RabbitMQ的Cluster模式分为两种
普通集群模式,就是将 RabbitMQ 部署到多台服务器上,每个服务器启动一个 RabbitMQ 实例,多个实例之间进行消息通信。
此时我们创建的队列 Queue,它的元数据(主要就是 Queue 的一些配置信息)会在所有的 RabbitMQ 实例中进行同步,但是队列中的消息只会存在于一个 RabbitMQ 实例上,而不会同步到其他队列。
当我们消费消息的时候,如果连接到了另外一个实例,那么那个实例会通过元数据定位到 Queue 所在的位置,然后访问 Queue 所在的实例,拉取数据过来发送给消费者。
这种集群可以提高 RabbitMQ 的消息吞吐能力,但是无法保证高可用,因为一旦一个 RabbitMQ 实例挂了,消息就没法访问了,如果消息队列做了持久化,那么等 RabbitMQ 实例恢复后,就可以继续访问了;如果消息队列没做持久化,那么消息就丢了。
大致的流程图如下图:
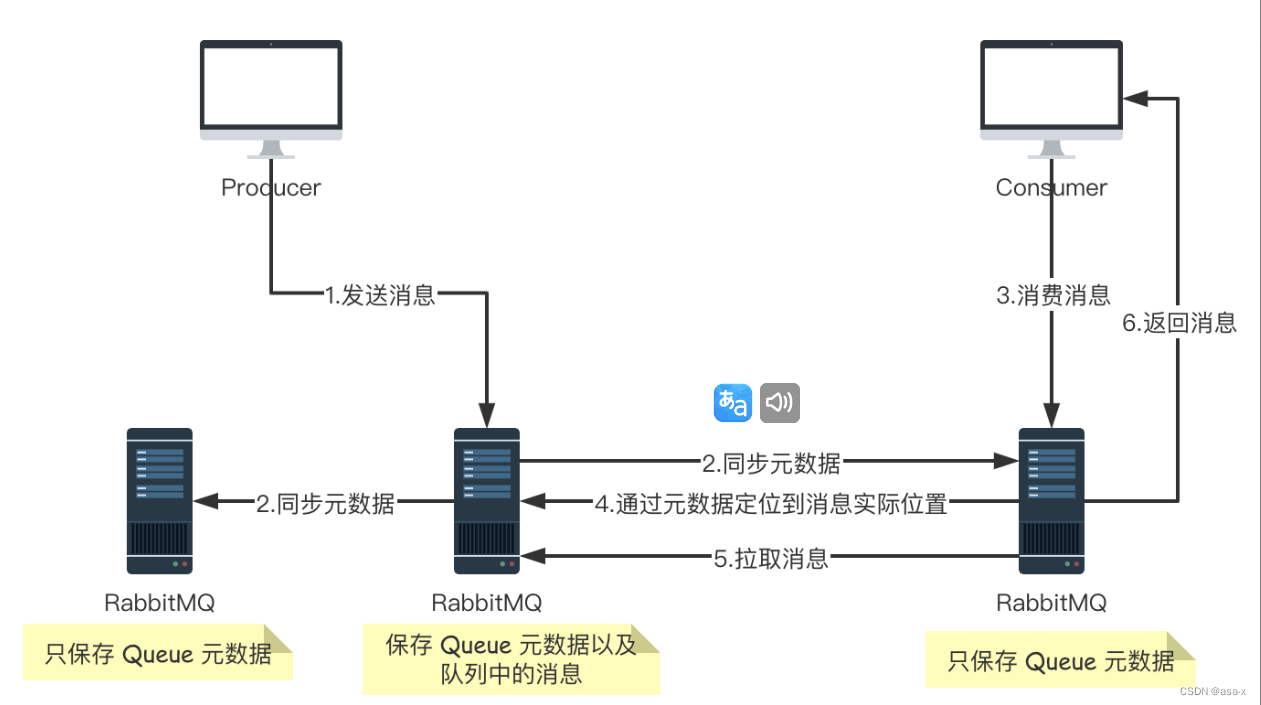
*我们会发现,其实队列的数据只是保存了一份,其他的broker只是保留了元数据而已,用来访问交换机,binding或者队列的基本信息(比如地址啥的)
元数据包含以下内容:
RabbitMQ 中的节点类型有两种:
RabbitMQ 要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。为了确保集群信息的可靠性,或者在不确定使用磁盘节点还是内存节点的时候,建议直接用磁盘节点。
我们会发现,在这汇总集群方式中的情形下,我们会遇到如下几个问题
分别访问他们的ui管理界面
http://localhost:15673/#/
http://localhost:15674/#/
http://localhost:15675/#/
界面应当如下,节点名称应当会变,但是应当可以访问
关闭rabbitmq node 2,3,让他们加入rabbit1集群
如果是通过rabbitmq-server方式启动的,直接关闭运行界面就可以了,如果是通过rabbitmq-server -detached的话,执行
D:\tools\RabbitMQ Server\rabbitmq_server-3.8.4-2\sbin>rabbitmqctl stop_app
Stopping rabbit application on node rabbit2@DESKTOP-IB5K0.. ... //成功关闭提示
ok,那我们正式开始,关闭所有的节点(命令基于powershell)

打开 http://localhost:15673/#/ 查看信息
.\rabbitmqctl.bat join_cluster rabbit1
出现如下提示,
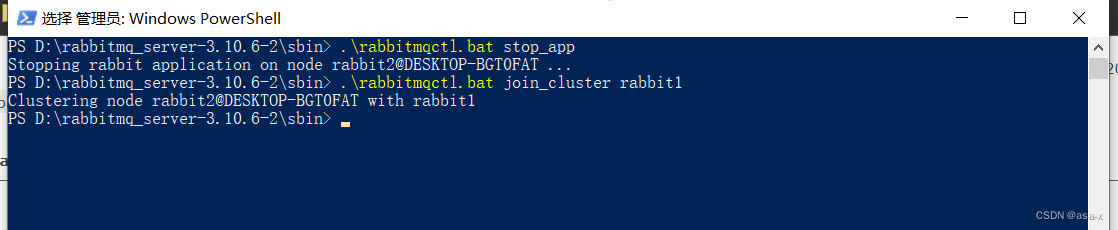
我们查看http://localhost:15673/#/,
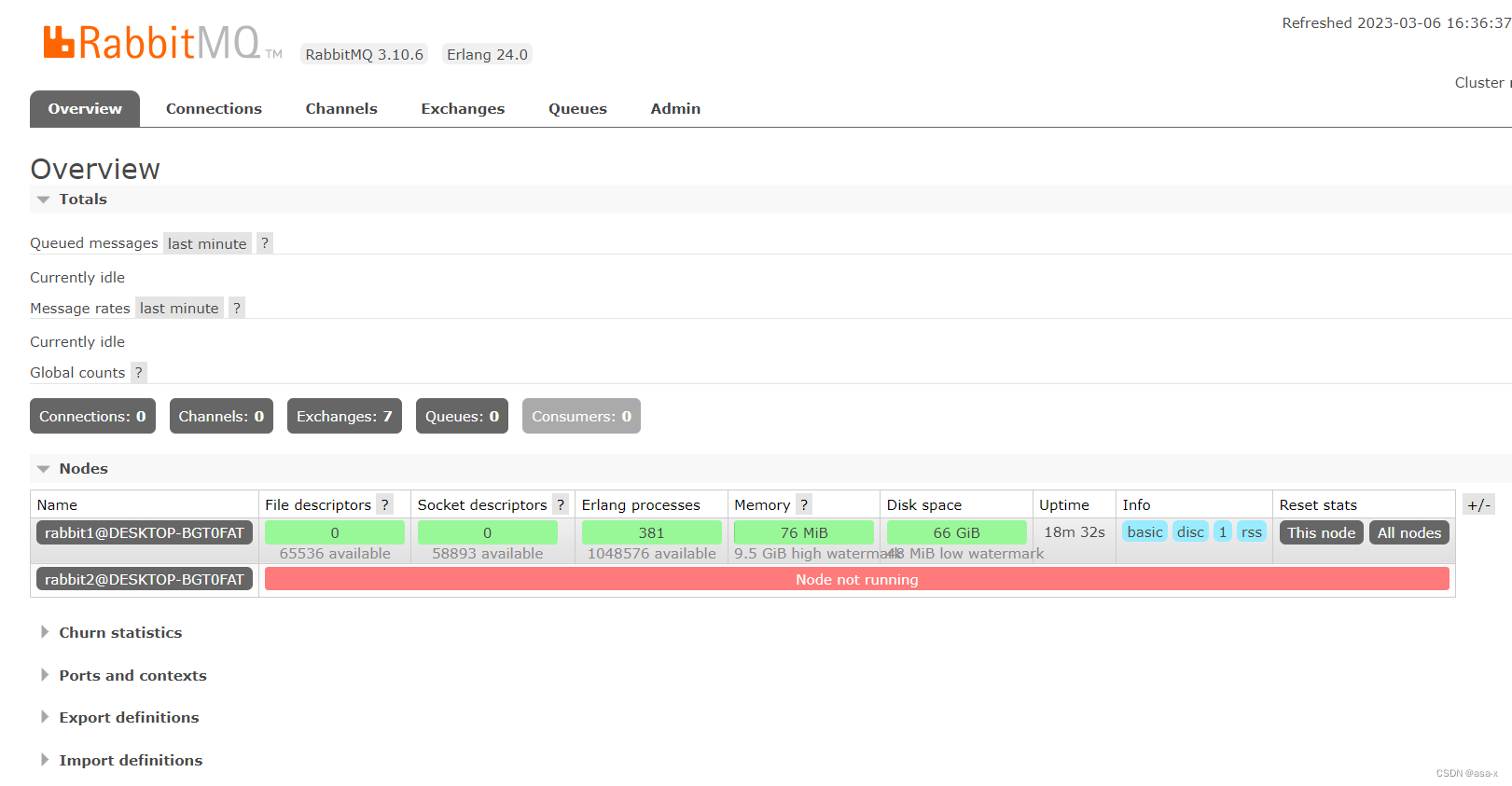
rabbit2节点没有启动,但是加进来了。
在D:\rabbitmq_server-3.10.6-2\sbin 下执行如下命令
rabbitmqctl start_app
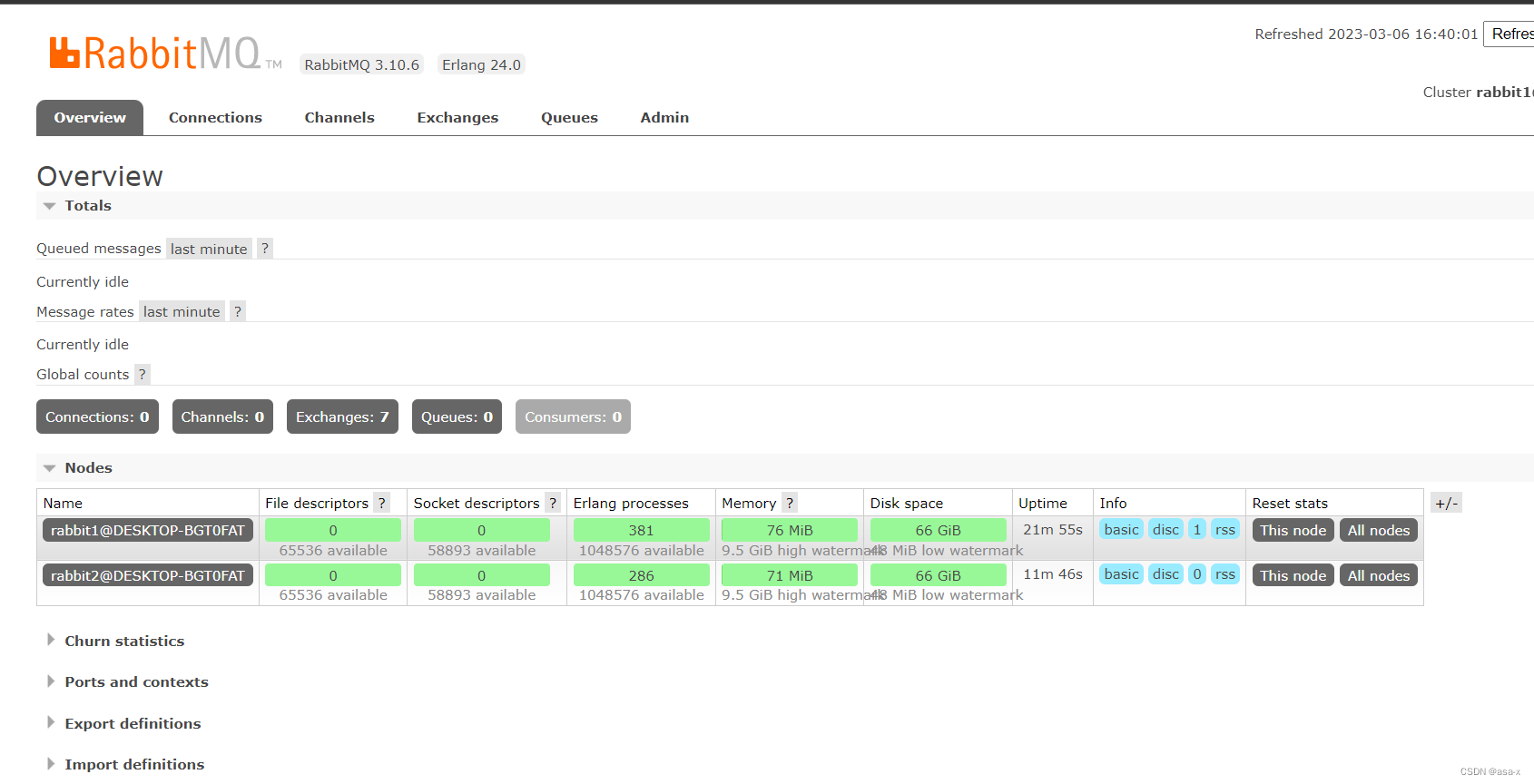
rabbit2节点启动了
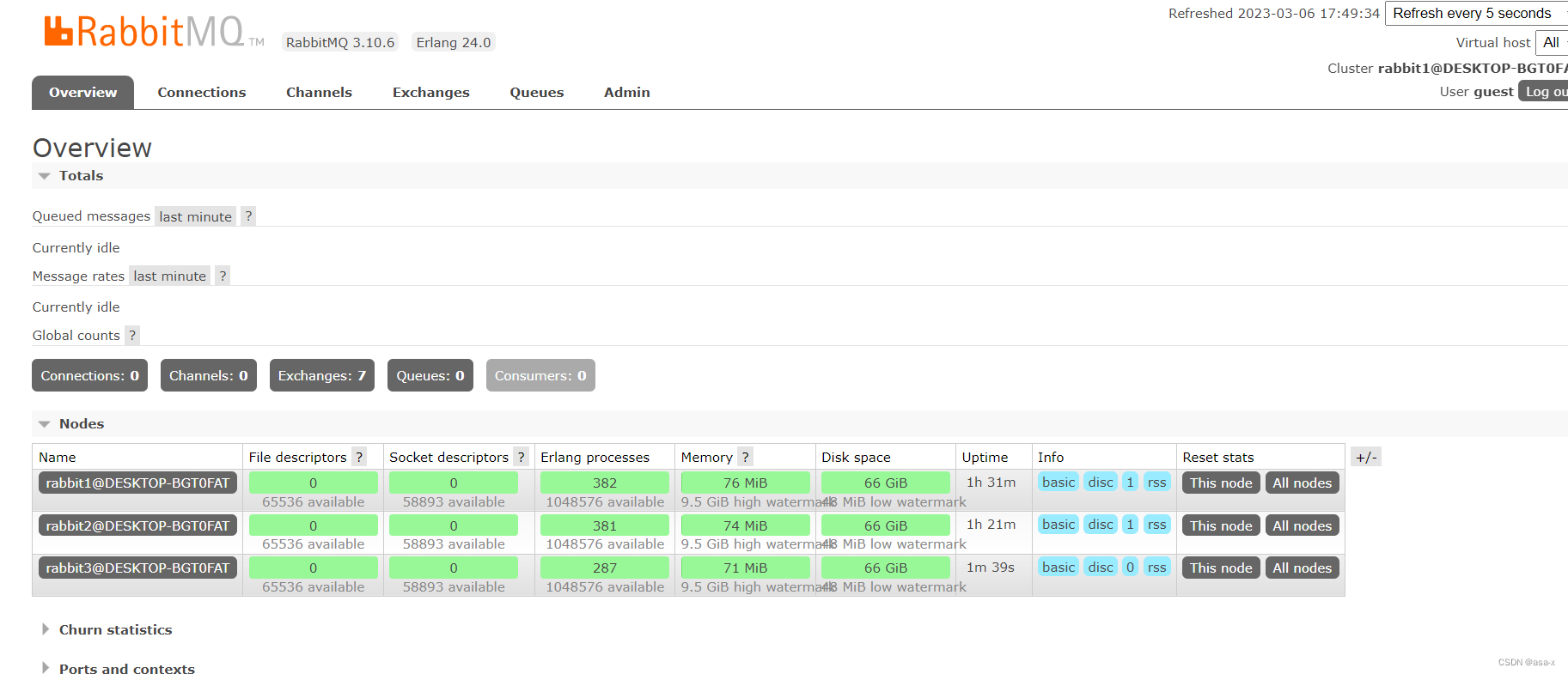
同理,注册rabbit3到集群中,并且启动
可以在ui中查看到注册进来了
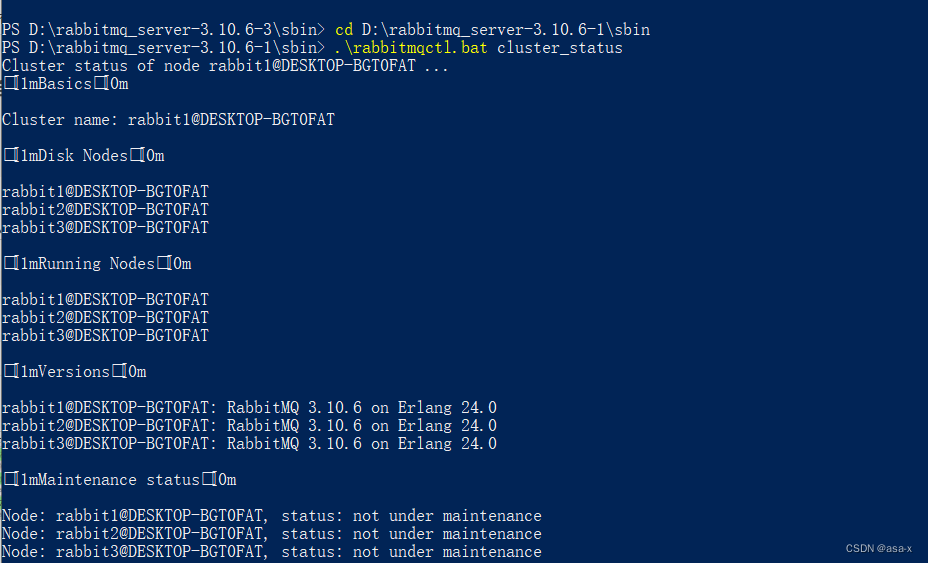
我们切换到server-1下执行命令
.\rabbitmqctl.bat cluster_status
可以查看各种节点的信息
假如我们需要结束节点3,那么在对应的目录下,执行命令如下


我们发现无论是访问下面的那个界面,都是出现了集群的信息的
http://localhost:15673/#/
http://localhost:15674/#/
http://localhost:15675/#/
前文请参考:spring-boot rabbitmq整合
如果publish指定集群的某个节点,其他的节点也是可以访问这个message的,除非该节点宕机了。
测试
搭建好集群后,我们需要做个测试,我们发送一个mq消息,会发现三个节点都有这个消息,我们修改配置把publish的broker节点设置为5673,而不是address设置集群地址
spring:
rabbitmq:
host: 0.0.0.0
port: 5673
username: root
password: root
publisher-confirms: true #确认消息已发送到交换机(Exchange)
publisher-returns: true #确认消息已发送到队列(Queue)
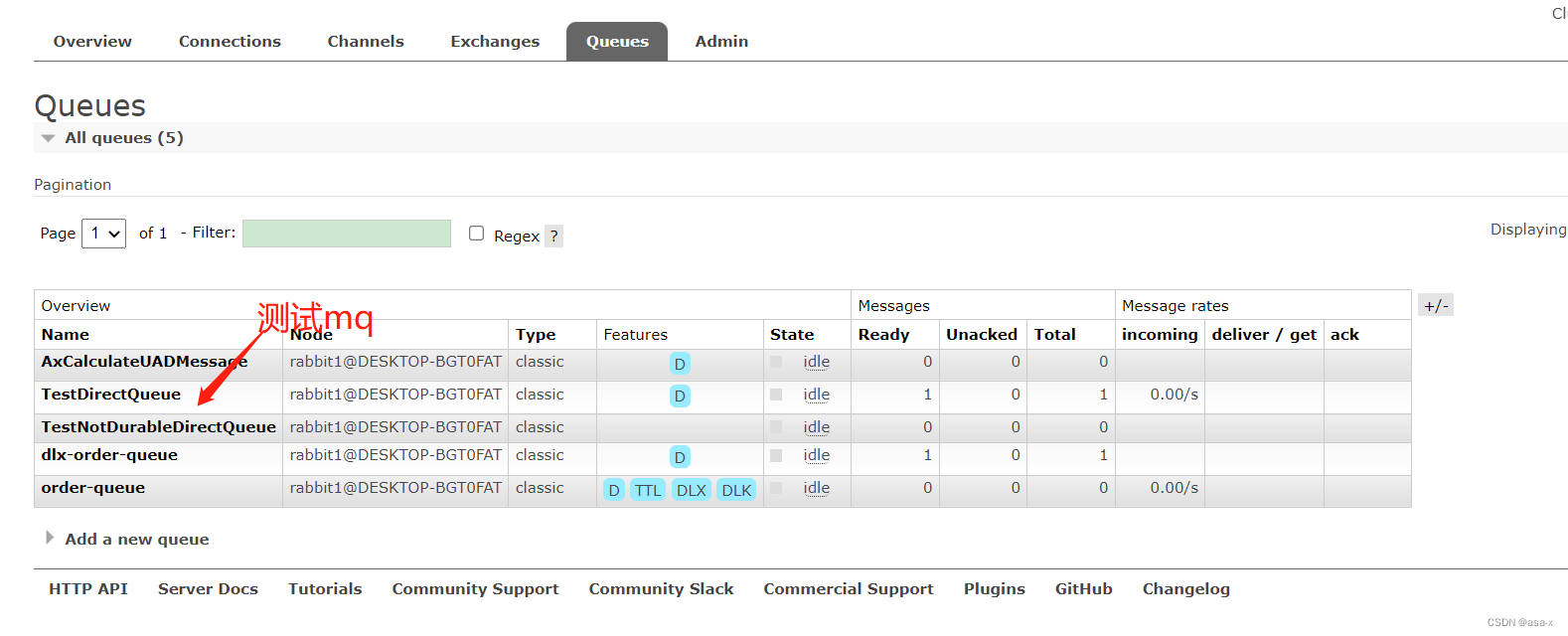
如果root没有权限,请改成guest/guest都行,我们发送了一个名为TestDirectQueue的队列,我们去
http://localhost:15673/#/queues
http://localhost:15674/#/queues
http://localhost:15675/#/queues
看,我们会发现都有未消费的的message
修改consumer配置为:
spring:
rabbitmq:
host: 0.0.0.0
port: 5674
username: root
password: root
virtual-host: pers-xrb
listener:
direct:
retry:
max-attempts: 3
simple:
retry:
max-attempts: 3
acknowledge-mode: manual
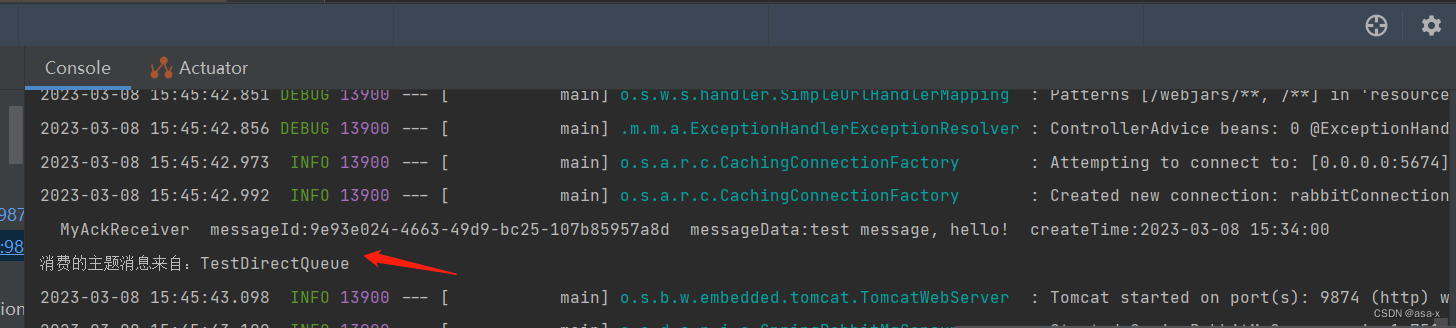
启动consumer项目,我们可以发现,message被消费完了
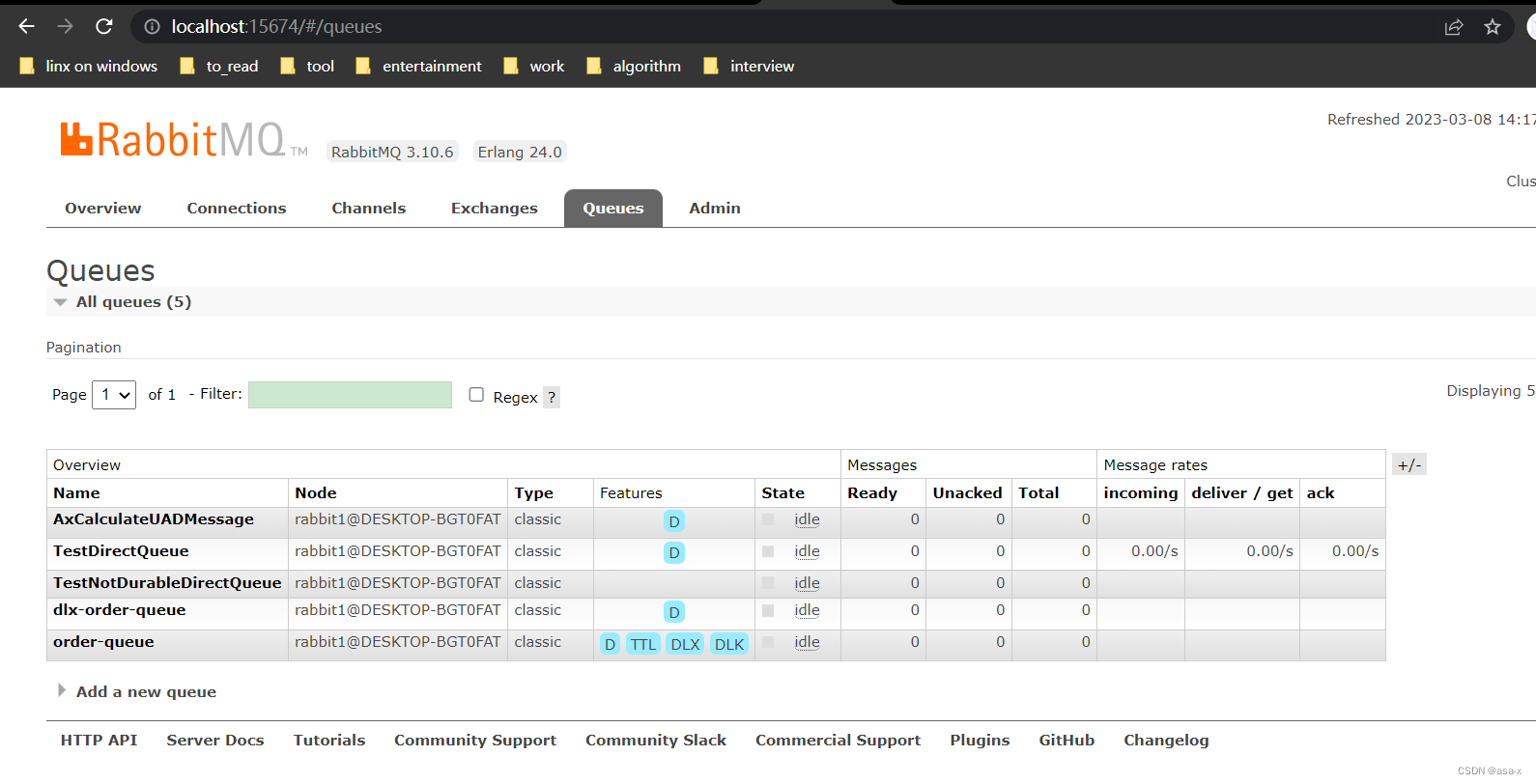
总结
我们可以大胆的猜测,保留队列信息的消息在节点1,rabbit1上的,但是集群中的其他节点也是可以消费的。如果节点1的消费者很慢的话,多几个节点也是可以的。但是如果rabbit1节点宕机了,理论上是其他节点应该是消费不了的了。
如果保存queue 消息队列的节点宕机了的话,那么就会发现,其他节点没有节点信息了,我们发送一个mq后,再执行命令,停止rabbit1
.\rabbitmqctl.bat stop_app
在访问 http://localhost:15674/#/ 或者http://localhost:15675/#/ 我们会发现节点 rabbit1停止了,我们再看queue的消息
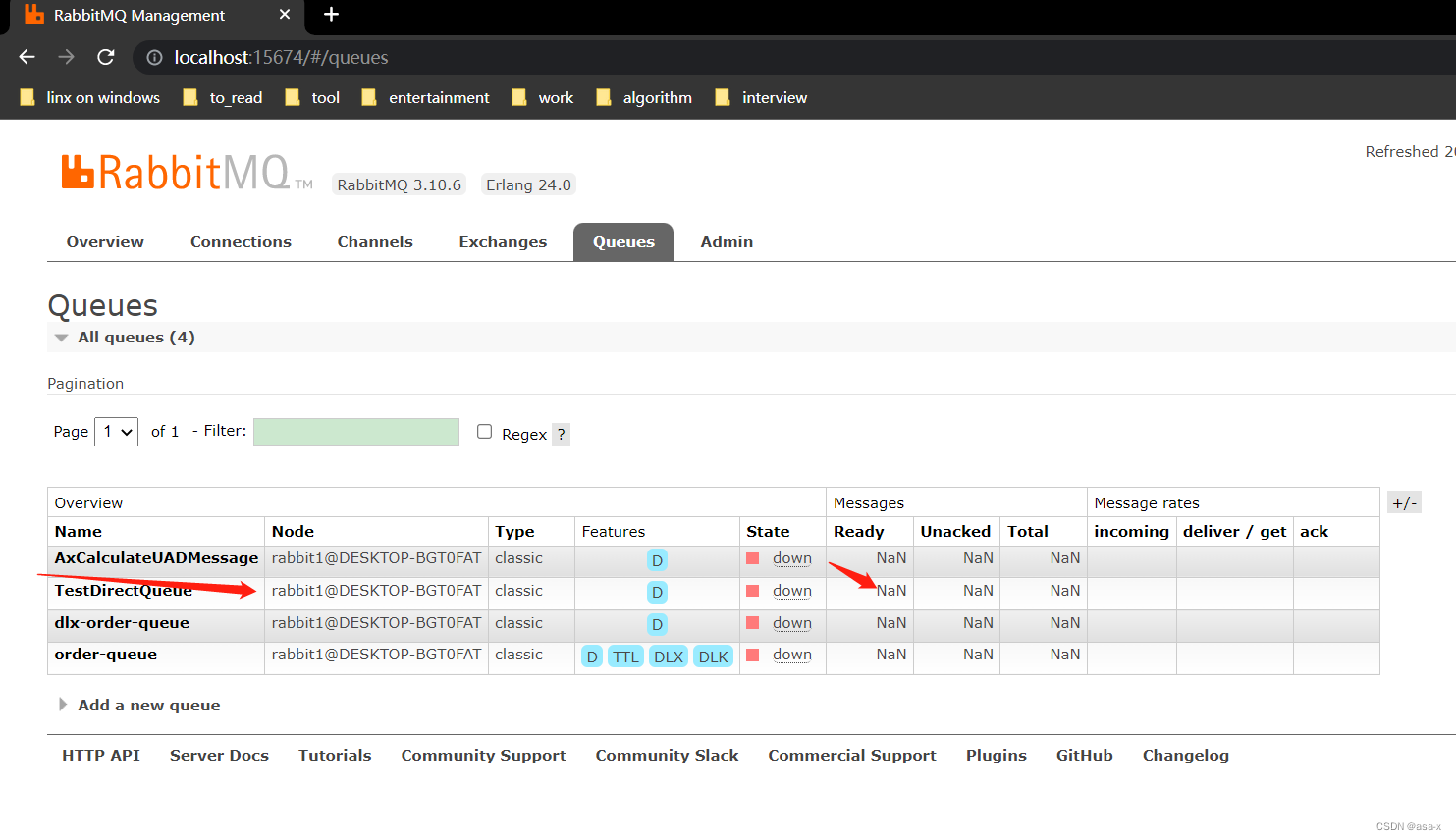
无法获取对应的消息了,启动消费者会报错
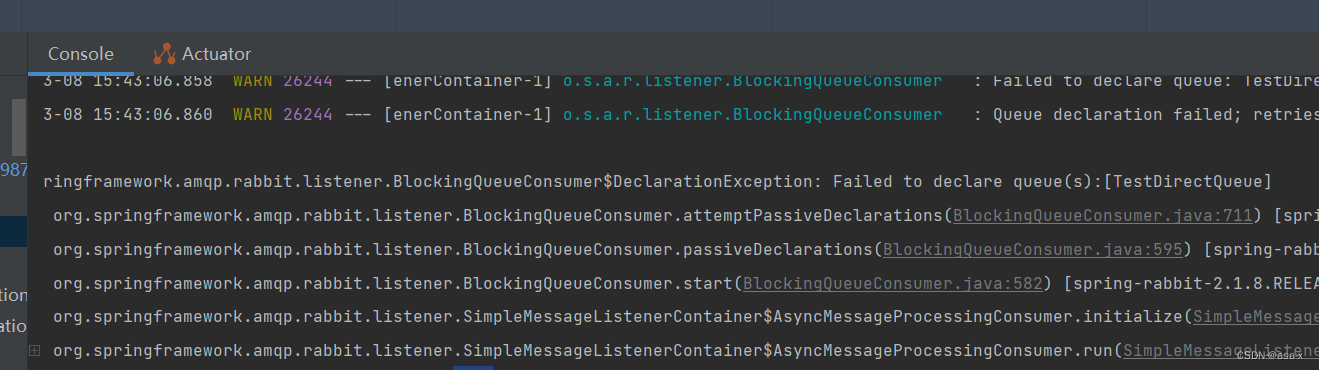
我们执行命令,重启节点rabbit1
.\rabbitmqctl.bat start_app
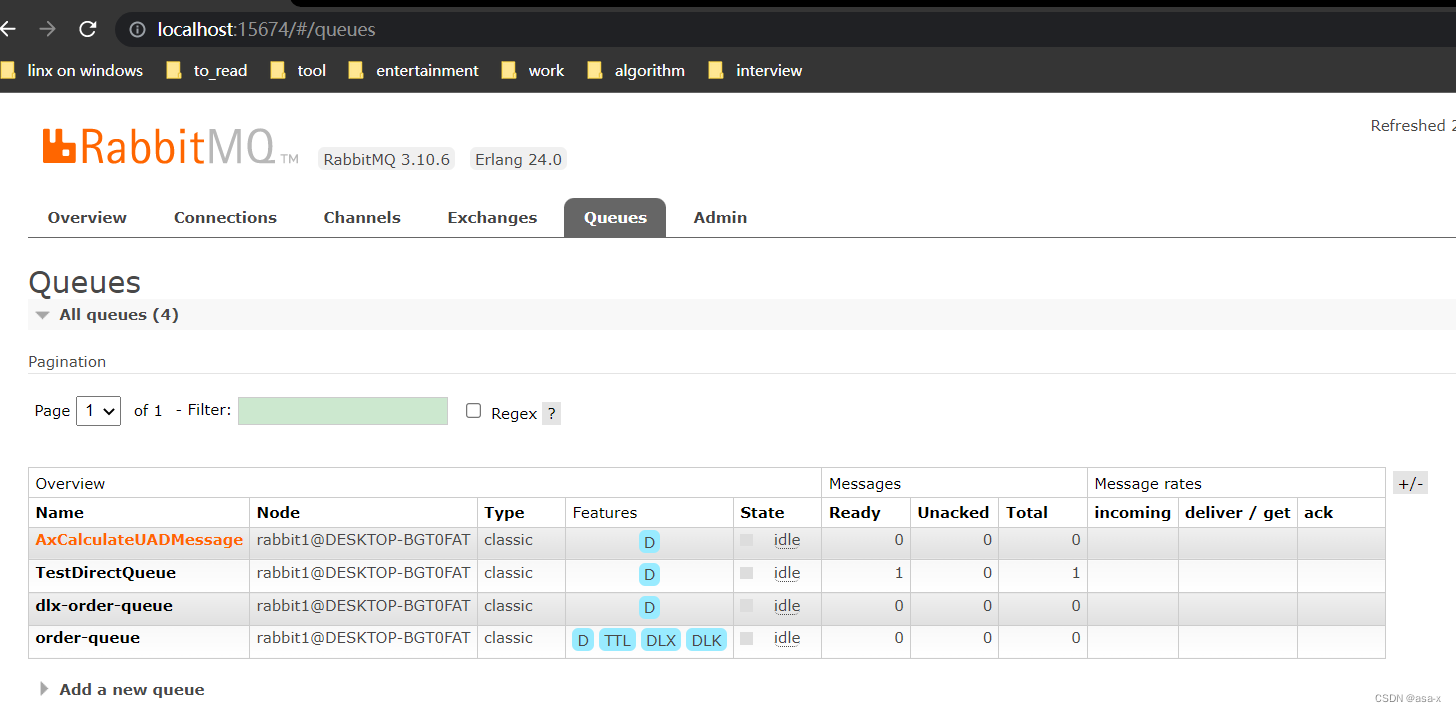
message又可见了,我们再重启消费者,消费成功
参考 3. spring boot + rabbitmq集群(单节点配置) 只需要修改配置文件就可以了。
通常来说,配置rabbitmq的集群应该如下配置,在address中配置多个地址,通过都好分割
spring:
rabbitmq:
username: root
password: root
publisher-confirms: true #确认消息已发送到交换机(Exchange)
publisher-returns: true #确认消息已发送到队列(Queue)
addresses: 0.0.0.0:5674,0.0.0.0:5673,0.0.0.0:5675
listener:
simple:
acknowledge-mode: manual
代码地址: https://github.com/GitHubsteven/spring-in-action2.0/tree/master/spring-boot-mesage
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
这应该是一个简单的问题,但我找不到任何相关信息。给定一个Ruby中的正则表达式,对于每个匹配项,我需要检索匹配的模式$1、$2,但我还需要匹配位置。我知道=~运算符为我提供了第一个匹配项的位置,而string.scan(/regex/)为我提供了所有匹配模式。如果可能,我需要在同一步骤中获得两个结果。 最佳答案 MatchDatastring.scan(regex)do$1#Patternatfirstposition$2#Patternatsecondposition$~.offset(1)#Startingandendingpo
我想开始使用“Sinatra”框架进行编码,但我找不到该框架的“MVC”模式。是“MVC-Sinatra”模式或框架吗? 最佳答案 您可能想查看Padrino这是一个围绕Sinatra构建的框架,可为您的项目提供更“类似Rails”的感觉,但没有那么多隐藏的魔法。这是使用Sinatra可以做什么的一个很好的例子。虽然如果您需要开始使用这很好,但我个人建议您将它用作学习工具,以对您来说最有意义的方式使用Sinatra构建您自己的应用程序。写一些测试/期望,写一些代码,通过测试-重复:)至于ORM,你还应该结帐Sequel其中(imho
有没有一种方法可以自动生成种子数据文件并创建种子数据,就像您在下面链接中的Laravel中看到的那样?LaravelDatabaseMigrations&Seed我在另一个应用程序上看到在Rails的db文件夹下创建了一些带有时间戳的文件,其中包含种子数据。创建它的好方法是什么? 最佳答案 我建议你使用Fabrication的组合gem和Faker.Fabrication允许您编写一个模式来构建您的对象,而Faker为您提供虚假数据,如姓名、电子邮件、电话号码等。这是制造商的样子:Fabricator(:user)dousernam
我有一个交互式RubyonRails应用程序,我想在特定时间将其置于“只读模式”。这将允许用户读取他们需要的数据,但阻止他们执行写入数据库的操作。执行此操作的一种方法是在数据库中放置一个true/false变量,该变量在进行任何写入之前进行检查。我的问题。有没有更优雅的解决方案来解决这个问题? 最佳答案 如果你真的想阻止任何数据库写入,我能想到的最简单的方法是覆盖readonly?始终返回true的模型方法,无论是在选定模型中还是对于所有ActiveRecord模型。如果模型设置为只读(通常通过调用#readonly!来完成),任何