Steam是由美国电子游戏商Valve于2003年9月12日推出的数字发行平台,被认为是计算机游戏界最大的数码发行平台之一,Steam平台是全球最大的综合性数字发行平台之一。玩家可以在该平台购买、下载、讨论、上传和分享游戏和软件。

而每周的steam会开启了一轮特惠,可以让游戏打折,而玩家就会购买心仪的游戏
传说每次有大折扣,无数的玩家会去购买游戏,可以让G胖亏死

import random
import time
import requests
import parsel
import csv
模块可以pycharm里直接安装,输入pip install XXX(模块名)就行
url = f'https://store.steampowered.com/contenthub/querypaginated/specials/TopSellers/render/?query=&start=1&count=15&cc=TW&l=schinese&v=4&tag='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
html_data = response.json()['results_html']
print(html_data)
这样网页源代码就获取到了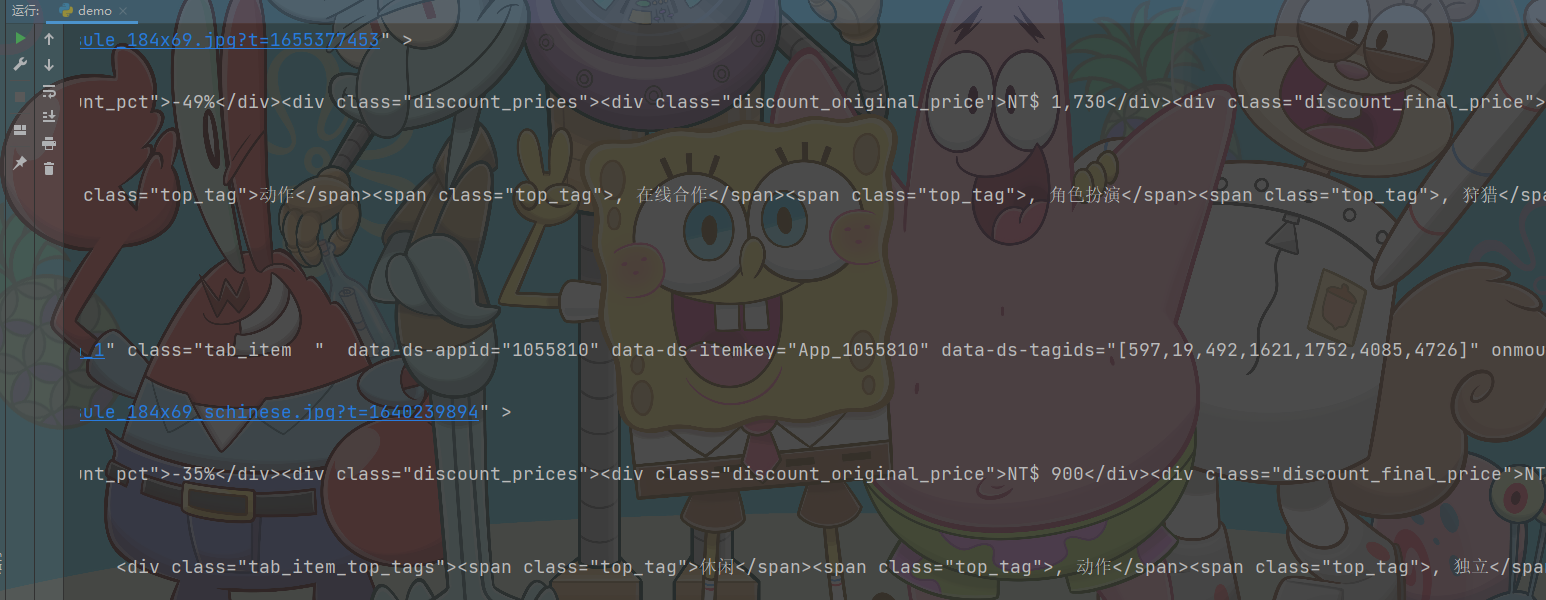
selector = parsel.Selector(html_data)
lis = selector.css('a.tab_item')
for li in lis:
href = li.css('::attr(href)').get()
title = li.css('.tab_item_name::text').get()
tag_list = li.css('.tab_item_top_tags .top_tag::text').getall()
tag = ''.join(tag_list)
price = li.css('.discount_original_price::text').get()
price_1 = li.css('.tab_item_discount .discount_final_price::text').get()
discount = li.css('.tab_item_discount .discount_pct::text').get()
print(title, tag, price, price_1, discount, href)
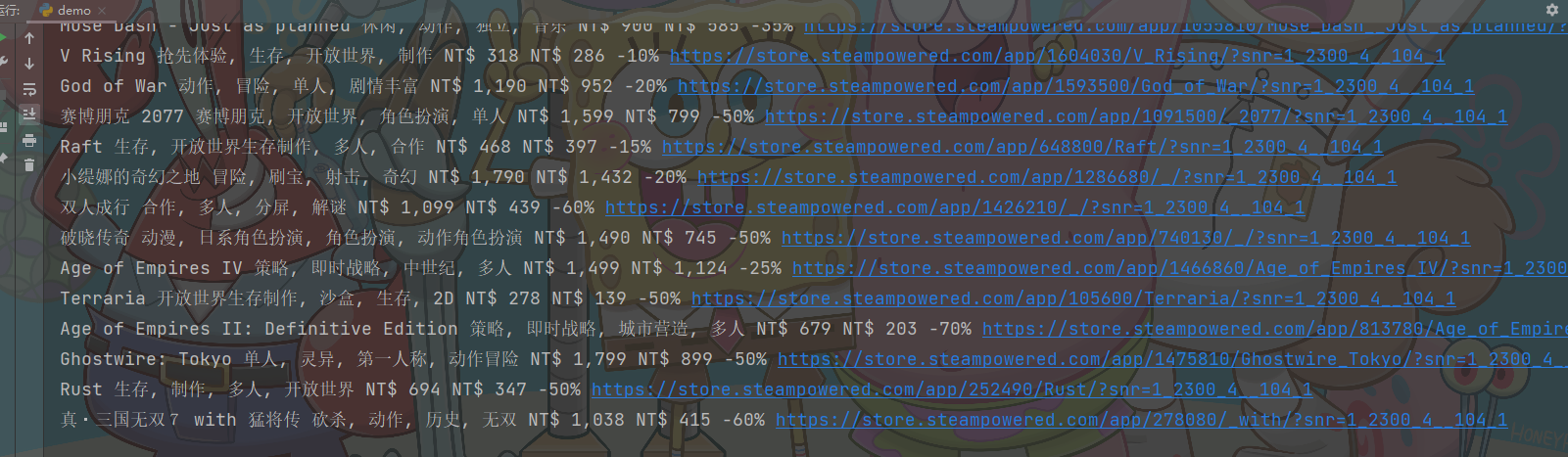
先把数据保存进字典里面
dit = {
'游戏': title,
'标签': tag,
'原价': price,
'售价': price_1,
'折扣': discount,
'详情页': href,
}
csv_writer.writerow(dit)
最后保存到csv里
f = open('游戏_1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'游戏',
'标签',
'原价',
'售价',
'折扣',
'详情页',
])
csv_writer.writeheader()
Steam是由美国电子游戏商Valve于2003年9月12日推出的数字发行平台,被认为是计算机游戏界最大的数码发行平台之一,Steam平台是全球最大的综合性数字发行平台之一。玩家可以在该平台购买、下载、讨论、上传和分享游戏和软件。

而每周的steam会开启了一轮特惠,可以让游戏打折,而玩家就会购买心仪的游戏

传说每次有大折扣,无数的玩家会去购买游戏,可以让G胖亏死

import random
import time
import requests
import parsel
import csv
模块可以pycharm里直接安装,输入pip install XXX(模块名)就行

url = f'https://store.steampowered.com/contenthub/querypaginated/specials/TopSellers/render/?query=&start=1&count=15&cc=TW&l=schinese&v=4&tag='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
html_data = response.json()['results_html']
print(html_data)
这样网页源代码就获取到了

selector = parsel.Selector(html_data)
lis = selector.css('a.tab_item')
for li in lis:
href = li.css('::attr(href)').get()
title = li.css('.tab_item_name::text').get()
tag_list = li.css('.tab_item_top_tags .top_tag::text').getall()
tag = ''.join(tag_list)
price = li.css('.discount_original_price::text').get()
price_1 = li.css('.tab_item_discount .discount_final_price::text').get()
discount = li.css('.tab_item_discount .discount_pct::text').get()
print(title, tag, price, price_1, discount, href)

先把数据保存进字典里面
dit = {
'游戏': title,
'标签': tag,
'原价': price,
'售价': price_1,
'折扣': discount,
'详情页': href,
}
csv_writer.writerow(dit)
最后保存到csv里
f = open('游戏_1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'游戏',
'标签',
'原价',
'售价',
'折扣',
'详情页',
])
csv_writer.writeheader()

关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。