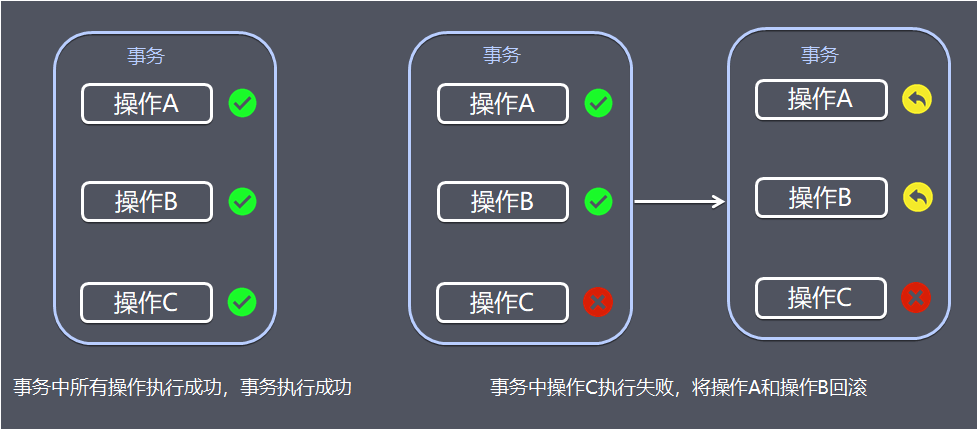
事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚。简单地说,事务提供一种“要么什么都不做,要么做全套(All or Nothing)”机制
说到数据库事务就不得不说,数据库事务中的四大特性,ACID
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
就像你买东西要么交钱收货一起都执行,要么要是发不出货,就退钱。
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态。如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
打个比方,你买东西这个事情,是不影响其他人的
指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
打个比方,你买东西的时候需要记录在账本上,即使老板忘记了那也有据可查。

简单而言,ACID是从不同维度描述事务的特性:
一个支持事务(Transaction)的数据库,需要具有这4种特性,否则在事务过程当中无法保证数据的正确性,处理结果极可能达不到请求方的要求。
在介绍完事务基本概念之后,什么时候该使用数据库事务?
简单而言,就是业务上有一组数据操作,需要如果其中有任何一个操作执行失败,整组操作全部不执行并恢复到未执行状态,要么全部成功,要么全部失败。
在使用数据库事务时需要注意,尽可能短的保持事务,修改多个不同表的数据的冗长事务会严重妨碍系统中的所有其他用户,这很有可能导致一些性能问题。
随着互联网快速发展,微服务,SOA等服务架构模式正在被大规模的使用,现在分布式系统一般由多个独立的子系统组成,多个子系统通过网络通信互相协作配合完成各个功能。
有很多用例会跨多个子系统才能完成,比较典型的是电子商务网站的下单支付流程,至少会涉及交易系统和支付系统,而且这个过程中会涉及到事务的概念,即保证交易系统和支付系统的数据一致性,此处我们称这种跨系统的事务为分布式事务,具体一点而言,分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。
举个互联网常用的交易业务为例:
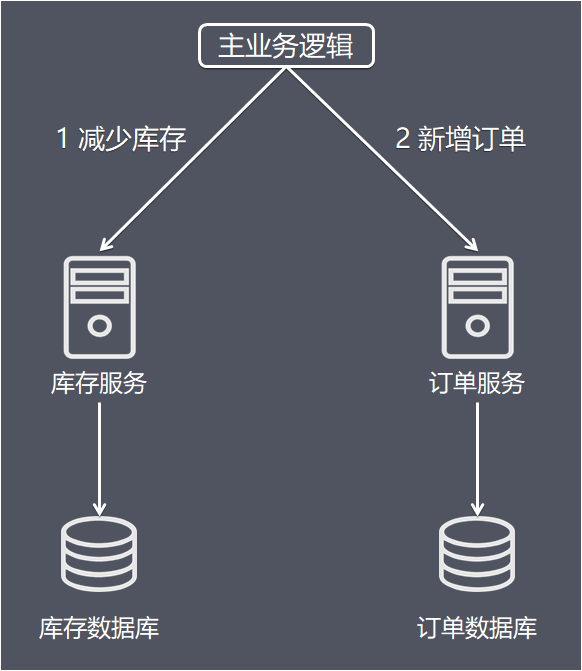
上图中包含了库存和订单两个独立的微服务,每个微服务维护了自己的数据库。在交易系统的业务逻辑中,一个商品在下单之前需要先调用库存服务,进行扣除库存,再调用订单服务,创建订单记录。
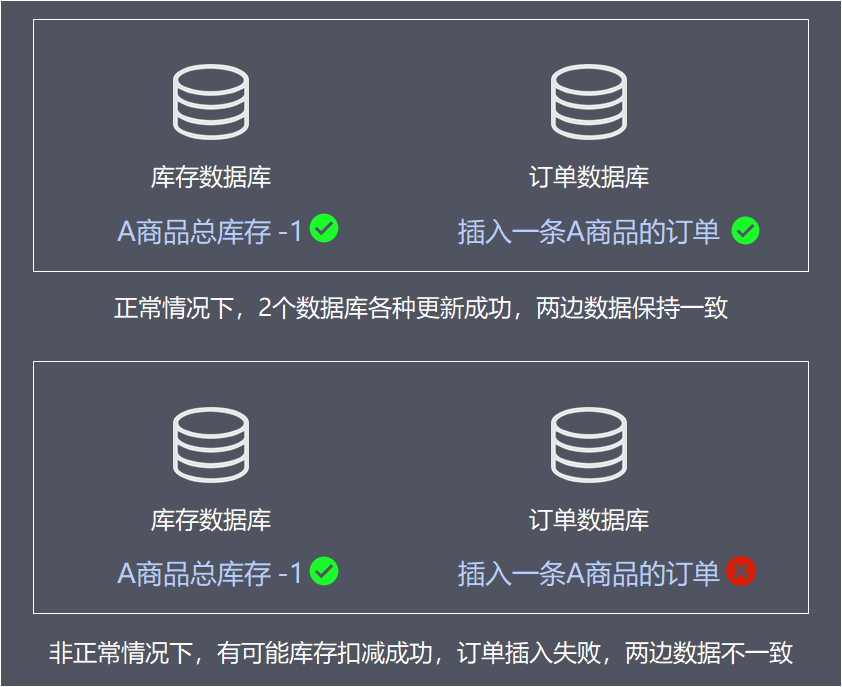
可以看到,如果多个数据库之间的数据更新没有保证事务,将会导致出现子系统数据不一致,业务出现问题。
事务操作跨不同节点,当多个节点某一节点操作失败时,需要保证多节点操作的**要么什么都不做,要么做全套(All or Nothing)**的原子性。
当发生网络传输故障或者节点故障,节点间数据复制通道中断,在进行事务操作时需要保证数据一致性,保证事务的任何操作都不会使得数据违反数据库定义的约束、触发器等规则。
事务隔离性的本质就是如何正确多个并发事务的处理的读写冲突和写写冲突,因为在分布式事务控制中,可能会出现提交不同步的现象,这个时候就有可能出现“部分已经提交”的事务。此时并发应用访问数据如果没有加以控制,有可能出现“脏读”问题。
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
保存成功后可以回滚吗?让我有一个带有属性名称、电子邮件等的用户模型。例如u=User.newu.name="test_name"u.email="test@email.com"u.save现在记录将成功保存在数据库中,之后我想回滚我的事务(不是销毁或删除)。有什么想法吗? 最佳答案 您可以通过交易来做到这一点,请参阅http://markdaggett.com/blog/2011/12/01/transactions-in-rails/例子:User.transactiondoUser.create(:username=>'Nemu
我目前正在上一门数据库类(class),其中一个实验室问题让我困惑于如何实现上述内容,事实上,如果可能的话。我试过搜索docs但是定义的交易方式比较模糊。这是我第一次尝试在没有Rails的情况下进行任何数据库操作,所以我有点迷茫。我已经成功地创建了一个到我的postgresql数据库的连接并且可以执行语句,我需要做的最后一件事是根据一个简单的条件回滚一个事务。请允许我向您展示代码:require'pg'@conn=PG::Connection.open(:dbname=>'db_15_11_labs')@conn.prepare('insert','INSERTINTOhouse(ho
如何使用Rails中的事务block一次性更新/保存模型的多个实例?我想更新数百条记录的值;每条记录的值都不同。这不是一个属性的批量更新情况。Model.update_all(attr:value)在这里不合适。MyModel.transactiondothings_to_update.eachdo|thing|thing.score=rand(100)+rand(100)thing.saveendendsave似乎发布了它自己的事务,而不是将更新分批处理到周围的事务中。我希望所有更新都在一次大交易中进行。我怎样才能做到这一点? 最佳答案
给定以下代码:defcreate@something=Something.new(params[:something])thing=@something.thing#anothermodel#modificationofattributesonboth'something'and'thing'omitted#doIneedtowrapitinsideatransactionblock?@something.savething.saveendcreate方法是隐式包装在ActiveRecord事务中,还是需要将其包装到事务block中?如果我确实需要包装它,这是最好的方法吗?
我为你们准备了一个简单的。我想要一个特色内容部分,其中排除了当前文章所以这可以通过delete_if使用MiddlemanBlog:但是我使用的是中间人代理,所以我无法访问current_article方法...我有一个YAML结构,其中包含以下模拟数据(以及其他数据),文件夹设置如下:data>site>caseStudy>RANDOM-ID423536.yaml(由CMS生成)在每个yaml文件中,您会发现如下内容::id:2k1YccJrQsKE2siSO6o6ac:title:Heyplace我的config.rb看起来像这样data.site.caseStudy.eachdo
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如
我正在为我的网站使用MiddlemanBloggem,但默认情况下,博客文章似乎需要位于/source中,这在查看vim中的树时并不是特别好并尝试在其中找到其他文件之一(例如模板)。通过查看文档,我看不出是否有任何方法可以移动博客文章,以便将它们存储在其他地方,例如blog_articles文件夹或类似文件夹。这可能吗? 最佳答案 将以下内容放入您的config.rb文件中。activate:blogdo|blog|blog.permalink=":year-:month-:day-:title.html"blog.sources=