小伙伴们大家好,昨天的文章,带着大家扒开了Disruptor华丽的外衣,最重要的是我们知道了Disruptor高性能的原因几个重要的原因,
这篇文章就在上篇文章的基础上来点实战应用。研究下Disruptor的生产和消费模式,以及高级应用,至此关于Disruptor的系列的文章,也就到此结束了,我已经尽力了,如果还有什么没能满足大家需求的,以及关于文章的内容大家有任何其他的看法的,也欢迎在评论区留言,毕竟本人才疏学浅,期待各位大佬能给小弟指点一二。
前两篇文章在这里哦:
根据上面的环形结构,我们来具体分析一下Disruptor的工作原理。
Disruptor 不像传统的队列,分为一个队头指针和一个队尾指针,而是只有一个角标(上面的seq),那么这个是如何保证生产的消息不会覆盖没有消费掉的消息呢。
在Disruptor中生产者分为单生产者和多生产者,而消费者并没有区分。
单生产者情况下,就是普通的生产者向RingBuffer中放置数据,消费者获取最大可消费的位置,并进行消费。而多生产者时候,又多出了一个跟RingBuffer同样大小的Buffer,称为AvailableBuffer。
在多生产者中,每个生产者首先通过CAS竞争获取可以写的空间,然后再进行慢慢往里放数据,如果正好这个时候消费者要消费数据,那么每个消费者都需要获取最大可消费的下标,这个下标是在AvailableBuffer进行获取得到的最长连续的序列下标。
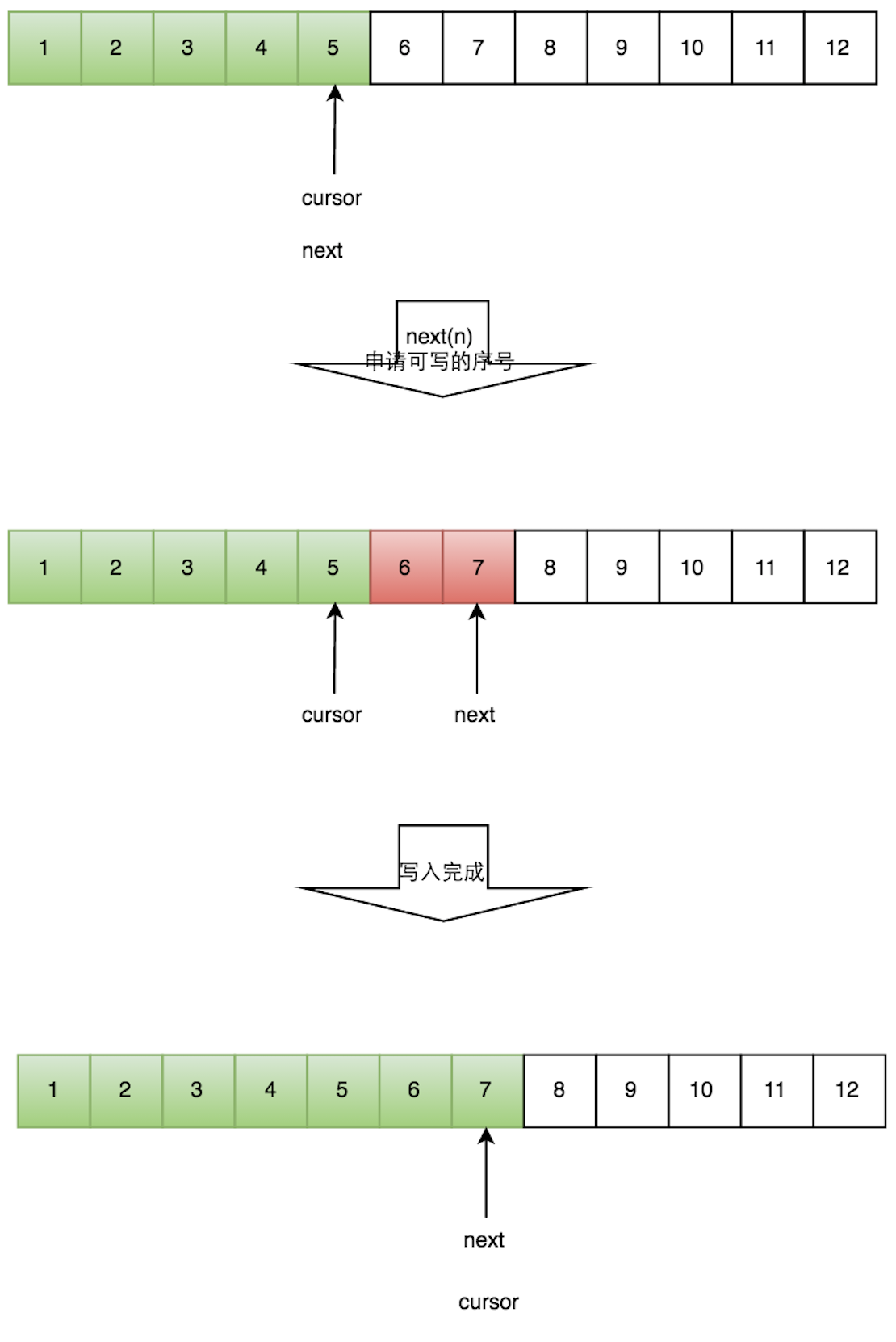
生产者单线程写数据的流程比较简单:
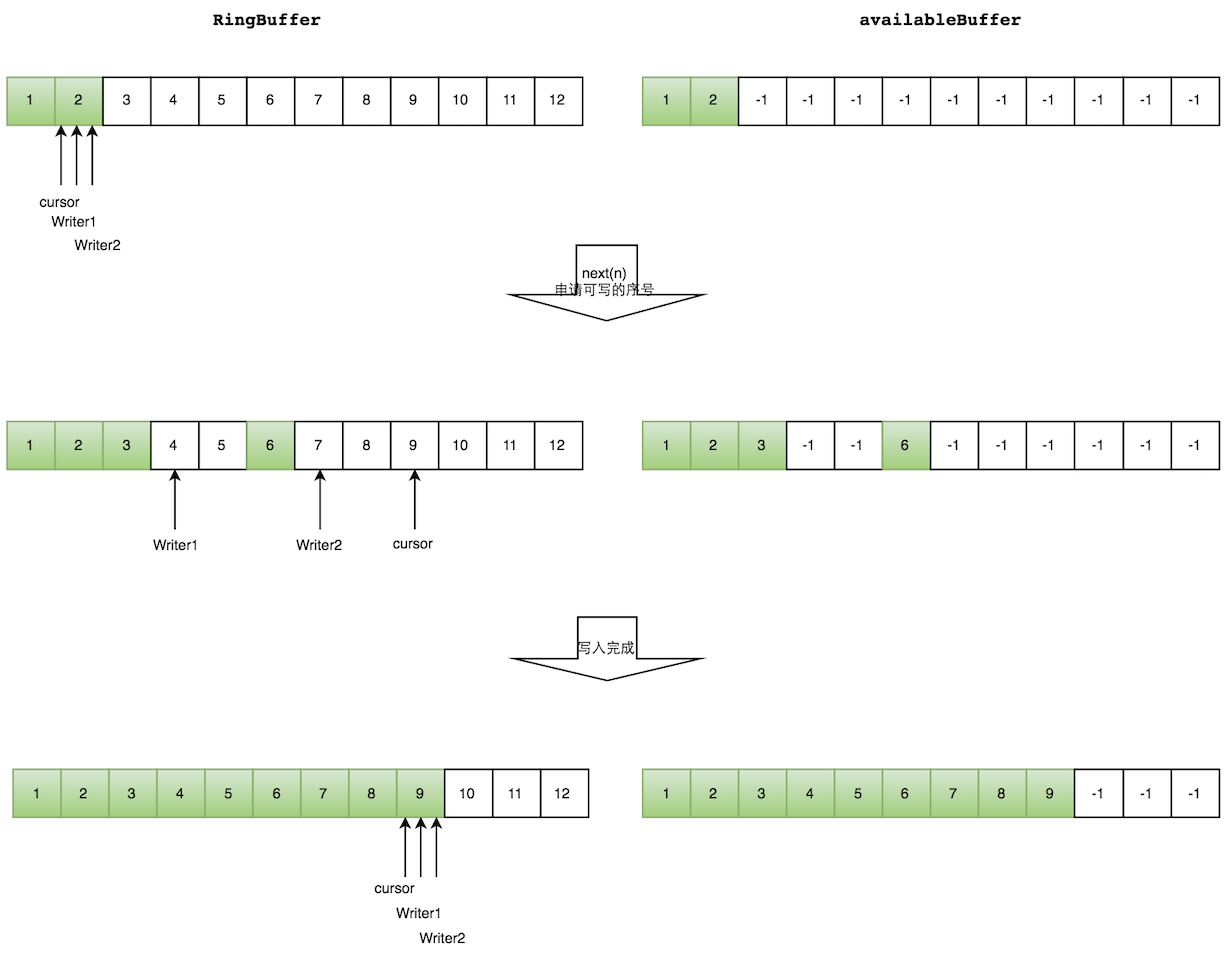
多个生产者的情况下,会遇到“如何防止多个线程重复写同一个元素”的问题。Disruptor的解决方法是,每个线程获取不同的一段数组空间进行操作。这个通过CAS很容易达到。只需要在分配元素的时候,通过CAS判断一下这段空间是否已经分配出去即可。
但是会遇到一个新问题:如何防止读取的时候,读到还未写的元素。Disruptor在多个生产者的情况下,引入了一个与Ring Buffer大小相同的buffer:available Buffer。当某个位置写入成功的时候,便把availble Buffer相应的位置置位,标记为写入成功。读取的时候,会遍历available Buffer,来判断元素是否已经就绪。
如下图所示,Writer1和Writer2两个线程写入数组,都申请可写的数组空间。Writer1被分配了下标3到下表5的空间,Writer2被分配了下标6到下标9的空间。
Writer1写入下标3位置的元素,同时把available Buffer相应位置置位,标记已经写入成功,往后移一位,开始写下标4位置的元素。Writer2同样的方式。最终都写入完成。
防止不同生产者对同一段空间写入的代码,如下所示:
通过do/while循环的条件cursor.compareAndSet(current, next),来判断每次申请的空间是否已经被其他生产者占据。假如已经被占据,该函数会返回失败,While循环重新执行,申请写入空间。
public long tryNext(int n) throws InsufficientCapacityException
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
current = cursor.get();
next = current + n;
if (!hasAvailableCapacity(gatingSequences, n, current))
{
throw InsufficientCapacityException.INSTANCE;
}
}
while (!cursor.compareAndSet(current, next));
return next;
}
绿色代表已经写OK的数据
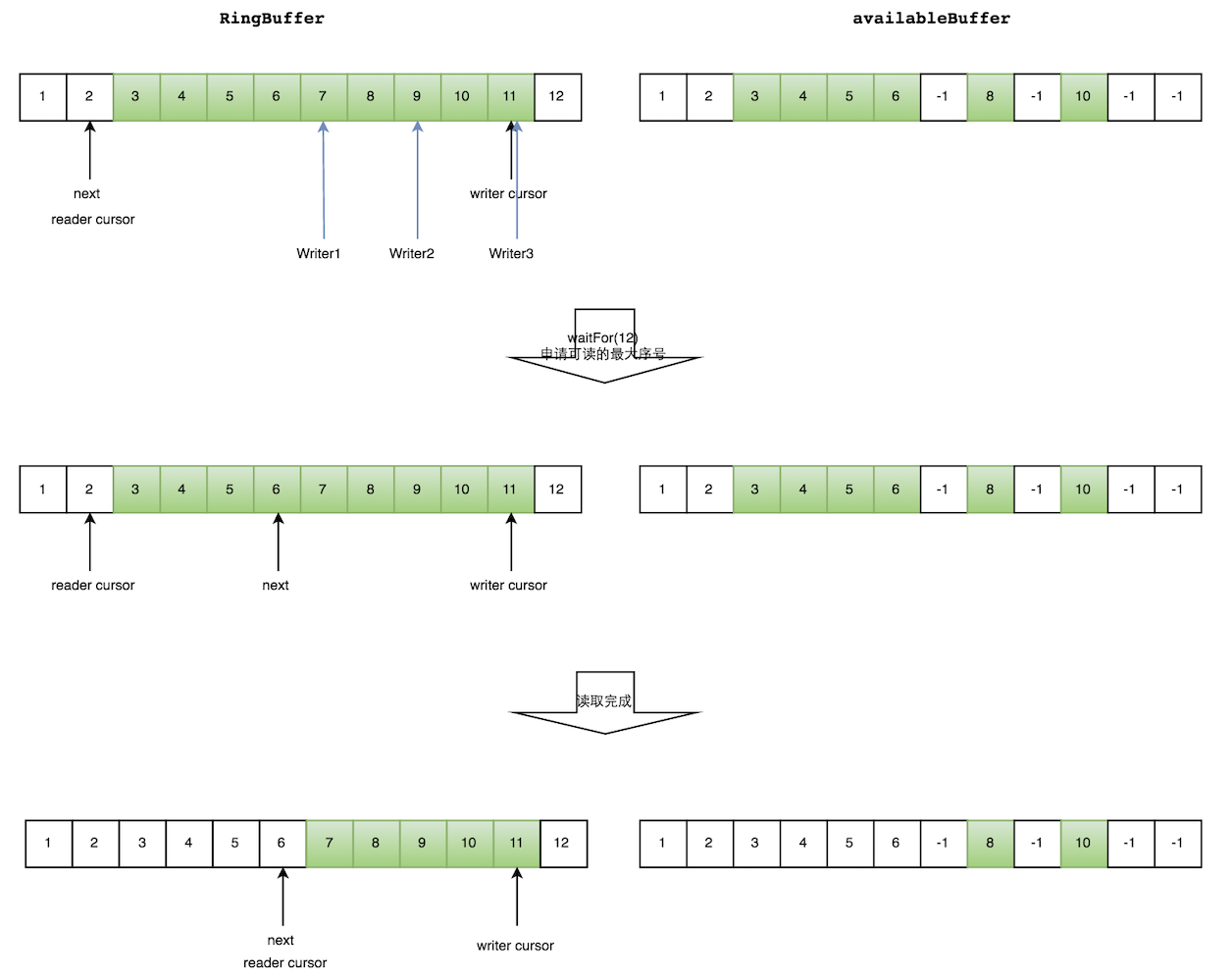
假设三个生产者在写中,还没有置位AvailableBuffer,那么消费者可获取的消费下标只能获取到6,然后等生产者都写OK后,通知到消费者,消费者继续重复上面的步骤。
如下图所示,读线程读到下标为2的元素,三个线程Writer1/Writer2/Writer3正在向RingBuffer相应位置写数据,写线程被分配到的最大元素下标是11。
读线程申请读取到下标从3到11的元素,判断writer cursor>=11。然后开始读取availableBuffer,从3开始,往后读取,发现下标为7的元素没有生产成功,于是WaitFor(11)返回6。
然后,消费者读取下标从3到6共计4个元素。
在并发系统中提高性能最好的方式之一就是单一写者原则,对Disruptor也是适用的。如果在你的代码中仅仅有一个事件生产者,那么可以设置为单一生产者模式来提高系统的性能。
public class singleProductorLongEventMain {
public static void main(String[] args) throws Exception {
//.....// Construct the Disruptor with a SingleProducerSequencer
Disruptor<LongEvent> disruptor = new Disruptor(factory,
bufferSize,
ProducerType.SINGLE, // 单一写者模式,
executor);//.....
}
}
比如:现在触发一个注册Event,需要有一个Handler来存储信息,一个Hanlder来发邮件等等。

/**
* 串行依次执行
* <br/>
* p --> c11 --> c21
* @param disruptor
*/
public static void serial(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWith(new C11EventHandler()).then(new C21EventHandler());
disruptor.start();
}
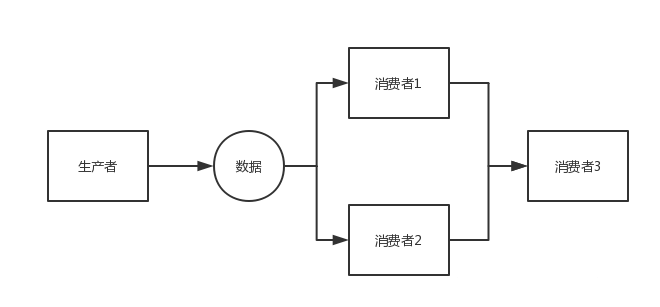
public static void diamond(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWith(new C11EventHandler(),new C12EventHandler()).then(new C21EventHandler());
disruptor.start();
}
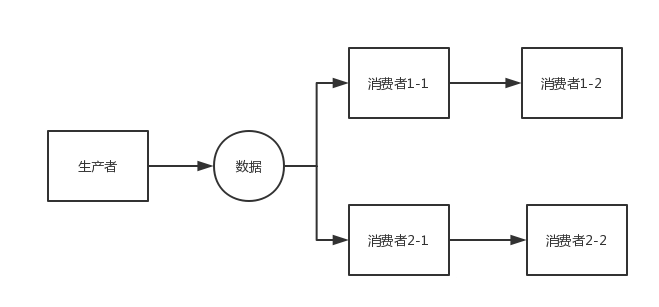
public static void chain(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWith(new C11EventHandler()).then(new C12EventHandler());
disruptor.handleEventsWith(new C21EventHandler()).then(new C22EventHandler());
disruptor.start();
}
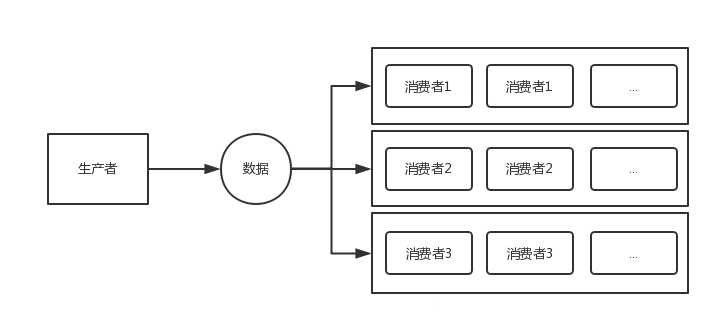
public static void parallelWithPool(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWithWorkerPool(new C11EventHandler(),new C11EventHandler());
disruptor.handleEventsWithWorkerPool(new C21EventHandler(),new C21EventHandler());
disruptor.start();
}
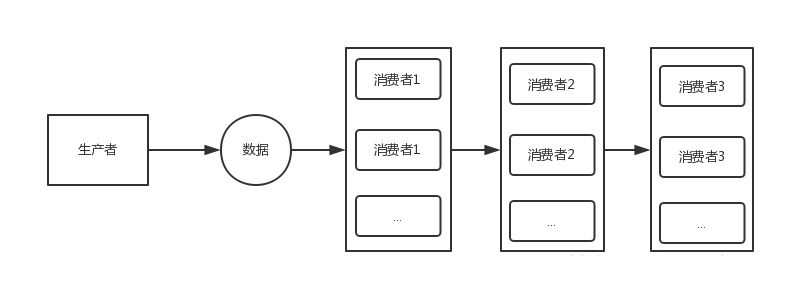
/**
* 串行依次执行,同时C11,C21分别有2个实例
* <br/>
* p --> c11 --> c21
* @param disruptor
*/
public static void serialWithPool(Disruptor<LongEvent> disruptor){
disruptor.handleEventsWithWorkerPool(new C11EventHandler(),new C11EventHandler()).then(new C21EventHandler(),new C21EventHandler());
disruptor.start();
}
本文由
传智教育博学谷教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除