【Avro介绍】
Apache Avro是hadoop中的一个子项目,也是一个数据序列化系统,其数据最终以二进制格式,采用行式存储的方式进行存储。
Avro提供了:
丰富的数据结构
可压缩、快速的二进制数据格式
一个用来存储持久化数据的容器文件
远程过程调用
与动态语言的简单集成,代码生成不需要读取或写入数据文件,也不需要使用或实现RPC协议。代码生成是一种可选的优化,只值得在静态类型语言中实现。
基于以上这些优点,avro在hadoop体系中被广泛使用。除此之外,在hudi、iceberg中也都有用到avro作为元数据信息的存储格式。
【schema】
Avro依赖"schema"(模式)来实现数据结构的定义,schema通过json对象来进行描述表示,具体表现为:
一个json字符串命名一个定义的类型
一个json对象,其格式为`{"type":"typeName" ...attributes...}`,其中`typeName`为原始类型名称或复杂类型名称。
一个json数组,表示嵌入类型的联合
schema中的类型由原始类型(也就是基本类型)(null、boolean、int、long、float、double、bytes和string)和复杂类型(record、enum、array、map、union和fixed)组成。
1、原始类型
原始类型包括如下几种:
null:没有值
boolean:布尔类型的值
int:32位整形
long:64位整形
float:32位浮点
double:64位浮点
bytes:8位无符号类型
string:unicode字符集序列
原始类型没有指定的属性值,原始类型的名称也就是定义的类型的名称,因此,schema中的"string"等价于{"type":"string"}。
2、复杂类型
Avro支持6种复杂类型:records、enums、arrays、maps、unions和fixed。
1)Records
reocrds使用类型名称"record",并支持以下属性
name:提供记录名称的json字符串(必选)
namespace:限定名称的json字符串
doc:一个json字符串,为用户提供该模式的说明(可选)
aliases:字符串的json数组,为该记录提供备用名称
fields:一个json数组,罗列所有字段(必选),每个字段又都是一个json对象,并包含如下属性:
name:字段的名称(必选)
doc:字段的描述(可选)
type:一个schema,定义如上
default:字段的默认值
order:指定字段如何影响记录的排序顺序,有效值为`"ascending"`(默认值)、"descending"和"ignore"。
aliases:别名
一个简单示例:
{
"type": "record",
"name": "LongList",
"aliases": ["LinkedLongs"],
"fields", [
{"name": "value", "type": "long"},
{"name": "next", "type": ["null", "LongList"]}
]
}2)Enums
Enum使用类型名称"enum",并支持以下属性
name:提供记录名称的json字符串(必选)
namespace:限定名称的json字符串
aliases:字符串的json数组,为该记录提供备用名称
doc:一个json字符串,为用户提供该模式的说明(可选)
symbols:一个json数组,以json字符串的形式列出符号。在枚举中每个符号必须唯一,不能重复,每个符号都必须匹配正则表达式"[A-Za-z_][A-Za-z0-9_]*"。
default:该枚举的默认值。
示例:
{
"type": "enum",
"name": "Suit",
"symbols": ["SPADES", "HEARTS", "DIAMONDS", "CLUBS"]
}3) Arrays
item:数组中元素的schema
一个例子:声明一个value为string的array
{
"type": "array",
"items": "string",
"default": []
}4)Maps
values:map的值(value)的schema,其key被假定为字符串
一个例子:声明一个value为long类型,(key类型为string)的map
{
"type": "map",
"values": "long",
"default": {}
}5)Unions
联合使用json数组表示,例如[null, "test"]声明一个模式,它可以是空值或字符串。
需要注意的是:当为union类型的字段指定默认值时,默认值的类型必须与union第一个元素匹配,因此,对于包含"null"的union,通常先列出"null",因为此类型的union的默认值通常为空。
另外, union不能包含多个相同类型的schema,类型为record、fixed和eum除外。
6)Fixed
Fixed使用类型名称"fixed"并支持以下属性:
name:提供记录名称的json字符串(必选)
namespace:限定名称的json字符串
aliases:字符串的json数组,为该记录提供备用名称
doc:一个json字符串,为用户提供该模式的说明(可选)
size:一个整数,指定每个值的字节数(必须)
例如,16字节的数可以声明为:
{
"type": "fixed",
"name": "md5",
"size": 16
}【Avro的文件存储格式】
1、数据编码
1)原始类型
对于null类型:不写入内容,即0字节长度的内容表示;
对于boolean类型:以1字节的0或1来表示false或true;
对于int、long:以zigzag的方式编码写入
对于float:固定4字节长度,先通过floatToIntBits转换为32位整数,然后按小端编码写入。
对于double:固定8字节长度,先通过doubleToLongBits转换为64位整型,然后按小端编码写入。
对于bytes:先写入长度(采用zigzag编码写入),然后是对应长度的二进制数据内容
对于string:同样先写入长度(采用zigzag编码写入),然后再写入字符串对应utf8的二进制数据。
2)复杂类型
对于enums:只需要将enum的值所在的Index作为结果进行编码即可,例如,枚举值为["A","B","C","D"],那么0就表示”A“,3表示"D"。
对于maps:被编码为一系列的块。每个块由一个长整数的计数表示键值对的个数(采用zigzag编码写入),其后是多个键值对,计数为0的块表示map的结束。每个元素按照各自的schema类型进行编码。
对于arrays:与map类似,同样被编码为一系列的块,每个块包含一个长整数的计数,计数后跟具体的数组项内容,最后以0计数的块表示结束。数组项中的每个元素按照各自的schema类型进行编码。
对于unions:先写入long类型的计数表示每个value值的位置序号(从零开始),然后再对值按对应schema进行编码。
对于records:直接按照schema中的字段顺序来进行编码。
对于fixed:使用schema中定义的字节数对实例进行编码。
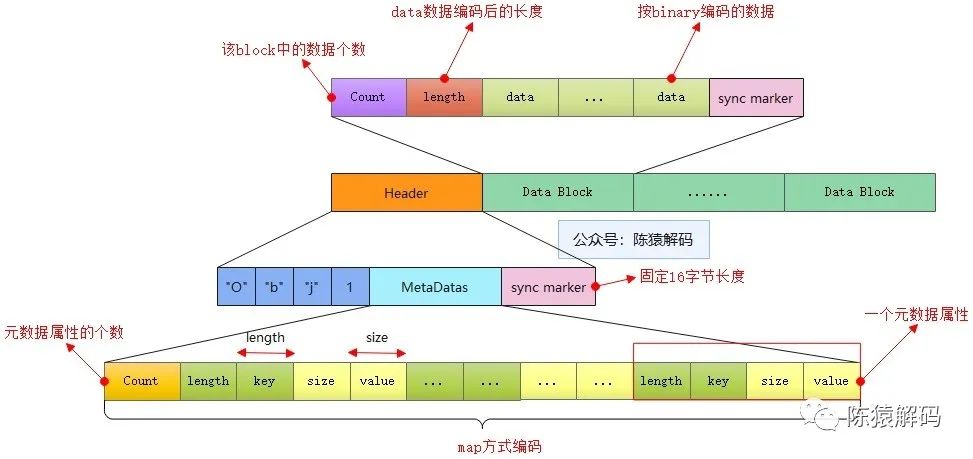
2、存储格式
在一个标准的avro文件中,同时存储了schema的信息,以及对应的数据内容。具体格式由三部分组成:
魔数
固定4字节长度,内容为字符'O','b','j',以及版本号标识,通常为1。
元数据信息
文件的元数据属性,包括schema、数据压缩编码方式等。整个元数据属性以一个map的形式编码存储,每个属性都以一个KV的形式存储,属性名对应key,属性值对应value,并以字节数组的形式存储。最后以一个固定16字节长度的随机字符串标识元数据的结束。
数据内容
而数据内容则由一个或多个数据块构成。每个数据块的最前面是一个long型(按照zigzag编码存储)的计数表示该数据块中实际有多少条数据,后面再跟一个long型的计数表示编码后的(N条)数据的长度,随后就是按照编码进行存储的一条条数据,在每个数据块的最后都有一个16字节长度的随机字符串标识块的结束。
整体存储内容如下图所示:
3、存储格式
我们通过一个实际例子来对照分析下。
首先定义schema的内容,具体为4个字段的表,名称(字符串)、年龄(整型)、技能(数组)、其他(map类型),详细如下所示:
{
"type":"record",
"name":"person",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
},
{
"name": "skill",
"type": {
"type":"array",
"items": "string"
}
},
{
"name": "other",
"type": {
"type": "map",
"values": "string"
}
}
]
}再按照上面的schema定义两条数据(person.json):
{"name":"hncscwc","age":20,"skill":["hadoop","flink","spark","kafka"],"other":{"interests":"basketball"}}
{"name":"tom","age":18, "skill":["java","scala"],"other":{}}通过avro-tools可以生成一个avro文件:
java -jar avro-tools-1.7.4.jar fromjson --schema-file person.avsc person.json > person.avro通过二进制的方式查看生成的avro文件内容:
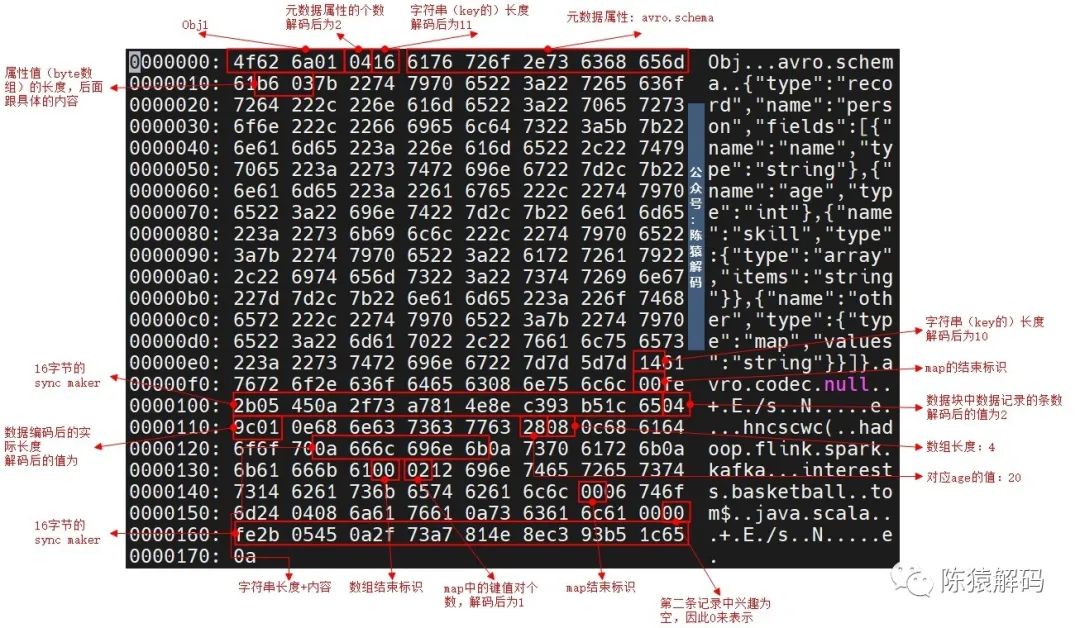
另外,对于一个已存在的文件,也可以通过avro-tools工具查看schema内容、数据内容。
[root@localhost avro]$ java -jar avro-tools-1.7.4.jar getschema ./person.avro
{
"type" : "record",
"name" : "person",
"fields" : [ {
"name" : "name",
"type" : "string"
}, {
"name" : "age",
"type" : "int"
}, {
"name" : "skill",
"type" : {
"type" : "array",
"items" : "string"
}
}, {
"name" : "other",
"type" : {
"type" : "map",
"values" : "string"
}
} ]
}
[root@localhost avro]$ java -jar avro-tools-1.7.4.jar tojson ./person.avro
{"name":"hncscwc","age":20,"skill":["hadoop","flink","spark","kafka"],"other":{"interests":"basketball"}}
{"name":"tom","age":18,"skill":["java","scala"],"other":{}}【小结】
本文对avro的格式定义、编码方式、以及实际存储的文件格式进行了详细说明,最后也以一个实际例子进行了对照说明。另外, 在官网中还涉及rpc的使用、mapreduce的使用,这里就没有展开说明,有兴趣的可移步官网进行查阅。
好了,这就是本文的全部内容,如果觉得本文对您有帮助,请点赞+转发,如果觉得有不正确的地方,也可以拍砖指点,最后,欢迎加我微信交流~
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
路由有如下代码:resources:orders,only:[:create],defaults:{format:'json'}resources:users,only:[:create,:update],defaults:{format:'json'}resources:delivery_types,only:[:index],defaults:{format:'json'}resources:time_corrections,only:[:index],defaults:{format:'json'}是否可以使用1个字符串为所有资源设置默认格式,每行不带“默认值”散列?谢谢。
我刚刚按照thebootsygempage上的安装说明进行操作在我保存并查看帖子内容之前,一切看起来都不错。这是输出在View中的样子:HeaderSubhead:似乎没有呈现任何html格式,因为它被引号或类似的东西转义了-其他人有这个问题吗?我没有在github页面或SO上看到任何问题来指出我正确的方向。除了遵循gem安装说明之外,我还没有做任何事情,但也许我错过了什么或者只是犯了一个愚蠢的错误。如果你还有什么想知道的,请尽管问。干杯 最佳答案 你需要有这样的东西,转义html: 关
有没有一种简单的方法可以将给定的整数格式化为具有固定长度和前导零的字符串?#convertnumberstostringsoffixedlength3[1,12,123,1234].map{|e|???}=>["001","012","123","234"]我找到了解决方案,但也许还有更聪明的方法。format('%03d',e)[-3..-1] 最佳答案 如何使用%1000而不是进行字符串操作来获取最后三位数字?[1,12,123,1234].map{|e|format('%03d',e%1000)}更新:根据theTinMan的
什么Ruby或RailsDSL会将字符串"mccdougal"格式化为"McDougal",同时留下字符串"McDougal"原样?将titleize传递给"McDougal"结果如下:"McDougal".titleize#=>"McDougal" 最佳答案 据我所知,没有可以处理这种情况的Rails助手。这是一个非标准的边缘案例,需要特殊处理。但是,您可以创建自定义字符串变形。您可以将这段代码放入初始化程序中:ActiveSupport::Inflector.inflections(:en)do|inflect|inflect.
什么是测试格式验证的最佳方法让我们说一个用户名,使用字母数字的正则表达式,但不是纯数字?我一直在我的模型中使用以下验证validates:username,:format=>{:with=>/^[a-z0-9]+[-a-z0-9]*[a-z0-9]+$/i}数字用户名(例如“342”)通过了验证,这是我不想要的。 最佳答案 您想“向前看”一封信:/\A(?=.*[a-z])[a-z\d]+\Z/i 关于ruby-on-rails-Rails格式验证——字母数字,但不是纯数字,我们在Sta