go-zero docker-compose 搭建课件服务(九):http统一返回和集成日志服务
https://github.com/liuyuede123/go-zero-courseware
一般返回中会有code,message,data。当请求成功的时候code返回0或者200,message返回success,data为要获取的数据;当请求失败的时候code返回自定义的错误码,message返回展示给前端的错误信息,data为空。
我们将封装一个错误返回的函数,应用到api handler的返回
在user服务中创建了common文件夹,里面存一些公用的方法,创建response/response.go
package response
import (
"go-zero-courseware/user/common/xerr"
"net/http"
"github.com/pkg/errors"
"github.com/zeromicro/go-zero/core/logx"
"github.com/zeromicro/go-zero/rest/httpx"
"google.golang.org/grpc/status"
)
type Response struct {
Code uint32 `json:"code"`
Message string `json:"message"`
Data interface{} `json:"data"`
}
//http返回
func HttpResult(r *http.Request, w http.ResponseWriter, resp interface{}, err error) {
if err == nil {
//成功返回
r := &Response{
Code: 0,
Message: "success",
Data: resp,
}
httpx.WriteJson(w, http.StatusOK, r)
} else {
//错误返回
errcode := uint32(500)
errmsg := "服务器错误"
causeErr := errors.Cause(err) // err类型
if e, ok := causeErr.(*xerr.CodeError); ok { //自定义错误类型
//自定义CodeError
errcode = e.GetErrCode()
errmsg = e.GetErrMsg()
} else {
if gstatus, ok := status.FromError(causeErr); ok { // grpc err错误
grpcCode := uint32(gstatus.Code())
errcode = grpcCode
errmsg = gstatus.Message()
}
}
logx.WithContext(r.Context()).Errorf("【API-ERR】 : %+v ", err)
httpx.WriteJson(w, http.StatusBadRequest, &Response{
Code: errcode,
Message: errmsg,
Data: nil,
})
}
}
创建xerr/errors.go文件,定义CodeError结构体
package xerr
import (
"fmt"
)
/**
常用通用固定错误
*/
type CodeError struct {
errCode uint32
errMsg string
}
//返回给前端的错误码
func (e *CodeError) GetErrCode() uint32 {
return e.errCode
}
//返回给前端显示端错误信息
func (e *CodeError) GetErrMsg() string {
return e.errMsg
}
func (e *CodeError) Error() string {
return fmt.Sprintf("ErrCode:%d,ErrMsg:%s", e.errCode, e.errMsg)
}
func NewErrCodeMsg(errCode uint32, errMsg string) *CodeError {
return &CodeError{errCode: errCode, errMsg: errMsg}
}
由于api一般调用的rpc的请求,获取到的错误无法展示给前端使用,我们会使用自定义的错误类型。当让rpc中的错误也可能是前端直接可以展示的错误,或者是数据库的某个异常抛出的错误,如果想区分这些错误,可以自己定义业务端code和message做下区分就行。这里我们统一api服务中处理。
当api或者rpc中有一些未知错误抛出的时候我们需要写入到日志中,包括具体的错误信息和堆栈信息。这些后续放到日志服务ELK中可以方便查看。
修改userinfohandler.go、userloginhandler.go、userregisterhandler.go中的返回
...
response.HttpResult(r, w, resp, err)
修改userinfologic.go
...
func (l *UserInfoLogic) UserInfo(req *types.UserInfoRequest) (resp *types.UserInfoResponse, err error) {
info, err := l.svcCtx.UserRpc.UserInfo(l.ctx, &userclient.UserInfoRequest{
Id: req.Id,
})
if err != nil {
// 自定义的错误返回
return nil, xerr.NewErrCodeMsg(500, "用户查询失败")
}
return &types.UserInfoResponse{
Id: info.Id,
Username: info.Username,
LoginName: info.LoginName,
Sex: info.Sex,
}, nil
}
修改userloginlogic.go
...
func (l *UserLoginLogic) UserLogin(req *types.LoginRequest) (resp *types.LoginResponse, err error) {
login, err := l.svcCtx.UserRpc.Login(l.ctx, &userclient.LoginRequest{
LoginName: req.LoginName,
Password: req.Password,
})
if err != nil {
return nil, xerr.NewErrCodeMsg(500, "用户登录失败")
}
now := time.Now().Unix()
login.Token, err = l.getJwtToken(l.svcCtx.Config.Auth.AccessSecret, now, l.svcCtx.Config.Auth.AccessExpire, int64(login.Id))
if err != nil {
// 返回错误信息,并打印堆栈信息到日志
return nil, errors.Wrapf(xerr.NewErrCodeMsg(5000, "token生成失败"), "loginName: %s,err:%v", req, err)
}
return &types.LoginResponse{
Id: login.Id,
Token: login.Token,
}, nil
}
...
修改userregisterlogic.go
...
func (l *UserRegisterLogic) UserRegister(req *types.RegisterRequest) (resp *types.RegisterResponse, err error) {
_, err = l.svcCtx.UserRpc.Register(l.ctx, &userclient.RegisterRequest{
LoginName: req.LoginName,
Username: req.Username,
Password: req.Password,
Sex: req.Sex,
})
if err != nil {
// 自定义的错误返回
return nil, xerr.NewErrCodeMsg(5000, "注册用户失败")
}
return &types.RegisterResponse{}, nil
}
关于errors.Wrapf
第一个参数是错误信息,第二个是格式化之后的错误信息字符串,args是fromat中的动态参数。最终还是返回我们传入的error,但是会把堆栈信息也打印出来。这个为后面的日志服务做铺垫
func Wrapf(err error, format string, args ...interface{}) error {
if err == nil {
return nil
}
err = &withMessage{
cause: err,
msg: fmt.Sprintf(format, args...),
}
return &withStack{
err,
callers(),
}
}
关于鉴权
对于鉴权,如果鉴权失败,之前是直接返回401状态码,但是我们想同样的返回错误信息和message
此时就需要自定义一个鉴权失败的回调函数
我们在response.go中增加一个鉴权失败的回调函数
...
func JwtUnauthorizedResult(w http.ResponseWriter, r *http.Request, err error) {
httpx.WriteJson(w, http.StatusUnauthorized, &Response{401, "鉴权失败", nil})
}
然后在api入口程序user.go中修改代码如下
...
func main() {
flag.Parse()
var c config.Config
conf.MustLoad(*configFile, &c)
// 此处加入鉴权失败的回调
server := rest.MustNewServer(c.RestConf, rest.WithUnauthorizedCallback(response.JwtUnauthorizedResult))
defer server.Stop()
ctx := svc.NewServiceContext(c)
handler.RegisterHandlers(server, ctx)
fmt.Printf("Starting server at %s:%d...\n", c.Host, c.Port)
server.Start()
}
然后我们再看下user的rpc服务
这里我们会引入一个拦截器。什么是拦截器?
定义:UnaryServerInterceptor 提供了一个钩子来拦截服务器上一元 RPC 的执行。 信息包含拦截器可以操作的这个 RPC 的所有信息。 处理程序是包装器服务方法实现。 拦截器负责调用处理程序完成 RPC。
其实就是拦截handler做一些返回前和返回后的处理
我们需要在common中新增一个拦截器方法,新建文件rpcserver/rpcserver.go
package rpcserver
import (
"context"
"github.com/pkg/errors"
"github.com/zeromicro/go-zero/core/logx"
"go-zero-courseware/user/common/xerr"
"google.golang.org/grpc"
"google.golang.org/grpc/codes"
"google.golang.org/grpc/status"
)
func LoggerInterceptor(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
resp, err = handler(ctx, req)
if err != nil {
causeErr := errors.Cause(err) // err类型
if e, ok := causeErr.(*xerr.CodeError); ok { //自定义错误类型
logx.WithContext(ctx).Errorf("【RPC-SRV-ERR】 %+v", err)
//转成grpc err
err = status.Error(codes.Code(e.GetErrCode()), e.GetErrMsg())
} else {
logx.WithContext(ctx).Errorf("【RPC-SRV-ERR】 %+v", err)
}
}
return resp, err
}
然后在入口文件user.go中添加一个拦截器
...
s.AddUnaryInterceptors(rpcserver.LoggerInterceptor)
...
课件服务和上面类似,这里就不一一添加修改了
我们需要搭建一个ELK体系的服务,流程图如下:
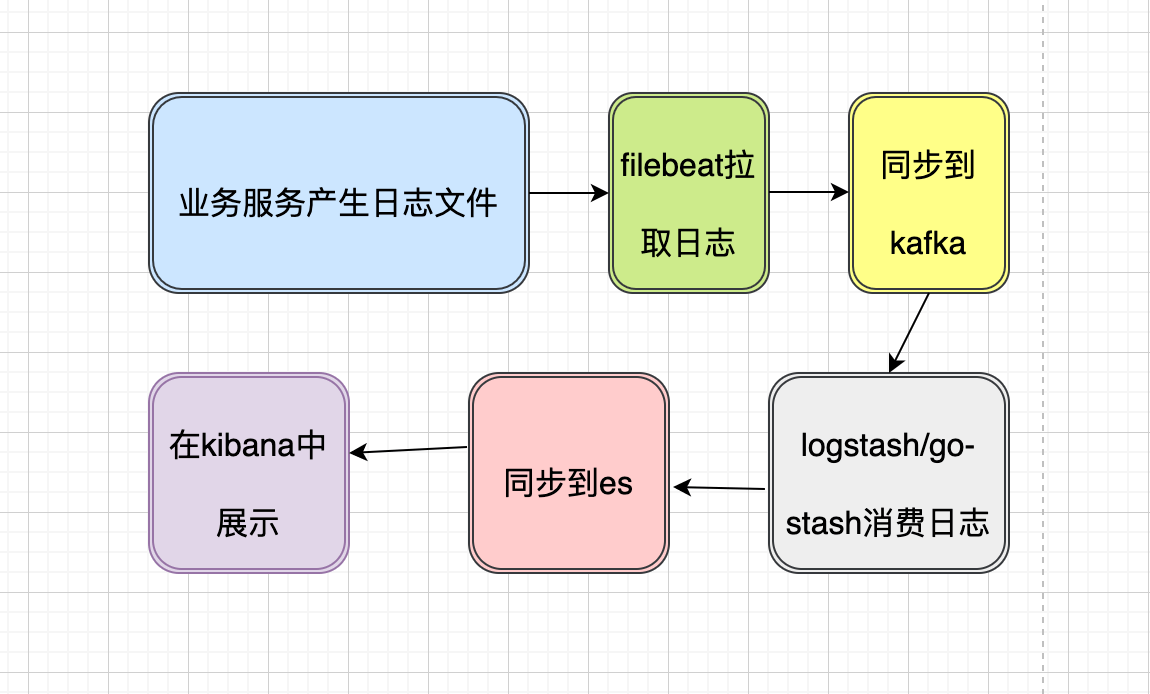
将会用到以下服务:
| 服务名 | 端口号 | |
|---|---|---|
| elasticsearch | 9200 | |
| kibana | 5601 | |
| go-stash | ||
| filebeat | ||
| zookeeper | 2181 | |
| kafka | 9092 |
docker-compose如下:
user服务中我们引入了日志地址,到我们的宿主机上。之所以这样做,是因为在mac系统上docker的日志文件路径和linux上的不一致。找了半天也没在mac上找到容器的日志。所以用户服务中的日志会写到文件中然后同步到宿主机的data/log目录下。
还有就是filebeat日志中,我们会从宿主机上的日志同步到filebeat指定目录。然后filebeat会同步到kafka
version: '3.5'
# 网络配置
networks:
backend:
driver: bridge
# 服务容器配置
services:
etcd: # 自定义容器名称
build:
context: etcd # 指定构建使用的 Dockerfile 文件
environment:
- TZ=Asia/Shanghai
- ALLOW_NONE_AUTHENTICATION=yes
- ETCD_ADVERTISE_CLIENT_URLS=http://etcd:2379
ports: # 设置端口映射
- "2379:2379"
networks:
- backend
restart: always
etcd-manage:
build:
context: etcd-manage
environment:
- TZ=Asia/Shanghai
ports:
- "7000:8080" # 设置容器8080端口映射指定宿主机端口,用于宿主机访问可视化web
depends_on: # 依赖容器
- etcd # 在 etcd 服务容器启动后启动
networks:
- backend
restart: always
courseware-rpc: # 自定义容器名称
build:
context: courseware # 指定构建使用的 Dockerfile 文件
dockerfile: rpc/Dockerfile
environment: # 设置环境变量
- TZ=Asia/Shanghai
privileged: true
ports: # 设置端口映射
- "9400:9400" # 课件服务rpc端口
stdin_open: true # 打开标准输入,可以接受外部输入
tty: true
networks:
- backend
restart: always # 指定容器退出后的重启策略为始终重启
courseware-api: # 自定义容器名称
build:
context: courseware # 指定构建使用的 Dockerfile 文件
dockerfile: api/Dockerfile
environment: # 设置环境变量
- TZ=Asia/Shanghai
privileged: true
ports: # 设置端口映射
- "8400:8400" # 课件服务api端口
stdin_open: true # 打开标准输入,可以接受外部输入
tty: true
networks:
- backend
restart: always # 指定容器退出后的重启策略为始终重启
user-rpc: # 自定义容器名称
build:
context: user # 指定构建使用的 Dockerfile 文件
dockerfile: rpc/Dockerfile
environment: # 设置环境变量
- TZ=Asia/Shanghai
privileged: true
volumes:
- ./data/log/user-rpc:/var/log/go-zero/user-rpc # 日志的映射地址
ports: # 设置端口映射
- "9300:9300" # 课件服务rpc端口
stdin_open: true # 打开标准输入,可以接受外部输入
tty: true
networks:
- backend
restart: always # 指定容器退出后的重启策略为始终重启
user-api: # 自定义容器名称
build:
context: user # 指定构建使用的 Dockerfile 文件
dockerfile: api/Dockerfile
environment: # 设置环境变量
- TZ=Asia/Shanghai
privileged: true
volumes:
- ./data/log/user-api:/var/log/go-zero/user-api
ports: # 设置端口映射
- "8300:8300" # 课件服务api端口
stdin_open: true # 打开标准输入,可以接受外部输入
tty: true
networks:
- backend
restart: always # 指定容器退出后的重启策略为始终重启
elasticsearch:
build:
context: ./elasticsearch
environment:
- TZ=Asia/Shanghai
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
privileged: true
ports:
- "9200:9200"
networks:
- backend
restart: always
prometheus:
build:
context: ./prometheus
environment:
- TZ=Asia/Shanghai
privileged: true
volumes:
- ./prometheus/prometheus.yml:/opt/bitnami/prometheus/conf/prometheus.yml # 将 prometheus 配置文件挂载到容器里
- ./prometheus/target.json:/opt/bitnami/prometheus/conf/targets.json # 将 prometheus 配置文件挂载到容器里
ports:
- "9090:9090" # 设置容器9090端口映射指定宿主机端口,用于宿主机访问可视化web
networks:
- backend
restart: always
grafana:
build:
context: ./grafana
environment:
- TZ=Asia/Shanghai
privileged: true
ports:
- "3000:3000"
networks:
- backend
restart: always
jaeger:
build:
context: ./jaeger
environment:
- TZ=Asia/Shanghai
- SPAN_STORAGE_TYPE=elasticsearch
- ES_SERVER_URLS=http://elasticsearch:9200
- LOG_LEVEL=debug
privileged: true
ports:
- "6831:6831/udp"
- "6832:6832/udp"
- "5778:5778"
- "16686:16686"
- "4317:4317"
- "4318:4318"
- "14250:14250"
- "14268:14268"
- "14269:14269"
- "9411:9411"
networks:
- backend
restart: always
kibana:
build:
context: ./kibana
environment:
- elasticsearch.hosts=http://elasticsearch:9200
- TZ=Asia/Shanghai
privileged: true
ports:
- "5601:5601"
networks:
- backend
restart: always
depends_on:
- elasticsearch
go-stash:
build:
context: ./go-stash
environment:
- TZ=Asia/Shanghai
privileged: true
volumes:
- ./go-stash/go-stash.yml:/app/etc/config.yaml
networks:
- backend
restart: always
depends_on:
- elasticsearch
- kafka
filebeat:
build:
context: ./filebeat
environment:
- TZ=Asia/Shanghai
entrypoint: "filebeat -e -strict.perms=false"
privileged: true
volumes:
- ./filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml
- ./data/log:/var/lib/docker/containers # 宿主机上的日志同步到filebeat指定目录
networks:
- backend
restart: always
depends_on:
- kafka
zookeeper:
build:
context: ./zookeeper
environment:
- TZ=Asia/Shanghai
privileged: true
networks:
- backend
ports:
- "2181:2181"
restart: always
kafka:
build:
context: ./kafka
ports:
- "9092:9092"
environment:
- KAFKA_ADVERTISED_HOST_NAME=kafka
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_AUTO_CREATE_TOPICS_ENABLE=false
- TZ=Asia/Shanghai
- ALLOW_PLAINTEXT_LISTENER=yes
restart: always
privileged: true
networks:
- backend
depends_on:
- zookeeper
(项目根目录下自行创建对应的Dokcerfile)
filebeat需要引入配置文件filebeat.yml如下:
其中filebeat需要从宿主机同步数据,就是上面用户服务中生成的日志文件,会同步到filebeat的对应文件中
拉取过来的文件会输出到kafka指定的topic中,我们这里定义的是courseware-log
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/lib/docker/containers/*/*.log # 此为宿主机同步过来的日志文件
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- add_cloud_metadata: ~
- add_docker_metadata: ~
output.kafka:
enabled: true
hosts: ["kafka:9092"]
#要提前创建topic
topic: "courseware-log"
partition.hash:
reachable_only: true
compression: gzip
max_message_bytes: 1000000
required_acks: 1
用户服务中也需要修改etc下的user.yaml配置,增加日志的配置,输出到data/log目录下
Log:
Mode: file
Path: /var/log/go-zero/user-api
Level: error
Log:
Mode: file
Path: /var/log/go-zero/user-rpc
Level: error
我们启动下相关服务,请求下user-api的接口
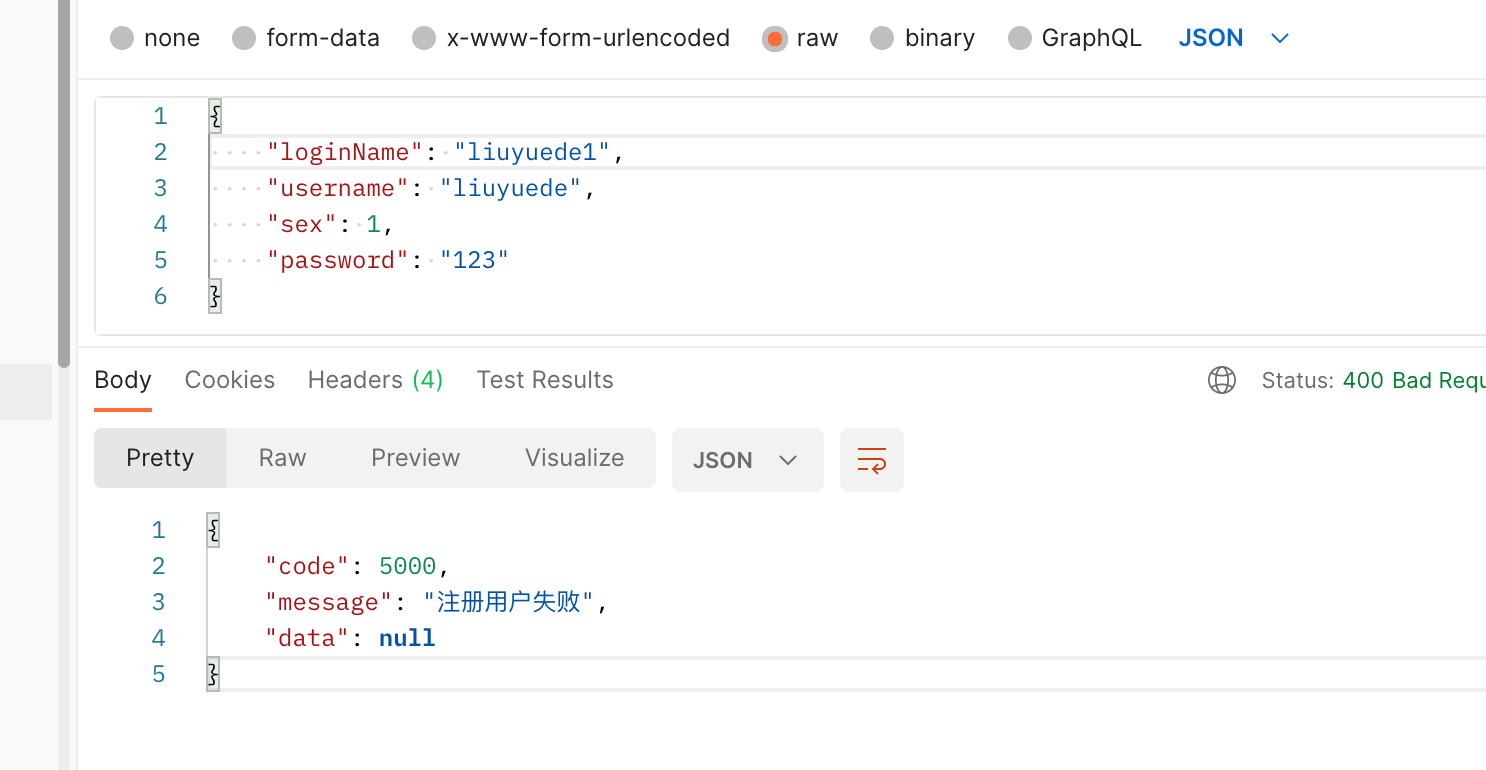
然后回到项目中查看data/log中是否生成相关日志
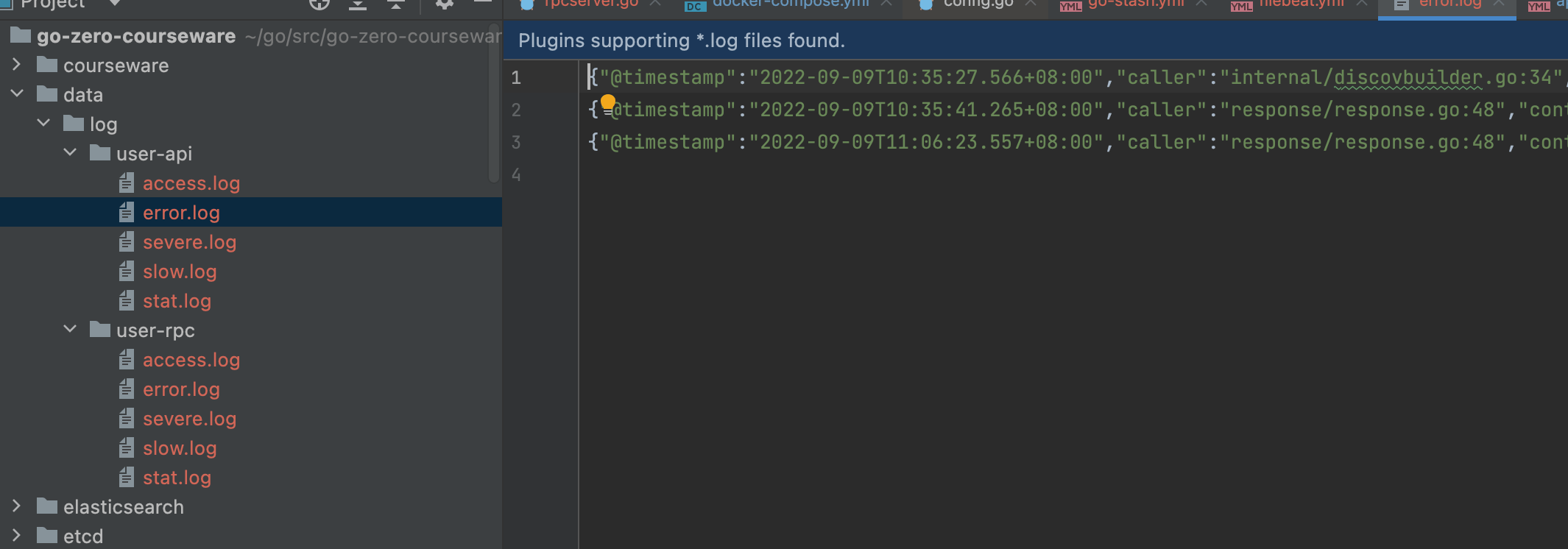
日志正常输出,再到filebeat服务中,查看文件是否同步上去:
# 进入容器
docker exec -it 231bf79f3d5e21cea153bd94bf29693e67360113256e0e3c67a693e727d0b660 /bin/sh
# 查看目录
cd /var/lib/docker/containers
ls
user-api user-rpc
然后我们再到kafka的容器中
# 进入到容器
docker exec -it cb764aeb86e8296a805e47c85f65ac5334c3ed15630fe36e7a39a81ca1bad67f /bin/sh
# 到bin目录下
cd /opt/bitnami/kafka/bin
# 可以看到这些调试脚本
$ ls
connect-distributed.sh kafka-cluster.sh kafka-consumer-perf-test.sh kafka-get-offsets.sh kafka-producer-perf-test.sh kafka-server-stop.sh kafka-verifiable-consumer.sh zookeeper-server-start.sh
connect-mirror-maker.sh kafka-configs.sh kafka-delegation-tokens.sh kafka-leader-election.sh kafka-reassign-partitions.sh kafka-storage.sh kafka-verifiable-producer.sh zookeeper-server-stop.sh
connect-standalone.sh kafka-console-consumer.sh kafka-delete-records.sh kafka-log-dirs.sh kafka-replica-verification.sh kafka-streams-application-reset.sh trogdor.sh zookeeper-shell.sh
kafka-acls.sh kafka-console-producer.sh kafka-dump-log.sh kafka-metadata-shell.sh kafka-run-class.sh kafka-topics.sh windows
kafka-broker-api-versions.sh kafka-consumer-groups.sh kafka-features.sh kafka-mirror-maker.sh kafka-server-start.sh kafka-transactions.sh zookeeper-security-migration.sh
$
先看下有没有创建courseware-log的topic,如果没有就创建一个
$ ./kafka-topics.sh --bootstrap-server kafka:9092 --list
__consumer_offsets
courseware-log
# 没有就创建,创建的命令。最新版的kafka不需要指定zookeeper
./kafka-topics.sh --create --bootstrap-server kafka:9092 --replication-factor 1 --partitions 1 --topic courseware-log
# 建错了删除用这个
./kafka-topics.sh --delete --bootstrap-server kafka:9092 --topic courseware-log
# 发布消息用这个
./kafka-console-producer.sh --broker-list kafka:9092 --topic courseware-log
# 消费用这个
./kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic courseware-log --from-beginning
我们执行消费脚本看下日志会不会过来。

现在还没有日志进来,我们请求一下接口让接口报错,可以看到日志开始消费了
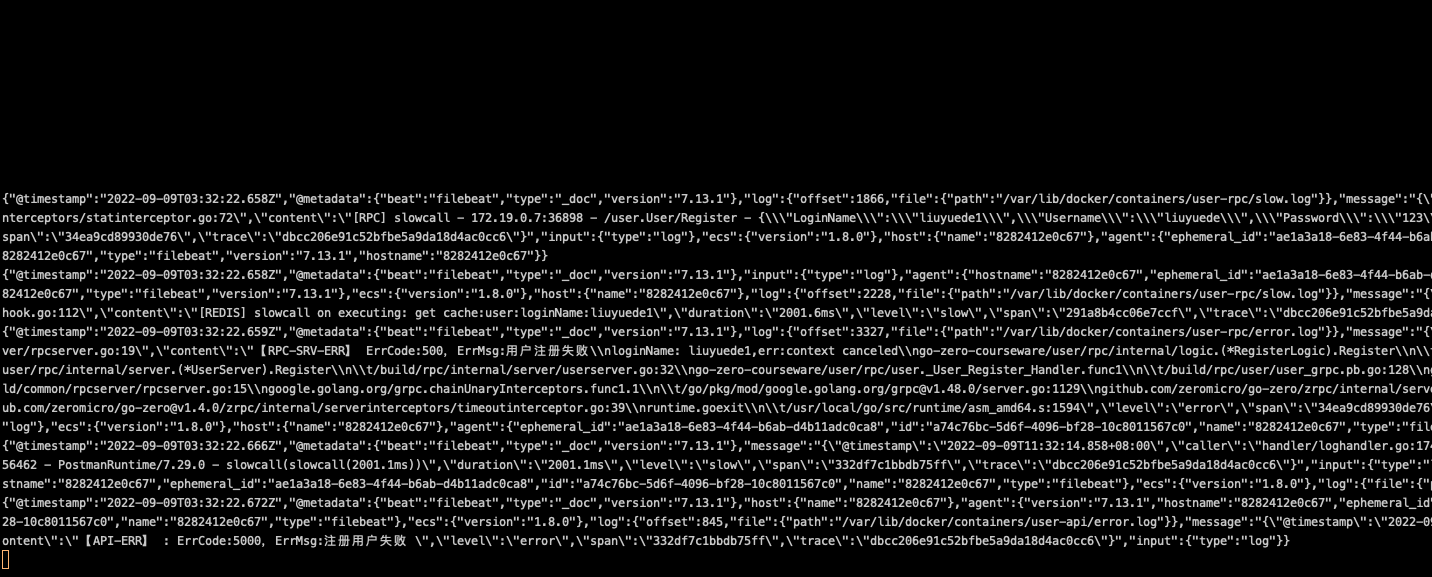
到这里日志已经流转到kafka中了。
下面是go-stash从kafka拉取日志处理并保存到elasticsearch的流程:
go-stash需要引入配置文件go-stash.yml,内容如下:
参数可参考github go-stash
Clusters:
- Input:
Kafka:
Name: go-stash
Brokers:
- "kafka:9092"
Topics:
- courseware-log
Group: pro
Consumers: 16
Filters:
- Action: drop
Conditions:
- Key: k8s_container_name
Value: "-rpc"
Type: contains
- Key: level
Value: info
Type: match
Op: and
- Action: remove_field
Fields:
# - message
- _source
- _type
- _score
- _id
- "@version"
- topic
- index
- beat
- docker_container
- offset
- prospector
- source
- stream
- "@metadata"
- Action: transfer
Field: message
Target: data
Output:
ElasticSearch:
Hosts:
- "http://elasticsearch:9200"
Index: "courseware-{{yyyy-MM-dd}}"
问题:
但是这里mac上又遇到一个问题就是对接go-stash时mac上的docker中会报错
2022/09/08 21:51:10 {"@timestamp":"2022-09-08T21:51:10.346+08:00","level":"error","content":"cpu_linux.go:29 open cpuacct.usage_percpu: no such file or directory"}
具体可以看这里https://github.com/zeromicro/go-zero/issues/311 还没有找到好的解决办法。
后续:
之后又重启了下docker发现问题解决了,同步到es生效了。
接下来我们请求下用户服务的接口,到es查看,索引已经创建,错误信息已经写进去了
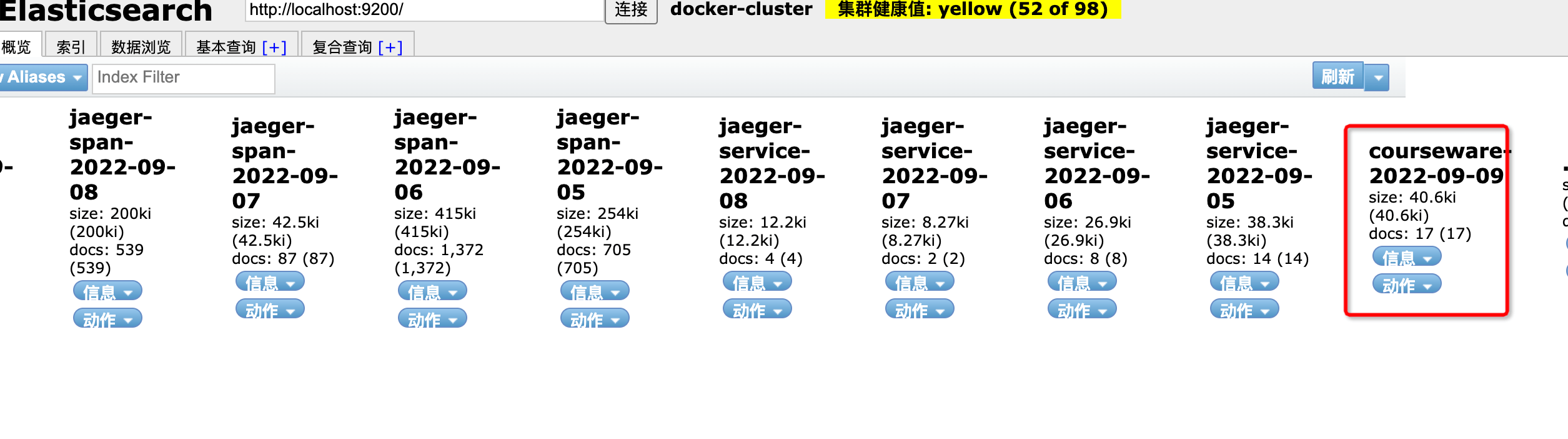
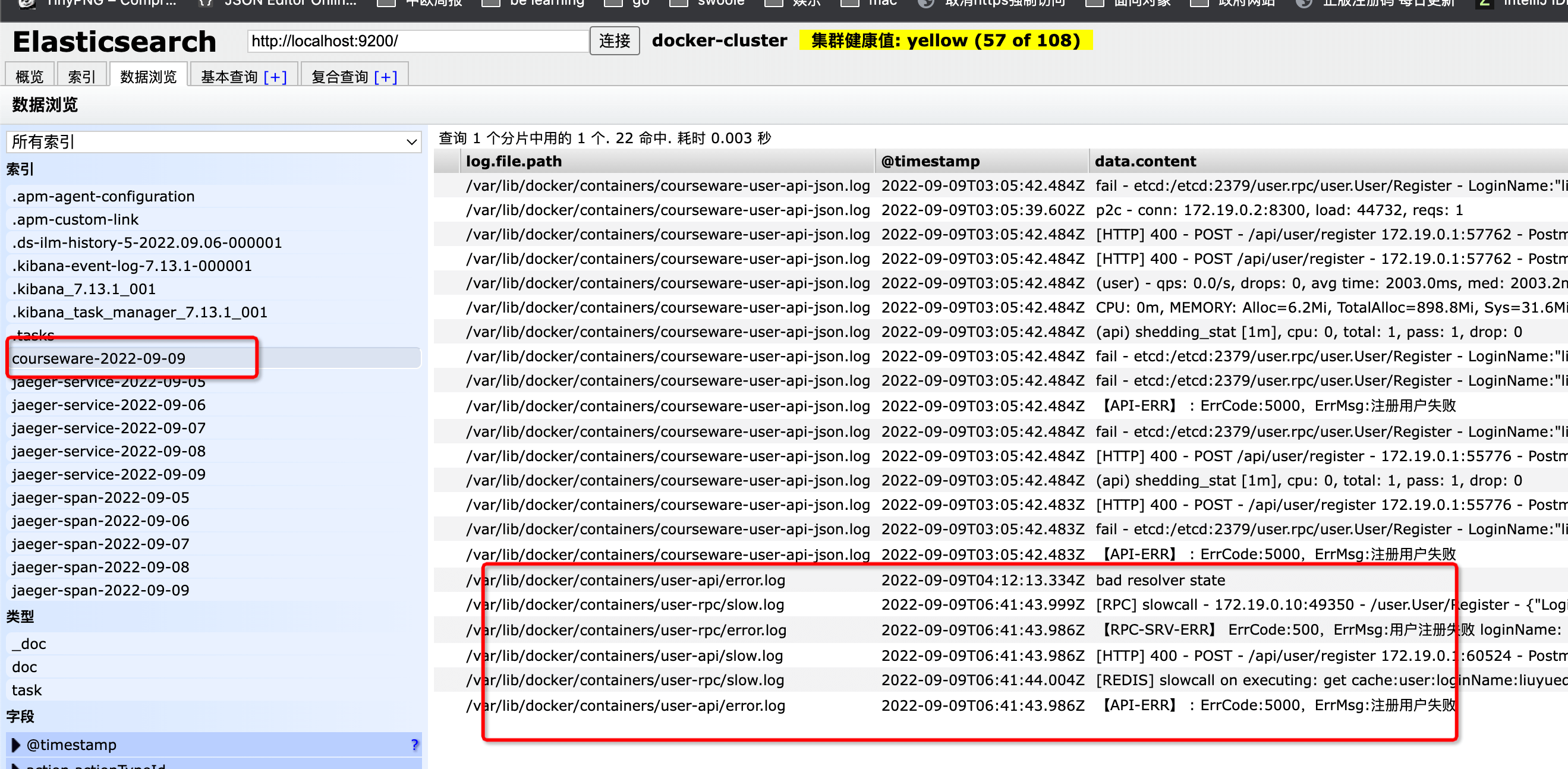
然后我们访问http://127.0.0.1:5601/进到kibana后台,点击Discover,并创建索引
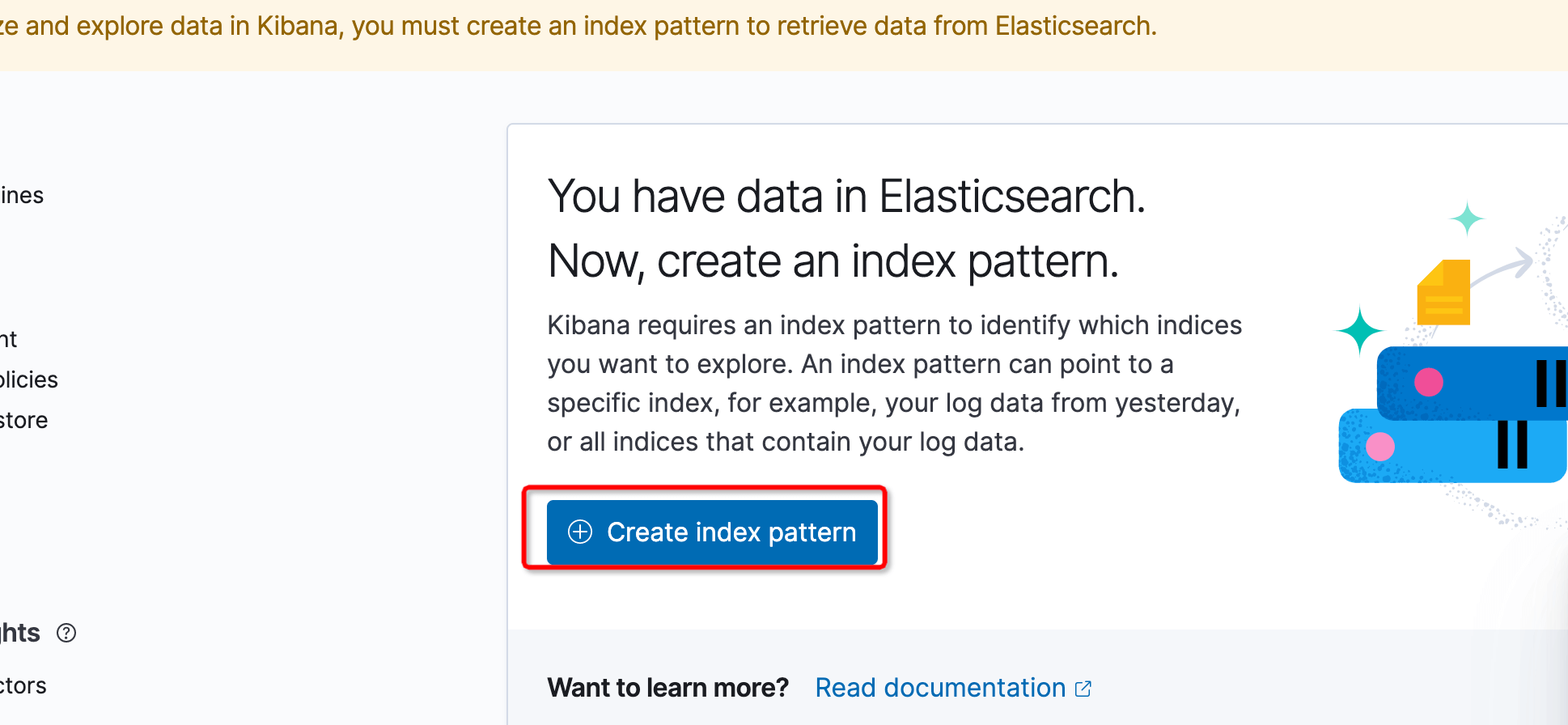
搜索到课件服务的索引后点击下一步
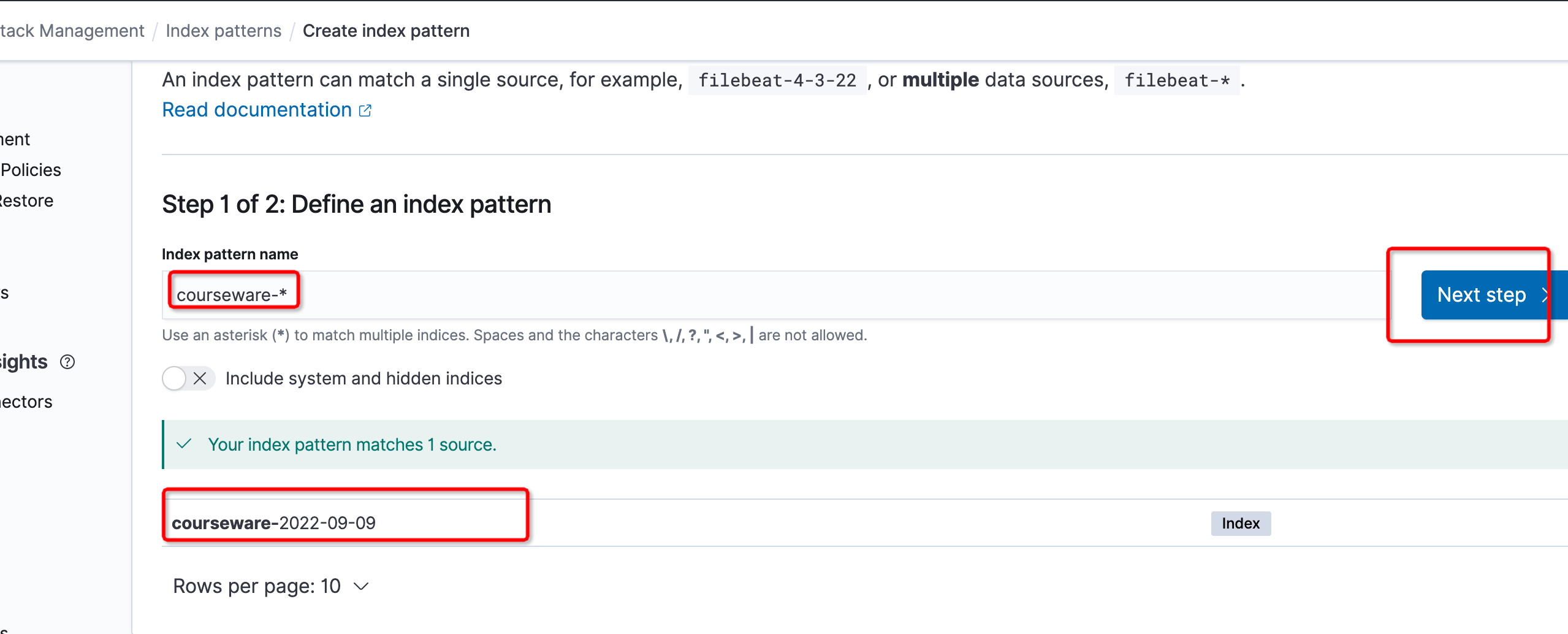
选择@timestamp,点击创建
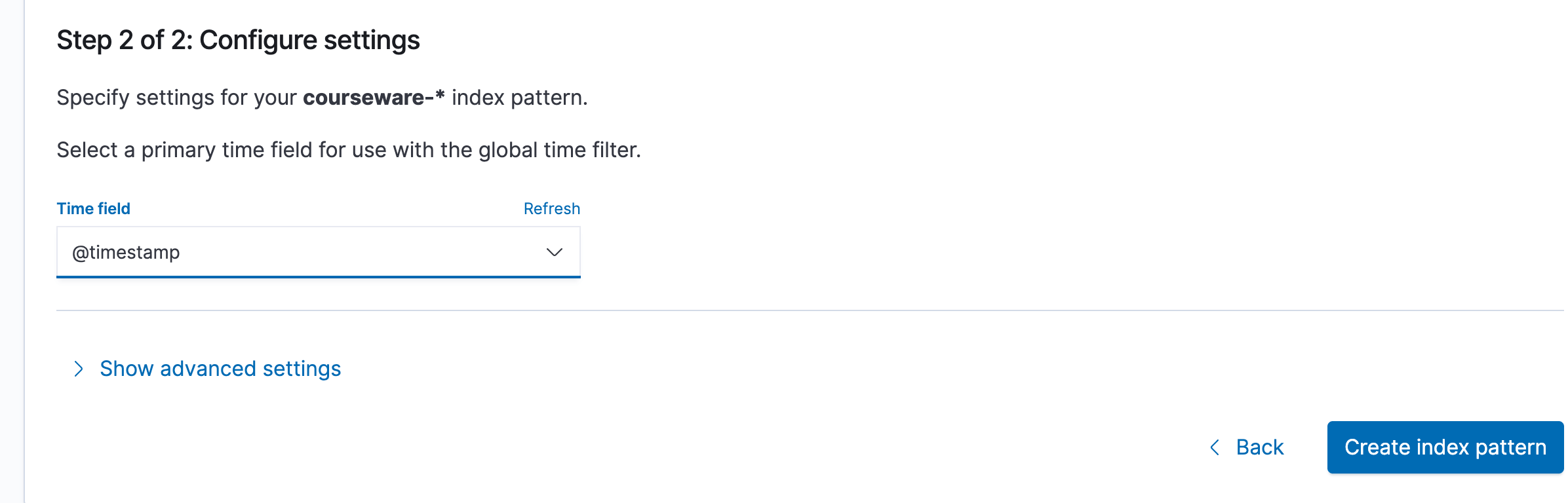
重新点击Discover之后可以看到课件的日志服务创建完成
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵