JunLeon——go big or go home

目录
目录
(4)配置log4j.properties 文件 [可选配置]
前言:
Spark部署模式主要有4种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、Spark On Yarn模式(使用YARN作为集群管理器)和Spark On Mesos模式(使用Mesos作为集群管理器)。
本教程做前三种环境搭建的详细讲解。
Linux:CentOS-7-x86_64-DVD-1708.iso
Hadoop:hadoop-2.7.3.tar.gz
Java:jdk-8u181-linux-x64.tar.gz
Anaconda:Anaconda3-2021.11-Linux-x86_64.sh
Spark:spark-2.4.0-bin-without-hadoop.tgz
请查看 大数据学习——Hadoop集群完全分布式的搭建(超详细)_IT路上的军哥的博客-CSDN博客_hadoop完全分布式搭建
注:本教程中使用Hadoop完全分布式集群,主机名分别为spark-master、spark-slave01、spark-slave02
(1)下载Anaconda3
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
注:如果打不开网页,可以尝试换浏览器打开
(2)上传Anaconda的文件到Linux
上传到指定目录:/opt/software #没有的话就创建
(3)Anaconda On Linux 安装
在该目录下,执行Anaconda文件
cd /opt/software
sh ./Anaconda3-2021.11-Linux-x86_64.sh进入以下界面:直接回车即可
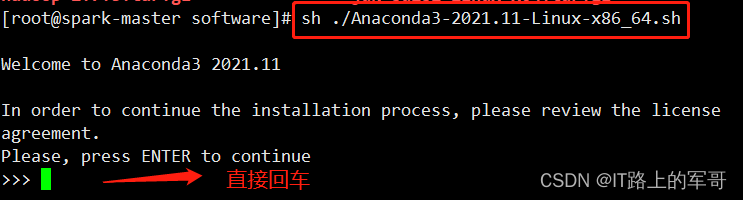
接下来 阅读许可条款 ,一直空格

在此处是询问是否同意许可条款,输入 yes

指定 anaconda3 安装路径:
将路径修改为
/opt/anaconda3目录下
此处需要初始化,输入 yes

最后,使用exit退出远程连接工具,重新连接,如果出现以下base字样,说明安装成功!

注:base是默认的虚拟环境。
以上单台 Anaconda On Linux 环境搭建成功,即可开始安装spark。
(4)配置国内源:
vi ~/.condarc这个文件,追加以下内容:
注:该文件是一个空文件,直接添加即可
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud(5)创建pyspark环境
conda create -n pyspark python=3.6 # 基于python3.6创建pyspark虚拟环境
conda activate pyspark # 激活(切换)到pyspark虚拟环境注:如果执行 conda create -n pyspark python=3.6 命令下载失败,可能是你的虚拟机不能ping通网络,可以看看ping www.baidu.com是否能够ping通
(6)pip下载pyhive、pyspark、jieba包
在pyspark环境中使用pip下载pyhive、pyspark、jieba包
pip install pyspark==2.4.0 jieba pyhive -i https://pypi.tuna.tsinghua.edu.cn/simpleSpark Local模式也称单机或者本地模式,仅供测试用。并在spark-master主机进行操作。
(1)Spark版本下载
该环境搭建spark使用spark-2.4.0版本
(2)上传Spark压缩包
上传到指定目录:/opt/software
(3)解压上传好的压缩包
cd /opt/software
tar -zxvf spark-2.4.0-bin-without-hadoop.tgz -C /opt
mv spark-2.4.0-bin-without-hadoop/ spark-2.4.0解压之后进行重命名,重命名为
spark-2.4.0
配置Spark由如下5个环境变量需要设置
SPARK_HOME: 表示Spark安装路径在哪里
PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
JAVA_HOME: 告知Spark Java在哪里
HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
HADOOP_HOME: 告知Spark Hadoop安装在哪里
这5个环境变量 都需要配置在: /etc/profile中
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_181
# HADOOP_HOME
export HADOOP_HOME=/opt/hadoop-2.7.3
# SPARK_HOME
export SPARK_HOME=/opt/spark-2.4.0
# HADOOP_CONF_DIR
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# PYSPARK_PYTHON
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$PATHPYSPARK_PYTHON和JAVA_HOME 需要同样配置在: ~/.bashrc中
vi ~/.bashrc
# 默认启动pyspark虚拟环境
conda activate pyspark
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_181
# PYSPARK_PYTHON
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$PATH配置好环境变量记得使文件生效:
source /etc/profile
source ~/.bashrc(1)spark-env.sh
cd /opt/spark-2.4.0/conf
cp spark-env.sh.template spark-env.sh在该文件最后追加以下内容:
export JAVA_HOME=/opt/jdk1.8.0_181
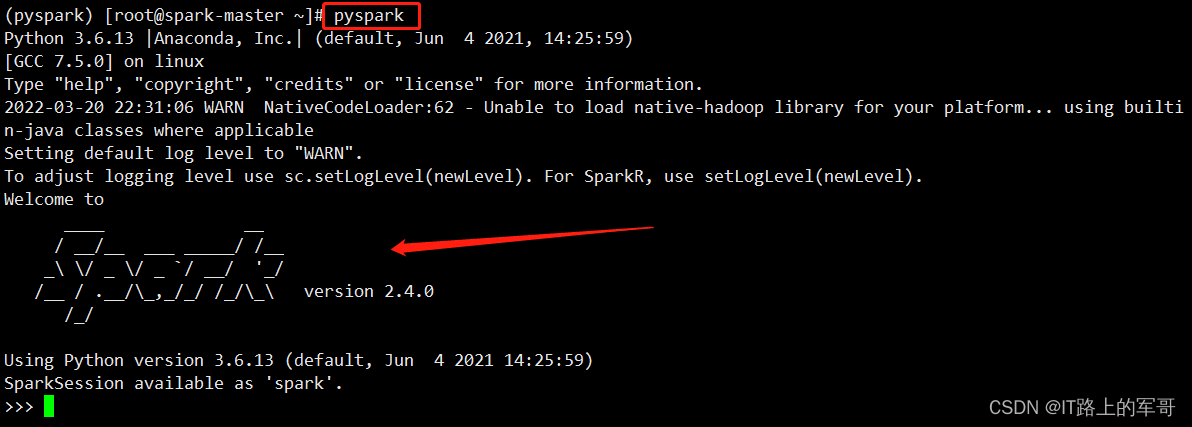
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)(1)验证Spark是否安装成功
pyspark进入pyspark虚拟环境后,输入pyspark后出现spark的logo则说明已成功:
(2)运行Spark自带的Pi实例
run-example SparkPi
run-example SparkPi 2>&1 | grep "Pi is roughly" # 过滤日志信息(3)运行WordCount.py文件
在家目录下,创建一个.py文件,添加以下代码:
附:WordCount.py代码
# ~/WordCount.py
if __name__ == '__main__':
# 导入相关依赖包
from pyspark import SparkConf, SparkContext
# 创建SparkConf,创建一个SparkContext对象
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
# 设置文件路径
logFile = "file:///opt/spark-2.4.0/README.md"
# 负责读取README.md文件生成RDD
logData = sc.textFile(logFile, 2).cache()
# 统计RDD元素中包含字母a和字母b的行数
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
# 打印输出统计结果
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))执行任务提交:
spark-submit ~/WordCount.py(1)spark-shell
同样是一个解释器环境, 和pyspark不同的是, 这个解释器环境运行的不是python代码, 而是scala程序代码。
scala> sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()
res0: Array[Int] = Array(2, 3, 4, 5, 6)(2)spark-submit
作用: 提交指定的Spark代码到Spark环境中运行
使用方法:
# 语法
bin/spark-submit [可选的一些选项] jar包或者python代码的路径 [代码的参数]
# 示例
bin/spark-submit /opt/spark-2.4.0/examples/src/main/python/pi.py 10
# 此案例运行Spark官方所提供的示例代码,来计算圆周率值。后面的10是主函数接受的参数, 数字越高, 计算圆周率越准确。(3)pyspark、spark-shell、spark-submit对比
| 功能 | bin/spark-submit | bin/pyspark | bin/spark-shell |
|---|---|---|---|
| 功能 | 提交java\scala\python代码到spark中运行 | 提供一个python | |
| 解释器环境用来以python代码执行spark程序 | 提供一个scala | ||
| 解释器环境用来以scala代码执行spark程序 | |||
| 特点 | 提交代码用 | 解释器环境 写一行执行一行 | 解释器环境 写一行执行一行 |
| 使用场景 | 正式场合, 正式提交spark程序运行 | 测试\学习\写一行执行一行\用来验证代码等 | 测试\学习\写一行执行一行\用来验证代码等 |
(1)集群主机名、IP规划
| 主机名 | IP地址 | 节点类型 |
|---|---|---|
| spark-master | 192.168.83.100 | Master |
| spark-slave01 | 192.168.83.101 | Slave |
| spark-slave02 | 192.168.83.102 | Slave |
(2)节点规划
| 节点进程 | spark-master | spark-slave01 | spark-slave02 |
|---|---|---|---|
| NameNode | ✔ | ||
| Secondary NameNode | ✔ | ||
| DataNode | ✔ | ✔ | ✔ |
| ResourceManager | ✔ | ||
| NodeManager | ✔ | ✔ | ✔ |
| JobHistoryServer(YARN) | ✔ | ||
| Master | ✔ | ||
| Worker | ✔ | ✔ | ✔ |
| HistoryServer(Spark) | ✔ |
注:
JobHistoryServer:YARN资源管理器的历史服务器,将YARN运行的程序的历史日志记录下来,通过历史服务器方便用户查看程序运行的历史信息。
HistoryServer:Spark的历史服务器,将Spark运行的程序的历史日志记录下来, 通过历史服务器方便用户查看程序运行的历史信息。
此Anaconda环境搭建参考以上 环境准备中的第3点。也可以从第一台分发到另外两台:
scp -r /opt/anaconda3 root@spark-slava01:/opt
scp -r /opt/anaconda3 root@spark-slava02:/opt可以在spark-master主机操作,最后再进行分发。
注:Spark安装路径为:/opt/spark-2.4.0
spark配置文件路径为:/opt/spark-2.4.0/conf
cd /opt/spark-2.4.0/conf# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑spark-env.sh, 在底部追加如下内容
vi spark-env.sh在spark-env.sh文件底部追加以下内容
## 设置JAVA安装目录
export JAVA_HOME=/opt/jdk1.8.0_181
## 设置hadoop命令路径
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)
## 以上两行在local模式中已经添加,如果有请勿重复配置
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
YARN_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=spark-master
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://spark-master:9000/sparklog/ -Dspark.history.fs.cleaner.enabled=true"# 1. 改名
mv spark-defaults.conf.template spark-defaults.confvi spark-defaults.conf # 2. 修改内容, 追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://spark-master:9000/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true# 改名, 去掉后面的.template后缀
mv slaves.template slaves# 编辑worker文件 vi slaves # 将文件里面最后一行的localhost删除
追加从节点worker运行的服务器,配置三台主机名
spark-master
spark-slave01
spark-slave02# 1. 改名
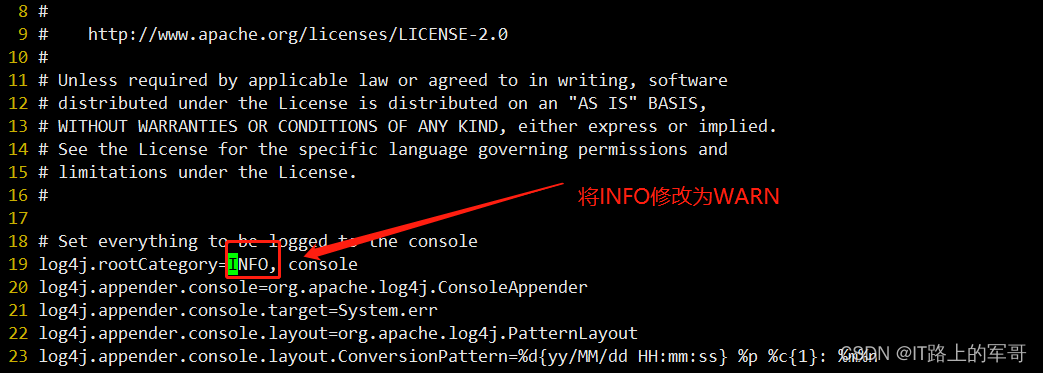
mv log4j.properties.template log4j.properties# 2. 修改内容 参考下图
vi log4j.properties定位到19行:将INFO修改为WARN
将在spark-master主机上配置好的spark分发到另外两台服务器上:
scp -r /opt/spark-2.4.0/ root@spark-slave01:/opt/
scp -r /opt/spark-2.4.0/ root@spark-slave02:/opt/将主机的/etc/profile文件和~/.bashrc文件也同时分发到另外两台:
scp /etc/profile root@spark-slave01:/etc/
scp /etc/profile root@spark-slave02:/etc/
scp ~/.bashrc root@spark-slave01:~/
scp ~/.bashrc root@spark-slave02:~/分发过去之后需要分别在两台使配置文件生效:
source /etc/profile
source ~/.bashrc1)启动Hadoop集群
start-all.sh # 只在spark-master主机上执行2)启动spark集群
cd /opt/spark-2.4.0/sbin
./start-all.sh开启全部节点后,如图所示:
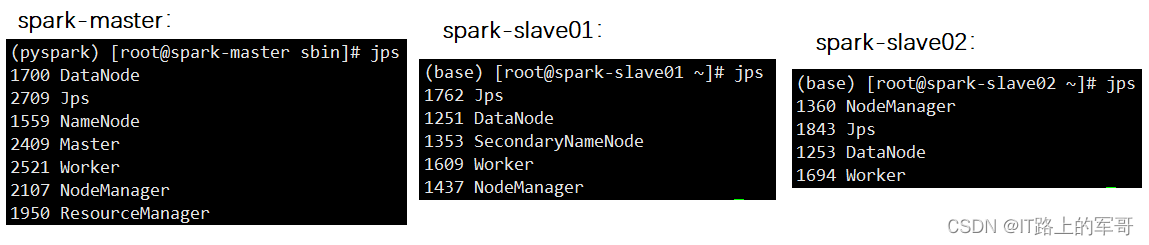
web端访问需要关闭防火墙:
systemctl stop firewalld1)访问HDFS
192.168.83.100:50070 # IP:端口号2)访问YARN
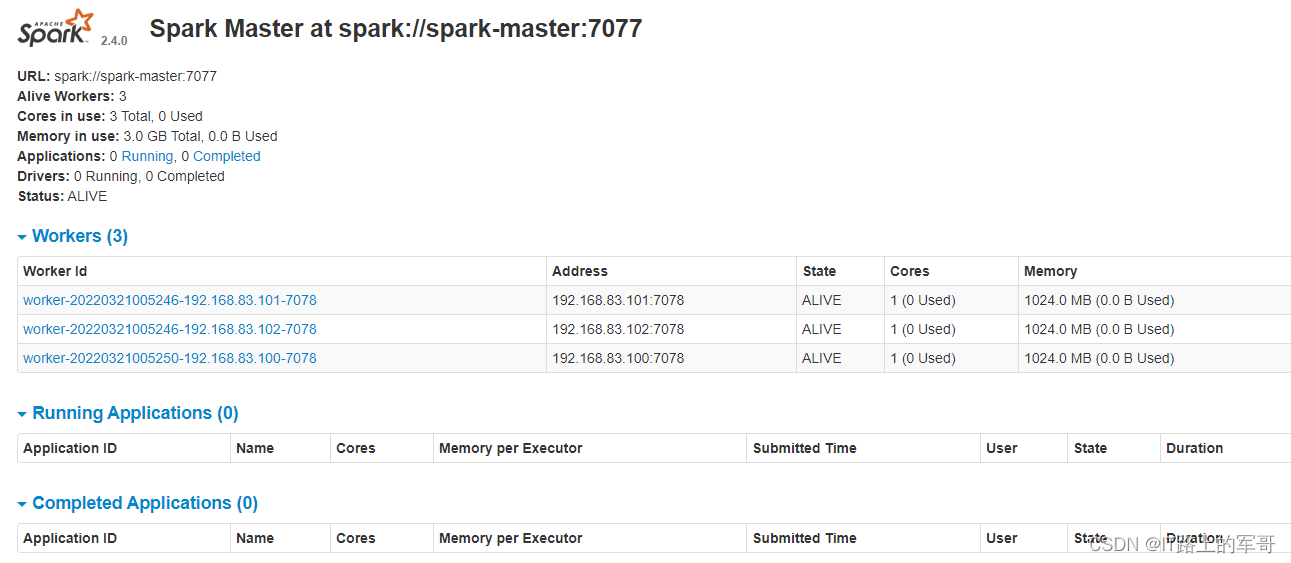
192.168.83.100:8088 # IP:端口号3)访问Spark
192.168.83.100:8080 # IP:端口号如图所示说明成功:
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
我试图在rails中了解rubygems是如何变得可以自动使用的,而不是在使用required的文件中gem? 最佳答案 这是通过bundler/setup完成的:http://bundler.io/v1.3/bundler_setup.html.它在您的config/boot.rb文件中是必需的。简而言之,它首先将环境变量设置为指向您的Gemfile:ENV['BUNDLE_GEMFILE']||=File.expand_path('../../Gemfile',__FILE__)然后它通过要求bundler/setup将所有ge
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情