HTTP :
计算机与网络设备要相互通信,双方就必须基于相同的方法。
Web使用一种名为HTTP(HyperText Transfer Protocol,超文本传输协议)的协议作为规范,完成从客户端到服务器端等一系列运作流程。
URL :
URL为应用程序提供了一种访问资源的手段。
URL提供了一种统一的资源命名方式。大多数URL都有同样的:“协议://服务器位置/路径”结构。
代理 :
位于客户端和服务器之间的HTTP中间实体。

出于安全考虑,通常会将代理作为转发所有Web流量的可信任中间节点使用。代理还可以对请求和响应进行过滤。
缓存 HTTP的仓库,使常用页面的副本可以保存在离客户端更近的地方。

网关 连接其他应用程序的特殊Web服务器。
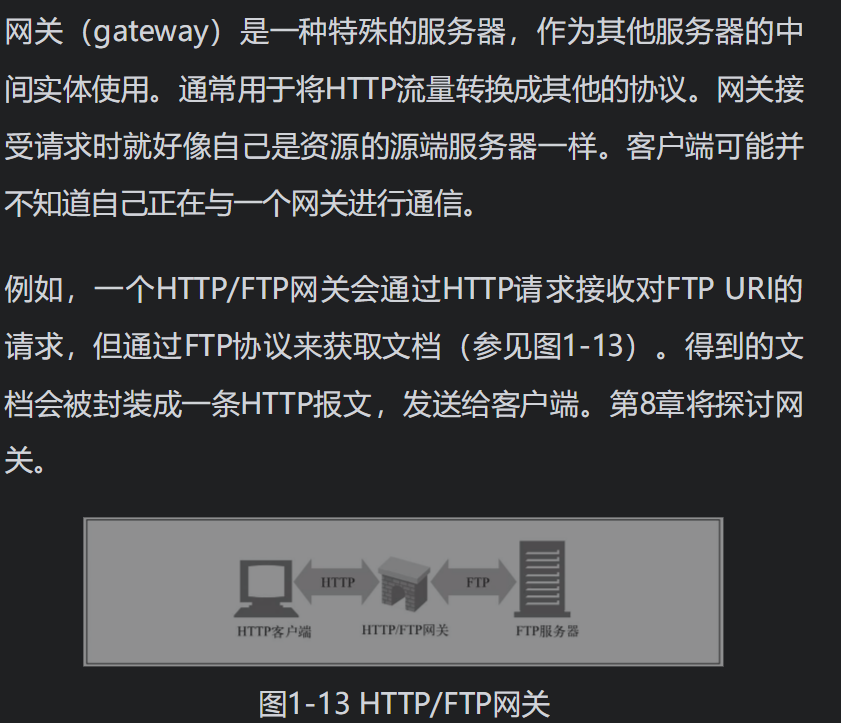
隧道 对HTTP通信报文进行盲转发的特殊代理。

Agent 代理发起自动HTTP请求的半智能Web客户端。

HTTP协议位于TCP的上层。HTTP使用TCP来传输其报文数据。
而在TCP中,你需要知道服务器的IP地址,以及与服务器上运行的特定软件相关的TCP端口号。
那么IP地址和端口号从哪里来的?URL!
补充:平时我们没打端口号是因为默认的协议有常用端口号,会自动填充。
具体步骤如下:
首先,什么是HTTP报文?
HTTP报文包括以下三个部分。
起始行
报文的第一行就是起始行,在请求报文中用来说明要做些什么,在响应报文中说明出现了什么情况。
总之,对报文进行描述。
首部字段
起始行后面有零个或多个首部字段。每个首部字段都包含一个名字和一个值,为了便于解析,两者之间用冒号(:)来分隔。首部以一个空行结束。添加一个首部字段和添加新行一样简单。
总之,包含属性。
主体
空行之后就是可选的报文主体了,其中包含了所有类型的数据。请求主体中包括了要发送给Web服务器的数据;响应主体中装载了要返回给客户端的数据。起始行和首部都是文本形式且都是结构化的,而主体则不同,主体中可以包含任意的二进制数据(比如图片、视频、音轨、软件程序)。当然,主体中也可以包含文本。
总之,是包含数据、可选的(可以为空)。
其次,什么是请求报文/响应报文?
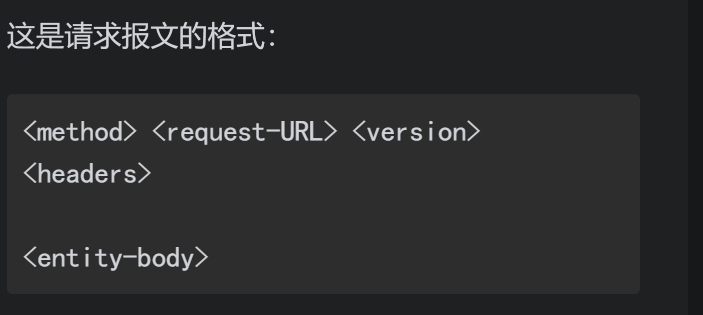
其中的几点如下:
method
客户端希望服务器对资源执行的动作。
request-URL
命名了所请求资源,或者URL路径组件的完整URL。
version
报文所使用的HTTP版本
status
status-code 这三位数字描述了请求过程中所发生的情况。
reason-phrase 数字状态码的可读版本,包含行终止序列之前的所有文本。原因短语只对人类有意义
headers
可以有零个或多个首部,由一个空行(CRLF)结束的,表示了首部列表的结束和实体主体部分的开始。
HTTP/1.1,要求有效的请求或响应报文中必须包含特定的首部。
entity-body
实体的主体部分包含一个由任意数据组成的数据块。并不是所有的报文都包含实体的主体部分,有时,报文只是以一个CRLF结束。
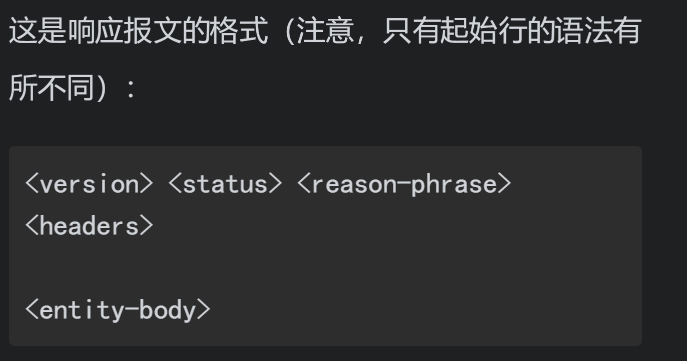
响应报文的起始行说明发生了什么。
请求报文请求服务器对资源进行一些操作。请求报文的起始行,或称为请求行,包含了一个方法和一个请求URL,这个方法描述了服务器应该执行的操作,请求URL描述了要对哪个资源执行这个方法。请求行中还包含HTTP的版本,用来告知服务器,客户端使用的是哪种HTTP。所有这些字段都由空格符分隔。
只有起始行的语法有所不同。
常见的响应码分类:

1xx:信息性状态码
2xx:成功状
3xx:重定向
4xx:客户端错误
5xx:服务端错误
常见状态码:
200 OK
302 Found
304 Not Modified
400 Bad Request
401 Unauthorized
403 Forbidden
404 Not Found
500 Internal Server Error
502 Bad Gateway
503 Unaviable
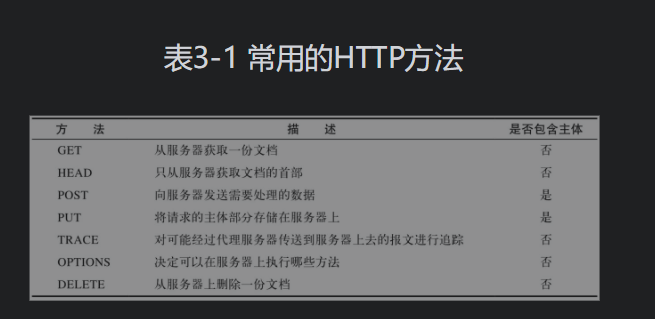






在HTTP/1.1中,所有的连接默认都是持久连接,但在HTTP/1.0内并未标准化。
HTTP1.1 持久连接使得多数请求以管线化(pipelining)方式发送成为可能。管线化技术出现后,不用等待响应亦可直接发送下一个请求。
HTTP/2.0的特点 HTTP/2.0的目标是改善用户在使用Web时的速度体验。
HTTP主要有这些不足,例举如下:
通信使用明文(不加密),内容可能会被窃听(TCP/IP是可能被窃听的网络)
不验证通信方的身份,因此有可能遭遇伪装

无法证明报文的完整性,所以有可能已遭篡改
通信加密
将通信加密。HTTP协议中没有加密机制,但可以通过和SSL(Secure Socket Layer,安全套接层)或TLS(Transport Layer Security,安全传输层协议)的组合使用,加密HTTP的通信内容。用SSL建立安全通信线路之后,就可以在这条线路上进行HTTP通信了。
内容加密
前提是要求客户端和服务器同时具备加密和解密机制。主要应用在Web服务中。有一点必须引起注意,由于该方式不同于SSL或TLS将整个通信线路加密处理,所以内容仍有被篡改的风险。
SSL不仅提供加密处理,而且还使用了一种被称为证书的手段,可用于确定方。
证书由值得信任的第三方机构颁发,用以证明服务器和客户端是实际存在的。
虽然有使用HTTP协议确定报文完整性的方法,但事实上并不便捷、可靠。其中常用的是MD5和SHA-1等散列值校验的方法,以及用来确认文件的数字签名方法。
SSL提供认证和加密处理及摘要功能。
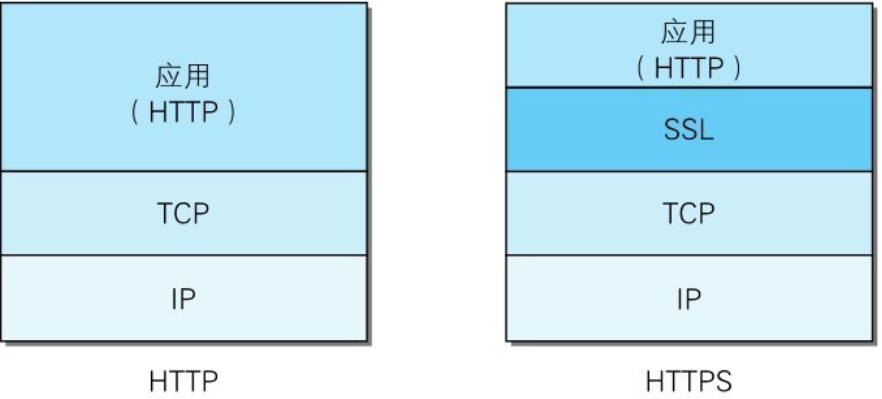
HTTP+加密+认证+完整性保护=HTTPS
HTTPS并非是应用层的一种新协议。只是HTTP通信接口部分用SSL(Secure Socket Layer)和TLS(Transport Layer Security)协议代替而已。
通常,HTTP直接和TCP通信。当使用SSL时,则演变成先和SSL通信,再由SSL和TCP通信了。简言之,所谓HTTPS,其实就是身披SSL协议这层外壳的HTTP。
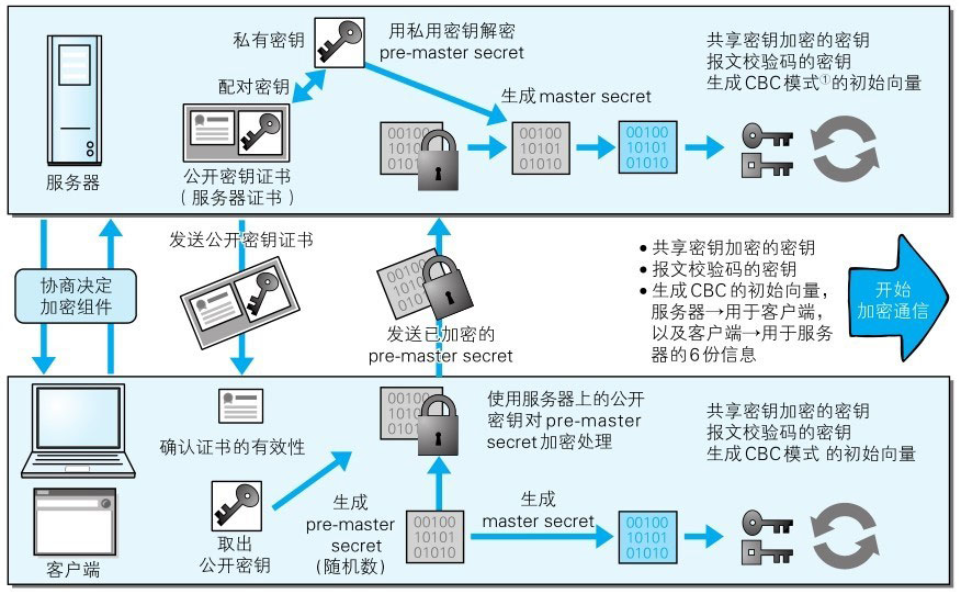
HTTPS采用共享密钥加密和公开密钥加密两者并用的混合加密机制。在交换密钥环节使用公开密钥加密方式,之后的建立通信交换报文阶段则使用共享密钥加密方式。
近代的加密方法中加密算法是公开的,而密钥却是保密的。通过这种方式得以保持加密方法的安全性。
对称加密:加密和解密同用一个密钥的方式称为共享密钥加密(Common key crypto system),也被叫做对称密钥加密。
非对称加密:使用公开密钥加密方式,发送密文的一方使用对方的公开密钥进行加密处理,对方收到被加密的信息后,再使用自己的私有密钥进行解密。
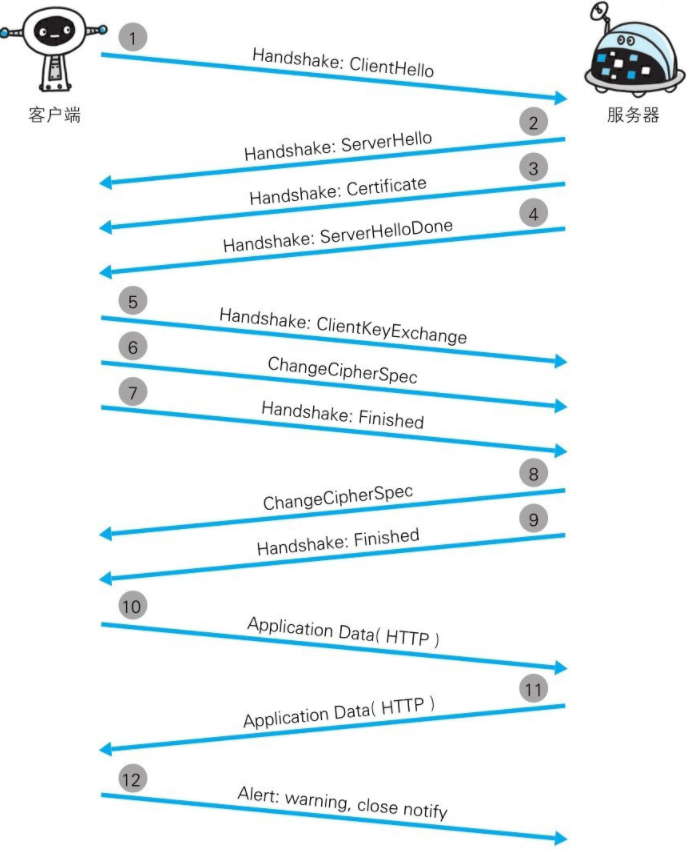
客户端发送Client Hello报文开始TLS通信,报文中包含了客户端支持的TLS版本、加密组件(包含所使用的加密算法和密钥长度等)
当服务器确认可以进行TLS通信时候,以Server Hello报文进行应答,应答报文中同样包含TLS版本和加密组件(从客户端发来的加密组件筛选出来的)
之后服务器发送Certificate报文(包含公开密钥证书)
最后服务器发送Server Hello Done报文通知客户端,最初的TLS握手协商部分结束。
TLS第一次握手结束后,客户端发送Clien Key Exchange报文做应答。报文包含通信加密中使用的一种被称为Pre-master secret的随机密码串,该密码串已经用步骤3中包含的公开密钥进行加密。
客户端紧接着继续发送Change Cipher Spec报文,提示服务器,在此报文之后的通信会使用上文的Pre-master secret密钥加密。
客户端发送 Finished报文,该报文包含连接至今全部保温二的整体校验值。该次握手是否成功,要以服务器是否能够正确解密该报文作为判断标准。
服务器同样发送Change Cipher Spec报文
服务器同样发送Finished报文
服务器和客户端的Finished报文交换完毕之后,TLS连接建立完成。通信收到TLS的保护。从此处开始HTTP通信,发送HTTP请求。
发送HTTP请求。
最后由客户端断开连接,断开连接时发送close_notify报文(图中省略了),在这步之后再发送TCP FIN报文关闭与TCP的通信。
SSL的慢分两种。一种是指通信慢。另一种是指由于大量消耗CPU及内存等资源,导致处理速度变慢。
加密通信会消耗更多的CPU及内存资源。如果每次通信都加密,会消耗相当多的资源,平摊到一台计算机上时,能够处理的请求数量必定也会随之减少。
要进行HTTPS通信,证书是必不可少的。而使用的证书必须向认证机构(CA)购买。证书价格可能会根据不同的认证机构略有不同。通常,一年的授权需要数万日元(现在一万日元大约折合600人民币)。

HTTP/1.1使用的认证方式如下所示。
BASIC认证(基本认证):从HTTP/1.0就定义的认证方式。

BASIC认证使用上不够便捷灵活,且达不到多数Web网站期望的安全性等级,因此它并不常用。
为弥补BASIC认证存在的弱点,从HTTP/1.1起就有了DIGEST认证。DIGEST认证同样使用质询/响应的方式(challenge/response),但不会像BASIC认证那样直接发送明文密码。
质询响应方式:一开始一方会先发送认证要求给另一方,接着使用从另一方那接收到的质询码计算生成响应码。最后将响应码返回给对方进行认证的方式。
DIGEST认证概要

如果用户ID和密码被盗,就很有可能被第三者冒充。利用SSL客户端认证则可以避免该情况的发生。
SSL客户端认证是借由HTTPS的客户端证书完成认证的方式。凭借客户端证书(在HTTPS一章已讲解)认证,服务器可确认访问是否来自已登录的客户端。
SSL客户端认证的认证步骤
接收到需要认证资源的请求,服务器会发送Certificate Request报文,要求客户端提供客户端证书。
用户选择将发送的客户端证书后,客户端会把客户端证书信息以Client Certificate报文方式发送给服务器。
服务器验证客户端证书验证通过后方可领取证书内客户端的公开密钥,然后开始HTTPS加密通信。
在多数情况下,SSL客户端认证不会仅依靠证书完成认证,一般会和基于表单认证(下一个概念)组合形成一种双因素认证(Two-factor authentication)来使用。
双因素认证:认证过程中不仅需要密码这一个因素,还需要申请认证者提供其他持有信息,从而作为另一个因素,与其组合使用的认证方式。
第一个认证因素的SSL客户端证书用来认证客户端计算机,另一个认证因素的密码则用来确定这是用户本人的行为。
客户端会向服务器上的Web应用程序发送登录信息(Credential),按登录信息的验证结果认证。
输入已事先登录的用户ID(通常是任意字符串或邮件地址)和密码等登录信息后,发送给Web应用程序,基于认证结果来决定认证是否成功。
认证多半为基于表单认证由于使用上的便利性及安全性问题,HTTP协议标准提供的BASIC认证和DIGEST认证几乎不怎么使用。另外,SSL客户端认证虽然具有高度的安全等级,但因为导入及维持费用等问题,还尚未普及。
基于表单认证的标准规范尚未有定论,一般会使用Cookie来管理Session(会话)。
鉴于HTTP是无状态协议,之前已认证成功的用户状态无法通过协议层面保存下来。即,无法实现状态管理,因此即使当该用户下一次继续访问,也无法区分他与其他的用户。于是我们会使用Cookie来管理Session,以弥补HTTP协议中不存在的状态管理功能。
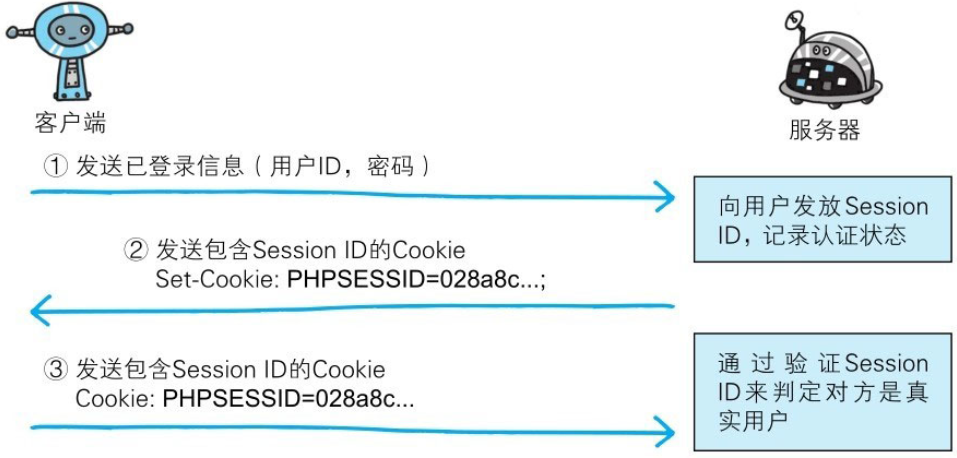
服务器端应如何保存用户提交的密码等登录信息等也没有标准化。
通常,一种安全的保存方法是,先利用给密码加盐(salt)的方式增加额外信息,再使用散列(hash)函数计算出散列值后保存。
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我正在使用Heroku(heroku.com)来部署我的Rails应用程序,并且正在构建一个iPhone客户端来与之交互。我的目的是将手机的唯一设备标识符作为HTTPheader传递给应用程序以进行身份验证。当我在本地测试时,我的header通过得很好,但在Heroku上它似乎去掉了我的自定义header。我用ruby脚本验证:url=URI.parse('http://#{myapp}.heroku.com/')#url=URI.parse('http://localhost:3000/')req=Net::HTTP::Post.new(url.path)#boguspara
我试图在我的网站上实现使用Facebook登录功能,但在尝试从Facebook取回访问token时遇到障碍。这是我的代码:ifparams[:error_reason]=="user_denied"thenflash[:error]="TologinwithFacebook,youmustclick'Allow'toletthesiteaccessyourinformation"redirect_to:loginelsifparams[:code]thentoken_uri=URI.parse("https://graph.facebook.com/oauth/access_token
我是Ruby的新手。我试过查看在线文档,但没有找到任何有效的方法。我想在以下HTTP请求botget_response()和get()中包含一个用户代理。有人可以指出我正确的方向吗?#PreliminarycheckthatProggitisupcheck=Net::HTTP.get_response(URI.parse(proggit_url))ifcheck.code!="200"puts"ErrorcontactingProggit"returnend#Attempttogetthejsonresponse=Net::HTTP.get(URI.parse(proggit_url)
我正在尝试解析网页,但有时会收到404错误。这是我用来获取网页的代码:result=Net::HTTP::getURI.parse(URI.escape(url))如何测试result是否为404错误代码? 最佳答案 像这样重写你的代码:uri=URI.parse(url)result=Net::HTTP.start(uri.host,uri.port){|http|http.get(uri.path)}putsresult.codeputsresult.body这将打印状态码和正文。
我正在安装gitlabhq,并且在Gemfile中有对某些资源的“git://...”的引用。但是,我在公司防火墙后面,所以我必须使用http://。我可以手动编辑Gemfile,但我想知道是否有另一种方法告诉bundler使用http://作为git存储库? 最佳答案 您可以通过运行gitconfig--globalurl."https://".insteadOfgit://或通过将以下内容添加到~/.gitconfig:[url"https://"]insteadOf=git://