgpu-scheduler 扩展调度器用于 qGPU 资源调度,返回符合要求的节点。当 Pod 绑定到节点上后,qgpu-provisioner 会更新ElasticGPU CRD 中节点、GPU 卡索引 等信息,实现 qGPU 设备的绑定。
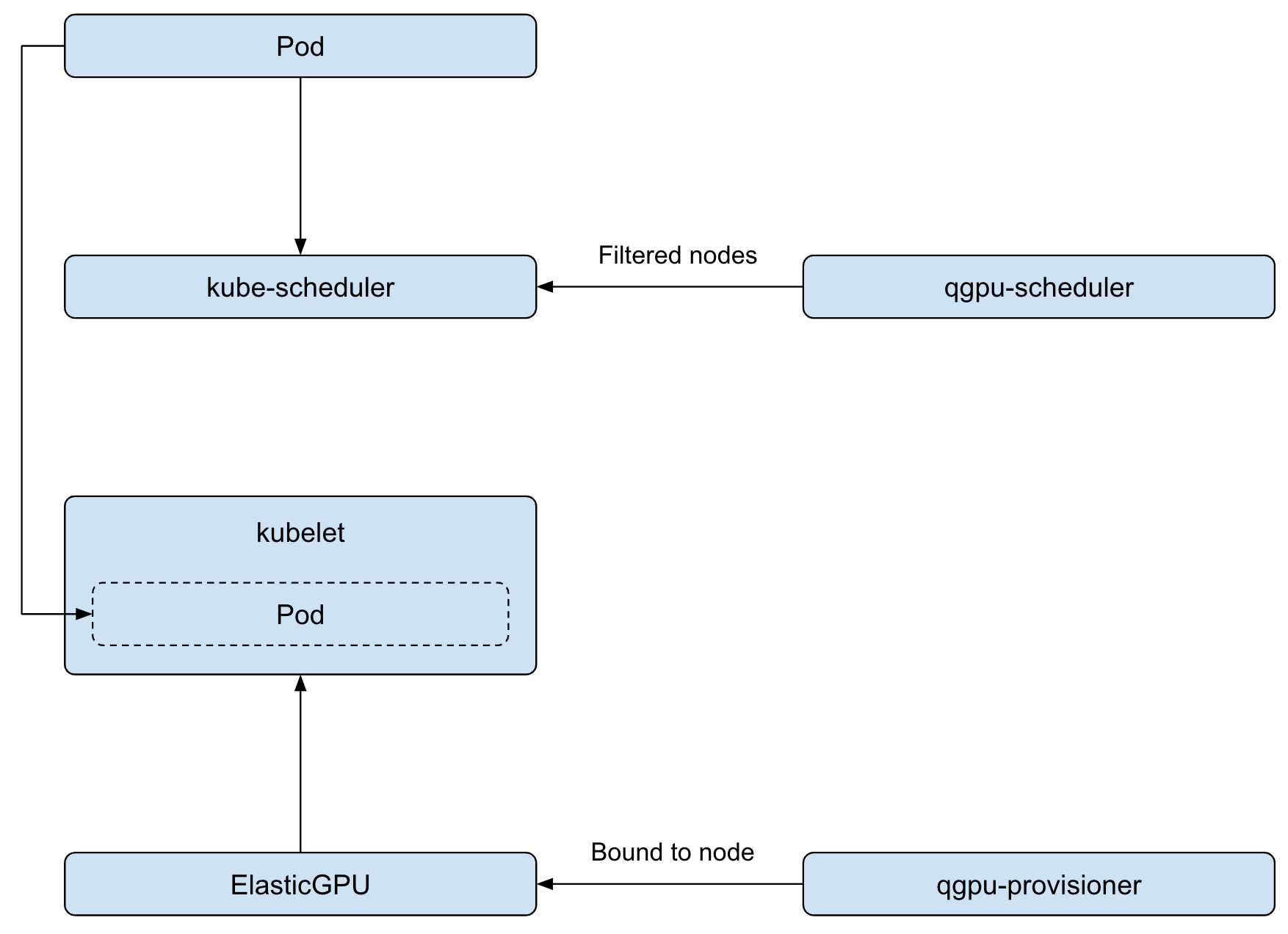
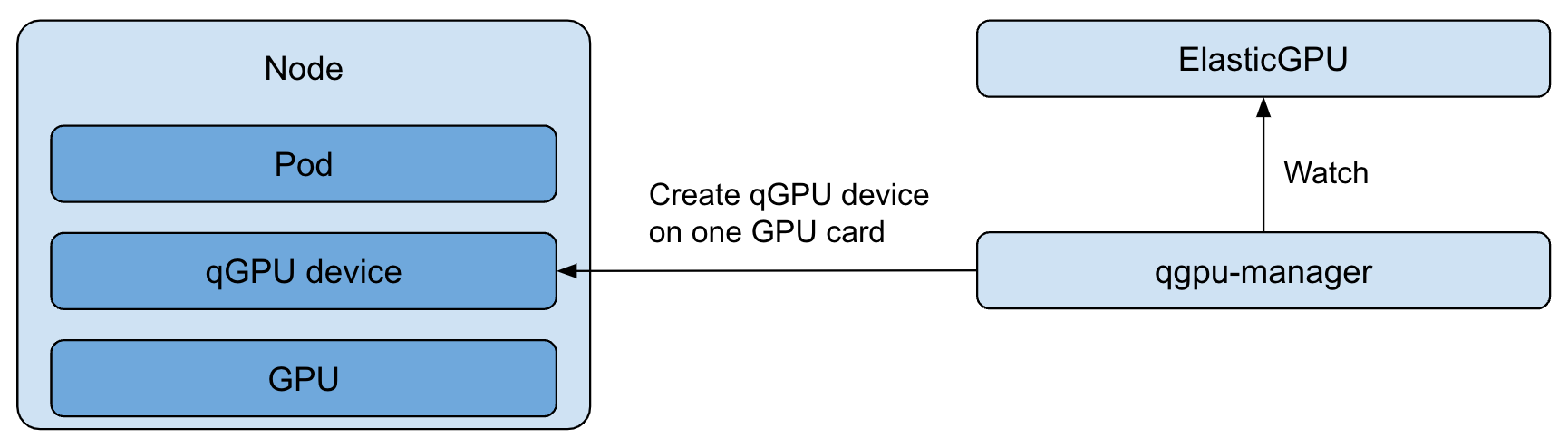
qgpu-manager 会 watch ElastciGPU CRD 变化,在绑定节点成功后,会执行创建 qGPU 设备的操作。qgpu-manager 会根据 CRD 中包含的申请算力与显存信息以及调度到的 GPU 卡索引,在底层创建 qGPU 设备。
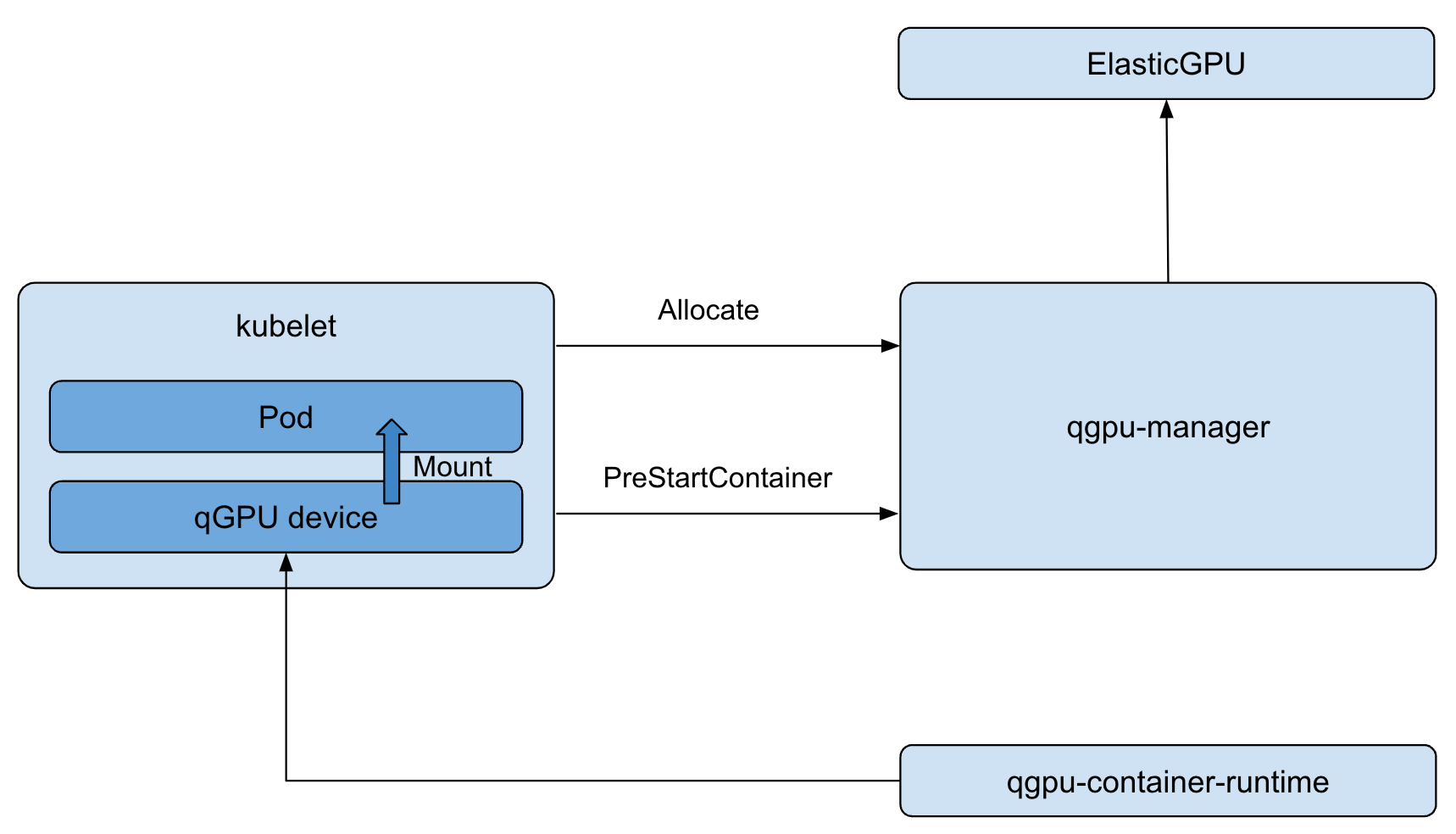
qgpu-manager 是一个 device plugin 插件,kubelet 会在分配 device 时通过标准接口调用插件。在接口 Allocate 和 PreStartContainer 中,我们会挂载必要的 qGPU、nvidia 设备以及设置环境变量。最后,我们依赖 qgpu-container-runtime 进行 qGPU 设备与容器的绑定工作。
随着 AI 业务的大规模落地,越来越多的用户在 Kubernetes 中使用 GPU 进行 AI 计算。现有的 extended resource 与 device plugin 机制很难满足客户对 GPU 资源的精细控制和分配,新的技术框架势在必行。Elastic GPU 在 Kubernetes 集群中抽象了一种 native GPU 资源,围绕三种自定义 CRD,在标准化定义了与其他 GPU 技术交互的前提下,同时提供了集群层面全局 GPU 资源视角,让用户可以更好的观察和管理 GPU 资源。
Elastic GPU 第一步会聚焦在 CRD 定义以及交互流程标准化,并首先适配 TKE qGPU。在这个阶段,我们希望参照 PV / PVC / CSI 的设计理念,以 Kubernetes native 的方式提供对 GPU 资源的抽象,标准化资源分配、调度、挂载等流程,并提供灵活的接口,供其他 GPU 技术集成。通过首先在生产环境支持 TKE qGPU,我们会持续打磨框架,发布第一个 alpha 版本。接下来,我们会推动社区实现对主流 GPU 技术的集成支持,包括 nvidia docker、gpu share 以及 vCUDA,横向扩展框架的适用场景。通过标准框架,统一接口和流程,降低客户管理成本。通过 GPU Sharing、Remote GPU 等技术提升灵活性、增加利用率,降低客户用卡成本。我们希望依赖 Elastic GPU 框架,最终可以为客户提供 Kubernetes 开箱即用使用 GPU 资源的能力。
TKE qGPU:https://cloud.tencent.com/document/product/457/61448
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
