超详细讲解C语言文件操作!!
磁盘上的文件是文件。但是在程序设计中,我们一般谈的文件有两种:程序文件、数据文件(从文件功能的角度来分类的)。
1、程序文件
包括源程序文件(后缀为.c),目标文件(windows环境后缀为.obj),可执行程序(windows环境后缀为.exe)。
2、数据文件
文件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件,
或者输出内容的文件。
之前我们处理数据的输入输出大都是以终端为对象的,即从终端的键盘输入数据,运行结果显示到显示器上;但实际上,有时候我们会把信息输出到磁盘上,当需要的时候再从磁盘上把数据读取到内存中使用,这里处理的就是磁盘上文件。
那我们为什么要使用文件呢?举个例子,假入我们实现了一个通讯录的代码,当通讯录运行起来的时候,可以给通讯录中增加、删除数据,此时数据是存放在内存中,当程序退出的时候,通讯录中的数据自然就不存在了,等下次运行通讯录程序的时候,数据又得重新录入,如果使用这样的通讯录就很难受。
我们在想既然是通讯录就应该把信息记录下来,只有我们自己选择删除数据的时候,数据才不复存在。这就涉及到了数据持久化的问题,我们一般数据持久化的方法有,把数据存放在磁盘文件、存放到数据库等方式。
一个文件要有一个唯一的文件标识,以便用户识别和引用。文件名包含3部分:文件路径+文件名主干+文件后缀
例如: c:\code\test.txt
为了方便起见,文件标识常被称为文件名。
一个指针变量指向一个文件,这个指针称为文件指针。通过文件指针就可对它所指的文件进行各种操作。
缓冲文件系统中,关键的概念是“文件类型指针”,简称“文件指针”。
每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的。该结构体类型是有系统
声明的,取名FILE。
例如,VS2013编译环境提供的 stdio.h 头文件中有以下的文件类型申明:
struct _iobuf {
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};
typedef struct _iobuf FILE;
需要提及的是,不同的编译器FILE类型包含的内容不完全相同,但是大同小异,因此读者可以灵活变通,不必拘泥于某一种编译器的文件类型声明。
每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息,而一般我们就是通过一个文件指针FILE来维护这个FILE结构的变量。
下面我们创建一个FILE指针的变量:
FILE* pf;//文件指针变量
定义pf是一个指向FILE类型数据的指针变量。可以使pf指向某个文件的文件信息区(是一个结构体变量)。通过该文件信息区中的信息就能够访问该文件。也就是说,通过文件指针变量能够找到与它关联的文件。
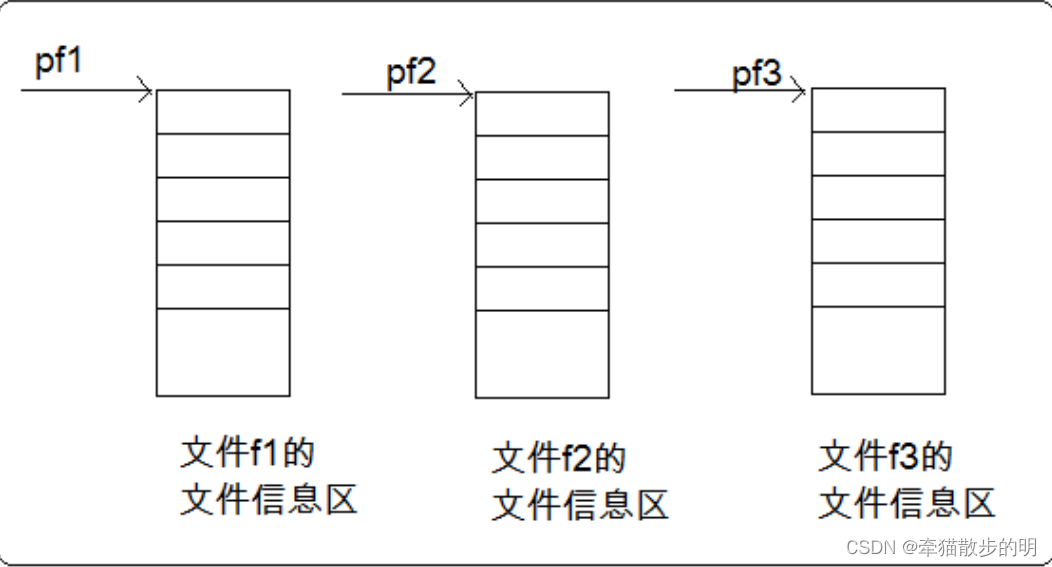
文件在读写之前应该先打开文件,在使用结束之后应该关闭文件。而关闭文件与否非常重要,在后面我会着重讲述这一个点。在打开文件的同时,都会返回一个FILE*的指针变量指向该文件,也相当于建立了指针和文件的关系。
一般,ANSIC 规定,打开文件我们使用的是fopen函数,关闭文件使用的是fclose文件,具体的文件函数我会单独写一篇博客进行介绍,这边读者们可以了解相关的函数参数,大致了解即可。


//打开文件
FILE * fopen ( const char * filename, const char * mode );
//关闭文件
int fclose ( FILE * stream );
而打开文件的方式也有许多种。
| 文件使用方式 | 含义 | 如果指定文件不存在 |
|---|---|---|
| “r”(只读) | 为了输入数据,打开一个已经存在的 文本文件 | 出错 |
| “w”(只写) | 为了输出数据,打开一个文本文件 | 建立一个新的文件 |
| “a”(追加) | 向文本文件尾添加数据 | 建立一个新的文件 |
| “rb”(只读) | 为了输入数据,打开一个二进制文件 | 出错 |
| “rb”(只读) | 为了输入数据,打开一个二进制文件 | 出错 |
| “wb”(只写) | 为了输出数据,打开一个二进制文件 | 建立一个新的文件 |
| “ab”(追加) | 向一个二进制文件尾添加数据 | 出错 |
| “r+”(读写) | 为了读和写,打开一个文本文件 | 出错 |
| “w+”(读写) | 为了读和写,建议一个新的文件 | 建立一个新的文件 |
| “a+”(读写) | 打开一个文件,在文件尾进行读写 | 建立一个新的文件 |
| “rb+”(读写) | 为了读和写打开一个二进制文件 | 出错 |
| “wb+”(读写) | 为了读和写,新建一个新的二进制文件 | 建立一个新的文件 |
| “ab+”(读写) | 打开一个二进制文件,在文件尾进行读和写 | 建立一个新的文件 |
下面进行代码的演示:
/* fopen fclose example */
#include <stdio.h>
int main ()
{
FILE * pFile;
//打开文件
pFile = fopen ("myfile.txt","w");
//文件操作
if (pFile!=NULL)
{
fputs ("fopen example",pFile);
//关闭文件
fclose (pFile);
}
return 0; }
需要注意的是,打开的文件一定要存在,且代码中打开文件的路径方式是因为文件本身就处在我们创建的C语言程序文件夹中,且注意的是txt是文件的后缀名而非名称的一部分。
在进行继续讲解时,我们首先要明白,文件指针中的 FILE * stream中的stream是什么。stream即为流,而流分为很多种,上述图中的所有输入\输出流即是指所有类型都可以进行输入输出,而文件指针对应的是文件流,即更改或读取等文件的数据。
流按方向分为:输入流和输出流。从文件获取数据的流称为输入流,向文件输出数据称为输出流。
流按数据形式分为:文本流和二进制流。文本流是 ASCII 码字符序列,而二进制流是字节序列。
流是一种抽象的概念,负责在数据的产生者和数据的使用者之间建立联系,并管理数据的流动。
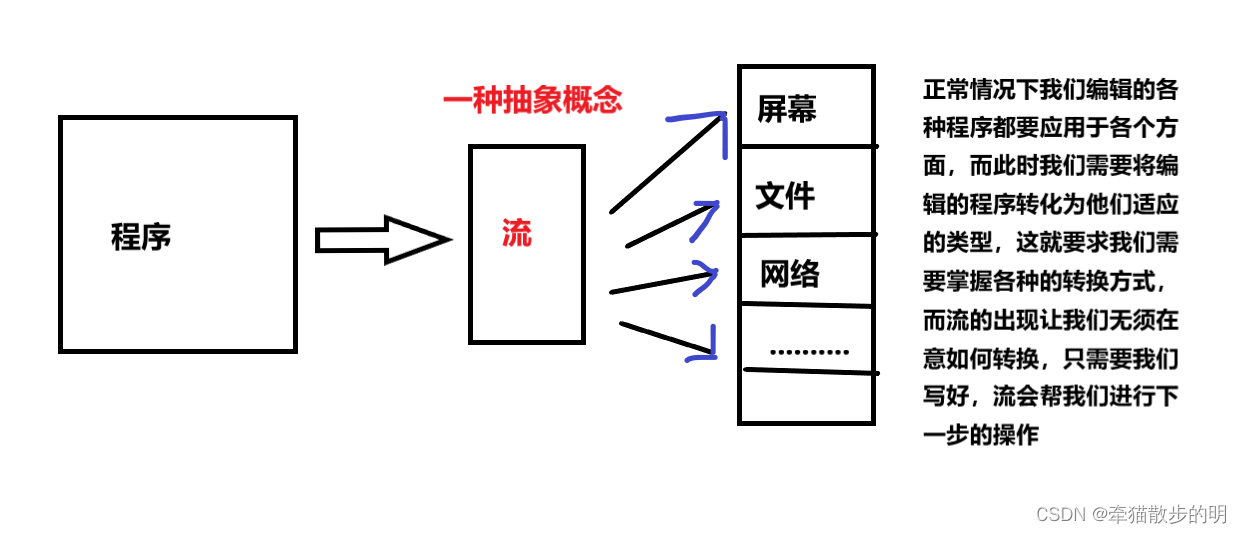
任何一个C语言程序运行时都会默认打开三个流:
stdin——标准输入(键盘)
stdout——标准输出(屏幕)
stdenr——标准错误(屏幕)
标准流属于流的一种。
具体的各函数讲解我会新写一篇博客进行,这边便不多赘述。

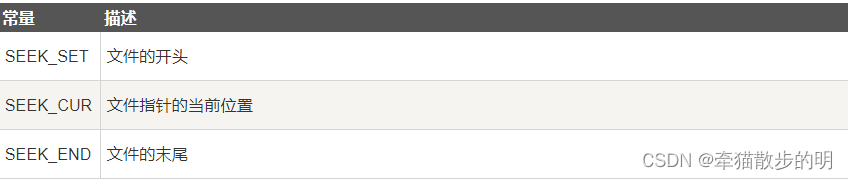
设置流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 origin 位置查找的字节数。
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
offset – 这是相对 whence 的偏移量,以字节为单位。
origin – 这是表示开始添加偏移 offset 的位置。它一般指定为下列常量之一。
下面的实例演示了 fseek函数的用法:
#include <stdio.h>
int main ()
{
FILE *fp;
fp = fopen("file.txt","w+");
fputs("This is runoob.com", fp);
fseek( fp, 7, SEEK_SET );
fputs(" C Programming Langauge", fp);
fclose(fp);
return(0);
}
编译并运行上面的程序,这将创建文件 file.txt,它的内容如下。最初程序创建文件和写入 This is runoob.com,但是之后我们在第七个位置重置了写指针,并使用 puts() 语句来重写文件,内容如下:
This is C Programming Langauge
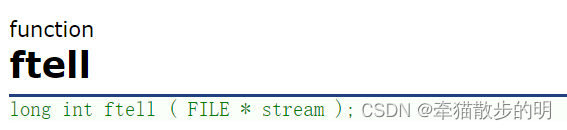
返回给定流 stream 的当前文件位置。(返回文件指针相对于起始位置的偏移量)
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
该函数返回位置标识符的当前值。如果发生错误,则返回 -1L,全局变量 errno 被设置为一个正值。
下面的实例演示了 ftell函数的用法:
#include <stdio.h>
int main ()
{
FILE *fp;
int len;
fp = fopen("file.txt", "r");
if( fp == NULL )
{
perror ("打开文件错误");
return(-1);
}
fseek(fp, 0, SEEK_END);
len = ftell(fp);
fclose(fp);
printf("file.txt 的总大小 = %d 字节\n", len);
return(0);
}
假设我们已经有了一个文本 file.txt,它的内容如下:
This is runoob.com
译并运行上面的程序,如果文件内容如上所示,这将产生以下结果,否则会根据文件内容给出不同的结果:file.txt 的总大小 = 19 字节。

设置文件位置为给定流 stream 的文件的开头(让文件指针的位置回到文件的起始位置)
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
该函数不返回任何值。
下面演示该函数用法。
/* rewind example */
#include <stdio.h>
int main ()
{
int n;
FILE * pFile;
char buffer [27];
pFile = fopen ("myfile.txt","w+");
for ( n='A' ; n<='Z' ; n++)
fputc ( n, pFile);
rewind (pFile);
fread (buffer,1,26,pFile);
fclose (pFile);
buffer[26]='\0';
puts (buffer);
return 0;
}
根据数据的组织形式,数据文件被称为文本文件或者二进制文件。
数据在内存中以二进制的形式存储,如果不加转换的输出到外存,就是二进制文件。如果要求在外存上以ASCII码的形式存储,则需要在存储前转换。以ASCII字符的形式存储的文件就是文本文件。
一个数据在内存中是怎么存储的呢?
字符一律以ASCII形式存储,数值型数据既可以用ASCII形式存储,也可以使用二进制形式存储。如有整数10000,如果以ASCII码的形式输出到磁盘,则磁盘中占用5个字节(每个字符一个字节),而二进制形式输出,则在磁盘上只占4个字节(VS2013测试)。
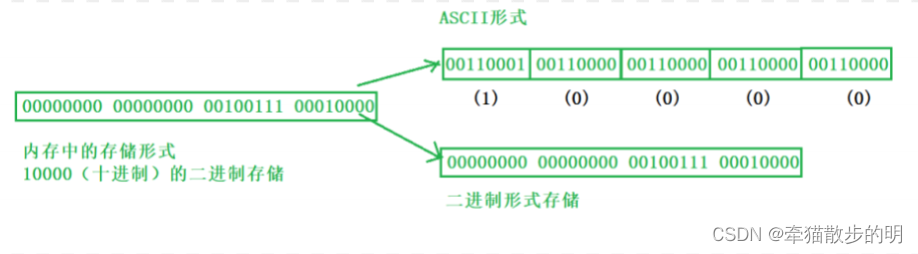
而对于二进制输出的文本文档,我们仍然可以用编译器进行查看。
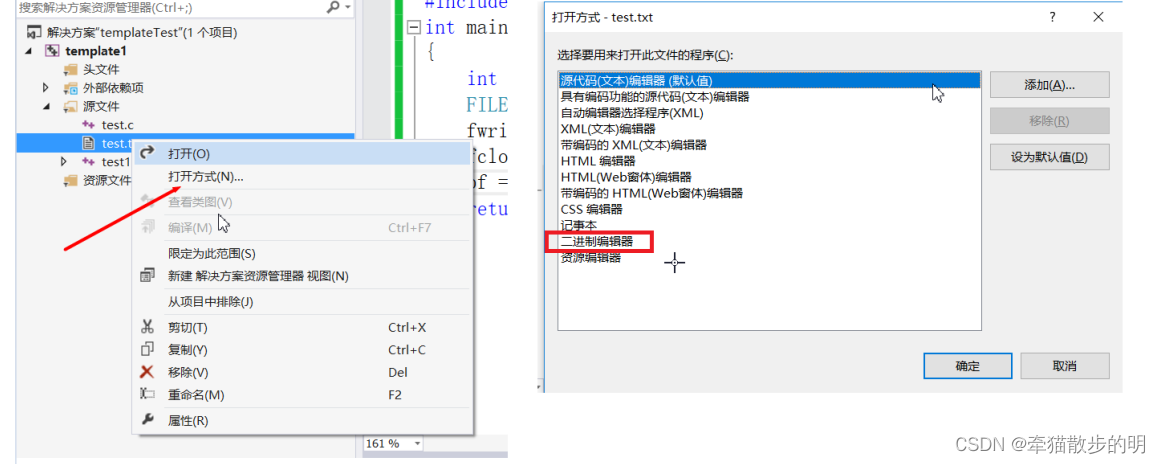
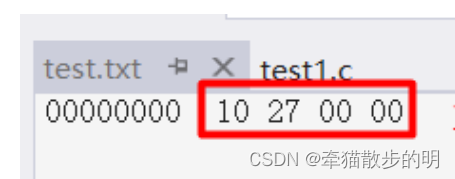
注意小端存储以及数据以16进制显现。
在文件读取过程中,不能用feof函数的返回值直接用来判断文件的是否结束。
而是应用于当文件读取结束的时候,判断是读取失败结束,还是遇到文件尾结束
1. 文本文件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets )
例如:
fgetc 判断是否为 EOF .
fgets 判断返回值是否为 NULL .
2. 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。
例如:
fread判断返回值是否小于实际要读的个数。
由于CPU 与 I/O 设备间速度不匹配。为了缓和 CPU 与 I/O 设备之间速度不匹配矛盾。文件缓冲区是用以暂时存放读写期间的文件数据而在内存区预留的一定空间。使用文件缓冲区可减少读取硬盘的次数。
ANSIC 标准采用“缓冲文件系统”处理的数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序中每一个正在使用的文件开辟一块“文件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区后才一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根据C编译系统决定的。
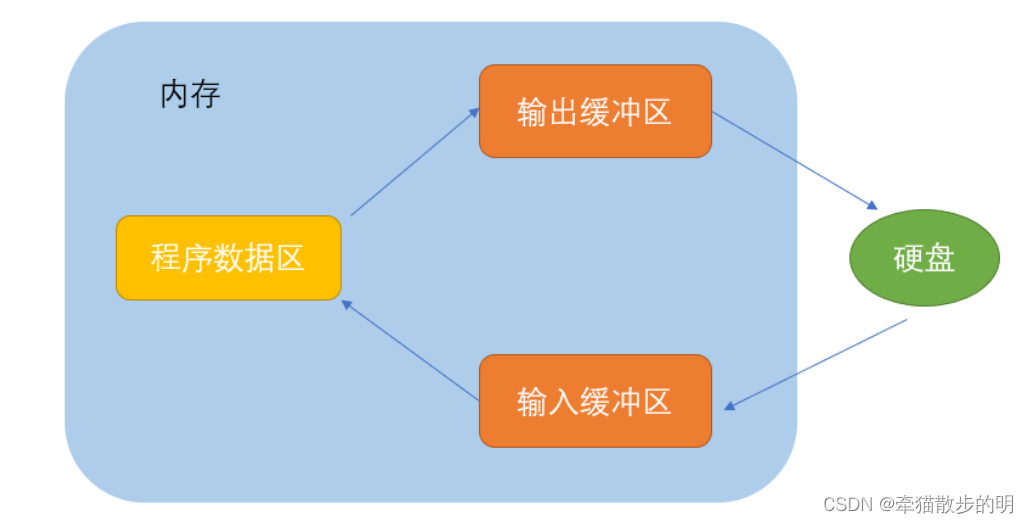
因此我们常说,打开文件对文件进行操作后要关闭文件,是因为fclose关闭文件操作执行前会自动进行缓冲区刷新操作。
因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文件。如果不做,可能导致读写文件的问题。
那么,今天的C语言文件操作的使用详解的相关内容我就讲述完啦,因为个人能力有限,文章难免会出现纰漏,届时有错误可以私信发给我以及时更正,谢谢大家!
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只