论文链接:https://arxiv.org/abs/2302.09419
该综述系统性的回顾了预训练基础模型(PFMs)在文本、图像、图和其他数据模态领域的近期前沿研究,以及当前、未来所面临的挑战与机遇。具体来说,作者首先回顾了自然语言处理、计算机视觉和图学习的基本组成部分和现有的预训练方案。然后,讨论了为其他数据模态设计的先进PFMs,并介绍了考虑数据质量和数量的统一PFMs。此外,作者还讨论了PFM基本原理的相关研究,包括模型的效率和压缩、安全性和隐私性。最后,列出了关键结论,未来的研究方向,挑战和开放的问题。
笔者主要从事NLP相关方向,因此在阅读该综述时,重点归纳整理了NLP部分的内容,对于CV和GL的PFMs应用仅以了解为主,如有需要再查漏补缺。
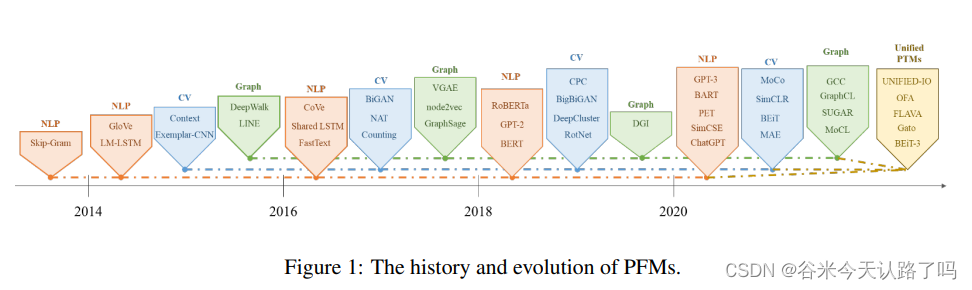
PFMs是通过大量的数据训练出一个通用模型,在使用时仅需微调就能应用于不同的下游任务。下图是PFMs的发展历程:
PFMs模型的一般架构如下图:
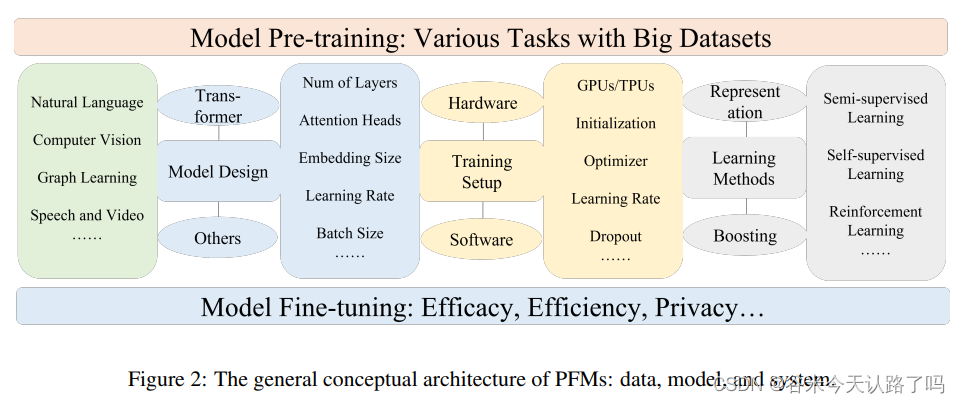 PFMs的具体设计根据不同领域的数据形态和任务要求而有所不同。Transformer是PFMs在NLP和CV等许多领域的主流模型架构设计。训练大型模型需要有各种数据集进行模型预训练。在训练PFMs之后,需要对模型进行微调,以满足如效率和隐私等下游需求。
PFMs的具体设计根据不同领域的数据形态和任务要求而有所不同。Transformer是PFMs在NLP和CV等许多领域的主流模型架构设计。训练大型模型需要有各种数据集进行模型预训练。在训练PFMs之后,需要对模型进行微调,以满足如效率和隐私等下游需求。
Transformer模型的原理大家应该都比较熟悉了。Transformer因能捕获输入序列数据中的长期依赖,且可扩展性强,能实现高度并行化而被广泛应用于PFMs。如NLP中的GPT-3、CV中的ViT和GL(图学习)中的GTN模型。
在预训练和微调的方案中,模型的参数是在预先设定的任务上训练的,以捕捉特定的属性、结构等信息。 预训练的特征可以帮助下游任务,提供足够的信息,并加速模型的收敛。
近年用于文本领域的PFMs汇总:
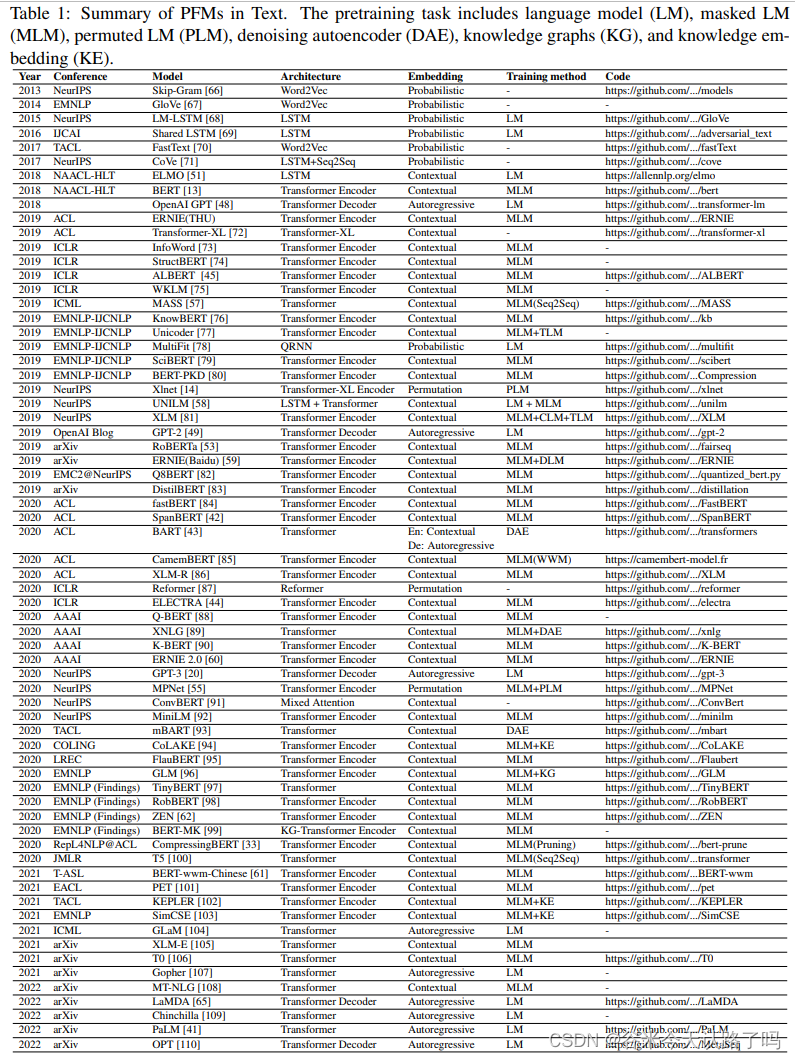
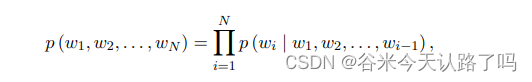
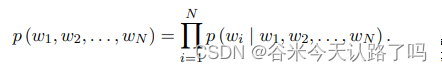
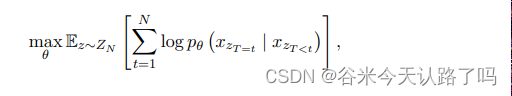
ELMO:主体采用双向的LSTM,相比于词向量方法,ELMO引入了上下文信息,改善了一词多义问题,但ELMO提取语言特征的整体能力较弱。
BERT:基于fine-tuning的PFMs典型代表。BERT使用Transformer的双向encoder来预测哪些token被mask,并确定两个句子是否上下文相关。然而,对文档进行双向编码和独立预测缺失token,降低了模型的生成能力
GPT:基于zero/few-shot prompts的PFMs的典型代表。GPT使用自回归解码器作为特征提取器,根据前几个单词预测下一个单词,并使用微调解决下游任务,因此它更适合文本生成任务。然而,GPT仅利用前一个词进行预测,无法学习双向交互信息。
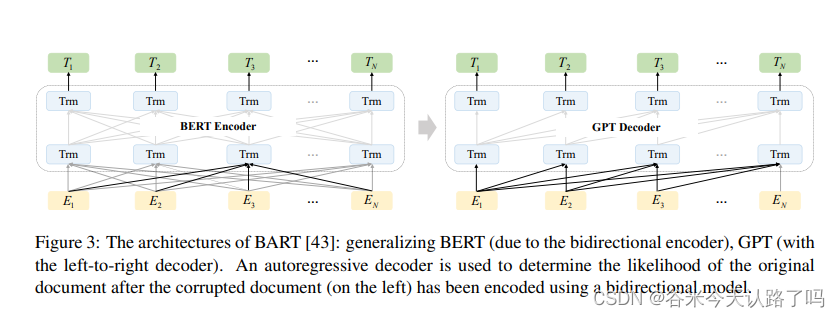
BART:使用encoder-decoder结构构成的降噪自编码器,预训练主要包括使用噪声破坏文本和使用seq2seq模型重建原始文本。具体见我的blog
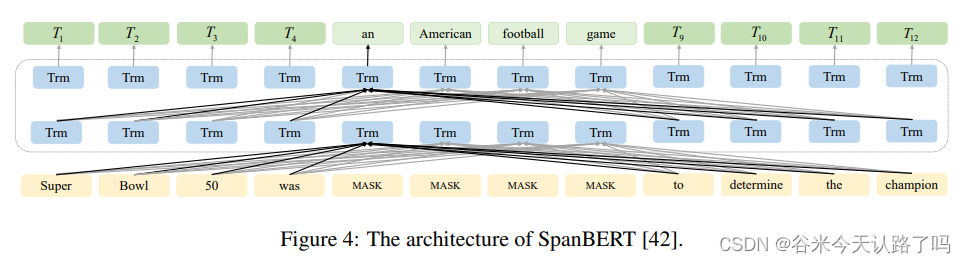
SpanBERT:基于RoBERTA提出的预训练模型,采用动态mask和single segment pretraining。其结构如图4所示,SpanBERT提出了Span mask和Span Boundary Objective(SBO)策略去mask一定长度的单词。SBO的目标是通过mask的span的两端来重构被mask的span;训练阶段使用RoBERTa提出的动态掩码策略,而不是在数据预处理的时候进行掩码。与BERT不同的是,SpanBERT随机地掩盖了连续文本并添加了SBO训练目标。它使用最接近span边界的tokens来预测跨度,并取消了NSP预训练任务。
MASS:对句子随机屏蔽一个长度为k的连续片段,然后通过编码器-注意力-解码器模型预测生成该片段。
UniLM:输入两句。第一句采用BiLM的编码方式,第二句采用单向LM的方式。同时训练encoder(BiLM)decoder(Uni-LM)。处理输入时同样也是随机mask掉一些token。
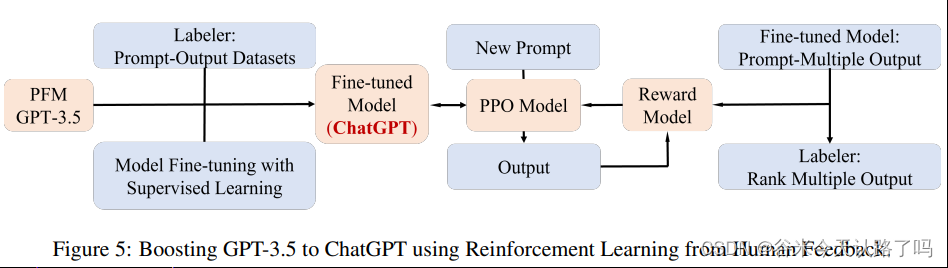
指示对齐方法的目的是让LM遵循人类的意图并产生有意义的输出。大致思路就是以有监督的方式得到高质量语料,去微调预训练LM。如:Supervised Fine-Tuning (SFT) 、Reinforcement Learning from Feedback、Chain-of-Thoughts (CoT)
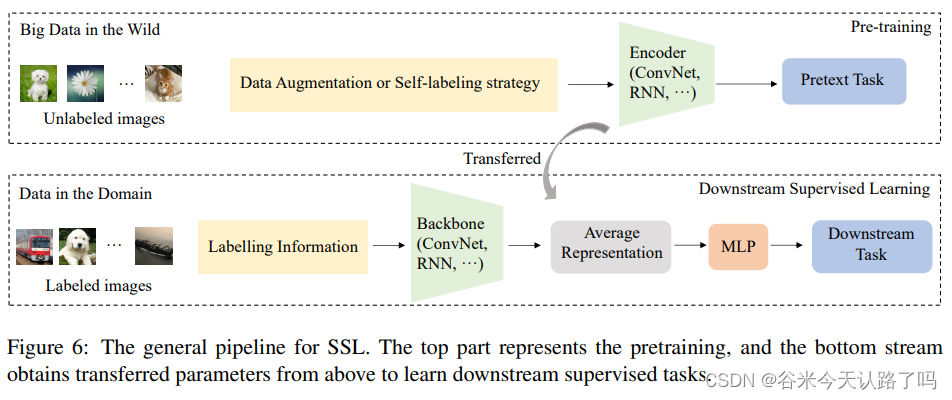
在CV领域基本采用自监督学习(SSL)的方式来训练,如上图所示。CV中的预训练任务被称为代理任务(pretext task),代理任务的数据标签是根据数据的特定属性自动生成的,例如来自同一来源的图像块被标记为“正”,来自不同来源的图像块被标记为“负”。然后,通过监督学习方法训练编码器网络以解决代理任务;由于浅层提取边缘、角度和纹理等细粒度细节,而较深的层捕获与任务相关的高层特征,如语义信息或图像内容,在代理任务中学习到的编码器可以迁移到下游的监督任务。在此阶段,骨干网络的参数是固定的,只需要学习一个简单的分类器,如两层多层感知器(MLP)。下游任务的训练过程通常被称为微调。总之,在SSL预训练阶段学习到的表示可以在其他下游任务上重用,并取得不错结果。
近年用于CV领域的PFMs汇总
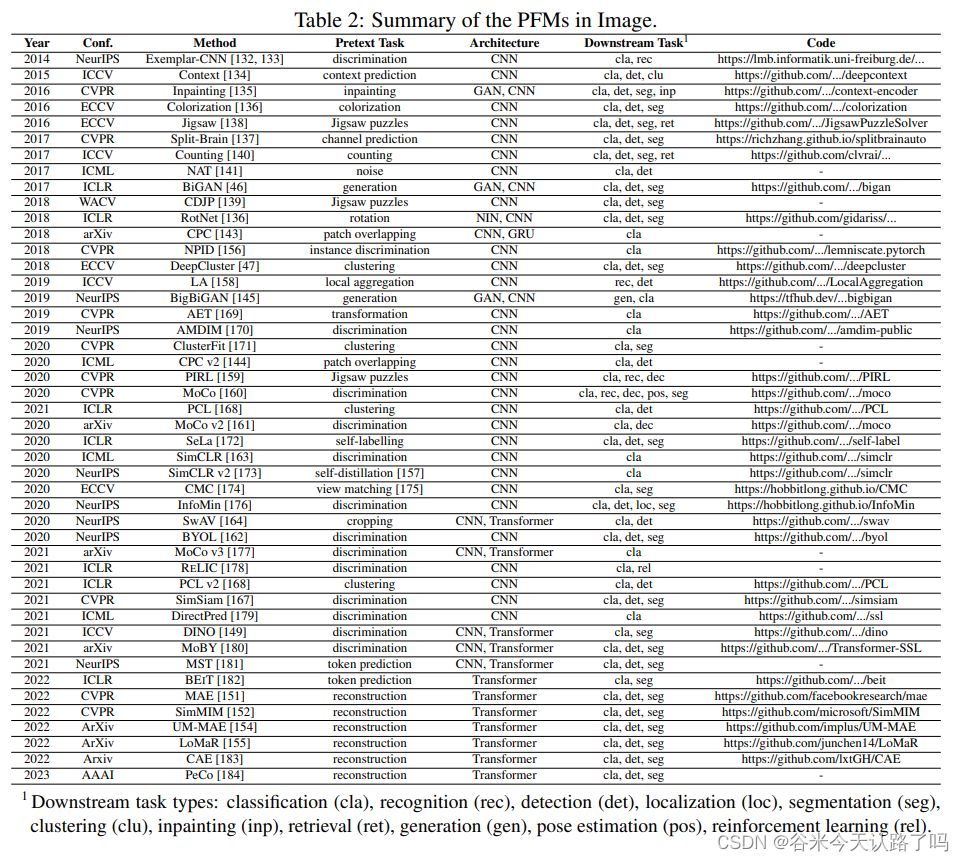
五花八门的pretext task设计,综述里写的比较琐碎,因此找了一些参考资料了解。

序列数据(如视频)的学习总是涉及到时间步的帧处理,因此可以设置能够学习视觉时间表示的代理任务。如Contrastive Predictive Coding (CPC)模型。
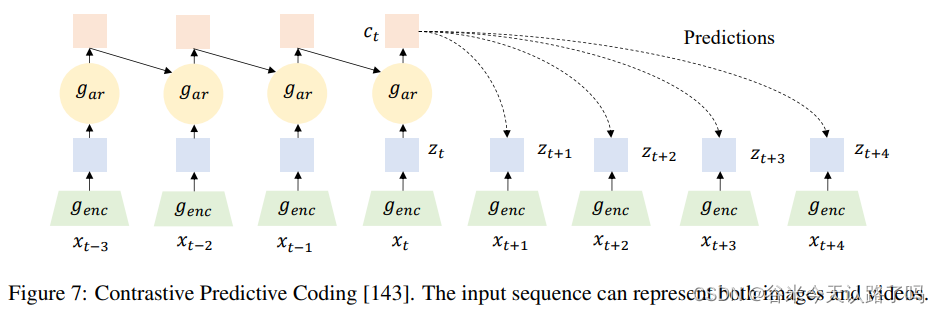
CPC模型的原理介绍
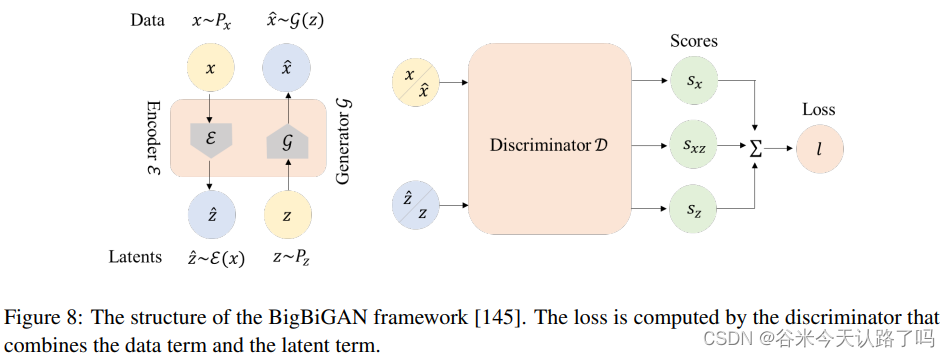
为GAN添加feature encoder以提升生成图像的质量。如BigBiGAN
如ViT(视觉的Transformer)、BEiT(视觉的Bert)、MAE等等
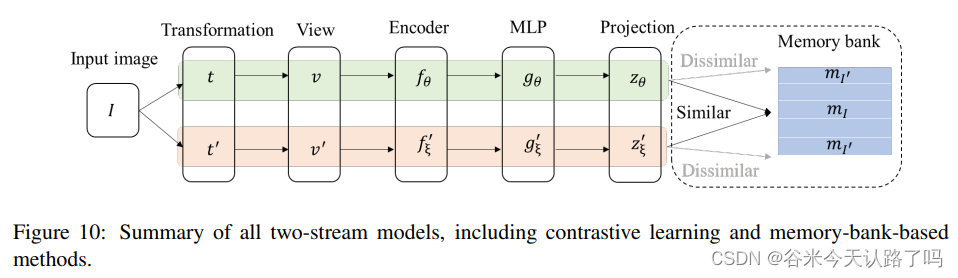
SSL倾向于使用两个编码器网络来进行不同的数据增强,然后通过最大化负对之间的距离或最小化正对之间的距离来预训练参数。从编码器共享参数的角度,可将SSL分为软共享和硬共享两类。
Soft Sharing. 软共享的两个编码器共享相似但不相同的参数,即fθ != f’ξ 。
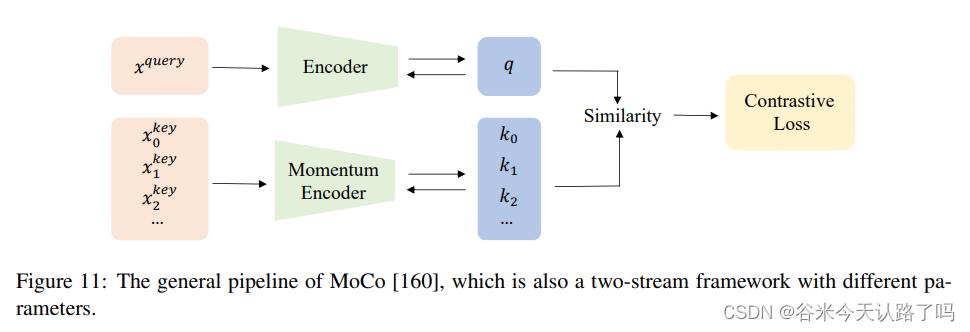
如MoCo、BYOL、PCL
Hard Sharing. 硬共享的两个编码器具有相同的结构和参数,即fθ = f’ξ
如SimCLR、SwAV、SEER等
将表征聚类到不同的簇中,并将这些簇标记为监督信号(伪标签),以预训练骨干网络的参数。如DeepCluster、SwAV、PCL
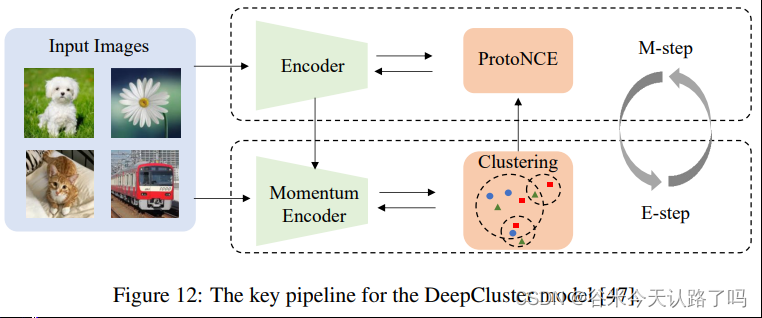
CV方向的PFMs之前都没太了解过,读完这个部分后,感觉几个核心关键词就是自监督学习、对比学习、正负样本对的构造这样的,其他的就是一些细节和针对特定下游任务的改进,很多模型的思想与NLP中的PFMs相似,如ViT、SimCLR等等。以后如果工作中碰到相关问题再去调研和学习一番吧。
近年来的研究开始关注图自身属性、拓扑结构、社区等内在信息,以增强节点自身所承载特征的有效性。
近期用于图学习的PFMs如下表所示:
基于图信息补全的预训练(GIC)的本质动机是对输入图数据的部分信息进行掩码,并基于未掩码的图数据恢复掩码信息,从而对图嵌入进行预训练。
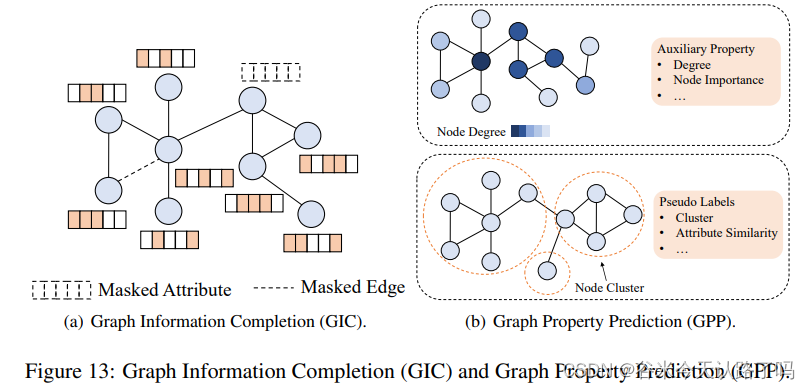
如GraphCompetion, AttributeMask,EdgeMask, PFM都用的SSL训练。
图的一致性分析(GCA)主要探索图中两个元素分布的一致性。具体来说,两个语义相似的元素的一致性应该显著强于两个语义不相关的元素,该特性可以用于图模型的预训练。对于一致性评估可分为以下三个方面:
随机游走是获取图中节点的局部上下文信息的典型方法,通过设计多种游走策略,能捕捉上下文中不同方面的分布特征。因此也被应用于DeepWalk和node2vec中。
近期的方法如LINE直接考虑节点的k阶邻居分布(正例)和非相邻节点(负例)之间的关系,并以此来训练图模型;VGAE将输入图的邻接矩阵和节点的特征矩阵喂入编码器(图卷积网络)学习节点低维向量表示的均值和方差,然后用解码器(链路预测)生成图。
将图的属性和结构信息作为信息补全的目标,学习图数据中的辅助属性来生成自监督信号,并将图属性预测任务作为图模型的预训练任务。根据代理任务的不同设置,可以大致分为属性回归和属性分类两类。
如MAGE, GMAE, MaskGAE, HGMAE等等。
这块就简单过一下了…
Wav2vec, vq-wav2vec, SpeechBERT, SPLAT
O3N, IIC, TCP, SeCO
文本和图像之间的多模态PFM可以分为单流模型和跨流模型两类。单流模型是指在模型一开始就整合文本信息和视觉信息;跨流模型是指分别由两个独立的编码模块编码的文本信息和视觉信息,然后利用互注意力机制融合不同模态信息。
多模态任务下的预训练模型。
从模型效率(model efficiency)和模型压缩(model compression)两方面,去化简模型参数和结构,在不影响任务完成度的情况下,降低预训练模型对内存和计算资源的消耗,提高计算效率。
比如ELECTRA,设置了Replaced Token Detection(RTD)任务让判别器预哪个token被替换过。这样ELECTRA就能训练到全部输入的token。
略
略
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我怀念ipython的一件事是它有一个?为特定功能挖掘文档的运算符。我知道ruby有一个类似的命令行工具,但是我在irb中调用它非常不方便。ruby/irb有类似的东西吗? 最佳答案 Pry是IPython的Ruby版本,它支持?命令来查找有关方法的文档,但语法略有不同:pry(main)>?File.dirnameFrom:file.cinRubyCore(CMethod):Numberoflines:6visibility:publicsignature:dirname()Returnsallcomponentsofthef
我经常使用嵌套数据结构,很多时候我必须从控制台手动分析它们。问题是它们全部打印在一行中。是否有一种简单的方法可以根据{,[,],}和逗号重新构造数据结构的显示,使其看起来像Ruby的pretty_print输出? 最佳答案 :%s/\([{,]\)/\1\r/gggVG=:setft=ruby呜呜呜 关于ruby-如何将Vim中的"expand"文本转换成一种易于阅读的方式?,我们在StackOverflow上找到一个类似的问题: https://stacko
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
我正在使用Watir进行自动化,它会创建一封我需要检查的电子邮件。有人指出电子邮件gem是执行此操作的最简单方法。我添加了以下代码,并且能够从我的收件箱中收到第一封电子邮件。require'mail'require'openssl'Mail.defaultsdoretriever_method:pop3,:address=>"email.someemail.com",:port=>995,:user_name=>'domain/username',:password=>'pwd',:enable_ssl=>trueendputsMail.first我是这个论坛的新手,有以下问题:如何获
我正在用Ruby编写类似curses的程序,我正在使用stty和ansi转义字符来实现我想要的。当我想获得用户输入时,我的问题就出现了。像许多基于控制台的程序一样,我想从终端底部获取用户输入。因此,我将光标放在屏幕底部并调用Readline.readline(或任何获取用户输入的方法)。像往常一样,它会读取所有内容,直到我按下回车键,并打印一个换行符。由于光标位于终端的最后一行,它会滚动一行,这会弄乱屏幕。我怎样才能避免这种情况?我试图使用stty来停止回显换行符,但我没有成功。也许可以使用stty来阻止终端滚动?当然,我可以编写自己的方法来通过一次读取一个字符(并捕获“返回”)来捕获
我想以编程方式访问Railssessionsecret(我正在使用它来生成登录token)。这是我想出的:ActionController::Base.session.first[:secret]这将返回sessionsecret。但是,每次调用ActionController::Base.session时,它都会向数组中添加另一个条目,因此您最终会得到如下内容:[{:session_key=>"_new_app_session",:secret=>"totally-secret-you-guys"},{},{},{},{},{},{},{},{},{},{},{},{}]我觉得这不太
当我将以下文本粘贴到在ruby-enterprise-2011.03下运行的IRB或PRY时,需要13秒。#Loremipsumdolorsitamet,consecteturadipisicingelit,seddoeiusmodtemporincididuntutlaboreetdoloremagnaaliqua.在同一台计算机上运行irb和其他ruby安装时,粘贴并不慢。jruby-1.5.6jruby-1.6.3ruby-1.8.6-p420ruby-1.8.7-p352ruby-1.9.1-p431ruby-1.9.2-p290ruby-1.9.3-preview1o
当您开始处理现有的Rails项目时,您采取了哪些步骤来理解代码?你从哪里开始?在深入了解Controller、模型、助手和View之前,您使用什么来获得高级View?您是否有任何特定的技术、技巧或工具可以帮助加快该过程?请不要回复“学习Rails和Ruby”(就像问这个问题的lastguy的回复之一——他的问题也没有得到太多回复,所以我想我会再问一次并提示多一点)。我对自己的代码很满意。它正在对其他人进行分类,这让我很头疼,需要很长时间才能理解。 最佳答案 看看模型。如果应用程序编写得很好,这应该为您提供其域模型的图片,这是有趣的逻