对于定时任务,在SpringBoot中只需要使用@Scheduled 这个注解就能够满足需求,它的出现也给我们带了很大的方便,我们只要加上该注解,并且根据需求设置好就可以使用定时任务了。
但是,我们需要注意的是,@Scheduled 并不一定会按时执行。
因为使用@Scheduled 的定时任务虽然是异步执行的,但是,不同的定时任务之间并不是并行的!!!!!!!!
在其中一个定时任务没有执行完之前,其他的定时任务即使是到了执行时间,也是不会执行的,它们会进行排队。
也就是如果你想你不同的定时任务互不影响,到时间就会执行,那么你最好将你的定时任务方法自己搞成异步方法,这样,定时任务其实就相当于调用了一个线程执行任务,一瞬间就结束了。比如使用:@Async
当然,也可以勉强将你的定时任务当做都会定时执行。但是,作为一个合格的程序员
那么,如何将@Scheduled实现的定时任务变成异步的呢?此时你需要对@Scheduled进行线程池配置。
package com.java.navtool.business.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.TaskExecutor;
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.SchedulingConfigurer;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.scheduling.config.ScheduledTaskRegistrar;
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
/**
* @author :mmzsblog.cn
* @date :Created in 2021/7/27 17:46
* @description:spring-boot 多线程 @Scheduled注解 并发定时任务的解决方案
* @modified By:
* @version:
*/
@Configuration
@EnableScheduling
public class ScheduleConfig implements SchedulingConfigurer {
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
taskRegistrar.setScheduler(taskExecutor());
}
public static final String EXECUTOR_SERVICE = "scheduledExecutor";
@Bean(EXECUTOR_SERVICE)
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 设置核心线程数
executor.setCorePoolSize(Runtime.getRuntime().availableProcessors());
// 设置最大线程数
executor.setMaxPoolSize(Runtime.getRuntime().availableProcessors() * 10);
// 设置队列容量
executor.setQueueCapacity(Runtime.getRuntime().availableProcessors() * 10);
// 设置线程活跃时间(秒)
executor.setKeepAliveSeconds(10);
// 设置默认线程名称
executor.setThreadNamePrefix("scheduled-");
// 设置拒绝策略
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 等待所有任务结束后再关闭线程池
executor.setWaitForTasksToCompleteOnShutdown(true);
return executor;
}
}
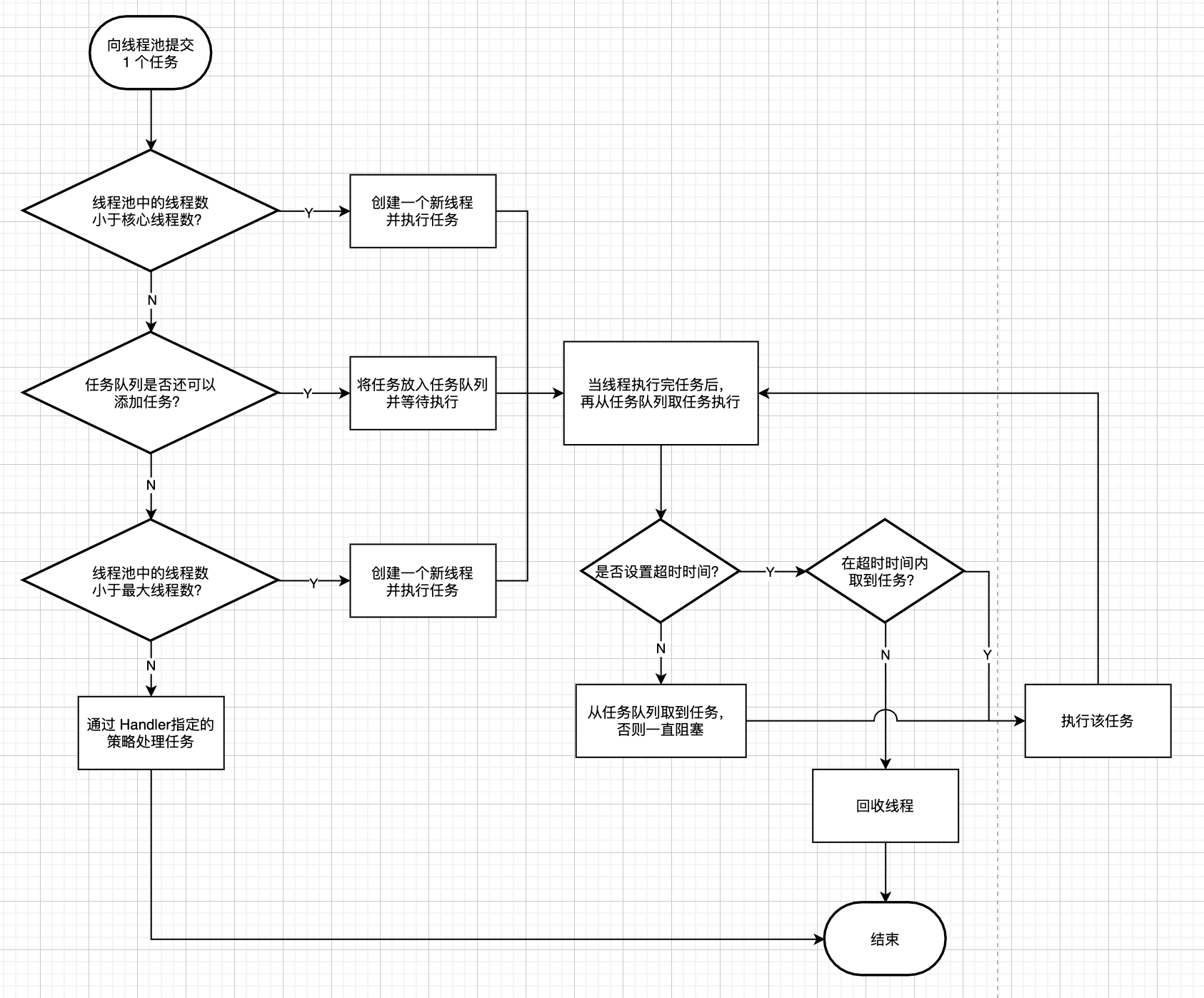
附带介绍一下线程池的几个参数。需要彻底搞懂,不要死记硬背哦!
上个流程图,先试着自己看下能不能看懂:
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?
我是ruby的新手,我认为重新构建一个我用C#编写的简单聊天程序是个好主意。我正在使用Ruby2.0.0MRI(Matz的Ruby实现)。问题是我想在服务器运行时为简单的服务器命令提供I/O。这是从示例中获取的服务器。我添加了使用gets()获取输入的命令方法。我希望此方法在后台作为线程运行,但该线程正在阻塞另一个线程。require'socket'#Getsocketsfromstdlibserver=TCPServer.open(2000)#Sockettolistenonport2000defcommandsx=1whilex==1exitProgram=gets.chomp
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它:
我以前没有使用过cron,所以我不能确定我这样做是对的。我想要自动化的任务似乎没有运行。我在终端中执行了这些步骤:sudogeminstall每当切换到应用程序目录无论何时。(这创建了文件schedule.rb)我将此代码添加到schedule.rb:every10.minutesdorunner"User.vote",environment=>"development"endevery:hourdorunner"Digest.rss",:environment=>"development"end我将此代码添加到deploy.rb:after"deploy:symlink","depl
如何在Rake任务中运行Capybara功能?例如:访问('http://google.com')谢谢! 最佳答案 在任务中尝试这样的事情:require'capybara'require'capybara/dsl'Capybara.current_driver=:seleniumBrowser=Class.new{includeCapybara::DSL}page=Browser.new.pagepage.visit("http://www.google.com")puts(page.html)
所以,Ruby1.9.1现在是declaredstable.Rails应该与它一起工作,并且正在慢慢地将gem移植到它。它具有native线程和全局解释器锁(GIL)。自从GIL到位后,原生线程是否比1.9.1中的绿色线程有任何优势? 最佳答案 1.9中的线程是原生的,但它们被“放慢了速度”,一次只允许一个线程运行。这是因为如果线程真的并行运行,它会混淆现有代码。优点:IO现在在线程中是异步的。如果一个线程阻塞在IO上,那么另一个线程将继续执行直到IO完成。C扩展可以使用真正的线程。缺点:任何非线程安全的C扩展都可能存在使用Thre