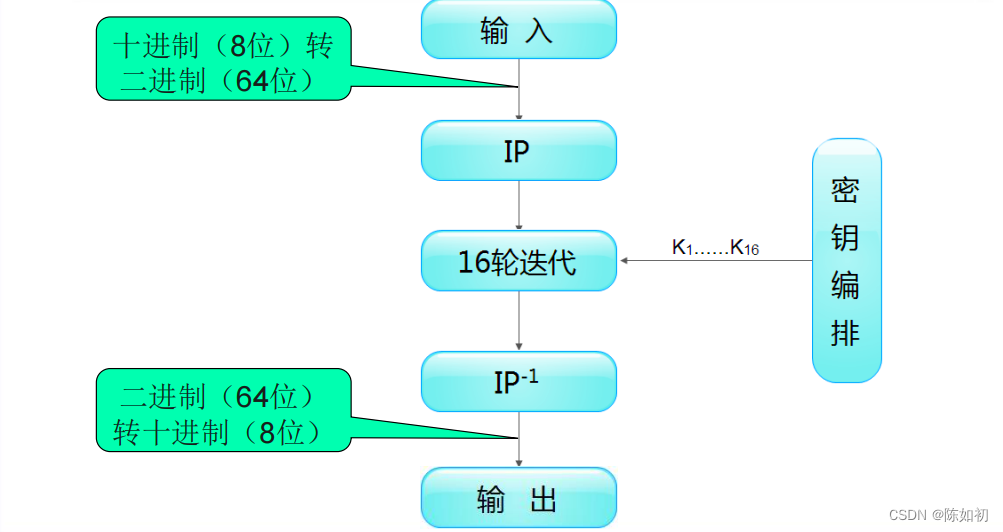
*细节流程图
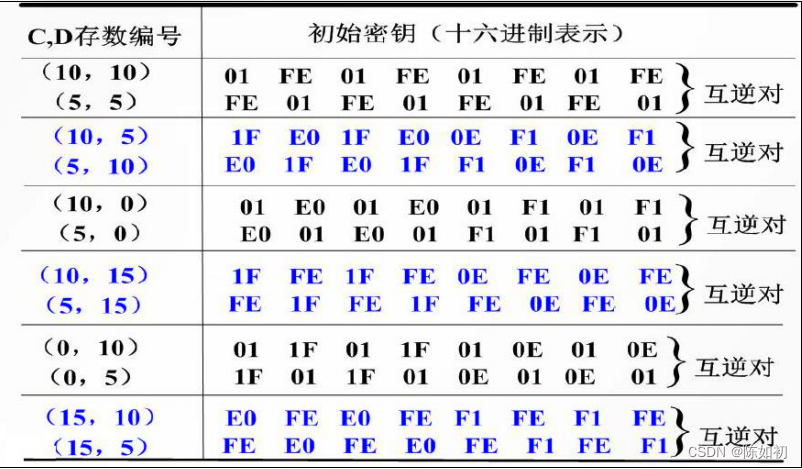
等分密钥:
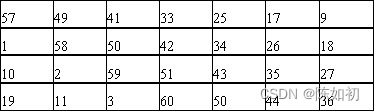
输入密钥位序/ A位序对照表
输入密钥位序/ B位序对照表
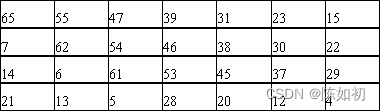
这样 key=k1k2k3…k55k56 形成了A、B两部分:
A = k57k49k41…k44k36
B=k65k55k47…k12k4
密钥移位
DES算法的密钥是经过16次迭代(循环左移)得到一组密钥的
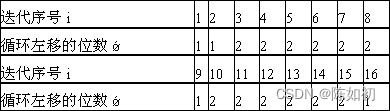
Ps:生成的A、B视为迭代的起始密钥,上表显示每一次迭代时密钥循环左移的位数。 比如在第1次迭代时密钥循环左移1位,第3次迭代时密钥循环左移2位…第9次迭代时密钥循环左移1位,第14次迭代时密钥循环左移2位。
迭代并乘积合并得到密钥C
第一次迭代:
A(1) =(1) A
第i次迭代:
A(i) =(i) A(i-1)
B(i) =(i) B(i-1)
第i次迭代生成的两个28位长的密钥并乘积得到56位密钥C(i)=A(i)B(i)=A(i)1…A(i)28B(i)1…B(i)28
按下述规则进行16次迭代: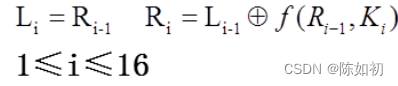
Ps1:这里的 “+” 是对应比特的模加2,f 是一个函数(轮函数)。
Ps2:16个长度为48比特的子密钥ki(1≤i≤16)是由密钥k经密钥编排函数计算出来的。
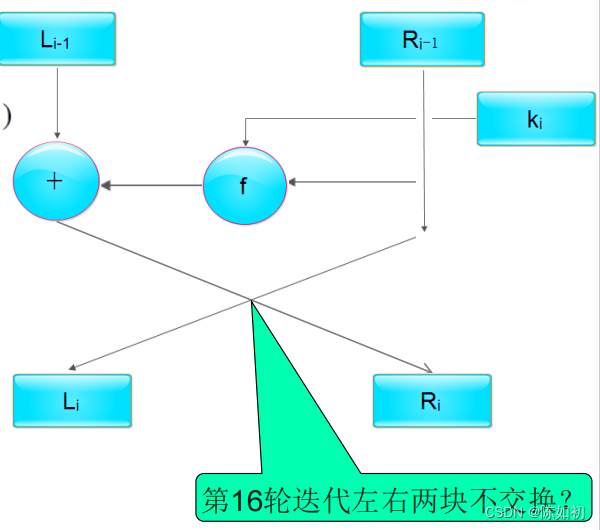 Ps3:第16轮迭代左右数值不做交换
Ps3:第16轮迭代左右数值不做交换
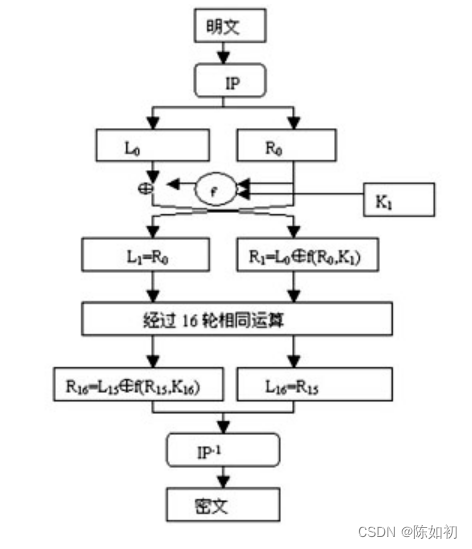
给定明文,通过一个固定的初始置换IP来重排输入明文块P中的比特,得到比特串P0=IP(P)=L0R0,这 里L0和R0分别是P0的前32比特和后32比特
Ps:利用乘积密码可获得简单的代换密码
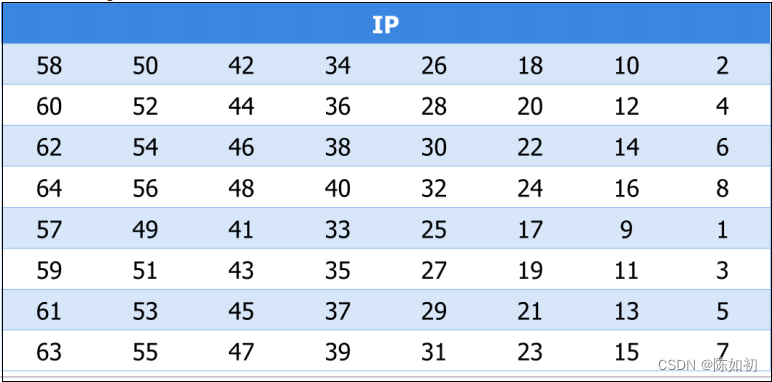
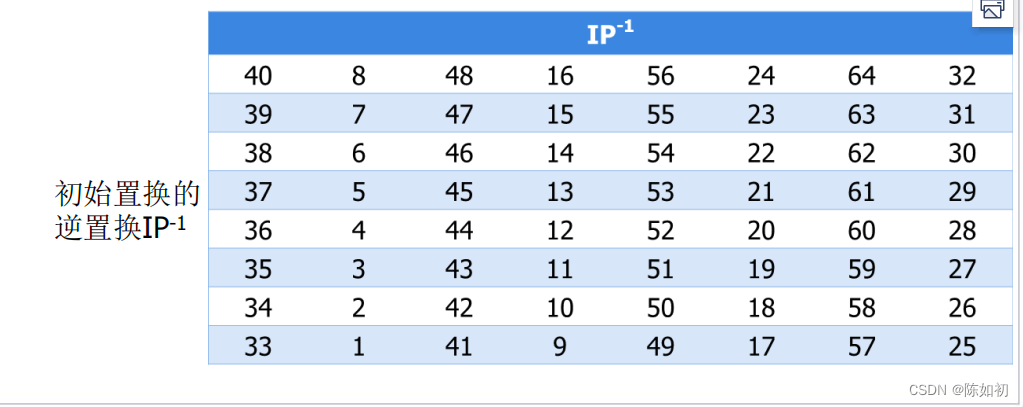
对比特串R16L16使用逆置换IP-1得到密文C,即
C=IP-1 (R16L16)。
1.总体过程
DES对64位明文分组进行操作。通过一个初始置换,将明文分组分成左半部分和右半部分,各32位长。
然后进行16轮完全相同的运算,这些运算被称为函数 f,在运算过程中数据与密钥结合。经过16轮
后,左、右半部分合在一起经过一个末置换(初始置换的逆置换),算法就完成了。
在每一轮中,密钥位移位,然后再从密钥的56位中选出48位。通过一个扩展置换将数据的右半部分
扩展成48位,并通过一个异或操作与48位密钥结合,通过 8个S盒将这48位替代成新的32位数据,再
将其置换一次。这四步运算构成了函数f。然后,通过另一个异或运算,函数f的输出与左半部分结合,
其结果即成 为新的左半部分。将该操作重复16次,便实现了DES的16轮运算。
假设Bi是第i次迭代的结果,Li和Ri是Bi的左半部分和右半部分,Ki是第i轮的48位密钥,且f是实现
代替、置换及密钥异或等运算的函数,那么每一轮就是:
Li=Ri-1
Ri=Li-1⊕f(Ri-1,Ki)
2、初始置换
初始置换在第一轮运算之前进行,对输入分组实施如下表所示的变换。初始置换把明文的第58位换到第1位的位置,把第50位换到第2位的位置,把第42位换到第3位的位置,以此类推。
58, 50, 42, 34, 26, 18, 10, 2, 60, 52, 44, 36, 28, 20, 12, 4
62, 54, 46, 38, 30, 22, 14, 6, 64, 56, 48, 40, 32, 24, 16, 8
57, 49, 41, 33, 25, 17, 9, 1, 59, 51, 43, 35, 27, 19, 11, 3
61, 53, 45, 37, 29, 21, 13, 5, 63, 55, 47, 39, 31, 23, 15, 7
初始置换和对应的末置换并不影响DES的安全性,它们的主要目的是为了更容易地将明文和密文数据以字节大小放入DES芯片中。
3、密钥置换
由于不考虑每个字节的第8位,DES的密钥由64位减至56位,每个字节第8位作为奇偶校验以确保密钥不发生错误。如下表所示:
57, 49, 41, 33, 25, 17, 9, 1, 58, 50, 42, 34, 26, 18
10, 2, 59, 51, 43, 35, 27, 19, 11, 3, 60, 52, 44, 36
63, 55, 47, 39, 31, 23, 15, 7, 62, 54, 46, 38, 30, 22
14, 6, 61, 53, 45, 37, 29, 21, 13, 5, 28, 20, 12, 4
在DES的每一轮中,从56位密钥产生出不同的48位子密钥(subkey),这些子密钥是这样确定的:
首先,56位密钥被分成两部分,每部分28位。
然后,根据轮数,这两部分分别循环左移1位或2位。每轮移动的位数如下表:
轮 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
位数 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 1
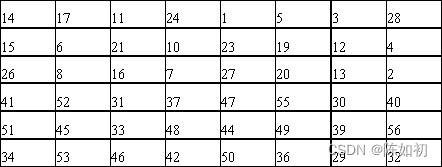
移动后,就从56位中选出48位。这个运算既置换了每位的顺序,也选择了子密钥,被称为压缩置换(compression permutation)。下表即定义了压缩置换:
14, 17, 11, 24, 1, 5, 3, 28, 15, 6, 21, 10
23, 19, 12, 4, 26, 8, 16, 7, 27, 20, 13, 2
41, 52, 31, 37, 47, 55, 30, 40, 51, 45, 33, 48
44, 49, 39, 56, 34, 53, 46, 42, 50, 36, 29, 32
可以看出,第33位的那一位在输出时移到了第35位,而处于第18位的那一位被忽略了。
4、扩展置换 (轮函数f的一部分)
这个运算将数据的右半部分从32位扩展到48位。这个操作两方面的目的:它产生了与密钥同长度的数据以进行异或运算;它提供了更长的结果,使得在替代运算中能进行压缩。
对每个4位输入分组,第1位和第4位分别表示输出分组中的两位,而第2位和第3位分别表示输出分组中的一位,下表给出了哪一输出位对应哪一输入位:
32, 1, 2, 3, 4, 5, 4, 5, 6, 7, 8, 9
8, 9, 10, 11, 12, 13, 12, 13, 14, 15, 16, 17
16, 17, 18, 19, 20, 21, 20, 21, 22, 23, 24, 25
24, 25, 26, 27, 28, 29, 28, 29, 30, 31, 32, 1
处于输入分组中第3位的位置移到了输出分组中的第4位,而输入分组的第21位则移到了输出分组的第30位和第32位。尽管输出分组大于输入分组,但每一个输入分组产生唯一的输出分组。
5、S盒代替 (轮函数f的一部分)
压 缩后的密钥与扩展分组异或以后,将48位的结果送入,进行代替运算。替代由8个S盒完成,每一个S盒都由6位输入,4位输出,且这8个S盒是不同的。48 位的输入被分为8个6位的分组,每一个分组对应一个S盒代替操作:分组1由S盒1操作,分组2由S盒2操作,等等。如下图所示:
每一个S盒是一个4行、16列的表。盒中的每一项都是一个4位的数。S盒的6个位输入确定了其对应的输出在哪一行哪一列。下表列出所有8个S盒:
S盒1:
14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7
0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8
4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0
15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13
S盒2:
15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10
3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5
0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15
13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9
S盒3:
10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8
13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1
13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7
1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12
S盒4:
7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5 ,11, 12, 4, 15
13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14, 9
10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4
3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14
S盒5:
2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9
14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6
4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14
11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3
S盒6:
12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11
10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8
9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6
4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13
S盒7:
4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1
13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6
1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2
6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12
S盒8:
13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7
1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2
7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8
2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11
假定将S盒的6位的输入标记位b1、b2、b3、b4、b5、b6。则b1和b6组合构成了一个2位数,从0到3,它对应着表的一行。从b2到b5构成了一个4位数,从0到15,对应着表中的一列。
例如,假设第6个S盒的输入为110011,第1位和第6位组合形成了11,对应着第6个S盒的第三行,中间4位组合形成了1001,它对应着同一个S盒的第9列,S盒6在第三行第9列的数是14,则用值1110来代替110011。
这是DES算法的关键步骤,所有其他的运算都是线性的,易于分析,而S盒是非线性的,它比DES的其他任何一步提供了更好的安全性。
这个代替过程的结果是8个4位的分组,他们重新合在一起形成了一个32位的分组。
6、P盒置换 (轮函数f的一部分)
S盒代替运算的32位输出依照P盒进行置换。该置换把每输入位映射到输出位,任一位不能被映射两次,也不能被略去,下表给出了每位移至的位置:
16, 7, 20, 21, 29, 12, 28, 17, 1, 15, 23, 26, 5, 18, 31, 10
2, 8, 24, 14, 32, 27, 3, 9, 19, 13, 30, 6, 22, 11, 4, 25
第21位移到了第4位,同时第4位移到了第31位。
最后,将P盒置换的结果与最初的64位分组的左半部分异或,然后左、右半部分交换,接着开始另一轮。
7、末置换 (轮函数f的一部分)
末置换是初始置换的逆过程。DES在最后一轮后,左半部分和右半部分并未交换,而是将两部分并在一起形成一个分组作为末置换的输入,该置换如下表如示:
40, 8, 48, 16, 56, 24, 64, 32, 39, 7, 47, 15, 55, 23, 63, 31
38, 6, 46, 14, 54, 22, 62, 30, 37, 5, 45, 13, 53, 21, 61, 29
36, 4, 44, 12, 52, 20, 60, 28, 35, 3, 43, 11, 51, 19, 59, 27
34, 2, 42, 10, 50, 18, 58, 26, 33, 1, 41, 9, 49, 17, 57, 25
8、DES的解密
DES使得用相同的函数来加密或解密每个分组成为可能,二者唯一的不同就是密钥的次序相反。
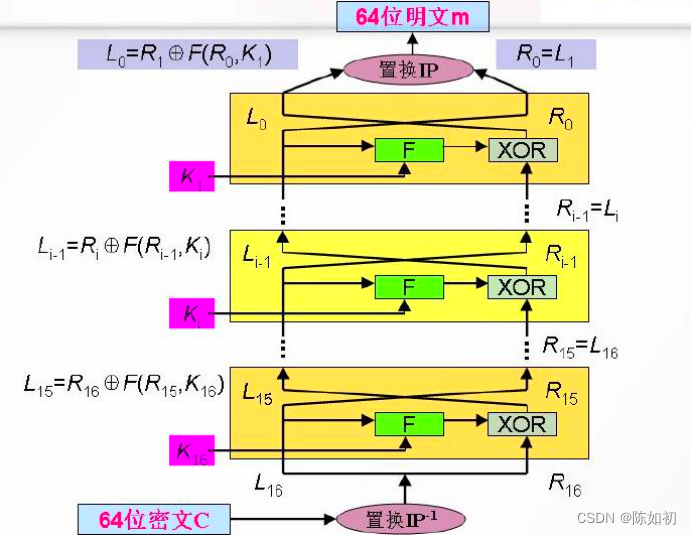
& DES的核心是S盒,除此之外的计算是线性的
& S盒作为该密码体制的非线性组件对安全性至
关重要
& S盒的设计准则:
1、 具有良好的非线性(输出的每一个比特与全部
输入比特有关)
2、每一行包括所有16种4位二进制
3、两个输入相差1bit时,输出相差2bit
4、 如果两个输入刚好在中间两个比特上不同,则
输出至少有两个比特不同
5、 如果两个输入前两位不同而最后两位相同,则
输出一定不同
6、 相差6bit的输入共有32对,在这32对中有不超
过8对的输出相同
密钥分配问题:通信双方要进行加密通信,
需要通过秘密的安全信道协商加密密钥,而
这种安全信道可能很难实现
密钥管理问题:在有多个用户的网络中,任
何两个用户之间都需要有共享的秘密钥,当
网络中的用户n很大时,需要管理的密钥数目
非常大n(n-1)/2
互补性,是由算法中的两次异或运算的配置所决定的。两次异或运算一次在S盒之前,一次在P盒置换之后。
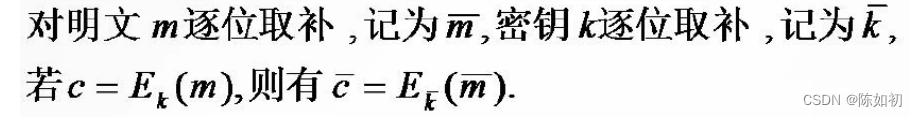
若对DES输入的明文和密钥同时取补,则选择扩展运算E的输出和子密钥产生器的输出也都取补,因
而经异或运算后的输出和明文及密钥未取补时的输出一样,这使得到达S盒的输入数据未变,其输出自然也不会变,但经第二个异或运算时,由于左边的数据已取补,因而输出也就取补了
互补性会使DES在选择明文攻击下所需的工作量减半
弱密钥和半弱密钥

若给定初始密钥k,产生的16个子密钥只有两种,且每种都出现8次,则称k为半弱密钥。
半弱密钥的特点是成对出现, 且具有下述性质:
若k1和k2为一对弱密钥,m为明文组,则有:Ek2(Ek1(m))=Ek1(Ek2(m))=m此外,还有四分之一弱密钥等。
DES的密钥中,弱密钥的比例非常小,而且极易避开,因此,弱密钥的存在对DES的安全性威胁不大。
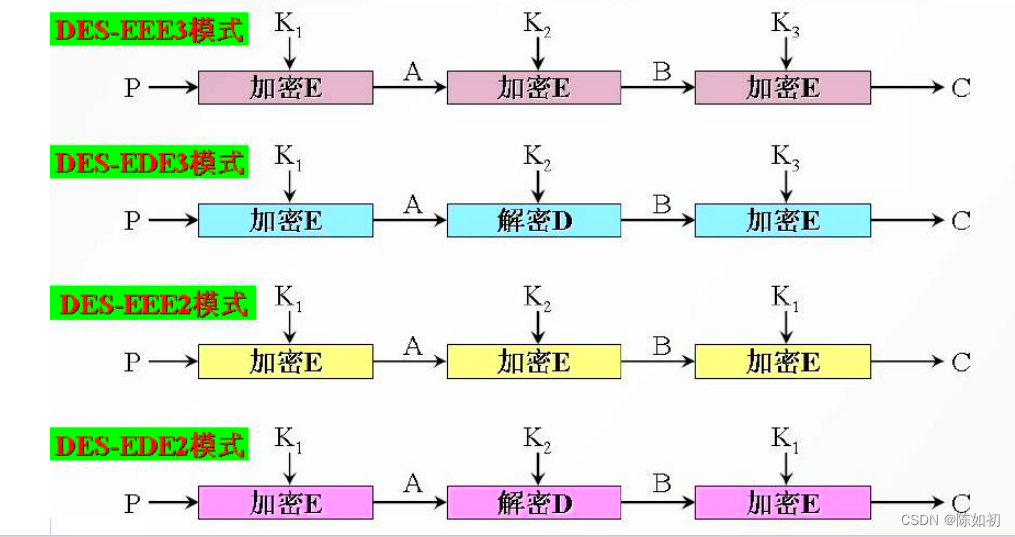
密钥搜索
DES的强度:56比特的密钥长度:
差分分析和线性分析
线性分析(实际上不可行)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <openssl/des.h>
#pragma comment(lib,"libssl.lib")
#pragma comment(lib,"libcrypto.lib")
using namespace std;
/************************************************************************
** 本例采用:
** 3des-ecb加密方式;
** 24位密钥,不足24位的右补0x00;
** 加密内容8位补齐,补齐方式为:少1位补一个0x01,少2位补两个0x02,...
** 本身已8位对齐的,后面补八个0x08。
************************************************************************/
int main(void)
{
int docontinue = 1;
char data[20] = "hello world!"; /* 明文 */
int data_len;
int data_rest;
unsigned char ch;
unsigned char* src = NULL; /* 补齐后的明文 */
unsigned char* dst = NULL; /* 解密后的明文 */
int len;
unsigned char tmp[8];
unsigned char in[8];
unsigned char out[8];
char k[100] = "01234567899876543210"; /* 原始密钥 */
int key_len;
#define LEN_OF_KEY 24
unsigned char key[LEN_OF_KEY]; /* 补齐后的密钥 */
unsigned char block_key[9];
DES_key_schedule ks, ks2, ks3;
/* 构造补齐后的密钥 */
key_len = strlen(k);
memcpy(key, k, key_len);
memset(key + key_len, 0x00, LEN_OF_KEY - key_len);
/* 分析补齐明文所需空间及补齐填充数据 */
data_len = strlen(data);
data_rest = data_len % 8;
len = data_len + (8 - data_rest);
ch = 8 - data_rest;
src = (unsigned char*)malloc(len);
dst = (unsigned char*)malloc(len);
if (NULL == src || NULL == dst)
{
docontinue = 0;
}
if (docontinue)
{
int count;
int i;
/* 构造补齐后的加密内容 */
memset(src, 0, len);
memcpy(src, data, data_len);
memset(src + data_len, ch, 8 - data_rest);
/* 密钥置换 */
memset(block_key, 0, sizeof(block_key));
memcpy(block_key, key + 0, 8);
DES_set_key_unchecked((const_DES_cblock*)block_key, &ks);
memcpy(block_key, key + 8, 8);
DES_set_key_unchecked((const_DES_cblock*)block_key, &ks2);
memcpy(block_key, key + 16, 8);
DES_set_key_unchecked((const_DES_cblock*)block_key, &ks3);
printf("before encrypt:\n");
for (i = 0; i < len; i++)
{
printf("0x%.2X ", *(src + i));
}
printf("\n");
/* 循环加密/解密,每8字节一次 */
count = len / 8;
for (i = 0; i < count; i++)
{
memset(tmp, 0, 8);
memset(in, 0, 8);
memset(out, 0, 8);
memcpy(tmp, src + 8 * i, 8);
/* 加密 */
DES_ecb3_encrypt((const_DES_cblock*)tmp, (DES_cblock*)in, &ks, &ks2, &ks3, DES_ENCRYPT);
/* 解密 */
DES_ecb3_encrypt((const_DES_cblock*)in, (DES_cblock*)out, &ks, &ks2, &ks3, DES_DECRYPT);
/* 将解密的内容拷贝到解密后的明文 */
memcpy(dst + 8 * i, out, 8);
}
printf("after decrypt :\n");
for (i = 0; i < len; i++)
{
printf("0x%.2X ", *(dst + i));
}
printf("\n");
}
if (NULL != src)
{
free(src);
src = NULL;
}
if (NULL != dst)
{
free(dst);
dst = NULL;
}
return 0;
}
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
我想使用spawn(针对多个并发子进程)在Ruby中执行一个外部进程,并将标准输出或标准错误收集到一个字符串中,其方式类似于使用Python的子进程Popen.communicate()可以完成的操作。我尝试将:out/:err重定向到一个新的StringIO对象,但这会生成一个ArgumentError,并且临时重新定义$stdxxx会混淆子进程的输出。 最佳答案 如果你不喜欢popen,这是我的方法:r,w=IO.pipepid=Process.spawn(command,:out=>w,:err=>[:child,:out])