最近想学习如何使用hdfs来存储文件,在网上学习了一下,明确了HDFS(Hadoop Distribute File System 分布式存储)、mapReduce(分布式计算)、YARN(Yet Another Resource Negotiator资源管理)是hadoop的三大组成部分,要想使用hdfs,必须搭建hadoop集群,为此展开了近一个星期的摸索。
网上的教程有很多,但很多都写的不全,自己也是一直踩坑,无奈之下只好对着官方文档一个个看,逐渐理解并明确了部署方法,在经过反复测试确保正常之后,决定在此记录一下,以便与大家交流分享。
hadoop版本不同,配置的内容也不同,本文使用的是hadopp-3.3.2,同样适用3的其他版本,安装包链接见2.1节
只为测试学习,节点不用太多,计划使用3个节点,即构建3个docker容器,1个namenode节点,2个datanode节点,其中1个datanode作为second namenode
hadoop集群要求节点具有固定的hostname和ip,在此做如下规划:
namenode的hostname为master,ip为192.168.0.10
第1个datanode的hostname为slave1,ip为192.168.0.11
第2个datanode的hostname为slave2,ip为192.168.0.12
hadoop集群提供了网页管理界面,主要包括hdfs(文件系统)、cluster(集群)、jobhistory(历史任务)三大部分,每个部分都有访问的端口号。通过查阅官方文档确认了默认的端口号分别为9870、8088、19888,我们直接使用这些默认的端口号

hadoop-3.3.2.tar.gz
jdk-8u321-linux-x64.tar.gz hadoop需要java的环境,此包下载需要oracle账号,没有账号的可以免费注册,如果有使用M1 MacOS系统的请下载aarch64版本的
构建镜像我们使用Dockerfile,注意这个文件的内容大家可以根据自己的情况修改,如
镜像源:使用centos7,大家可以换
LABEL:元数据这里列了作者和日期,大家可以改成自己的信息
ssh:用于节点直接相互访问用
which:hadoop命令执行需要which,不然会报错
jdk:不是8u321版本的,可以修改下面这两行中的版本信息
ADD jdk-8u321-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_321 /usr/local/jdk1.8
hadoop:不是3.3.2版本的,可以修改下面这两行中的版本信息
ADD hadoop-3.3.2.tar.gz /usr/local
RUN mv /usr/local/hadoop-3.3.2 /usr/local/hadoop
下面是完整的文件内容
# 镜像源
FROM centos:7
# 添加元数据
LABEL author="hjq" date="2022/03/05"
# 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
# 安装openssh-clients
RUN yum install -y openssh-clients
# 安装which
RUN yum install -y which
# 添加测试用户root,密码root,并且将此用户添加到sudoers里
RUN echo "root:root" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 启动sshd服务并且暴露22端口
RUN mkdir /var/run/sshd
EXPOSE 22
# 拷贝并解压jdk,根据自己的版本修改
ADD jdk-8u321-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_321 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
# 拷贝并解压hadoop,根据自己的版本修改
ADD hadoop-3.3.2.tar.gz /usr/local
RUN mv /usr/local/hadoop-3.3.2 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
# 设置容器启动命令
CMD ["/usr/sbin/sshd", "-D"]
在本地新建一个自定义名称的文件夹,将上述的Dockerfile、hadoop-3.3.2.tar.gz、jdk-8u321-linux-x64.tar.gz拷贝到该文件夹下,然后使用终端进入该目录,并运行docker build -t hadoop-test .别忘了后面的.
等待运行结束,包含ssh、jdk、hadoop的镜像就构建完成了
我们先用上述构建好的镜像运行一个测试容器,在此容器中配置好参数后,保存为新的镜像,这样以后构建node容器就不用重新配置了
docker run -d --name hadoop-test hadoop-testdocker exec -it hadoop-test bashcd /usr/local/hadoop/etc/hadoop/vi hadoop-env.shexport HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/usr/local/jdk1.8
vi core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
vi hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
</configuration>
vi yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
</configuration>
vi mapred-site.xml0.0.0.0:10020,可按需修改0.0.0.0:19888,可按需修改<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
vi workers hadoop2配置的slaves,这是2与3的一大差别slave1
slave2
docker commit hadoop-test hadoop:base有了上述配置好的hadoop镜像,我们可以快速构建 node 容器
之前说过,hadoop要求节点具有固定ip,docker可以通过network为容器配置固定ip
docker network create --subnet=192.168.0.0/24 hadoop
其中24表示ip的前24位为固定,后8为可用,即192.168.0.1-192.168.0.254可用,hadoop为network的名称,此部分可按需修改
分别运行如下命令构建master、slave1、slave2三个容器,其中–hostname用于设置node的主机名称,–ip用于配置固定ip
我们为master绑定8088、9870、19888端口号,便于在本地访问
需要注意的是,我们在构建镜像时为容器设置了启动命令CMD ["/usr/sbin/sshd", "-D"](Dockerfile最后一行,使容器启动时自动启动ssh服务),所以不要使用docker run -itd来构建容器,否则会被后面自定义的命令(如bash)替换,导致ssh未启动,从而出现22端口无法访问的问题
docker run -d --name master --hostname master --network hadoop --ip 192.168.0.10 -P -p 8088:8088 -p 9870:9870 -p 19888:19888 hadoop:base
docker run -d --name slave1 --hostname slave1 --network hadoop --ip 192.168.0.11 -P hadoop:base
docker run -d --name slave2 --hostname slave2 --network hadoop --ip 192.168.0.12 -P hadoop:base
进入master容器 docker exec -it master bash
生成密钥 ssh-keygen 一直回车就行
将密钥分发给其他node,此过程需要输入 yes 和 密码(Dockerfile里设置的是root)
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
进入其他datanode节点做上述同样的操作
ok,终于全都配置好了,回到master容器去启动服务
hdfs namenode -format注意,第一次格式化就行,以后慎用,格式化会导致namenode的clusterID和datanode的clusterID不一致,以致datanode无法启动$HADOOP_HOME/sbin/start-all.sh$HADOOP_HOME/bin/mapred --daemon start historyserverjps,master节点有如下服务表示正常
slave1、slave2容器,运行 jps,slave节点有如下服务表示正常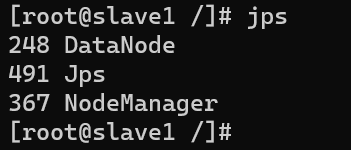
如果需要关闭服务,可执行以下命令
$HADOOP_HOME/bin/mapred --daemon stop historyserver$HADOOP_HOME/sbin/stop-all.shvi test.txt,随便输入一些字符,并保存退出hdfs dfs -put test.txt /hadoop fs -ls /,可以看到文件已保存到hdfs
localhost:9870,并在Utilities中点击Browse the file system,即可看到文件存储情况,网址端口号根据自己的配置来
cd $HADOOP_HOME/share/hadoop/mapreducehadoop jar hadoop-mapreduce-examples-3.3.2.jar pi 3 100 调用jar包计算pi的值,计算100次(根据自己的hadoop版本修改命令)localhost:8088,可以查看任务情况以及日志等,网址端口号根据自己的配置来
localhost:19888,网址端口号根据自己的配置来
写了一晚上终于写完了,最近一周没算白忙活,后面还得继续深入学习,加油~
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n
我想要像“嘿那里”这样的东西变成,例如,#316583。我希望将任意长度的字符串“归结”为十六进制颜色。我不知道从哪里开始。我在想,每个字符串的MD5散列都是不同的-但如何将该散列转换为十六进制颜色数字? 最佳答案 你可以只取几位前几位:require'digest/md5'color=Digest::MD5.hexdigest('Mytext')[0..5] 关于ruby-如何使用Ruby基于字母数字字符串生成颜色?,我们在StackOverflow上找到一个类似的问题:
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
我正在尝试使用docker运行一个Rails应用程序。通过github的sshurl安装的gem很少,如下所示:Gemfilegem'swagger-docs',:git=>'git@github.com:xyz/swagger-docs.git',:branch=>'my_branch'我在docker中添加了keys,它能够克隆所需的repo并从git安装gem。DockerfileRUNmkdir-p/root/.sshCOPY./id_rsa/root/.ssh/id_rsaRUNchmod700/root/.ssh/id_rsaRUNssh-keygen-f/root/.ss