分词器是es中的一个组件,通俗意义上理解,就是将一段文本按照一定的逻辑,分析成多个词语,同时对这些词语进行常规化的一种工具;ES会将text格式的字段按照分词器进行分词,并编排成倒排索引,正是因为如此,es的查询才如此之快。
一个analyzer即分析器,无论是内置的还是自定义的,只是一个包含character filters(字符过滤器)、 tokenizers(分词器)、token filters(令牌过滤器)三个细分模块的包。
看下这三个细分模块包的作用:
character filters(字符过滤器):分词之前的预处理,过滤无用字符
token filters(令牌过滤器):停用词、时态转换,大小写转换、同义词转换、语气词处理等。
tokenizers(分词器):切词
先来看个自定义分词器,了解整个分析器analyzer的构造
PUT custom_analysis
{
"settings":{
"analysis":{ #分析配置,可以设置char_filter(字符过滤器)、filter(令牌过滤器)、tokenizer(分词器)、analyzer(分析器)
"char_filter": { # 字符过滤器配置
"my_char_filter":{ #定义一个字符过滤器:my_char_filter
"type":"mapping", # 字符过滤器类型:主要有三种:html_strip(标签过滤)、mapping(字符替换)、pattern_replace(正则匹配替换)
"mappings":[ # mapping的参数:表示 '&' 会被替换成 'and'
"& => and",
"| => or"
]
},
"html_strip_char_filter":{
"type":"html_strip",
"escaped_tags":["a"]
}
},
"filter": { # 令牌过滤器配置
"my_stopword":{ # 定义一个令牌过滤器:my_stopword
"type":"stop", # 令牌过滤器类型:stop(停用(删除)词)
"stopwords":[ # stop的参数:表示这些词会被删除
"is",
"in",
"the",
"a",
"at",
"for"
]
}
},
"tokenizer": { # 分词器配置
"my_tokenizer":{ # 定义一个分词器my_tokenizer
"type":"pattern", # 分词器类型:pattern 正则匹配
"pattern":"[ ,.!?]" # pattern的参数:会根据这几个字符进行分割
}
},
"analyzer": { # 分析器:可以理解成组合了字符过滤器、令牌过滤器、分词器的一个整体。
"my_analyzer":{ #定义一个分析器:my_analyzer
"type":"custom",
"char_filter":["my_char_filter","html_strip_char_filter"], # 使用的字符过滤器
"filter":["my_stopword"], # 使用的令牌过滤器
"tokenizer":"my_tokenizer" # 使用的分词器
}
}
}
}
}
字符过滤器是分词之前的预处理,过滤无用字符,主要有这三种:html_strip、mapping、pattern_replace
html_strip用于过滤html标签,它有个参数escaped_tags可以设置保留的标签
看下面例子
PUT index_html_strip
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter":{
"type":"html_strip",
"escaped_tags":["a"]
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":["my_char_filter"]
}
}
}
}
}
GET my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "<p>要的话就<a>点击</a></p>"
}
结果:p标签过滤掉了,而a标签保留了

mapping是字符替换
看下面例子,可以设置一些敏感词替换成*
PUT index_mapping
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter":{
"type":"mapping",
"mappings":[
"滚 => *",
"垃圾 => *",
"手枪 => *",
"你妈 => *"
]
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":["my_char_filter"]
}
}
}
}
}
GET index_mapping/_analyze
{
"analyzer": "my_analyzer",
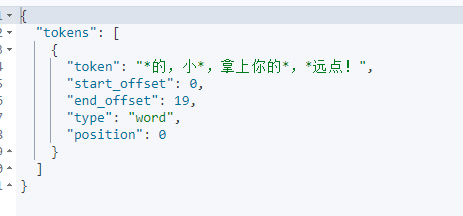
"text": "你妈的,小垃圾,拿上你的手枪,滚远点!"
}
结果:可以看到设置的敏感词被替换成*了
pattern_replace是正则匹配替换
可以匹配手机号码,将中间四个数字加密处理
PUT index_pattern_replace
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter":{
"type":"pattern_replace",
"pattern":"(\\d{3})\\d{4}(\\d{4})",
"replacement":"$1****$2"
}
},
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":["my_char_filter"]
}
}
}
}
}
GET index_pattern_replace/_analyze
{
"analyzer": "my_analyzer",
"text": "你的手机号是18814142694"
}
结果:

停用词(stop)、大小写转换(lowercase)、同义词转换(synonym)等。
停用词有个参数可以设置删除的词语:stopwords
PUT /index_stop
{
"settings": {
"analysis": {
"analyzer": {
"my_stop": {
"tokenizer": "whitespace",
"filter": [ "my_stop" ]
}
},
"filter": {
"my_stop": {
"type": "stop",
"stopwords": [
"is",
"in",
"the",
"a",
"at",
"for"
]
}
}
}
}
}
GET index_stop/_analyze
{
"analyzer": "my_stop",
"text": ["What is a apple?"]
}
结果:

同义词过滤器需要配置同义词的文件路径synonyms_path,需要放在项目目录下的config文件目录里
(本项目同义词文件完整路径:/app/elasticsearch-8.4.2/config/analysis/synonym.txt)
蒙丢丢 => 'DaB'
PUT /index_synonym
{
"settings": {
"analysis": {
"analyzer": {
"synonym": {
"tokenizer": "whitespace",
"filter": [ "synonym" ]
}
},
"filter": {
"synonym": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt"
}
}
}
}
}
GET index_synonym/_analyze
{
"analyzer": "synonym",
"text": ["蒙丢丢"]
}
结果:

分词器的作用就是用来切词的。
常见的分词器有:
standard:默认分词器,中文支持的不理想,会逐字拆分
pattern:以正则匹配分隔符,把文本拆分成若干词项
simple pattern:以正则匹配词项,速度比pattern tokenizer快
whitespace:以空白符分割
GET _analyze
{
"analyzer": "whitespace",
"text": ["What is a apple?"]
}
结果

ES的中文分词器需要下载插件安装使用的。
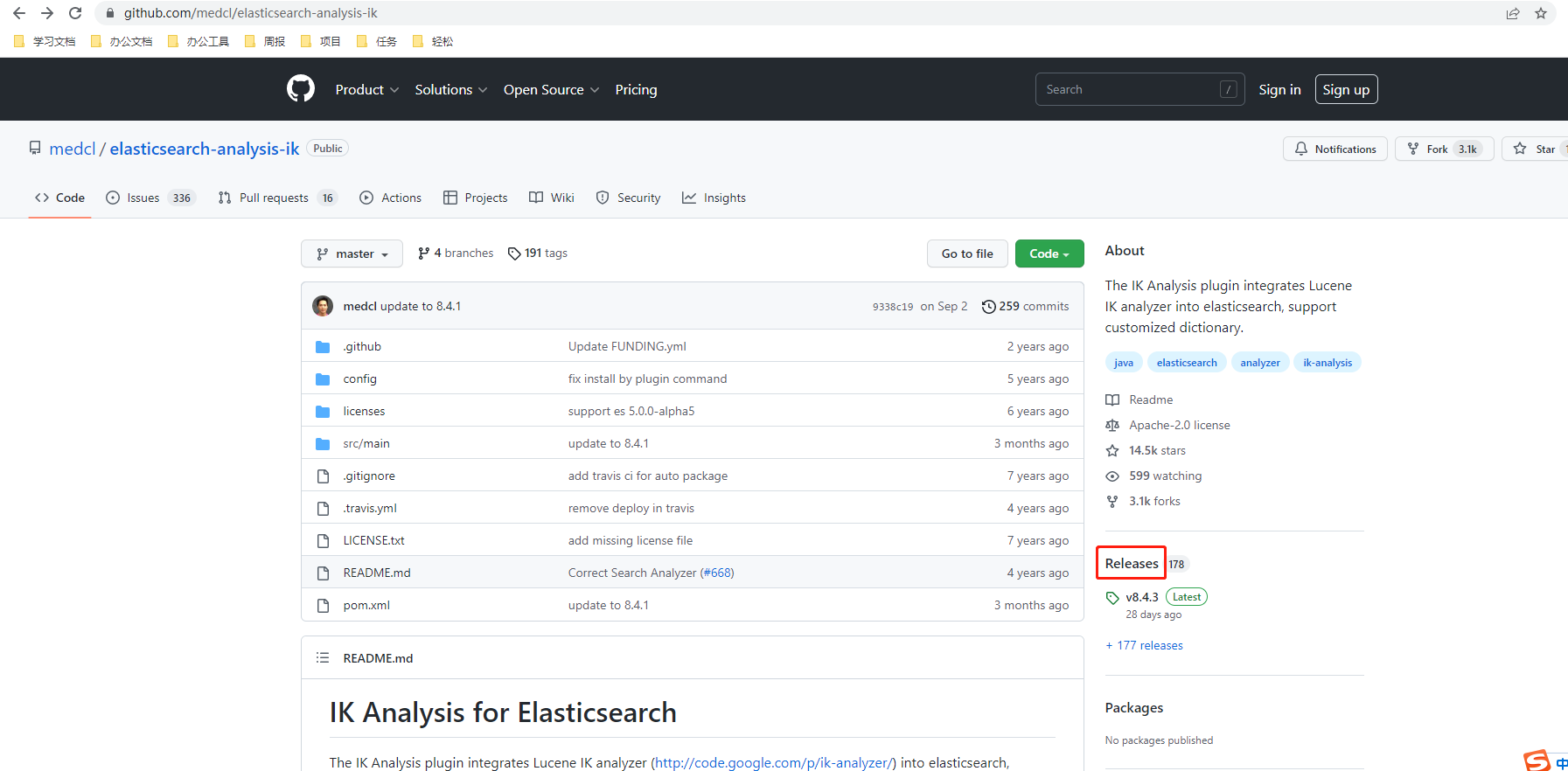
点击Releases,选择版本下载

在根目录下的plugins文件夹下,创建ik文件目录,将下载的插件解压到ik目录下
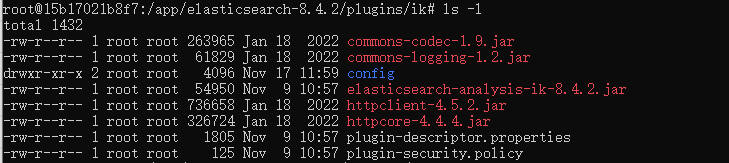
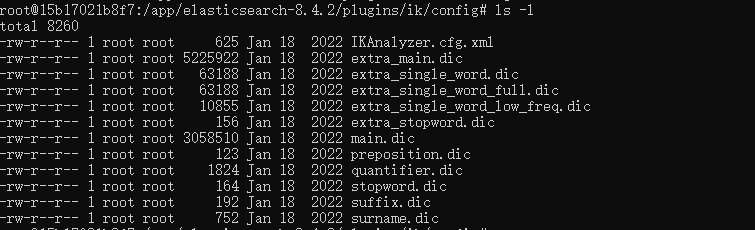
IKAnalyzer.cfg.xml:IK分词配置文件
main.dic:主词库:
stopword.dic:英文停用词,不会建立在倒排索引中
quantifier.dic:特殊词库:计量单位等
suffix.dic:特殊词库: 后级名
surname.dic: 特殊词库: 百家姓
preposition:特殊词库: 语气词
自定义词库:网络词汇、流行词、自造词等
/app/elasticsearch-8.4.2/bin/elasticsearch -d /app/kibana-8.4.2/bin/kibana &
GET _analyze
{
"analyzer": "ik_max_word", #中文分词器:ik_max_word
"text": ["今天真是美好的一天"]
}
结果
{
"tokens": [
{
"token": "今天",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "天真",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "真是",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "美好",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 3
},
{
"token": "的",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 4
},
{
"token": "一天",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 5
},
{
"token": "一",
"start_offset": 7,
"end_offset": 8,
"type": "TYPE_CNUM",
"position": 6
},
{
"token": "天",
"start_offset": 8,
"end_offset": 9,
"type": "COUNT",
"position": 7
}
]
}
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
我在OSX上使用irb,当我按左/右选项(或META+B/F)时,光标移动到下一个/上一个单词。但irb不会将点(.)字符视为单词分隔符。我尝试将(.)添加到.irbrc,所以现在看起来像这样:Readline.basic_word_break_characters="\t\n`>但这没有任何效果。我使用的是普通的MountainLionruby和手动编译的1.9.3,这两个版本的irb行为相似。此外,点在bash和pry中被视为分隔符,因此系统范围的设置可能没问题。感谢任何帮助,谢谢 最佳答案 好吧,问题似乎出在我的系统中根本
目录一、下载Elasticsearch1.选择你要下载的Elasticsearch版本二、采用通用搭建集群的方法三、配置三台es1.上传压缩包到任意一台虚拟机中2.解压并修改配置文件(配置单台es)3.配置三台es集群4.设置后台启动和开机自启(可选)一、下载Elasticsearch1.选择你要下载的Elasticsearch版本es下载地址这里我下载的是二、采用通用搭建集群的方法集群搭建方法三、配置三台es1.上传压缩包到任意一台虚拟机中上传方式有两种第一种:使用xftp上传直接拖动过去就可以了。第二种:使用lrzsz先安装yum-yinstalllrzsz切换到要上传的位置cd/opt/
IK分词器本文分为简介、安装、使用三个角度进行讲解。简介倒排索引众所周知,ES是一个及其强大的搜索引擎,那么它为什么搜索效率极高呢,当然和他的存储方式脱离不了关系,ES采取的是倒排索引,就是反向索引;常见索引结构几乎都是通过key找value,例如Map;倒排索引的优势就是有效利用Value,将多个含有相同Value的值存储至同一位置。分词器为了配合倒排索引,分词器也就诞生了,只有合理的利用Value,才会让倒排索引更加高效,如果一整个Value不进行任何操作直接进行存储,那么Value和key毫无区别。分词器Analyzer通常会对Value进行操作:一、字符过滤,过滤掉html标签;二、分
目录前言第一个部分:安装ES的包1.安装成功的截图2.下载es的安装包3.检查本地的jdk的安装是否存在问题4.修改config文件夹下面的配置第二部分:windows安装Kibana可视化工具1.下载安装包2.安装过程中遇到的问题3.安装6.0.0的版本是可以的4.安装后的效果第三部分:安装Elasticsearch-Head进行搜索本地es环境内的所有数据1.下载git项目文件:GitHub-mobz/elasticsearch-head:Awebfrontendforanelasticsearchcluster2.关于kibana不能监控es环境内数据的问题3.重启es的bat文件,使用
一、Elasticsearch简介实际业务场景中,多端的查询功能都有很大的优化空间。常见的处理方式有:建索引、建物化视图简化查询逻辑、DB层之上建立缓存、分页…然而随着业务数据量的不断增多,总有那么一张表或一个业务,是无法通过常规的处理方式来缩短查询时间的。在查询功能优化上,作为开发人员应该站在公司的角度,本着优化客户体验的目的去寻找解决方案。本人有幸做过Tomcat整合solr,今天一起研究一下当前比较火热的Elasticsearch搜索引擎。Elasticsearch是一个非常强大的搜索引擎。它目前被广泛地使用于各个IT公司。Elasticsearch是由Elastic公司创建。它的代码位
matchAll分页查询@TestpublicvoidtestMatchAll()throwsIOException{//创建查询请求对象SearchRequestsearchRequest=newSearchRequest("goods");//构建查询条件(分页,查询所有)SearchSourceBuildersearchSourceBuilder=newSearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchAllQuery());//searchSourceBuilder.from(0);searchSour