TreeMap是Map家族中的一员,也是用来存放key-value键值对的。平时在工作中使用的可能并不多,它最大的特点是遍历时是有顺序的,根据key的排序规则来,那么它具体是如何使用,又是怎么实现的呢?本文基于jdk8做一个讲解。
TreeMap是一个基于key有序的key value散列表。

以上是TreeMap的类结构图:
说明:使用键的自然排序构造一个新的空树映射。
说明:构造一个新的空树映射,根据给定的比较器排序。
说明:构造一个新的树映射,包含与给定映射相同的映射,按照键的自然顺序排序。
说明:构造一个新的树映射,包含相同的映射,并使用与指定排序映射相同的顺序。
这边主要讲解下NavigableMap和SortedMap提供的一些方法,Map相关的方法大家应该都很熟悉了。
SortedMap接口:
返回用于排序此映射中的键的比较器,如果此映射使用其键的自然排序,则返回null。
返回此映射中包含的映射的Set视图。
返回当前映射中的第一个(最低)键。
返回当前映射中的最后(最高)键。
NavigableMap接口:
返回与大于或等于给定键的最小键相关联的键值映射,如果没有这样的键则返回null。
返回大于或等于给定键的最小键,如果没有这样的键,则返回null。
返回此映射中包含的映射的倒序视图。
返回与该映射中最小的键关联的键值映射,如果映射为空,则返回null。
返回与小于或等于给定键的最大键相关联的键值映射,如果没有这样的键则返回null。
返回该映射中键严格小于toKey的部分的视图。
返回与严格大于给定键的最小键关联的键值映射,如果没有这样的键,则返回null。
返回与此映射中最大键关联的键值映射,如果映射为空,则返回null。
返回与严格小于给定键的最大键关联的键值映射,如果没有这样的键,则返回null。
删除并返回与该映射中最小的键关联的键值映射,如果映射为空,则返回null。
删除并返回与此映射中最大键关联的键值映射,如果映射为空,则返回null。
返回该映射中键范围从fromKey(包含)到toKey(独占)的部分的视图。
返回该映射中键大于或等于fromKey的部分的视图。
@Test
public void test1() {
Map<Integer, String> treeMap = new TreeMap<>();
treeMap.put(16, "a");
treeMap.put(1, "b");
treeMap.put(4, "c");
treeMap.put(3, "d");
treeMap.put(8, "e");
// 遍历
System.out.println("默认排序:");
treeMap.forEach((key, value) -> {
System.out.println("key: " + key + ", value: " + value);
});
// 构造方法传入比较器
Map<Integer, String> tree2Map = new TreeMap<>((o1, o2) -> o2 - o1);
tree2Map.put(16, "a");
tree2Map.put(1, "b");
tree2Map.put(4, "c");
tree2Map.put(3, "d");
tree2Map.put(8, "e");
// 遍历
System.out.println("倒序排序:");
tree2Map.forEach((key, value) -> {
System.out.println("key: " + key + ", value: " + value);
});
}
运行结果:

@Test
public void test2() {
Map<Integer, String> treeMap = new TreeMap<>();
treeMap.put(null, "a");
}
运行结果:
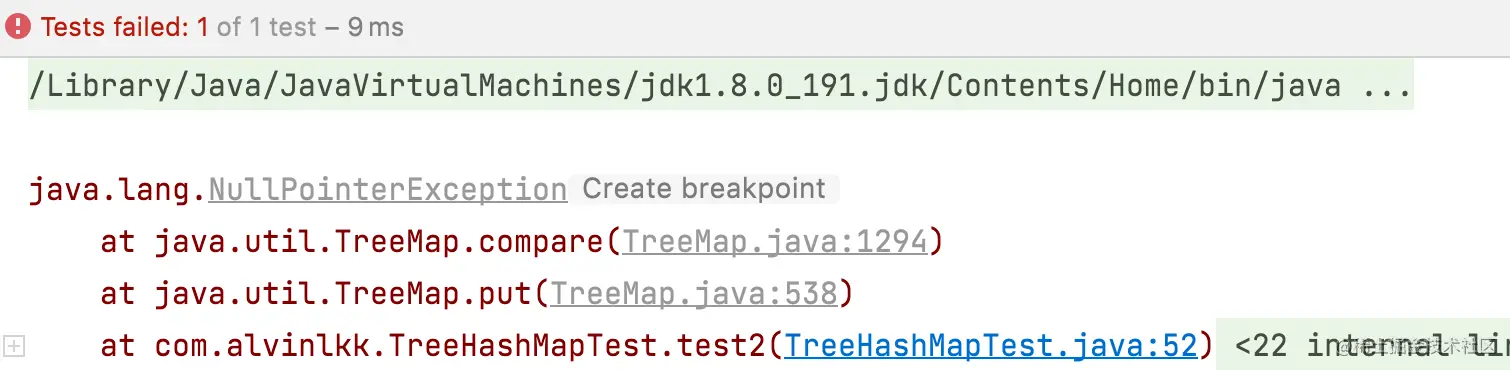
@Test
public void test3() {
NavigableMap<Integer, String> treeMap = new TreeMap<>();
treeMap.put(16, "a");
treeMap.put(1, "b");
treeMap.put(4, "c");
treeMap.put(3, "d");
treeMap.put(8, "e");
// 获取大于等于5的key
Integer ceilingKey = treeMap.ceilingKey(5);
System.out.println("ceilingKey 5 is " + ceilingKey);
// 获取最大的key
Integer lastKey = treeMap.lastKey();
System.out.println("lastKey is " + lastKey);
}
运行结果:

大家有想过TreeMap的底层是怎么实现的吗,是如何维护key的顺序呢?答案就是基于红黑树实现的。
那什么是红黑树呢?我们在这里简单的认识一下,了解一下红黑树的特点:红黑树是一颗自平衡的排序二叉树。我们就先从二叉树开始说起。
二叉树很容易理解,就是一棵树分俩叉。
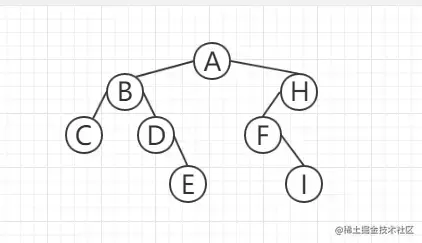
上面这颗就是一颗最普通的二叉树。但是你会发现看起来不那么美观,因为你以H为根节点,发现左右两边高低不平衡,高度相差达到了2。于是出现了平衡二叉树,使得左右两边高低差不多。
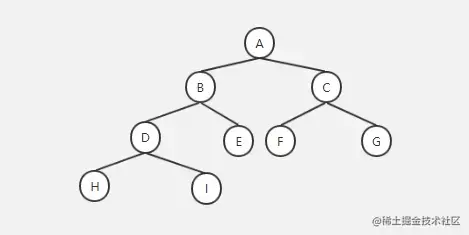
这下子应该能看到,不管是从任何一个字母为根节点,左右两边的深度差不了2,最多是1。这就是平衡二叉树。不过好景不长,有一天,突然要把字母变成数字,还要保持这种特性怎么办呢?于是又出现了平衡二叉排序树。
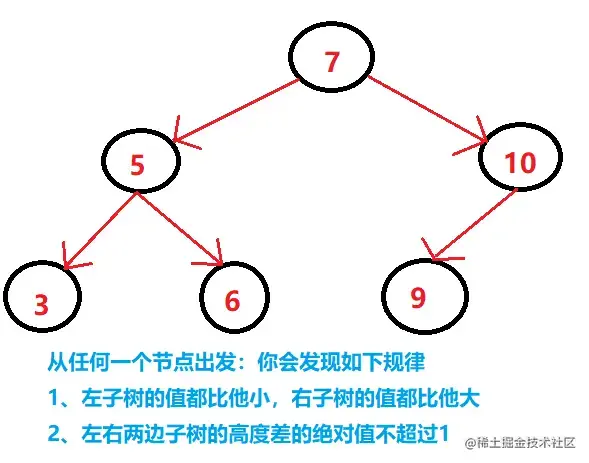
不管是从长相(平衡),还是从规律(排序)感觉这棵树超级完美。但是有一个问题,那就是在增加删除节点的时候,你要时刻去让这棵树保持平衡,需要做太多的工作了,旋转的次数超级多,于是乎出现了红黑树。

这就是传说中的红黑树,和平衡二叉排序树的区别就是每个节点涂上了颜色,他有下列五条性质:
这些性质有什么优点呢?就是插入效率超级高。因为在插入一个元素的时候,最多只需三次旋转,O(1)的复杂度,但是有一点需要说明他的查询效率略微逊色于平衡二叉树,因为他比平衡二叉树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的avl树最多多一次比较。如何去旋转呢?如下图所示。
首先是左旋:
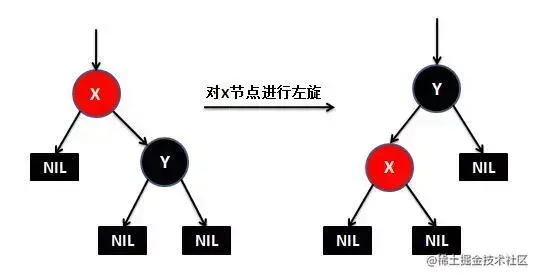
然后是右旋:

红黑树更详细的内容可以参考这篇文章:segmentfault.com/a/119000001…
//这是一个比较器,方便插入查找元素等操作
private final Comparator<? super K> comparator;
//红黑树的根节点:每个节点是一个Entry
private transient Entry<K,V> root;
//集合元素数量
private transient int size = 0;
//集合修改的记录
private transient int modCount = 0;
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
//左子树
Entry<K,V> left;
//右子树
Entry<K,V> right;
//父节点
Entry<K,V> parent;
//每个节点的颜色:红黑树属性。
boolean color = BLACK;
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return valEquals(key,e.getKey()) && valEquals(value,e.getValue());
}
public int hashCode() {
int keyHash = (key==null ? 0 : key.hashCode());
int valueHash = (value==null ? 0 : value.hashCode());
return keyHash ^ valueHash;
}
public String toString() {
return key + "=" + value;
}
}
TreeMap基于红黑树实现,而红黑树是一种自平衡二叉查找树,所以 TreeMap 的查找操作流程和二叉查找树一致。二叉树的查找流程是这样的,先将目标值和根节点的值进行比较,如果目标值小于根节点的值,则再和根节点的左孩子进行比较。如果目标值大于根节点的值,则继续和根节点的右孩子比较。在查找过程中,如果目标值和二叉树中的某个节点值相等,则返回 true,否则返回 false。TreeMap 查找和此类似,只不过在 TreeMap 中,节点(Entry)存储的是键值对<k,v>。在查找过程中,比较的是键的大小,返回的是值,如果没找到,则返回null。TreeMap 中的查找方法是get。
public V get(Object key) {
//调用 getEntry方法查找
Entry<K,V> p = getEntry(key);
return (p==null ? null : p. value);
}
final Entry<K,V> getEntry(Object key) {
/ 如果比较器为空,只是用key作为比较器查询
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
// 取得root节点
Entry<K,V> p = root;
//核心来了:从root节点开始查找,根据比较器判断是在左子树还是右子树
while (p != null) {
int cmp = k.compareTo(p.key );
if (cmp < 0)
p = p. left;
else if (cmp > 0)
p = p. right;
else
return p;
}
我们来看下关键的插入方法,在插入时候是如何维护key的。
public V put(K key, V value) {
Entry<K,V> t = root;
// 1.如果根节点为 null,将新节点设为根节点
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
//如果root不为null,说明已存在元素
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
//如果比较器不为null 则使用比较器
if (cpr != null) {
//找到元素的插入位置
do {
parent = t;
cmp = cpr.compare(key, t.key);
//当前key小于节点key 向左子树查找
if (cmp < 0)
t = t.left;
//当前key大于节点key 向右子树查找
else if (cmp > 0)
t = t.right;
else
//相等的情况下 直接更新节点值
return t.setValue(value);
} while (t != null);
}
//如果比较器为null 则使用默认比较器
else {
//如果key为null 则抛出异常
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
//找到元素的插入位置
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
//根据比较结果决定插入到左子树还是右子树
if (cmp < 0)
parent.left = e;
else
parent.right = e;
//保持红黑树性质,进行红黑树的旋转等操作
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
比较关键的就是fixAfterInsertion方法, 看懂这个方法需要你对红黑树的机制比较了解。
private void fixAfterInsertion(Entry<K,V> x) {
// 将新插入节点的颜色设置为红色
x. color = RED;
// while循环,保证新插入节点x不是根节点或者新插入节点x的父节点不是红色(这两种情况不需要调整)
while (x != null && x != root && x. parent.color == RED) {
// 如果新插入节点x的父节点是祖父节点的左孩子
if (parentOf(x) == leftOf(parentOf (parentOf(x)))) {
// 取得新插入节点x的叔叔节点
Entry<K,V> y = rightOf(parentOf (parentOf(x)));
// 如果新插入x的父节点是红色
if (colorOf(y) == RED) {
// 将x的父节点设置为黑色
setColor(parentOf (x), BLACK);
// 将x的叔叔节点设置为黑色
setColor(y, BLACK);
// 将x的祖父节点设置为红色
setColor(parentOf (parentOf(x)), RED);
// 将x指向祖父节点,如果x的祖父节点的父节点是红色,按照上面的步奏继续循环
x = parentOf(parentOf (x));
} else {
// 如果新插入x的叔叔节点是黑色或缺少,且x的父节点是祖父节点的右孩子
if (x == rightOf( parentOf(x))) {
// 左旋父节点
x = parentOf(x);
rotateLeft(x);
}
// 如果新插入x的叔叔节点是黑色或缺少,且x的父节点是祖父节点的左孩子
// 将x的父节点设置为黑色
setColor(parentOf (x), BLACK);
// 将x的祖父节点设置为红色
setColor(parentOf (parentOf(x)), RED);
// 右旋x的祖父节点
rotateRight( parentOf(parentOf (x)));
}
} else { // 如果新插入节点x的父节点是祖父节点的右孩子和上面的相似
Entry<K,V> y = leftOf(parentOf (parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf (x), BLACK);
setColor(y, BLACK);
setColor(parentOf (parentOf(x)), RED);
x = parentOf(parentOf (x));
} else {
if (x == leftOf( parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf (x), BLACK);
setColor(parentOf (parentOf(x)), RED);
rotateLeft( parentOf(parentOf (x)));
}
}
}
// 最后将根节点设置为黑色
root.color = BLACK;
}
删除remove是最复杂的方法。
public V remove(Object key) {
// 根据key查找到对应的节点对象
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
// 记录key对应的value,供返回使用
V oldValue = p. value;
// 删除节点
deleteEntry(p);
return oldValue;
}
private void deleteEntry(Entry<K,V> p) {
modCount++;
//元素个数减一
size--;
// 如果被删除的节点p的左孩子和右孩子都不为空,则查找其替代节
if (p.left != null && p. right != null) {
// 查找p的替代节点
Entry<K,V> s = successor (p);
p. key = s.key ;
p. value = s.value ;
p = s;
}
Entry<K,V> replacement = (p. left != null ? p.left : p. right);
if (replacement != null) {
// 将p的父节点拷贝给替代节点
replacement. parent = p.parent ;
// 如果替代节点p的父节点为空,也就是p为跟节点,则将replacement设置为根节点
if (p.parent == null)
root = replacement;
// 如果替代节点p是其父节点的左孩子,则将replacement设置为其父节点的左孩子
else if (p == p.parent. left)
p. parent.left = replacement;
// 如果替代节点p是其父节点的左孩子,则将replacement设置为其父节点的右孩子
else
p. parent.right = replacement;
// 将替代节点p的left、right、parent的指针都指向空
p. left = p.right = p.parent = null;
// 如果替代节点p的颜色是黑色,则需要调整红黑树以保持其平衡
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
// 如果要替代节点p没有父节点,代表p为根节点,直接删除即可
root = null;
} else {
// 如果p的颜色是黑色,则调整红黑树
if (p.color == BLACK)
fixAfterDeletion(p);
// 下面删除替代节点p
if (p.parent != null) {
// 解除p的父节点对p的引用
if (p == p.parent .left)
p. parent.left = null;
else if (p == p.parent. right)
p. parent.right = null;
// 解除p对p父节点的引用
p. parent = null;
}
}
}
最终还是落到了对红黑树节点的删除上,需要维持红黑树的特性,做一系列的工作。
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
我经常将预配置的lambda插入可枚举的方法中,例如“map”、“select”等。但是“注入(inject)”的行为似乎有所不同。例如与mult4=lambda{|item|item*4}然后(5..10).map&mult4给我[20,24,28,32,36,40]但是,如果我制作一个2参数lambda用于像这样的注入(inject),multL=lambda{|product,n|product*n}我想说(5..10).inject(2)&multL因为“inject”有一个可选的单个初始值参数,但这给了我......irb(main):027:0>(5..10).inject
是否有self验证的问题列表。看着那个,我可以确定我知道。我应该复习一下。在学习的过程中,我列了一个这样的list,但它只包含我在某处听说过的项目。我需要一段时间才能找到新的东西。 最佳答案 以下是针对ruby和Rails的一些测试列表。证书名称:RubyonRails谁提供:oDeskIncorporation认证费用:免费网站:https://www.odesk.com/tests/985?pos=0证书名称:RubyonRails提供者:Techgig.com(TimesBusinessSolutionsLimited(T
我想覆盖store_accessor的getter。可以查到here.代码在这里:#Fileactiverecord/lib/active_record/store.rb,line74defstore_accessor(store_attribute,*keys)keys=keys.flatten_store_accessors_module.module_evaldokeys.eachdo|key|define_method("#{key}=")do|value|write_store_attribute(store_attribute,key,value)enddefine_met
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。我一直在Rails上做两个项目,它们运行良好,但在这个过程中重新发明了轮子,自来水(和热水)和止痛药,正如我随后了解到的那样,这些已经存在于框架中。那么基本上,正确了解框架中所有智能部分的最佳方法是什么,这将节省时间而不是自己构建已经实现的功能?从第1页开始阅读文档?是否有公开所有内容的特定示例应用程序?一个特定的开源项目?所有的rails交通?还是完全
假设我有一个函数defodd_or_evennifn%2==0return:evenelsereturn:oddendend我有一个简单的可枚举数组simple=[1,2,3,4,5]然后我用我的函数在map中运行它,使用一个do-endblock:simple.mapdo|n|odd_or_even(n)end#=>[:odd,:even,:odd,:even,:odd]如果不首先定义函数,我怎么能做到这一点?例如,#doesnotworksimple.mapdo|n|ifn%2==0return:evenelsereturn:oddendend#Desiredresult:#=>[
在以下示例中,我无法理解Ruby运算符的优先级:x=1&&y=2由于&&的优先级高于=,我的理解是类似于+和*运算符:1+2*3+4解析为1+(2*3)+4它应该等于:x=(1&&y)=2但是,所有Ruby源代码(包括内部语法解析器Ripper)都将其解析为x=(1&&(y=2))为什么?编辑[08.01.2016]让我们关注一个子表达式:1&&y=2根据优先规则,我们应该尝试将其解析为:(1&&y)=2这没有意义,因为=需要特定的LHS(变量、常量、[]数组项等)。但是既然(1&&y)是一个正确的表达式,那么解析器应该如何处理呢?我试过咨询Ruby的parse.y,但它太像意大利面条
我在维基百科上找到了这个代码块,作为Ruby中quine(打印自身的程序)的示例。puts但是,我不明白它是如何工作的。特别是,我没有得到的是,当我删除最后一行时,出现此错误:syntaxerror,unexpected$end,expectingtSTRING_CONTENTortSTRING_DBEGortSTRING_DVARortSTRING_END这些行中发生了什么? 最佳答案 语法以here-document开始,通过Perl从UNIXshell借用-它基本上是一个多行字符串文字,从之后的行开始当一行以something
一文解决关于VLAN所有的疑惑VLAN基本概念为什么需要VLAN?怎么在交换机上划分VLAN,VLAN的工作原理有了子网,已经隔离了广播,还需要VLAN干啥?只进行子网划分,不进行VLAN划分VLAN划分与子网划分附加VLAN信息的方法VLAN划分交换机的端口类型(Access和Trunk)一、访问链接二、汇聚链接汇聚链接VLAN间通信为什么要进行VLAN间通信?路由器实现VLAN间通信路由器和交换机的连接方式通信细节三层交换机实现VLAN间通信加速VLAN间通信三层交换机与路由器三层交换机路由器路由器和交换机配合构建LAN的实例使用VLAN设计局域网的特点VLAN增加网络的灵活性不使用VLA