认识异常
大家好 , Java 专栏本应该早就完成的
但是之前发表异常的文章的时候 , 超过当天发布文章限制了
所以那时候就没上传成功 , 真的深感抱歉
刚才发现竟然少文章了
另外祝大家新年快乐
大年初七别忘了吃面条
在计算机程序运行的过程中,总是会出现各种各样的错误。
在Java中,将程序执行过程中发生的不正常的行为叫做异常.
我们以前也见到过许多异常,比如
算数异常
//算术异常
public static void main(String[] args) {
System.out.println(10/0);
}
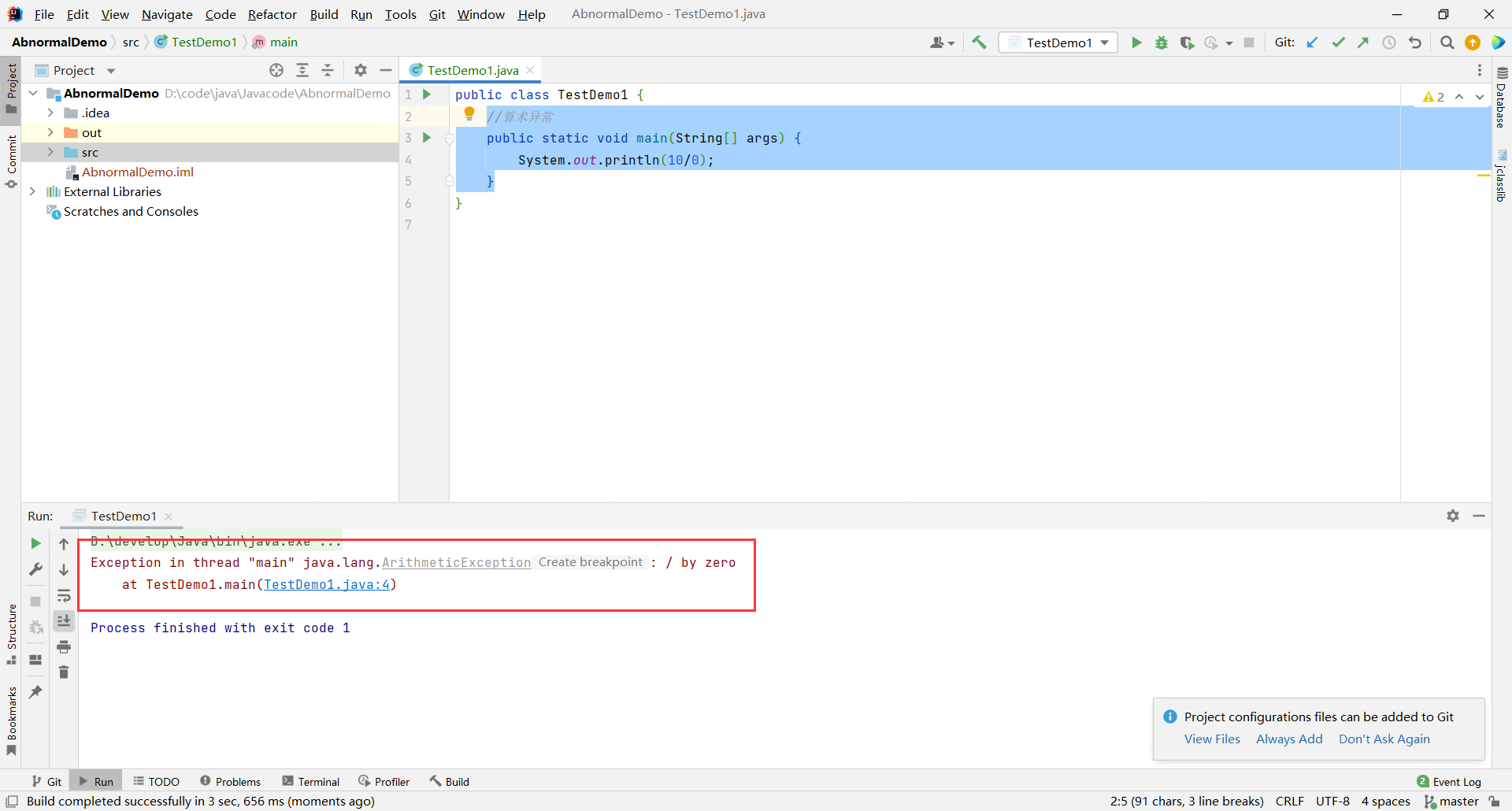
数组越界异常
//数组越界异常
public static void main(String[] args) {
int[] array = {1,2,3};//只有三个元素
System.out.println(array[100]);//访问下标为100的元素,数组中没有就会报错
}
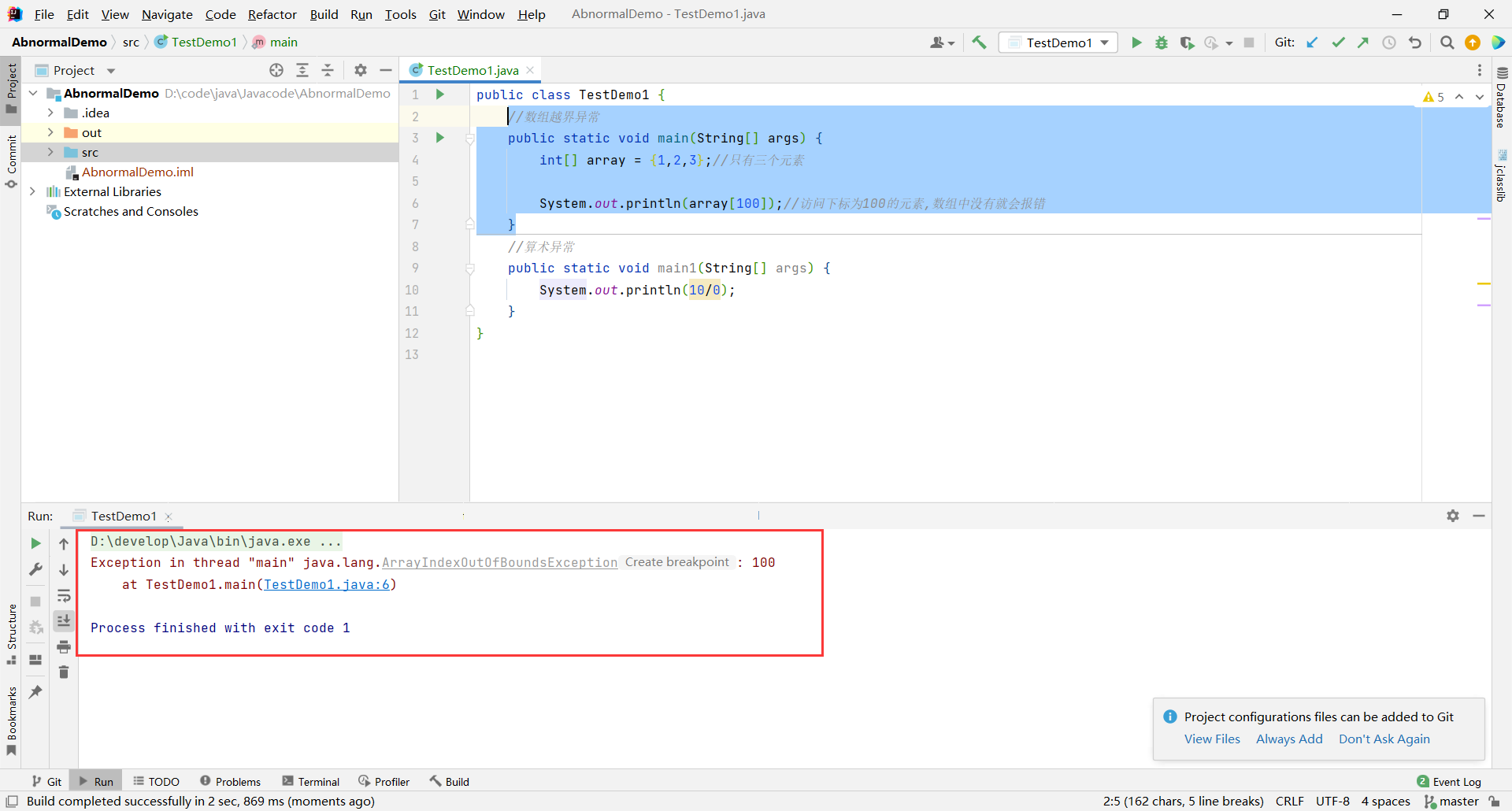
空指针异常
//空指针异常
public static void main(String[] args) {
int[] array = null;//先让数组什么都不指向
array[1] = 99;//报错:因为数组根本没指向任何对象,操作数组就会发生空指针异常
}

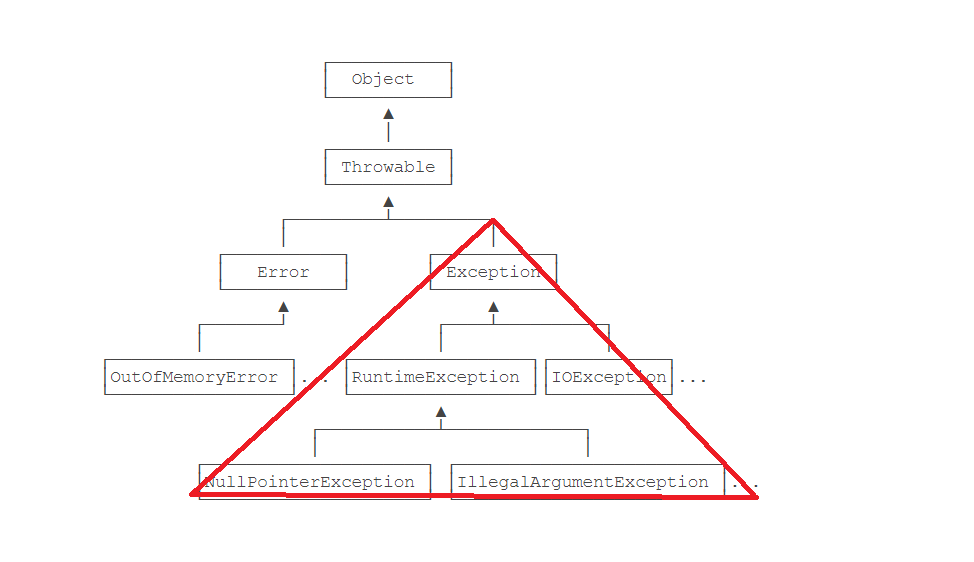
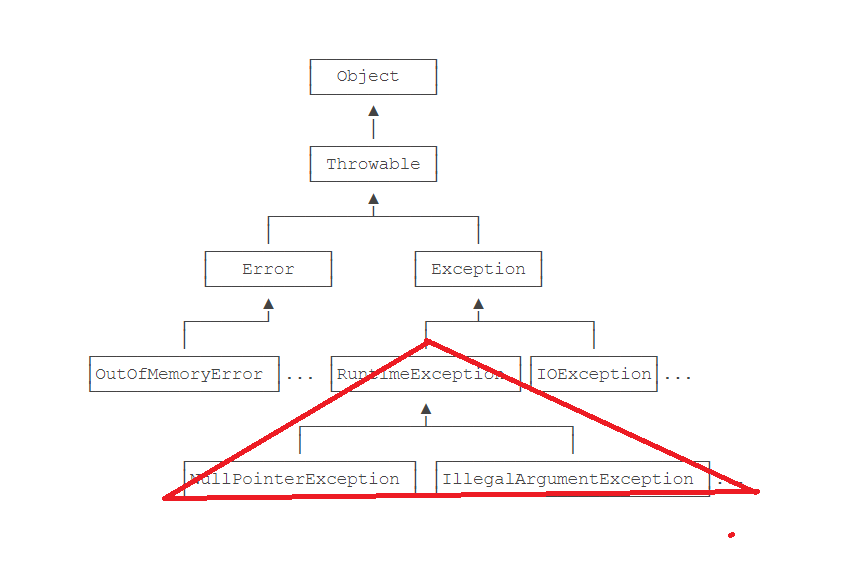
那么我们可以看出来,每一个异常对应的都是一个类.

在编译期间发生的错误,叫做编译时异常(也叫受查异常)
在程序执行期间发生的错误,叫做运行时异常(也叫非受查异常)
RunTimeException及其子类对应的异常.都叫做运行时异常
要注意:我们少写了个分号 括号这种算语法错误,不算异常
真正的异常是指程序变异之后得到
class文件,再通过JVM执行发现错误
在操作前就做好充分的检查,即:事前防御型,每做一步都要检查
形象一点就是:刚交往的男女生,男生想要牵手之前先问问,想要抱抱时候也要先问问
boolean ret = false;
ret = 登陆游戏();
if (!ret) {
处理登陆游戏错误;
return;
}
ret = 开始匹配();
if (!ret) {
处理匹配错误;
return;
}
ret = 游戏确认();
if (!ret) {
处理游戏确认错误;
return;
}
ret = 选择英雄();
if (!ret) {
处理选择英雄错误;
return;
}
ret = 载入游戏画面();
if (!ret) {
处理载入游戏错误;
return;
}
......
缺陷:正常流程和错误处理流程代码混在一起, 代码整体显的比较混乱。
先进行操作,遇到问题再处理,即:事后认错性.
形象一点就是男女朋友,男生想亲亲,直接就霸王硬上攻,过后再说"宝宝我错了".
语法:
//捕获异常使用try...catch语句,把可能发生异常的代码放到try {...}中,然后使用catch捕获对应的Exception及其子类:
try {
} catch() {
} catch() {
}
...
刚才的例子接下来这么写
try {
登陆游戏();
开始匹配();
游戏确认();
选择英雄();
载入游戏画面();
...
} catch (登陆游戏异常) {
处理登陆游戏异常;
} catch (开始匹配异常) {
处理开始匹配异常;
} catch (游戏确认异常) {
处理游戏确认异常;
} catch (选择英雄异常) {
处理选择英雄异常;
} catch (载入游戏画面异常) {
处理载入游戏画面异常;
}
......

优势:正常流程和错误流程是分离开的, 程序员更关注正常流程,代码更清晰,容易理解代码
在Java中,异常处理主要的5个关键字:throw、try、catch、final、throws。
在编写程序时,如果程序中出现错误,此时就需要将错误的信息告知给调用者,比如:参数检测。
在Java中,可以借助throw关键字,抛出一个指定的异常对象,将错误信息告知给调用者。具体语法如下:
throw new XXXException("异常产生的原因");//自定义异常会出现的多一些
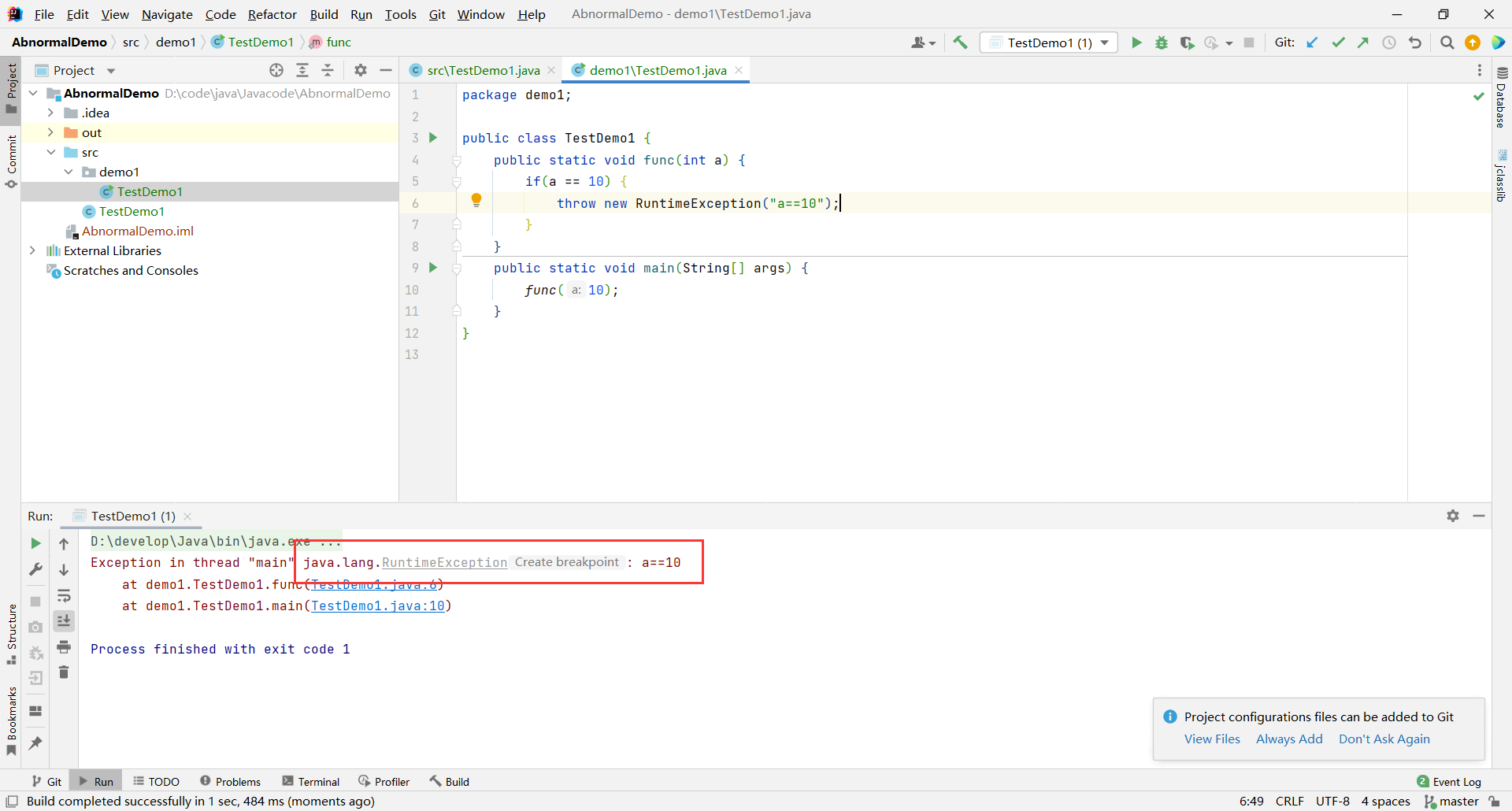
举个栗子:
public class TestDemo1 {
public static void func(int a) {
if(a == 10) {
throw new RuntimeException("a==10");
}
}
public static void main(String[] args) {
func(10);
}
}
注意:
throw必须写在方法体内部
抛出的对象必须是Exception或者他的子类
如果抛出的是RuntimeException或者他的子类,那么我们可以不用处理,交给JVM帮我们处理
如果抛出的是编译时异常,用户必须处理,否则无法通过编译
异常一旦抛出,其后的代码就不会执行
异常的捕获,也就是异常的具体处理方式,主要有两种:异常声明throws 以及 try-catch 捕获处理。
在方法的参数列表后面写 throws , 当方法中抛出编译时异常,用户不想处理该异常,此时就可以借助 throws 将异常抛
给方法的调用者来处理。即当前方法不处理异常,提醒方法的调用者处理异常。直到遇到某个 try ... catch 被捕获为止:
public class TestDemo1 {
public static void func(int a) throws CloneNotSupportedException {
if(a == 10) {
throw new RuntimeException("a==10");
}
}
public static void main(String[] args) {
func(10);
}
}
注意:
throws必须跟在方法的参数列表之后
声明的异常必须是 Exception 以及 他的子类
方法内部如果抛出了多个异常,throws 之后必须跟多个异常类型,之间用逗号隔开,如果抛出多个异常类型具有父子关系,直接声明父类即可。
public class TestDemo1 {
//throws:声明了一下异常,但是并没有处理异常
public static void func(int a) throws RuntimeException,NullPointerException {
if(a == 10) {
throw new RuntimeException("a==10");
} else {
throw new NullPointerException("a == 其他");
}
}
public static void main(String[] args) {
func(10);
}
}
调用声明抛出异常的方法时,调用者必须对该异常进行处理,或者继续使用 throws 抛出
public class TestDemo1 {
public static void func(int a) throws RuntimeException,NullPointerException {
if(a == 10) {
throw new RuntimeException("a==10");
} else {
throw new NullPointerException("a == 其他");
}
}
public static void main(String[] args) throws Exception {
func(10);
}
}
throws 对异常并没有真正处理,而是将异常报告给抛出异常方法的调用者,由调用者处理。如果真正要对异常进行处理,就需要try-catch。
try {
// 将可能出现异常的代码放在这里
} catch (要捕获的异常类型 e) {
// 如果try中的代码抛出异常了,此处catch捕获时异常类型与try中抛出的异常类型一致时,或者是try中抛出异常的基类时,就会被捕获到
// 对异常就可以正常处理,处理完成后,跳出try-catch结构,继续执行后序代码
} catch (要捕获的异常类型 e) {
// 对异常进行处理
} finally {
// 此处代码一定会被执行到
}
// 后序代码
// 当异常被捕获到时,异常就被处理了,这里的后序代码一定会执行
// 如果捕获了,由于捕获时类型不对,那就没有捕获到,这里的代码就不会被执行
//注意:try中的代码可能会抛出异常,也可能不会
举个栗子:
public class TestDemo2 {
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;
} catch (NullPointerException e) {
e.printStackTrace();
System.out.println("捕获到了一个空指针异常");
} catch (ArrayIndexOutOfBoundsException e) {
e.printStackTrace();
System.out.println("捕获到了一个数组越界异常");
}
System.out.println("其他业务逻辑");
}
}
注意:
try后面的代码块内抛出异常位置之后的代码将不会被执行
public class TestDemo2 {
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;
System.out.println("上面那行出现异常,这行是执行不了的");
} catch (NullPointerException e) {
e.printStackTrace();
System.out.println("捕获到了一个空指针异常");
} catch (ArrayIndexOutOfBoundsException e) {
e.printStackTrace();
System.out.println("捕获到了一个数组越界异常");
}
System.out.println("其他业务逻辑");
}
}
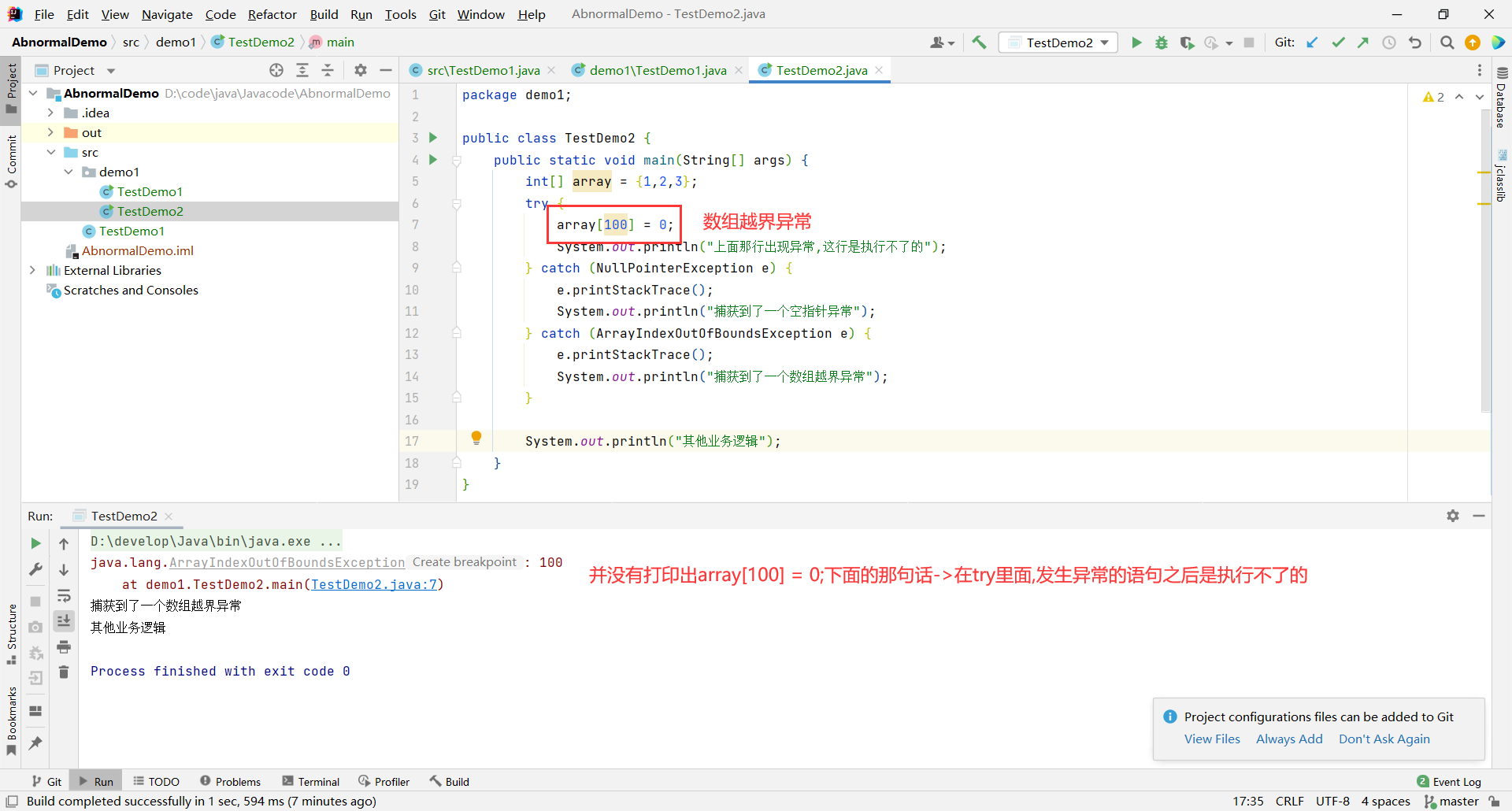
如果抛出异常类型与 catch 时异常类型不匹配,即异常不会被成功捕获,也就不会被处理,继续往外抛,直到 JVM 收到后中断程序.
public class TestDemo2 {
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;//发生数组越界异常
System.out.println("上面那行出现异常,这行是执行不了的");
} catch (NullPointerException e) {//空指针异常
e.printStackTrace();
System.out.println("捕获到了一个空指针异常");
}
System.out.println("其他业务逻辑");
}
}
//try语句中发生的是数组越界异常,而我们的catch里面是空指针异常,数组越界异常就不能被捕捉到.最后一行的其他业务逻辑也就不能被打印了
try 中可能会抛出多个不同的异常对象,则必须用多个 catch 来捕获
public class TestDemo2 {
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;
} catch (NullPointerException e) {
e.printStackTrace();
System.out.println("捕获到了一个空指针异常");
} catch (ArrayIndexOutOfBoundsException e) {
e.printStackTrace();
System.out.println("捕获到了一个数组越界异常");
}
System.out.println("其他业务逻辑");
}
}
如果多个异常的处理方式是完全相同, 也可以写成这样:
public class TestDemo2 {
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;
} catch (NullPointerException | ArrayIndexOutOfBoundsException e) {
e.printStackTrace();
}
System.out.println("其他业务逻辑");
}
}
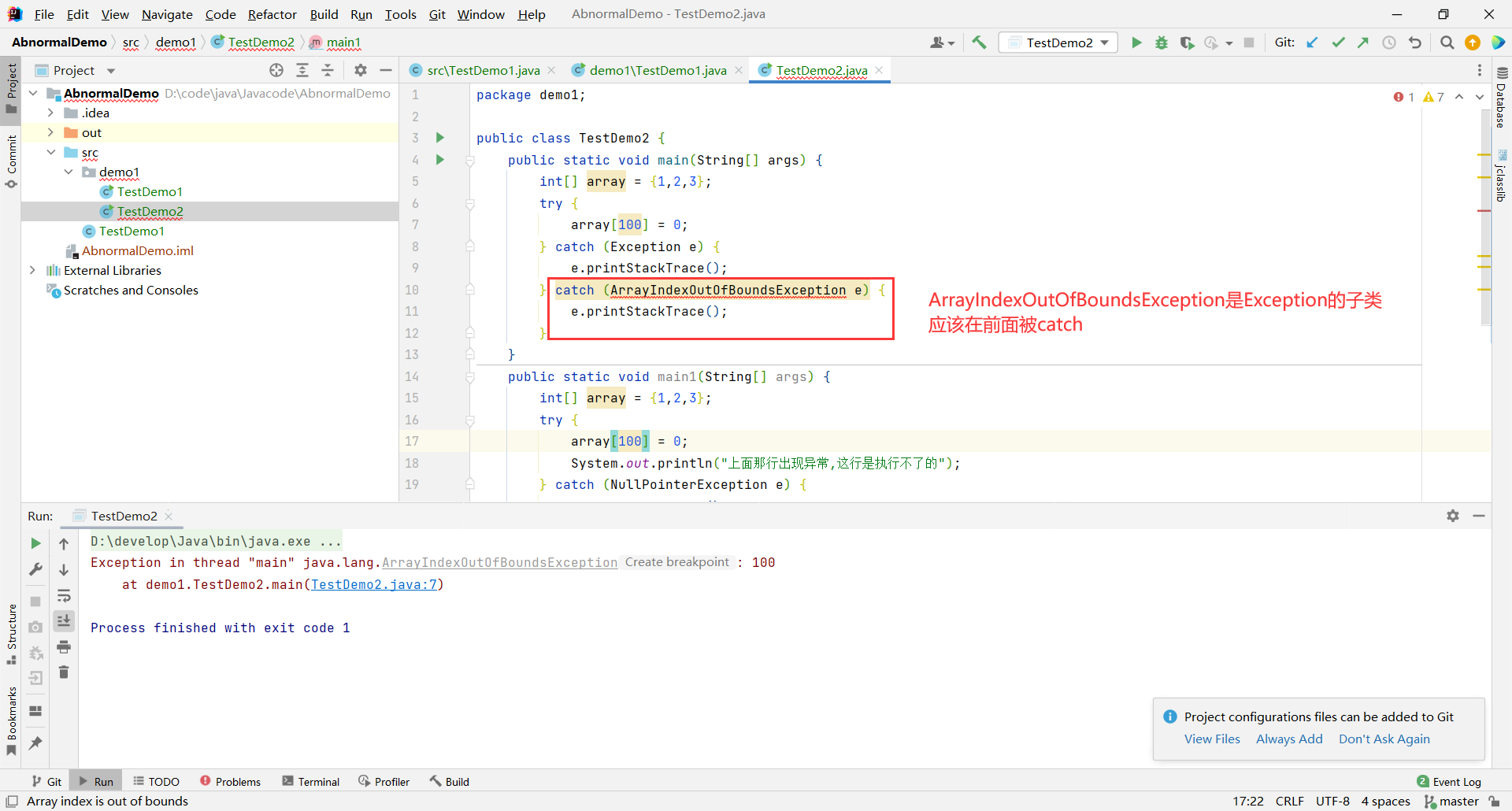
如果异常之间具有父子关系,一定是子类的异常在前 catch,父类的异常在后面 catch,否则语法错误:
public class TestDemo2 {
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;
} catch (Exception e) {
e.printStackTrace();
} catch (ArrayIndexOutOfBoundsException e) {
e.printStackTrace();
}
}
}
正确写法:
public class TestDemo2 {
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;
} catch (ArrayIndexOutOfBoundsException e) {
e.printStackTrace();
} catch (Exception e) {//Exception可以捕捉到所有异常,所以我们可以拿它来兜底
e.printStackTrace();
}
}
}
可以通过一个 catch 捕获所有的异常,即多个异常,一次捕获(不推荐)
public class TestDemo2 {
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;
} catch (Exception e) {//Exception可以捕捉到所有异常,所以我们可以拿它来兜底,但是不能只有Exception
e.printStackTrace();
}
}
}
一个 try 里面只能同时处理一个异常
public class TestDemo2 {
public static void func(int a) throws RuntimeException {
if(a == 10) {
throw new RuntimeException("a == 10");
}
}
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;
func(10);
} catch (ArrayIndexOutOfBoundsException e) {
e.printStackTrace();
} catch (RuntimeException e) {
e.printStackTrace();
}
}
}
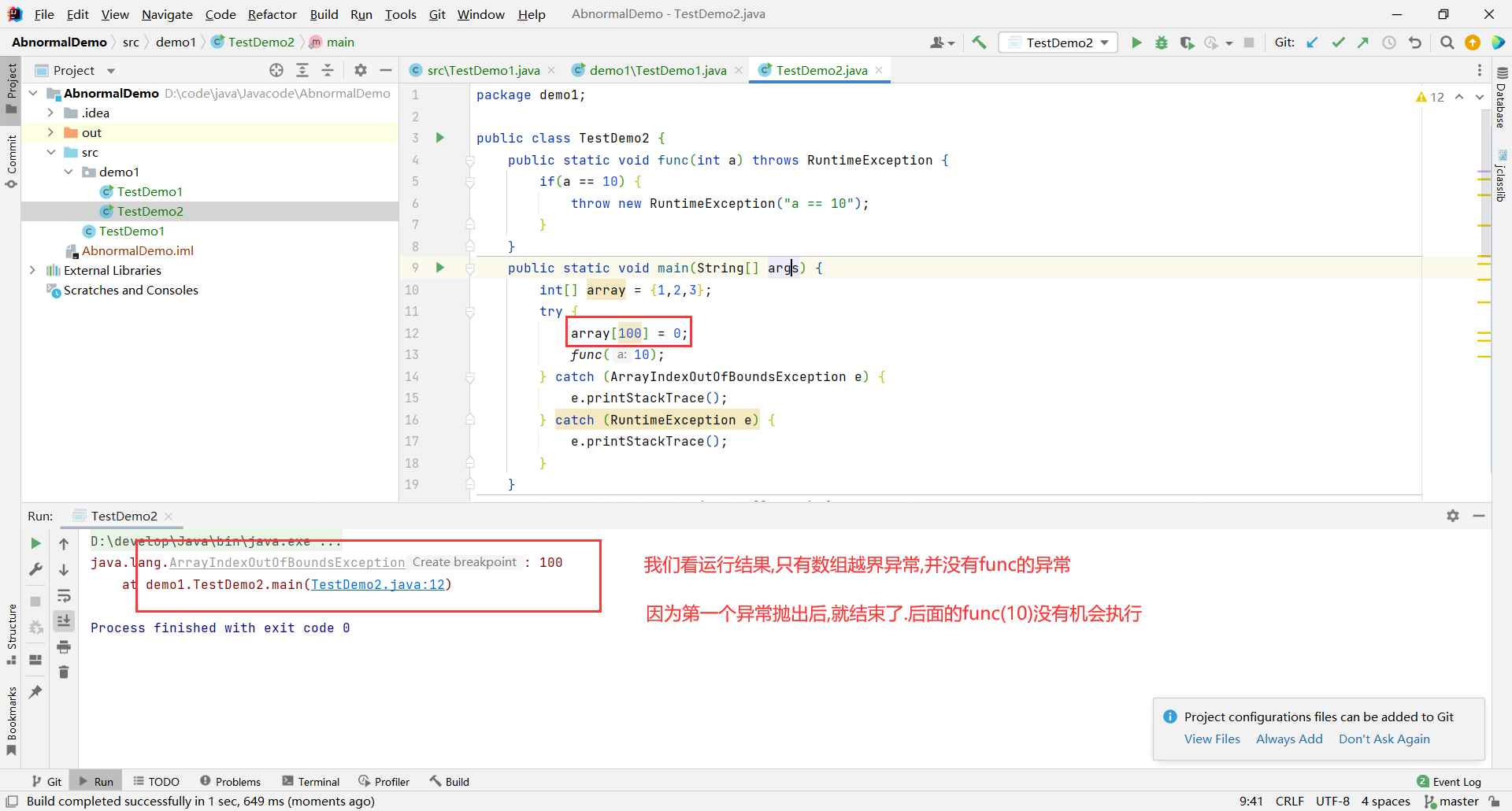
编译时候的异常必须处理!运行时的异常可以不处理,交给 JVM 来处理~
程序员处理了异常,就没啥事了.程序猿没处理, JVM 就帮我们处理了
在写程序时,有些特定的代码,不论程序是否发生异常,都需要执行,比如程序中打开的资源:网络连接、数据库连接、IO 流等,在程序正常或者异常退出时,必须要对资源进进行回收。另外,因为异常会引发程序的跳转,可能导致有些语句执行不到,finally 就是用来解决这个问题的。
语法:
try {
// 可能会发生异常的代码
} catch (异常类型 e) {
// 对捕获到的异常进行处理
} finally {
// 此处的语句无论是否发生异常,都会被执行到
}
// 如果没有抛出异常,或者异常被捕获处理了,这里的代码也会执行
举个栗子:
public static void main(String[] args) {
int[] array = {1,2,3};
try {
array[100] = 0;
} catch (ArrayIndexOutOfBoundsException e) {
e.printStackTrace();
} finally {
System.out.println("finally里面的这句话一定会被执行");
}
}
那么有一个问题:既然 finally 和 try-catch-finally 后面的代码都会执行,那为什么还要有 finally 呢?
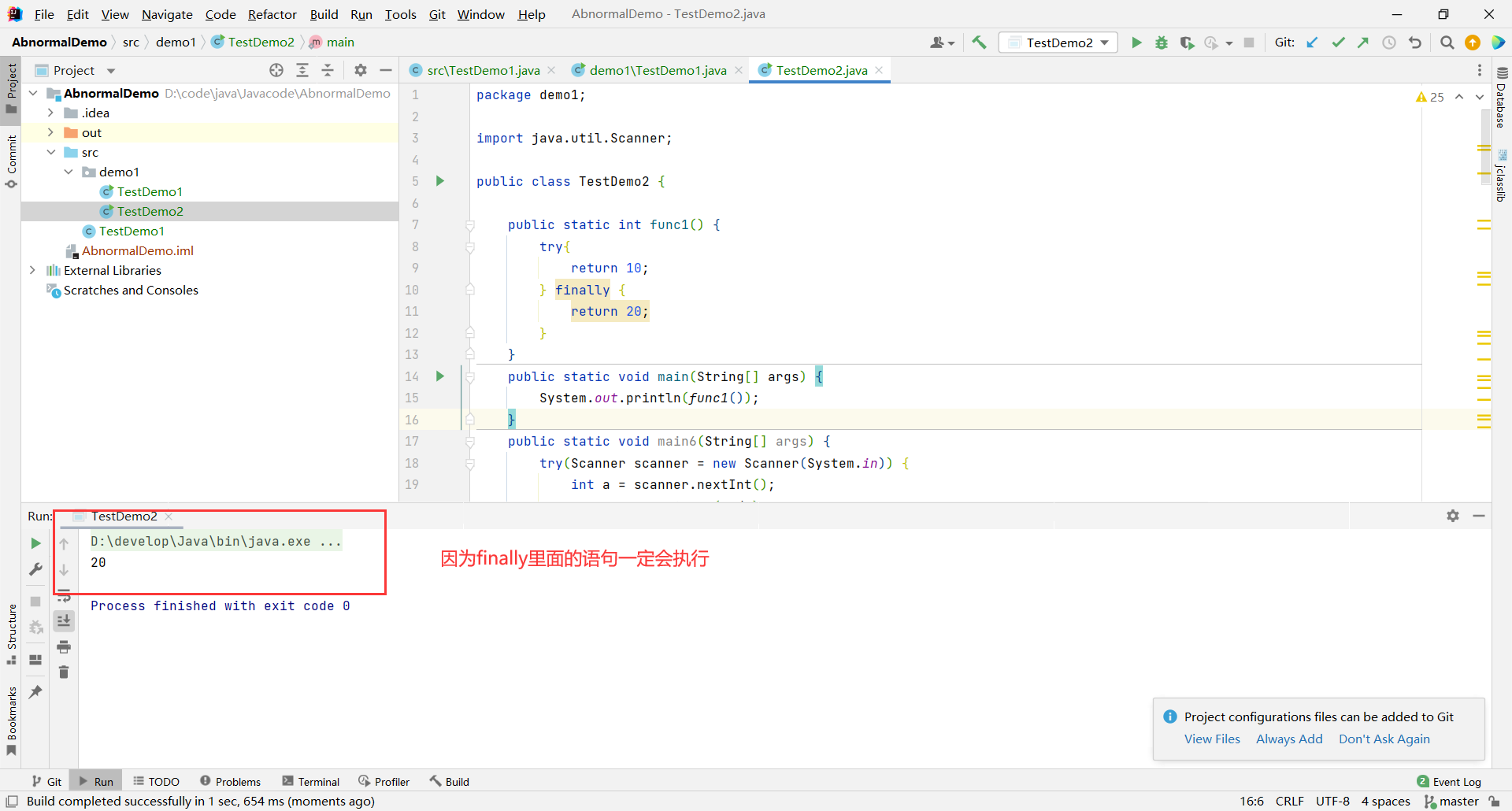
finally一般是用来做资源清理的扫尾操作的
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
try {
int a = scanner.nextInt();
System.out.println(10/a);
} catch (ArithmeticException e) {
System.out.println("捕捉到了算术异常");
e.printStackTrace();
} finally {
scanner.close();//正常我们使用scanner就需要在最后close的
System.out.println("finally语句一定会被执行,所以这里面会执行一些关闭资源的语句");
}
}
当我们只有一个资源进行中的时候,我们也可以这么写
public static void main(String[] args) {
try(Scanner scanner = new Scanner(System.in)) {
int a = scanner.nextInt();
System.out.println(10/a);
} catch (ArithmeticException e) {
System.out.println("捕捉到了算术异常");
e.printStackTrace();
} finally {
//这种情况就可以不用关闭资源了
System.out.println("finally语句一定会被执行,所以这里面会执行一些关闭资源的语句");
}
}
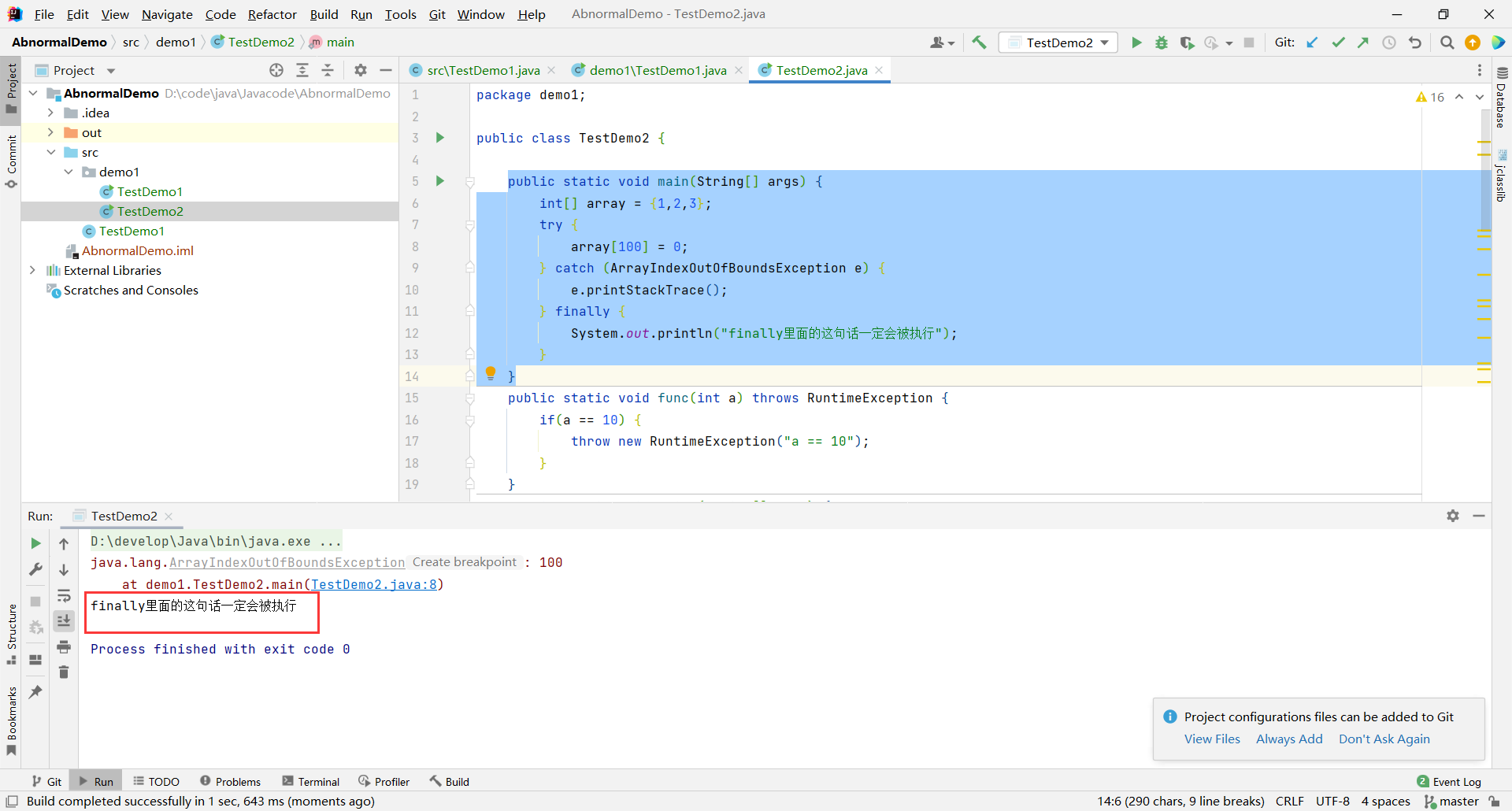
那么我们看这样一道题:
public static int func1() {
try{
return 10;
} finally {
return 20;
}
}
public static void main(String[] args) {
System.out.println(func1());
}
输出结果是多少?
关于 “调用栈”
方法之间是存在相互调用关系的, 这种调用关系我们可以用 “调用栈” 来描述. 在
JVM中有一块内存空间称为 “虚拟机栈” 专门存储方法之间的调用关系. 当代码中出现异常的时候, 我们就可以使用e.printStackTrace();的方式查看出现异常代码的调用栈.
如果本方法中没有合适的处理异常的方式, 就会沿着调用栈向上传递.如果向上一直传递都没有合适的方法处理异常, 最终就会交给 JVM 处理, 程序就会异常终止
//这种就是抛出异常,有捕捉的
public static void func3(int a) throws ArithmeticException {
if(a == 10) {
throw new ArithmeticException("a == 10");
}
}
public static void main(String[] args) {
try {
func3(10);
} catch (ArithmeticException e) {
e.printStackTrace();
}
}
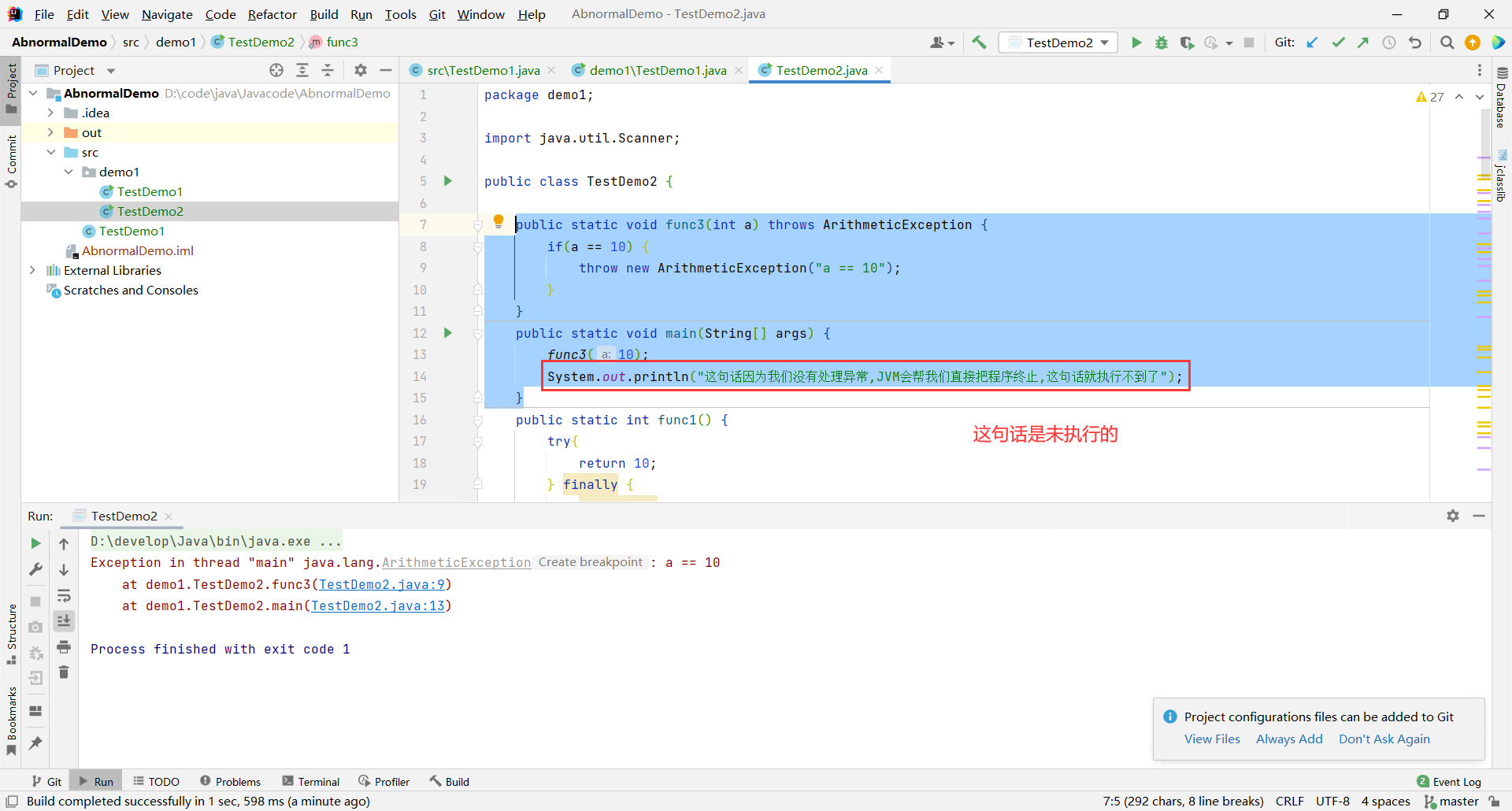
//这种就是我们没有捕获异常,JVM帮我们直接把程序终止掉了
public static void func3(int a) throws ArithmeticException {
if(a == 10) {
throw new ArithmeticException("a == 10");
}
}
public static void main(String[] args) {
func3(10);
System.out.println("这句话因为我们没有处理异常,JVM会帮我们直接把程序终止,这句话就执行不到了");
}
try 中的代码try 中的代码出现异常, 就会结束 try 中的代码, 看和 catch 中的异常类型是否匹配.catch 中的代码finally 中的代码都会被执行到(在该方法结束之前执行).main 方法也没有合适的代码处理异常, 就会交给 JVM 来进行处理, 此时程序就会异常终止.在一个大型项目中,可以自定义新的异常类型,但是,保持一个合理的异常继承体系是非常重要的。
语法:
自定义一个异常类,继承 Exception 或者 RunTimeException
继承自
Exception的异常默认是受查异常
继承自RuntimeException的异常默认是非受查异常.
在这个异常类当中,实现一个带有一个参数( String )的构造方法,参数代表报错原因
//用户名错误,我们设计出来的异常类
public class UserNameError extends RuntimeException {
public UserNameError(String message) {
super(message);
}
}
//密码错误,我们设计出来的异常类
public class PasswordError extends RuntimeException {
public PasswordError(String message) {
super(message);
}
}
例如,我们实现一个简易的用户登录功能
我们先来自定义异常类
//用户名错误,我们设计出来的异常类
public class UserNameError extends RuntimeException {
public UserNameError(String message) {
super(message);
}
}
//密码错误,我们设计出来的异常类
public class PasswordError extends RuntimeException {
public PasswordError(String message) {
super(message);
}
}
再来写我们的测试逻辑
public class Login {
private String userName = "admin";
private String pass = "123456";
public void LoginInfor(String userName,String password) throws UserNameError,PasswordError {
if(!this.userName.equals(userName)) {//不相等的情况
throw new UserNameError("用户名错误");
}
if(!this.pass.equals(password)) {//不相等的情况
throw new PasswordError("密码错误");
}
//走到这里,代表登陆成功
System.out.println("登陆成功");
}
public static void main(String[] args) {
try {
Login login = new Login();
login.LoginInfor("admin","avd");
} catch (UserNameError e) {
System.out.println("用户名错误");
e.printStackTrace();
} catch (PasswordError e) {
System.out.println("密码错误");
e.printStackTrace();
}
}
}
至此 , Java 基础部分已经分享完毕 , 多线程以及文件操作等难度稍微有点高的内容我会放到 JavaWeb 阶段跟大家再来分享

我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在学习Rails,并阅读了关于乐观锁的内容。我已将类型为integer的lock_version列添加到我的articles表中。但现在每当我第一次尝试更新记录时,我都会收到StaleObjectError异常。这是我的迁移:classAddLockVersionToArticle当我尝试通过Rails控制台更新文章时:article=Article.first=>#我这样做:article.title="newtitle"article.save我明白了:(0.3ms)begintransaction(0.3ms)UPDATE"articles"SET"title"='dwdwd
在Cooper的书BeginningRuby中,第166页有一个我无法重现的示例。classSongincludeComparableattr_accessor:lengthdef(other)@lengthother.lengthenddefinitialize(song_name,length)@song_name=song_name@length=lengthendenda=Song.new('Rockaroundtheclock',143)b=Song.new('BohemianRhapsody',544)c=Song.new('MinuteWaltz',60)a.betwee
我早就知道Ruby中的“常量”(即大写的变量名)不是真正常量。与其他编程语言一样,对对象的引用是唯一存储在变量/常量中的东西。(侧边栏:Ruby确实具有“卡住”引用对象不被修改的功能,据我所知,许多其他语言都没有提供这种功能。)所以这是我的问题:当您将一个值重新分配给常量时,您会收到如下警告:>>FOO='bar'=>"bar">>FOO='baz'(irb):2:warning:alreadyinitializedconstantFOO=>"baz"有没有办法强制Ruby抛出异常而不是打印警告?很难弄清楚为什么有时会发生重新分配。 最佳答案
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
