指视频文件在单位时间内使用的数据流量,也叫码流率。码率越大,说明单位时间内取样率越大,数据流精度就越高,这样表现出来的的效果就是:视频画面更清晰画质更高。
一般以秒为单位,如:128 kbps,表示每秒通过网络传送的数据量为 128k bit.
指视频每秒钟包含多少张画面,一般单位为fps。
帧率越高,表示单位时间内图像帧的个数,普通的视频文件一般在25fps - 30fps之间,表示每秒钟25-30张图像,而一般涉及到游戏等帧率会比较高一些,一般>60fps。在其他的参数一定的情况下,帧率越高,视频或游戏的流畅度更好,反之,帧率越低,视频或游戏的流畅度越次,低于15fps的时候人眼一般都会比较感觉到明显的卡顿
分辨率就是(矩形)图片的长度和宽度,即图片的尺寸。分辨率影响图像大小,与图像大小成正比:分辨率越高,图像越大;分辨率越低,图像越小。
为什么要做编码压缩:

对于视频数据而言,视频编码的最主要目的是数据压缩。这是因为动态图像的像素形式表示数据量极为巨大,存储空间和传输带宽完全无法满足保存和传输的需求。例如,图像的每个像素的三个颜色分量RGB各需要一个字节表示,那么每一个像素至少需要3字节,分辨率1280×720的图像的大小为2.76M字节。
如果对于同样分辨率的视频,如果帧率为25帧/秒,那么传输所需的码率将达到553Mb/s!如果对于更高清的视频,如1080P、4k、8k视频,其传输码率更是惊人。这样的数据量,无论是存储还是传输都无法承受。因此,对视频数据进行压缩称为了必然之选。
视频信息为什么可以被压缩
视频信息之所以存在大量可以被压缩的空间,是因为其中本身就存在大量的数据冗余。其主要类型有:
1). 预测编码
预测编码可以用于处理视频中的时间和空间域的冗余。视频处理中的预测编码主要分为两大类:帧内预测和帧间预测。
通常在视频码流中,I帧全部使用帧内编码,P帧/B帧中的数据可能使用帧内或者帧间编码。
目前主流的视频编码算法均属于有损编码,通过对视频造成有限而可以容忍的损失,获取相对更高的编码效率。而造成信息损失的部分即在于变换量化这一部分。在进行量化之前,首先需要将图像信息从空间域通过变换编码变换至频
H.264编解码主要分为五部分:帧间和帧内预测(Estimation)、变换(Transform)和反变换、量化(Quantization)和反量化、环路滤波(Loop Filter)、熵编码(Entropy Coding)。
在H.264进行编码的过程中,每一帧的H图像被分为一个或多个切片(slice)进行编码。每一个切片包含多个宏块(MB,Macroblock)。宏块是H.264标准中基本的编码单元,其基本结构包含一个包含16×16个亮度像素块和两个8×8色度像素块,以及其他一些宏块头信息。在对一个宏块进行编码时,每一个宏块会分割成多种不同大小的子块进行预测。
帧内预测采用的块大小可能为16×16或者4×4,帧间预测/运动补偿采用的块可能有7种不同的形状:16×16、16×8、8×16、8×8、8×4、4×8和4×4。相比于早期标准只能按照宏块或者半个宏块进行运动补偿,H.264所采用的这种更加细分的宏块分割方法提供了更高的预测精度和编码效率。在变换编码方面,针对预测残差数据进行的变换块大小为4×4或8×8(仅在FRExt版本支持)。相比于仅支持8×8大小的变换块的早期版本,H.264避免了变换逆变换中经常出现的失配问题。

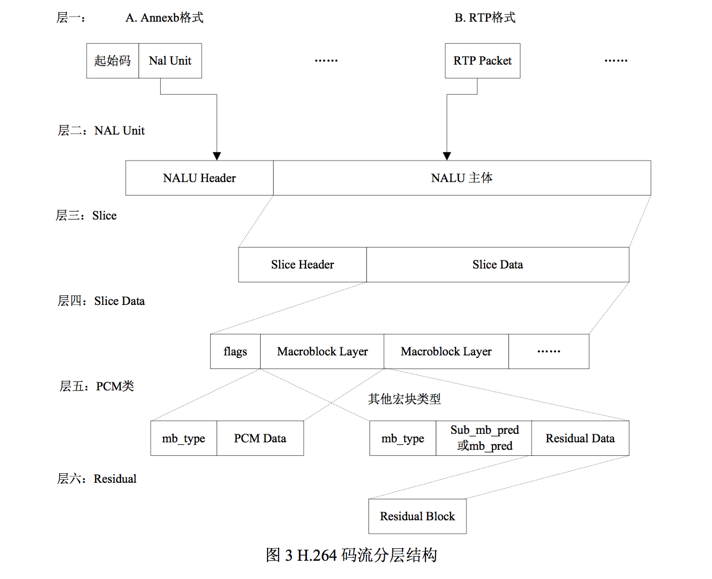
在H.264 中,分为: 序列、图像、片、宏块、子宏块五个层次
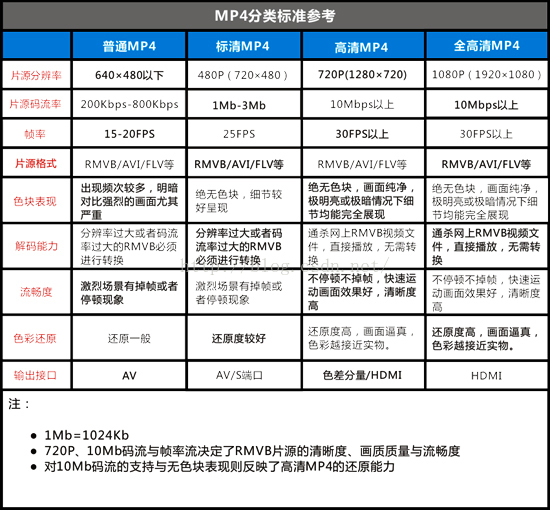
一帧图片经过 H.264 编码器之后,就被编码为一个或多个切片(slice),而装载着这些切片(slice)的载体,就是 NALU。
什么是 NALU 呢?
H.264 原始码流(又称为裸流),是有一个接一个的NALU组成的,而它的功能分为两层: 视频编码层(VCL, Video Coding Layer)和网络提取层(NAL, Network Abstraction Layer)。VCL 数据即编码处理的输出,它表示被压缩编码后的视频数据序列,网络提取层(NAL, Network Abstraction Layer)将VCL封装,成为一个个NALU。 NALU的结构是:NAL头+RBSP

切片的主要作用是用作宏块(Macroblock)的载体。
切片之所以被创造出来,主要目的是为限制误码的扩散和传输。
如何限制误码的扩散和传输?
每个切片(slice)都应该是互相独立被传输的,某片的预测(片(slice)内预测和片(slice)间预测)不能以其它片中的宏块(Macroblock)为参考图像。
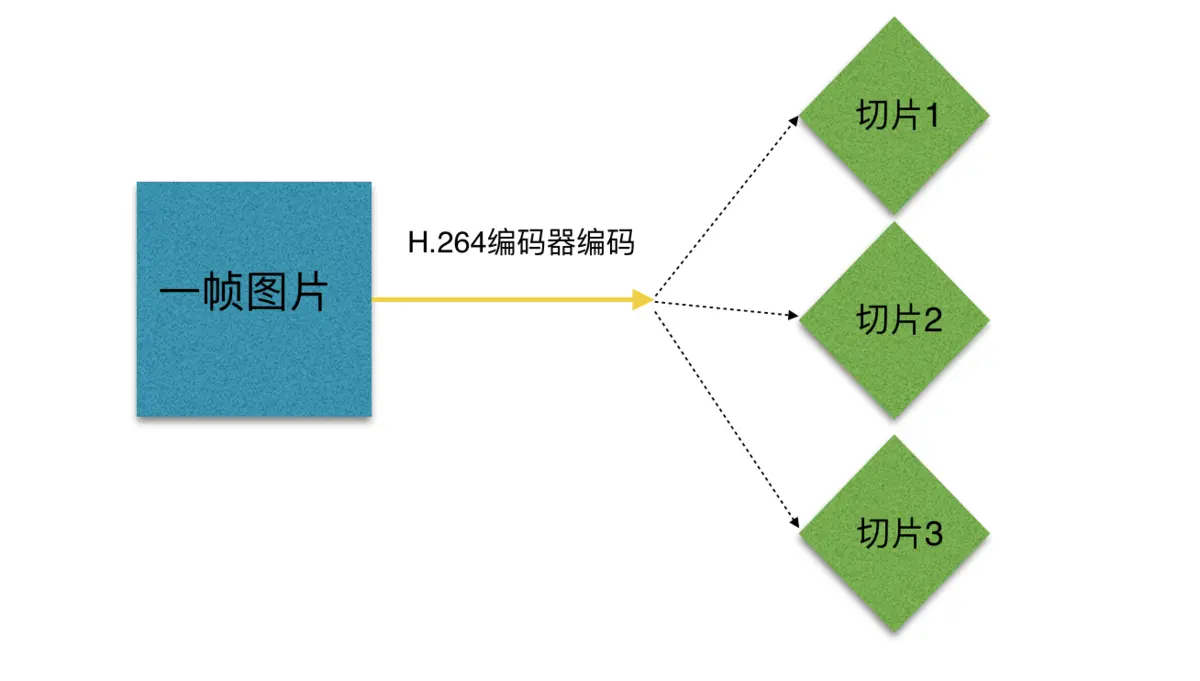
切片可分为 切片头和切片数据【如上】,一个切片的数据又被分成若干个宏块【如下】。

分片数据中则是宏块,其实宏块存储像素数据的地方。
宏块是视频信息的主要承载者,因为它包含着每一个像素的亮度和色度信息。视频解码最主要的工作则是提供高效的方式从码流中获得宏块中的像素阵列。
组成部分:一个宏块由一个16×16亮度像素和附加的一个8×8 Cb和一个 8×8 Cr 彩色像素块组成。每个图象中,若干宏块被排列成片的形式。
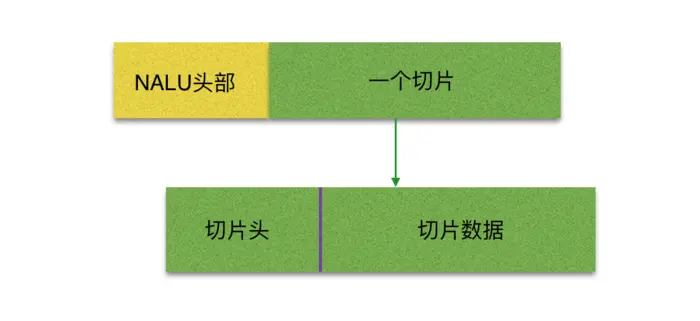
从上图中,可以看到,宏块中包含了宏块类型、预测类型、Coded Block Pattern、Quantization Parameter、像素的亮度和色度数据集等等信息。
对于切片(slice)来讲,分为以下几种类型:
I片:只包 I宏块,I 宏块利用从当前片中已解码的像素作为参考进行帧内预测(不能取其它片中的已解码像素作为参考进行帧内预测)。
P片:可包 P和I宏块,P 宏块利用前面已编码图象作为参考图象进行帧内预测,一个帧内编码的宏块可进一步作宏块的分割:即 16×16、16×8、8×16 或 8×8 亮度像素块(以及附带的彩色像素);如果选了 8×8 的子宏块,则可再分成各种子宏块的分割,其尺寸为 8×8、8×4、4×8 或 4×4 亮度像素块(以及附带的彩色像素)。
B片:可包 B和I宏块,B 宏块则利用双向的参考图象(当前和 来的已编码图象帧)进行帧内预测。
SP片(切换P):用于不同编码流之间的切换,包含 P 和/或 I 宏块
SI片:扩展档次中必须具有的切换,它包 了一种特殊类型的编码宏块,叫做 SI 宏块,SI 也是扩展档次中的必备功能。
NALU 整体结构可以呼之欲出了,以下就引用 H.264 文档当中的一幅图了
DTS、PTS、GOP
- DTS : 解码时间戳
- PTS: 显示时间戳
- GOP : 一组完整的IBP帧画面
GOP 是画面组,一个 GOP 是一组连续的画面。下图GOP(Group of Picture)所示:
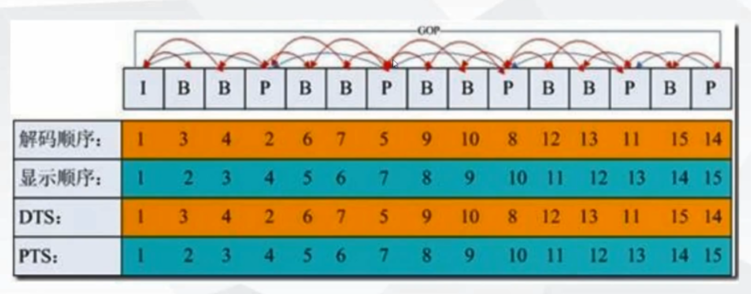
GOP 一般有两个数字,如 M = 3,N = 12,M 制定 I 帧与 P 帧之间的距离,N 指定两个 I 帧之间的距离。那么现在的 GOP 结构是:
I BBP BBP BBP BB I增大图片组能有效的减少编码后的视频体积,但是也会降低视频质量,至于怎么取舍,得看需求了。
从上图,可以看到,DTS和PTS的顺序是不一致的,并且每组GOP中开头都是I帧,然后后面都是B、P帧,如果开头的I帧图像质量比较差时,也会影响到一个GOP中后续B、P帧的图像质量.
- I帧(intra picture) : 帧内编码帧,自身可以通过视频解压算法解压成一张单独的完整的图片;
- B帧(bidirectional) : 双向预测内插编码帧,参考前面和后面两帧的数据加上本帧的变化而得出的本帧数据
- P帧 : 前向预测编码帧,参考前面而得出的本帧数据.
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
我正在尝试在Ruby中复制Convert.ToBase64String()行为。这是我的C#代码:varsha1=newSHA1CryptoServiceProvider();varpasswordBytes=Encoding.UTF8.GetBytes("password");varpasswordHash=sha1.ComputeHash(passwordBytes);returnConvert.ToBase64String(passwordHash);//returns"W6ph5Mm5Pz8GgiULbPgzG37mj9g="当我在Ruby中尝试同样的事情时,我得到了相同sha
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手