检测算法作为深度学习的一种主要基础算法,一直吸引着广大的科研工作者。这里总结了一些常见的Loss,作为记录。
目录
检测算法一般包含分类损失(区分目标类别的),回归损失(回归坐标的),目标置信度(表示是否存在目标的,也是一个分类损失)。先说分类损失:
BCEBlurWithLogitsLoss是BCE函数的一个变种,在yolov5中提出来的,其目的是削弱missing样本(就是存在目标但是没有标注出来)带来的负面影响。其实就是通过降低missing样本loss的权重,降低其在反向传播中的比重,达到降低missing样本的负面影响的目的。但是笔者认为,这样可能导致模型无法区分目标和混淆目标,提高混淆目标的误检率。代码如下:
class BCEBlurWithLogitsLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=0.05):
super().__init__()
self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
self.alpha = alpha
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred = torch.sigmoid(pred) # prob from logits
dx = pred - true # reduce only missing label effects
# dx = (pred - true).abs() # reduce missing label and false label effects
alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
loss *= alpha_factor
return loss.mean()其中,alpha_factor的函数曲线如下(alpha默认为0.05)
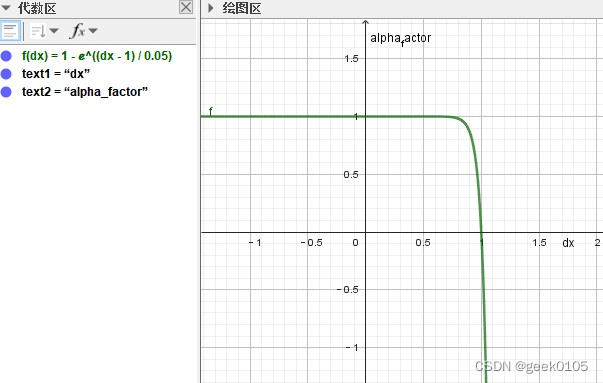
横轴dx=pred-true,再没有使用label smooth的情况下,代表gt的true属于[0,1],过完sigmoid的pred也属于[0-1].
那么,missing的样本label即true为0,pred可能比较大,假如是0.9,alpha_factor接近0,该样本在反向传播中基本不起作用,达到了减少missing样本由于label错误导致的负面影响。但是,与此同时,与目标相似的混淆样本,label也为0,如果模型预测pred的分数也偏大,则该混淆样本的在反向传播中依然不起作用,则模型训练达不到区分混淆目标的目的。
同理,代码中注释掉的 # dx = (pred - true).abs() 去除false样本(其实就是没有目标但是错误标注了一个目标)的负面影响。原理是,label=1,但是pred的分数较低,比如是0.1,0.1-1=-0.9,取绝对值就是0.9,对应的alpha_factor接近0,该样本在反向传播中几乎不起作用,达到了去除false样本的负面影响。但是,与此同时,外观形状变化比较大的目标可能会被误认为是false样本,在训练中不起作用,导致检测不到的问题。
总之,这个loss有利有弊,只能根据数据集label的标注情况,结合alpha的参数调整,看情况是否适合使用。
FcoalLoss是何凯明大神在2017年发表的一篇论文:Focal Loss for Dense Object Detection.中提出的。
论文地址:https://arxiv.org/abs/1708.02002
主要思路是: 通过增加困难样本的权重,让模型专注于困难样本(hard_sample)的学习,防止简单样本(easy_sample)过多主导训练的进程,可以解决难样本过少的问题。代码如下
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(FocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
对于原始交叉熵
定义
可以简化为
值得注意的是,简单样本在数据集中占据很大比重,并且简单样本的损失数值
并不小,大量的简单样本会压倒困难样本,模型偏向于学到简单样本的信息。通常,通过引入一个系数来解决类别不均衡的问题
其中
由于,均衡交叉熵只能平衡正例和负例,不能平衡正样本和负样本。
所以,论文中对交叉熵引入了一个调制系数 ,叫做FocalLoss
函数的曲线如下:
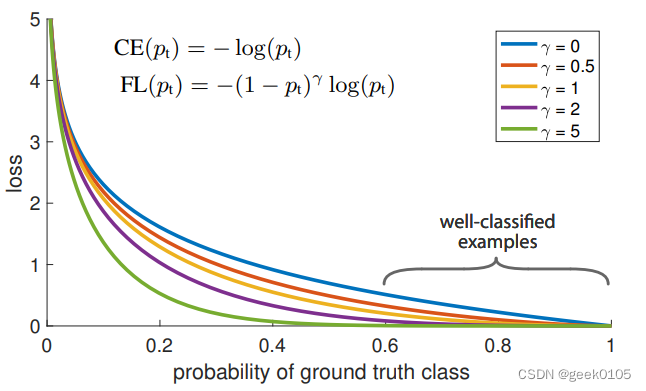
其实,就是对loss做了一个gama变换,使其在容易样本上快速降低,增加困难样本
的比重,防止容易样本主导训练进程,从而达到难易样本均衡的问题。
另外,在实验中发现,alpha均衡对最终结果有一点提升,所以最终FocalLoss表达式如下:
默认gama取1.5,alpha取0.25.
QFocalLoss是2020年的一篇文章,主要是解决FocalLoss只能适用于标签是0-1这样的二分类或者多分类任务,对于使用了label smooth的任务则无法使用。QFL的公式如下:
QFL整理成FL的形式如下:
区别就在于调制系数,FocalLoss的调制系数是
QFocalLoss的调制系数是
代码如下:
class QFocalLoss(nn.Module):
# Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(QFocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred) # prob from logits
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = torch.abs(true - pred_prob) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return lossAP-Loss for Accurate One-Stage Object Detection
基于Ranking的平均定位召回率(Average Localization Recall Precision)损失
论文 :A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection
Rank & Sort Loss for Object Detection and Instance Segmentation
秩和排序损失
IoU、GIoU、DIoU、CIoU、EIoU、αIoU、SIoU
IoU(Intersection over Union)交并比,是指目标框和预测框之间的交际除以并集. IoULoss广泛用于目标检测领域,并且发展出了诸多变体。
针对不相交目标IoU都为0,GIoU引入了并集上的广义交集概念Generalized intersection over Union
其中C为目标框和预测框的最小外接矩形,对应的损失函数为
GIoULoss考虑了目标框和预测框无重叠区域造成的梯度消失问题,可以得到比 MSE 和 IoU 损失函数更高精度的预测框。
GIoU的问题:
1.预测框和目标框相互包含,GIoU退化为IoU
2.预测框和目标框宽高且处于同一水平或同一垂直线时,GIoU退化为IoU
论文:Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
论文提出了预测框和目标框中心的距离作为损失的一部分,考虑了重叠面积+两框的距离,用于解决GIoU回归不准确和回归速度慢的问题
其中,c为最小外接矩形框的对角线欧氏距离,d为预测框和目标框中心点的欧氏距离。
因为DIoU Loss能够直接最小化两个boxes之间的距离,因此其收敛速度比IoU Loss与GIoU Loss更快。
论文:Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
CIoU也是DIoU这篇论文提出的
CIoU提出,一个优秀的回归定位损失应该考虑到3种几何参数:重叠面积、中心点距离、长宽比;
其中
CIoU 同时解决了收敛不准确和收敛速度慢的问题。同时考虑了长宽比。
与 GIoU 和 DIoU 一样,CIoU 也是通过迭代将预测框向真实框移动,但是 CIoU 所需要的迭代次数更少,并且得到的预测框与真实框的纵横比更为接近。
论文:Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation https://arxiv.org/abs/2005.03572
CIoU的团队对CIoU做的改进,主要是改进了的值
EIoU的主要贡献有两个,一个是将长宽比拆开,二是引入了Focal Loss解决难易样本不均衡的问题。
EIoU 在 CIoU 的基础上将长宽比拆开,明确地衡量了三个几何因素的差异,即重叠区域、中心点和边长,同时引入 Fcoal loss 解决了难易样本不平衡的问题。认为简单的任务框回归不需要用过大的权重来学习,而复杂的任务框回归需要大权重来学习,进而将 EIoU loss 进行改进提出 Focal EIoU loss 公式见下:
论文:Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression 2110.13675.pdf (arxiv.org)
alphaIoU是IoU的大一统,对IoU和其他正则项增加一个幂系数
比如IoULoss:
'
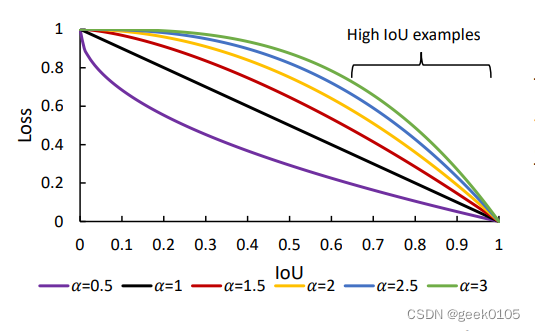
其实类似Focal Loss,对IoU增加了一个gama变换,调整难易样本的比重。通过调整alpha的值,能够适应不同的数据集和训练精度,尤其是解决小样本带噪声数据。
类似的:
IoU显著优于现有的IoU-base的loss。
论文:SIoU Loss: More Powerful Learning for Bounding Box Regression
SIoU 提出了一种新的损失函数,重新定义了惩罚度量,考虑了期望回归之间的向量夹角。
传统的目标检测损失函数依赖于边界框回归指标的聚合,例如预测框和真实框(即 GIoU、CIoU 等)的距离、重叠区域和纵横比。然而,迄今为止提出和使用的方法都没有考虑期望的真实框和预测框之间不匹配的方向。这种不足导致收敛速度较慢且效率较低,因为预测框在训练过程中可能会“四处游荡”,最终会产生一个更差的模型。
参考:
(50条消息) 各种 IoU 损失变体_iou及其变体_有为少年的博客-CSDN博客
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
我想知道我的代码是否在rspec下运行。这可能吗?原因是我正在加载一些错误记录器,这些记录器在测试期间会被故意错误(expect{x}.toraise_error)弄得乱七八糟。我查看了我的ENV变量,没有(明显的)测试环境变量的迹象。 最佳答案 在spec_helper.rb的开头添加:ENV['RACK_ENV']='test'现在您可以在代码中检查RACK_ENV是否经过测试。 关于ruby-检测由RSpec、Ruby运行的代码,我们在StackOverflow上找到一个类似的问题
我正在使用rubydaemongem。想知道如何向停止操作添加一些额外的步骤?希望我能检测到停止被调用,并向其添加一些额外的代码。任何人都知道我如何才能做到这一点? 最佳答案 查看守护程序gem代码,它似乎没有用于此目的的明显扩展点。但是,我想知道(在守护进程中)您是否可以捕获守护进程在发生“停止”时发送的KILL/TERM信号...?trap("TERM")do#executeyourextracodehereend或者你可以安装一个at_exit钩子(Hook):-at_exitdo#executeyourextracodehe
我有一个定义类的Ruby脚本。我希望脚本执行语句BoolParser.generate:file_base=>'bool_parser'仅当脚本作为可执行文件被调用时,而不是当它被irbrequire(或通过-r在命令行上传递)时。我可以用什么来包装上面的语句,以防止它在我的Ruby文件加载时执行? 最佳答案 条件$0==__FILE__...!/usr/bin/ruby1.8classBoolParserdefself.generate(args)p['BoolParser.generate',args]endendif$0==_
我有以下字符串,我想检测那里的换行符。但是Ruby的字符串方法include?检测不到它。我正在运行Ruby1.9.2p290。我哪里出错了?"/'ædres/\nYour".include?('\n')=>false 最佳答案 \n需要在双引号内,否则无法转义。>>"\n".include?'\n'=>false>>"\n".include?"\n"=>true 关于Ruby无法检测字符串中的换行符,我们在StackOverflow上找到一个类似的问题: h
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记