一、虚拟机安装CentOS7并配置共享文件夹
二、CentOS 7 上hadoop伪分布式搭建全流程完整教程
三、本机使用python操作hdfs搭建及常见问题
四、mapreduce搭建
五、mapper-reducer编程搭建
六、hive数据仓库安装
CentOS 7 上进行hadoop伪分布式搭建
yum -y install gcc* readline* python-devel cmake net-tools psmisc vim* bash-completion.noarch lrzsz
出现报错:
gcc-go-4.8.5-44.el7.x86_64.rpm FAILED
http://mirrors.aliyun.com/centos/7.9.2009/os/x86_64/Packages/gcc-go-4.8.5-44.el7.x86_64.rpm: [Errno 12] Timeout on http://mirrors.aliyun.com/centos/7.9.2009/os/x86_64/Packages/gcc-go-4.8.5-44.el7.x86_64.rpm: (28, 'Operation too slow. Less than 1000 bytes/sec transferred the last 30 seconds')
正在尝试其它镜像。
gcc-go-4.8.5-44.el7.x86_64.rpm FAILED
http://mirrors.bfsu.edu.cn/centos/7.9.2009/os/x86_64/Packages/gcc-go-4.8.5-44.el7.x86_64.rpm: [Errno -1] 软件包与预期下载的不符。建议:运行 yum --enablerepo=base clean metadata
按照提示执行
yum --enablerepo=base clean metadata
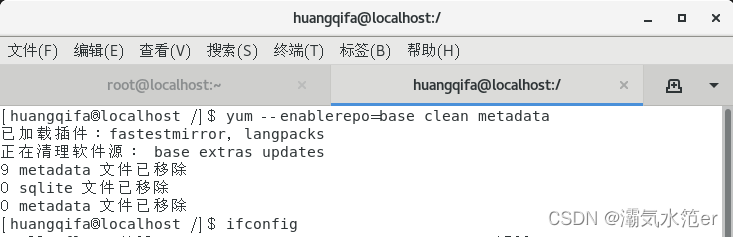
再次执行
yum -y install gcc* readline* python-devel cmake net-tools psmisc vim* bash-completion.noarch lrzsz
成功
参考:https://blog.csdn.net/hanwenshan123/article/details/78717782
对问题2、问题3进行配置
进行完之后
查看50070进程是否存在
ps -aux |grep 50070
确保存在50070进程
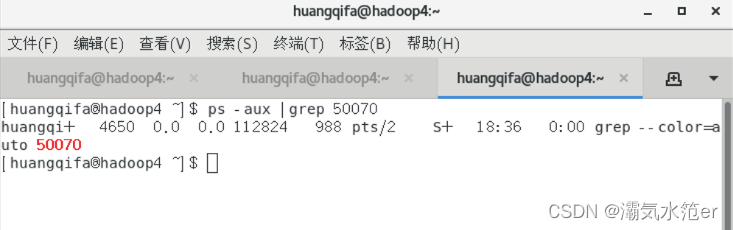
hostnamectl set-hostname hadoop4
查看当前ip
ifconfig

sudo gedit /etc/hosts
在文件末尾添加:
192.168.137.134 hadoop4
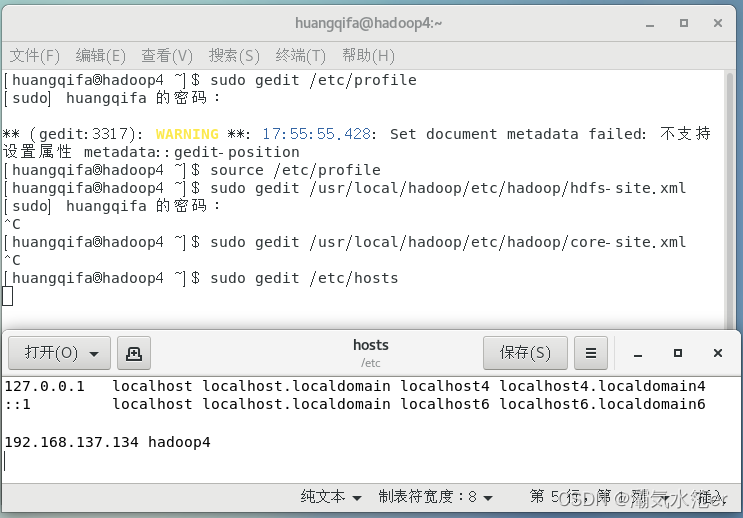
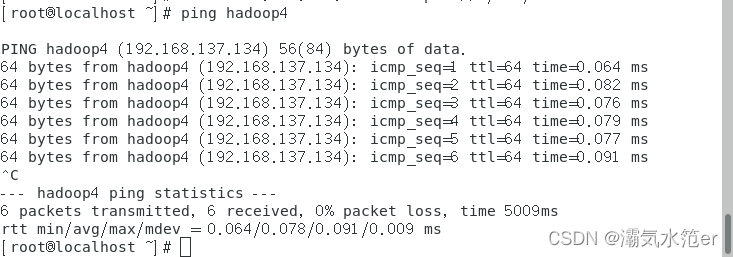
测试是否可以连通
ping hadoop4
网盘链接:https://pan.baidu.com/s/1bXLZ20yr8egVmLEwYBSLMA
提取码:hl99
cd +filepath
sudo tar -zxf jdk-8u212-linux-x64.tar.gz -C /usr/local/
sudo mv /usr/local/jdk1.8.0_212/ /usr/local/java
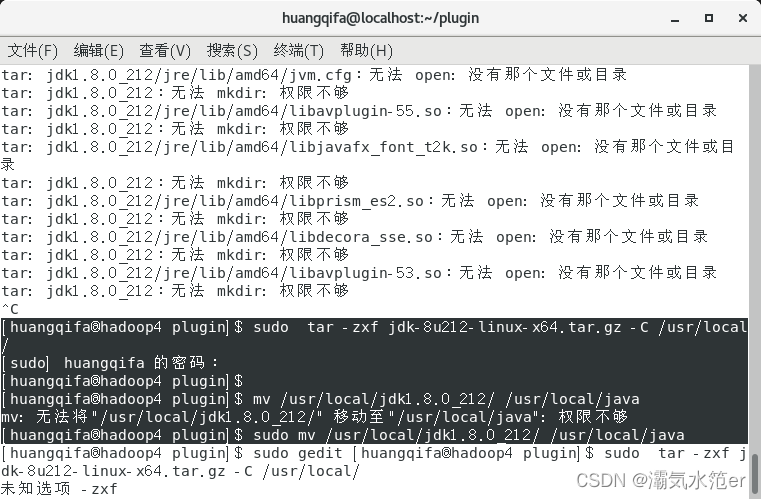
sudo gedit /etc/profile
在文件末尾添加
export JAVA_HOME=/usr/local/java
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

保存,退出
刷新/etc/profile
source /etc/profile

java -version

网盘链接:https://pan.baidu.com/s/1o826SqMe3PnnoO8fVUwCfw
提取码:hl99
cd +filepath
sudo tar -zxf hadoop-2.7.7.tar.gz -C /usr/local/
sudo mv /usr/local/hadoop-2.7.7/ /usr/local/hadoop
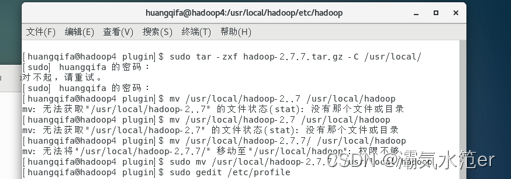
sudo gedit /etc/profile
文件末尾添加:
export PATH=$JAVA_HOME/bin:$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin

刷新
source /etc/profile
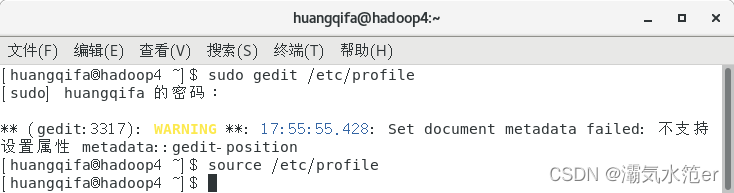
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
添加
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop4:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/huangqifa/data/hadoop/tmp</value>
</property>
</configuration>
如图:

sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
添加
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/huangqifa/data/hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/huangqifa/data/hadoop/datanode</value>
</property>
</configuration>
如图
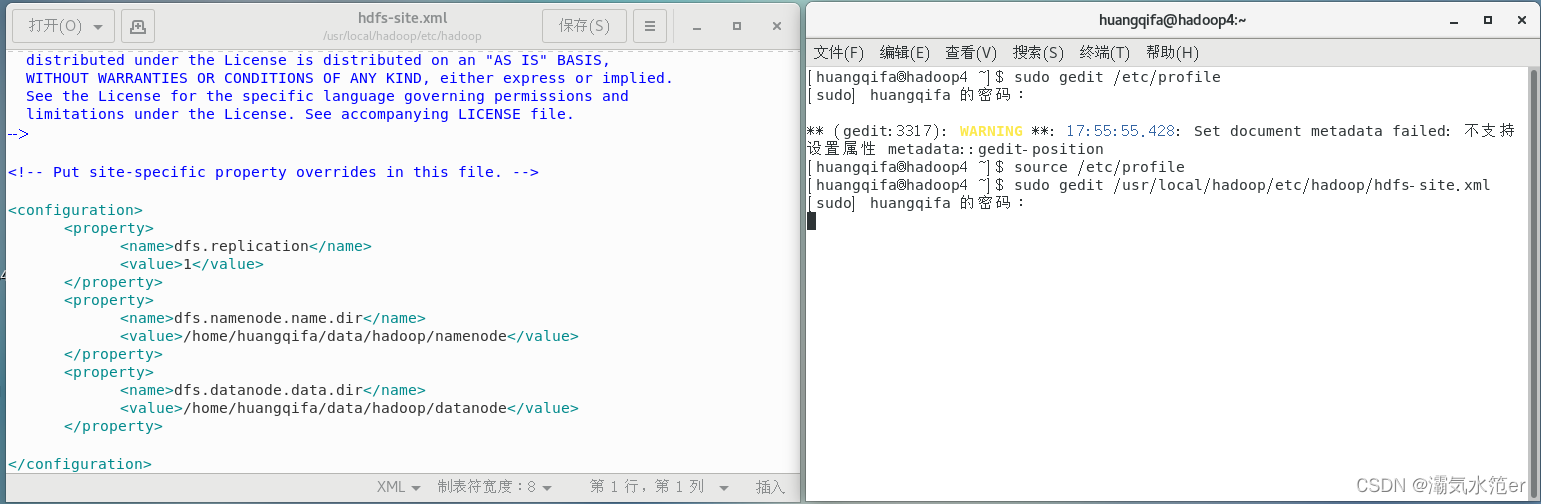
core-site.xml、hdfs-site.xml中所涉及的文件夹不用创建,执行后面的命令时会自动创建
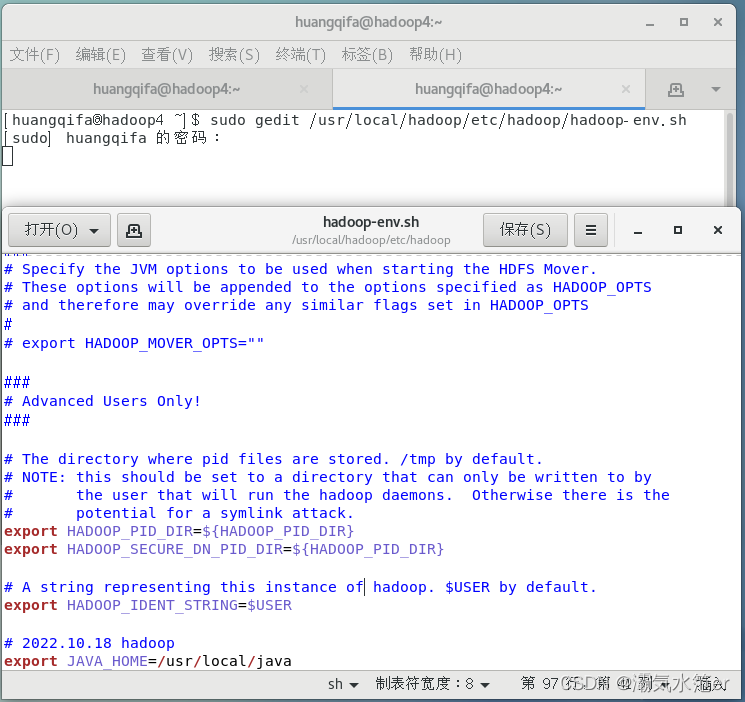
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
文档末尾添加
export JAVA_HOME=/usr/local/java
hadoop namenode -format
sh /usr/local/hadoop/sbin/start-all.sh
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
出现错误的话,可以去找对应的log文件
jps

浏览器访问
192.168.137.134:50070
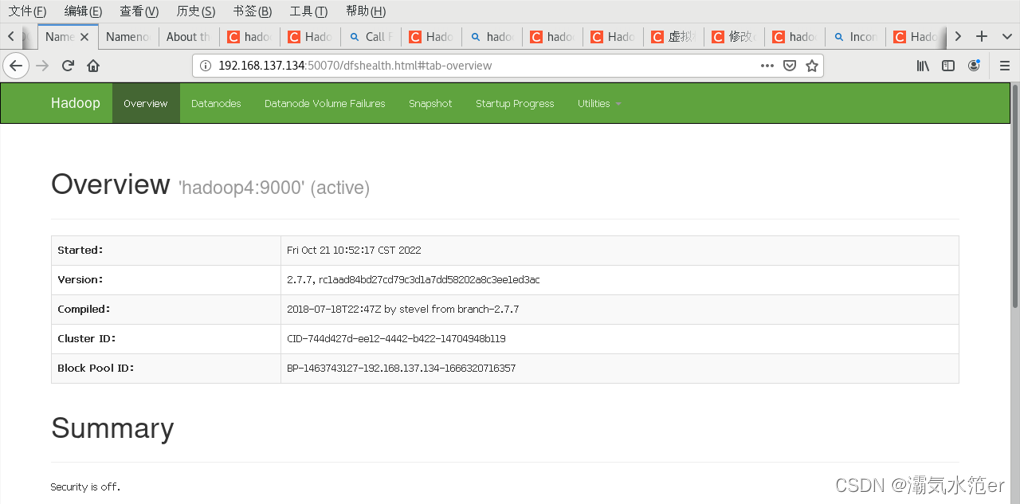
hadoop4:50070
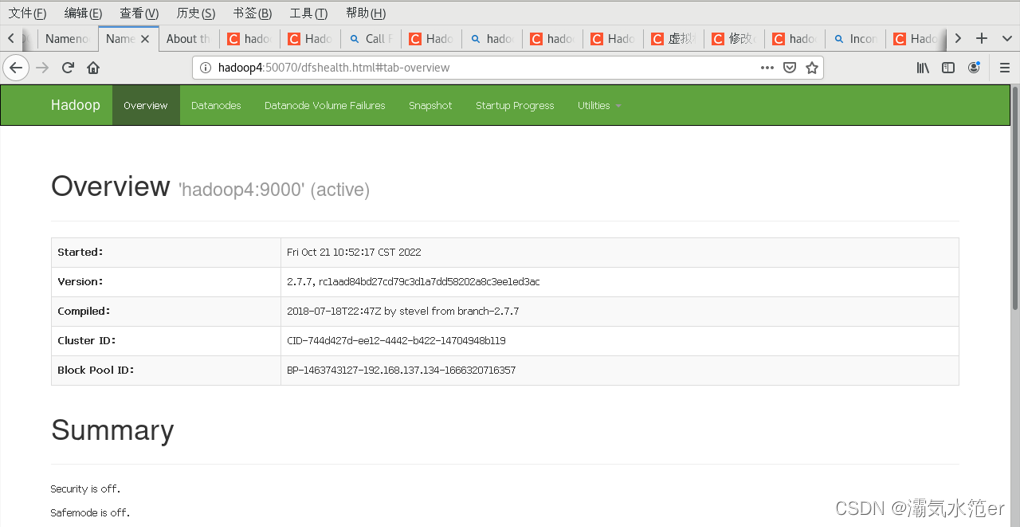
192.168.137.134:8088
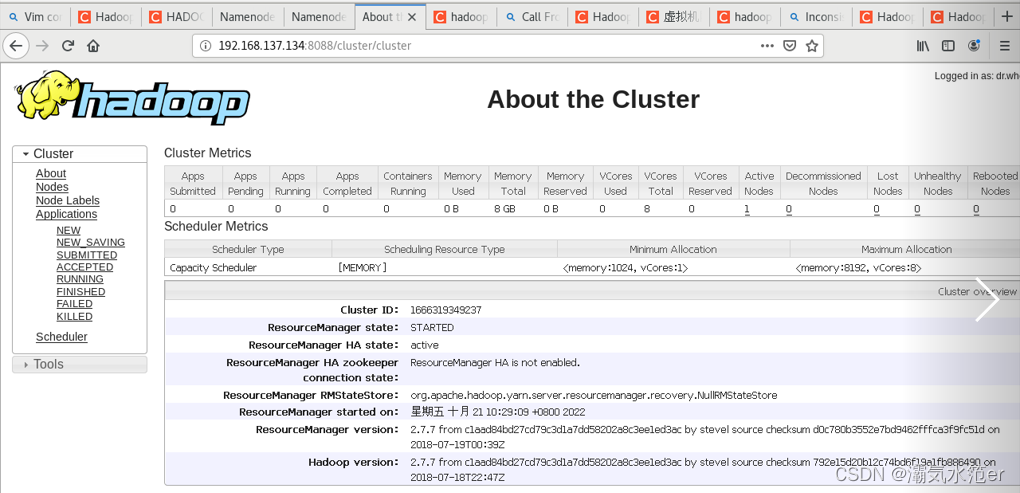
每次重启需要删除/home/huangqifa/data(core-site.xml、hdfs-site.xml中的存储路径)文件夹,然后将以上1-4再重新做一遍才可以访问
注:以上配置可能会导致此问题,不过依然可以正常联网,毫无影响。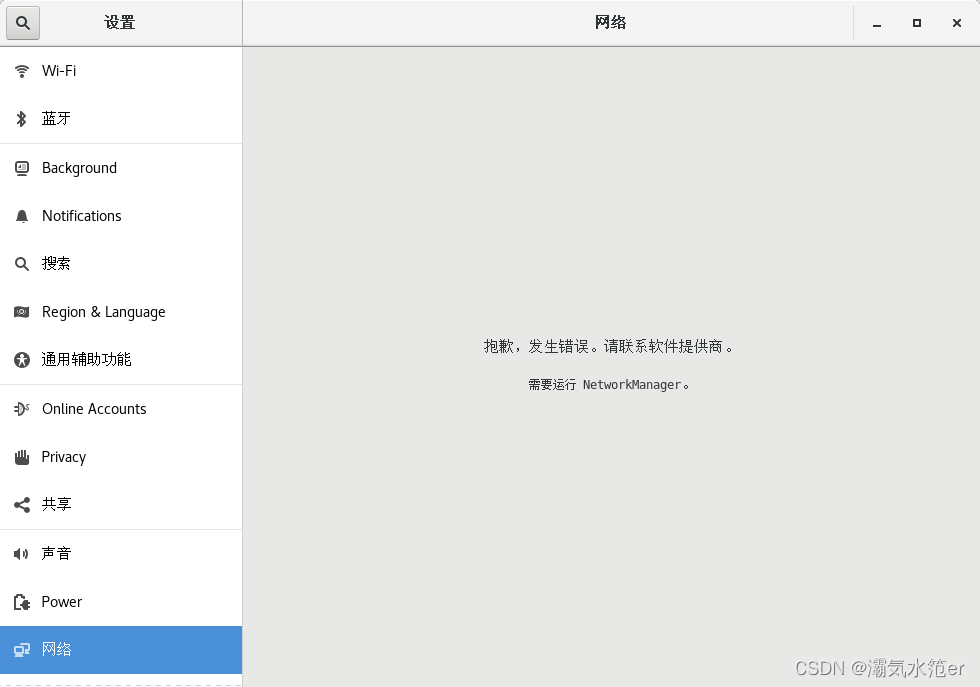 解决:systemctl start NetworkManager.service ,但之后ip就变了,原因未知,好在每次重启又自动复原,原因未知。
解决:systemctl start NetworkManager.service ,但之后ip就变了,原因未知,好在每次重启又自动复原,原因未知。
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我是Ruby新手,并被要求在我们的新项目中使用它。我们还被要求使用Padrino(Sinatra)作为后端/框架。我们被要求使用Rspec进行测试。我一直在寻找可以指导在Padrino上使用RspecforRuby的教程。我得到的主要是引用RoR。但是,我需要RubyonPadrino。请在任何入门/指南/引用/讨论等方面指导我。如有不妥之处请指正。可能是我没有针对我的问题搜索正确的词/短语组合。我正在使用Ruby1.9.3和Padrinov.0.10.6。注意:我还提到了SOquestion,但它没有帮助。 最佳答案 我没用过Pa
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:FlashMessagesinPartials(Rails3)我正在做MichaelHartl的Railstutorial和listing7.26将flash消息添加到应用程序布局:...">...这很好用。但是,我试图通过在我的部分文件夹中创建一个_flash.html.erb来清理这段代码...">-->...并且比使用......在我的应用程序布局中,我的所有Rspec测试开始失败,每个测试都显示以下消息:Failure/Error:before{visitsignup_path}ActionView:
在我的应用程序中我有classUserincludeUser::FooendUser::Foo定义在app/models/user/foo.rb现在我正在使用一个定义了自己的Foo类的库。我收到此错误:warning:toplevelconstantFooreferencedbyUser::FooUser仅引用具有完整路径的Foo,User::Foo,而Foo实际上从来没有指的是Foo。这是怎么回事?更新:才想起我之前遇到过同样的问题,在问题1中看到这里:HowdoIrefertoasubmodule's"fullpath"inruby? 最佳答案