目录
http-only的设计主要是用来防御XSS攻击,所以学习本实验的读者应首先了解XSS攻击的相关原理内容。
跨站点脚本攻击是困扰Web服务器安全的常见问题之一。跨站点脚本攻击是一种服务器端的安全漏洞,常见于当把用户的输入作为HTML提交时,服务器端没有进行适当的过滤所致。跨站点脚本攻击可能引起泄漏Web站点用户的敏感信息。为了降低跨站点脚本攻击的风险,微软公司的Internet Explorer 6 SP1引入了一项新的特性。
对于很多只依赖于cookie验证的网站来说,http-only cookies是一个很好的解决方案,在支持http-only cookies的浏览器中(IE6以上,FF3.0以上),Javascript是无法读取和修改http-only cookies,这样可让网站用户验证更加安全。
1)了解http-only的作用及在Cookie中的存在方式。
2)掌握通过设置http-only防御XSS攻击。

一台Windows XP主机。
主机部署实验测试网站。
主机安装Fiddler软件。
在IE浏览器中访问本实验的测试网站:http://10.1.1.189/httponly-test/login.php。
(注意,本实验一定要在IE中浏览网页,这是因为目前版本的IE没有XSS过滤器,方便我们做实验)
此时我们打开fiddler工具抓包,返回浏览器,在登录框中输入用户ID:admin和密码:123456进行登录。登录后我们可以看到主界面:
在Fiddler中查看刚刚用于登录的HTTP包,观察响应头的Cookie字段(红色框内),记录下此时的cookie内容:
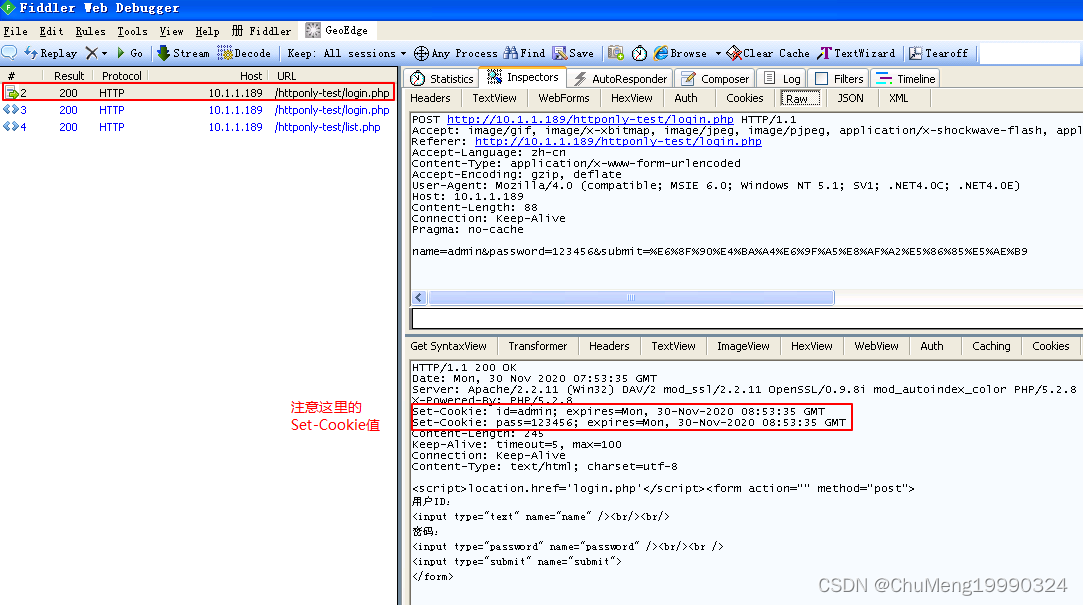
这里的昵称输入框由于没有对输入字符进行过滤,存在XSS漏洞。我们在框中输入“<script>alert(document.cookie);</script>”提交验证,结果弹出如下提示,从而验证了XSS漏洞的存在。(对于XSS不理解的读者一定要首先掌握XSS基本知识)

在网站建设过程中,由于编程人员安全意识薄弱或工作疏忽,很容易出现如上所示的XSS漏洞。恶意攻击者可以利用该种漏洞窃取用户Cookie信息,从而冒充用户身份访问网站。应对XSS攻击,可以采用对输入(输出)文本进行特殊字符过滤的方式,但由于网站业务类型复杂多样,且针对过滤也存在绕过方法,所以,仅仅通过过滤手段并不能完全解决XSS问题。Http-only的引入,就是从防止脚本读取Cookie的角度有效防御了XSS漏洞的攻击。
http-only具体怎样引入,又为何能解决XSS问题呢?
我们重新看步骤一中所抓取得http包,当我们输入用户名和口令进行登录操作时,服务器端对口令进行校验,如果成功,返回给我们登录信息,并且在返回数据包中包含了cookie信息,以便保存用户的登录状态。如这条cookie:
id=admin;expires=mon, 30-Nov-2020 08:53:35 GMT
它实质上包含了两个内容,一个是服务器端程序设定的用于保存用户身份标识的字段值(id=admin),另一个是这条cookie的过期时间。而步骤一中的XSS攻击做了什么呢?它利用JavaScript脚本,读取到了这条cookie,既然能读取到,那攻击者就更有办法把这条cookie为他所用,借用cookie中包含的身份标识假冒用户去登录网站。这时,如果能出台一种机制,禁止JavaScript脚本来读取cookie信息,那一切都得到了解决。攻击者即使成功发动了XSS攻击,获得了在用户浏览器端执行JavaScript脚本的能力,但由于脚本无法读取cookie,他仍然不能得到任何用户身份标识。
http-only字段,就是加在cookie身上的一个“护身符”。浏览器存在这种机制,只要cookie中含有Http-only字段,那么任何JavaScript脚本都没有权限读取这条cookie的内容。
所以,下边我们要改写服务器端代码,使用户重新登陆后,Cookie中附带上http-only属性。找到源代码文件:C:\xampp\htdocs\httponly-test\login.php,右键选择EditPlus打开。注意不要用记事本修改php代码,否则会误添加BOM导致PHP无法正常解析。打开文件方法如下图所示:

找到下图所示两行代码,setcookie函数表示当验证用户合法登陆后,向用户浏览器中返回Cookie。
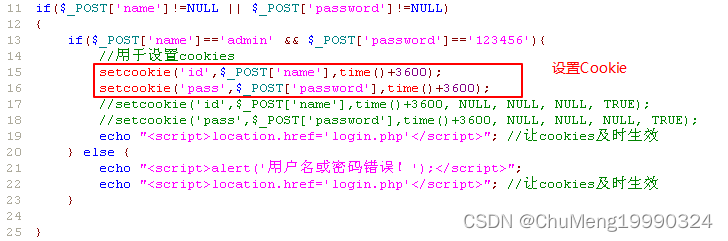
上图中的两条setcookie语句,在实际过程中就转变为服务器向客户端返回的两条cookie信息:
Set-Cookie:id=admin;expires=mon, 30-Nov-2020 08:53:35 GMT
Set-Cookie:pass=12346;expires=mon,30-Nov-2020 08:53:35 GMT
现在,我们修改setcookie方法参数,改为以下这种方式调用setcookie:

我们在setcookie方法的第七个传入参数中设置了变量TRUE,表示这个cookie具有HTTP-only属性。保存并退出文件。
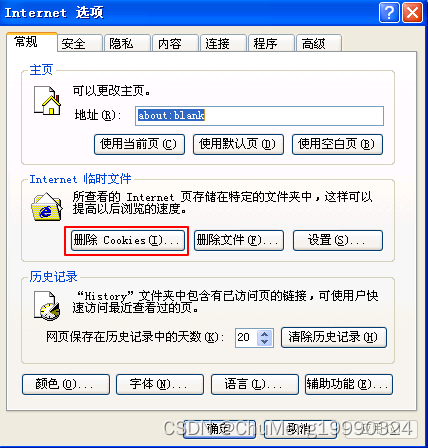
回到浏览器中,首先把浏览器的Cookie清空。清空方法为打开菜单栏→工具→Internet选项,选择删除Cookie:
打开抓包软件Fiddler,重新登陆我们的测试网站。
http://10.1.1.189/httponly-test/login.php
登陆后在fiddler中观察数据包。
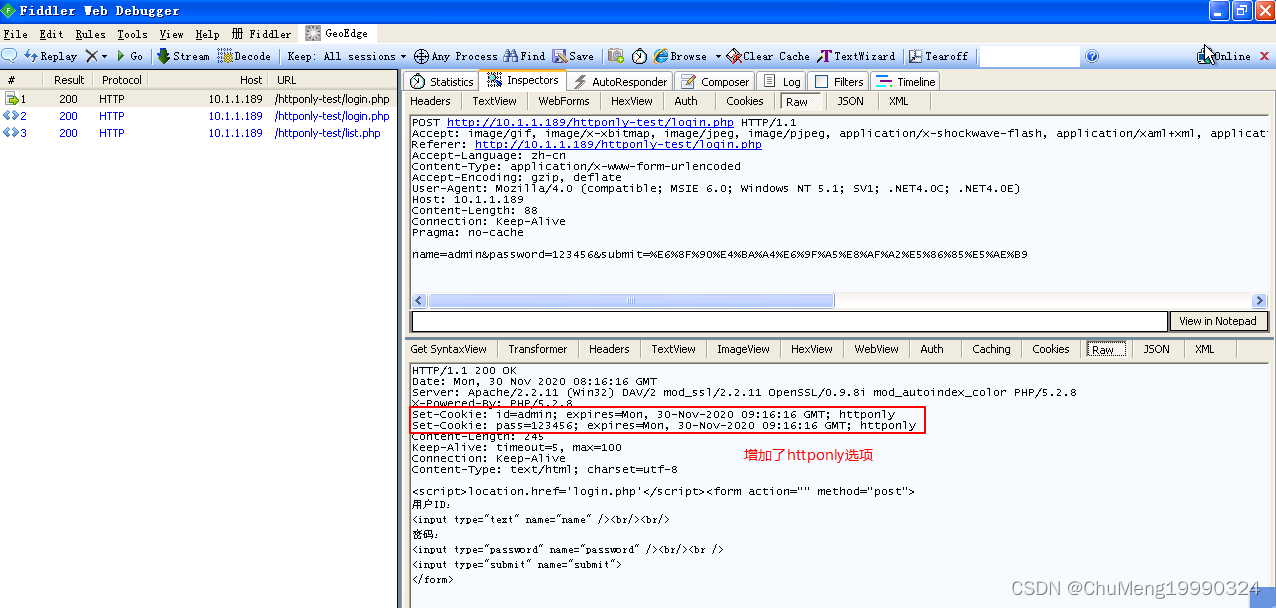
可以发现,这次服务器返回给用户浏览器的cookie中,两个字段都被添加上了http-only属性。这样从理论上,用户的身份标识cookie,因为有了http-only这个“护身符”,将令任何JavaScript脚本无可奈何。
我们接着步骤二的操作,现在我们已经成功登录进输入昵称的界面中。此时,这个输入框仍然存在反射型XSS漏洞,我们继续利用该漏洞点,尝试窃取cookie。在昵称输入框中输入:
<script>alert(document.cookie);</script>
点击提交,此时再观察弹出框:
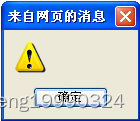
此时发现,虽然XSS漏洞点依旧存在,但XSS的恶意利用脚本已无法获取到用户的Cookie,弹出的内容为空。这个实验结果成功验证向cookie中添加http-only字段的效果。通过这种方法,网站成功保护了用户的Cookie信息免遭攻击者窃取。
我们知道,防御XSS攻击的思路方法有很多。我们常见的,如在用户输入和输出端加过滤,过滤掉某些特殊字符,从而避免恶意JavaScript脚本的运行。而http-only,则是从另一角度考虑对XSS做防御,即使攻击者传进来的恶意JavaScript脚本得到运行,但我的用户cookie受到了保护,脚本无法读取cookie内容。这使得想利用XSS攻击窃取用户身份的想法化为泡影。在实战中,网站防御者们往往会综合利用到对字符做过滤和添加http-only属性的方式,对抗XSS。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
给定以下方法:defsome_method:valueend以下语句按我的预期工作:some_method||:other#=>:valuex=some_method||:other#=>:value但是下面语句的行为让我感到困惑:some_method=some_method||:other#=>:other它按预期创建了一个名为some_method的局部变量,随后对some_method的调用返回该局部变量的值。但为什么它分配:other而不是:value呢?我知道这可能不是一件明智的事情,并且可以看出它可能有多么模棱两可,但我认为应该在考虑作业之前评估作业的右侧...我已经在R
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我正在使用Heroku(heroku.com)来部署我的Rails应用程序,并且正在构建一个iPhone客户端来与之交互。我的目的是将手机的唯一设备标识符作为HTTPheader传递给应用程序以进行身份验证。当我在本地测试时,我的header通过得很好,但在Heroku上它似乎去掉了我的自定义header。我用ruby脚本验证:url=URI.parse('http://#{myapp}.heroku.com/')#url=URI.parse('http://localhost:3000/')req=Net::HTTP::Post.new(url.path)#boguspara
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion