如今,网络服务、数字媒体、传感器日志数据等众多来源产生了大量数据,只有一小部分数据得到妥善管理或利用来创造价值。读取大量数据、处理数据并根据这些数据采取行动比以往任何时候都更具挑战性。
在这篇文章中,我试图展示:
在我之前的文章 “Elastic:使用 Kafka 部署 Elastic Stack”,我实现了如下的一个数据 pipeline:

在今天的文章中,我将实现如下的一个数据 pipeline:
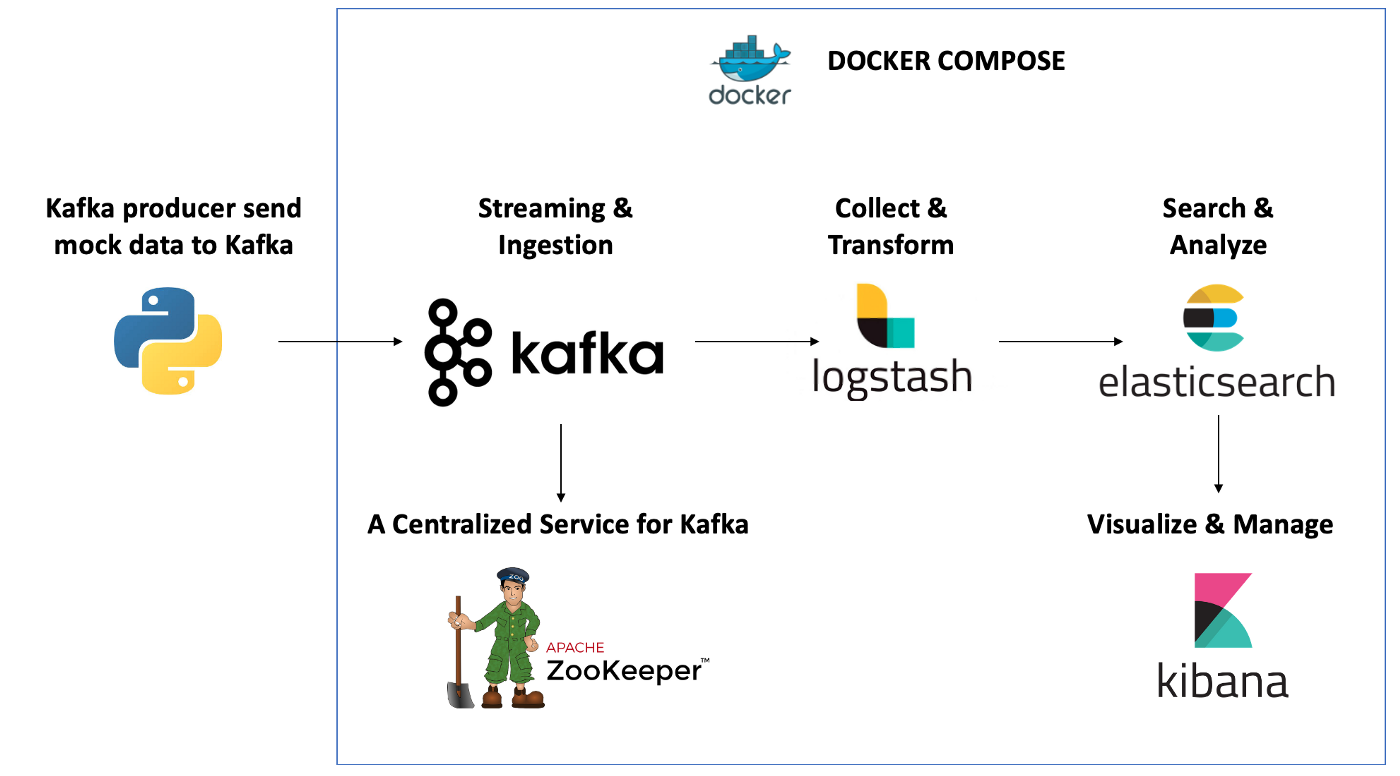
在今天的展示中,我将使用最新的 Elastic Stack 8.6.1 来进行展示。我将使用如下的配置:
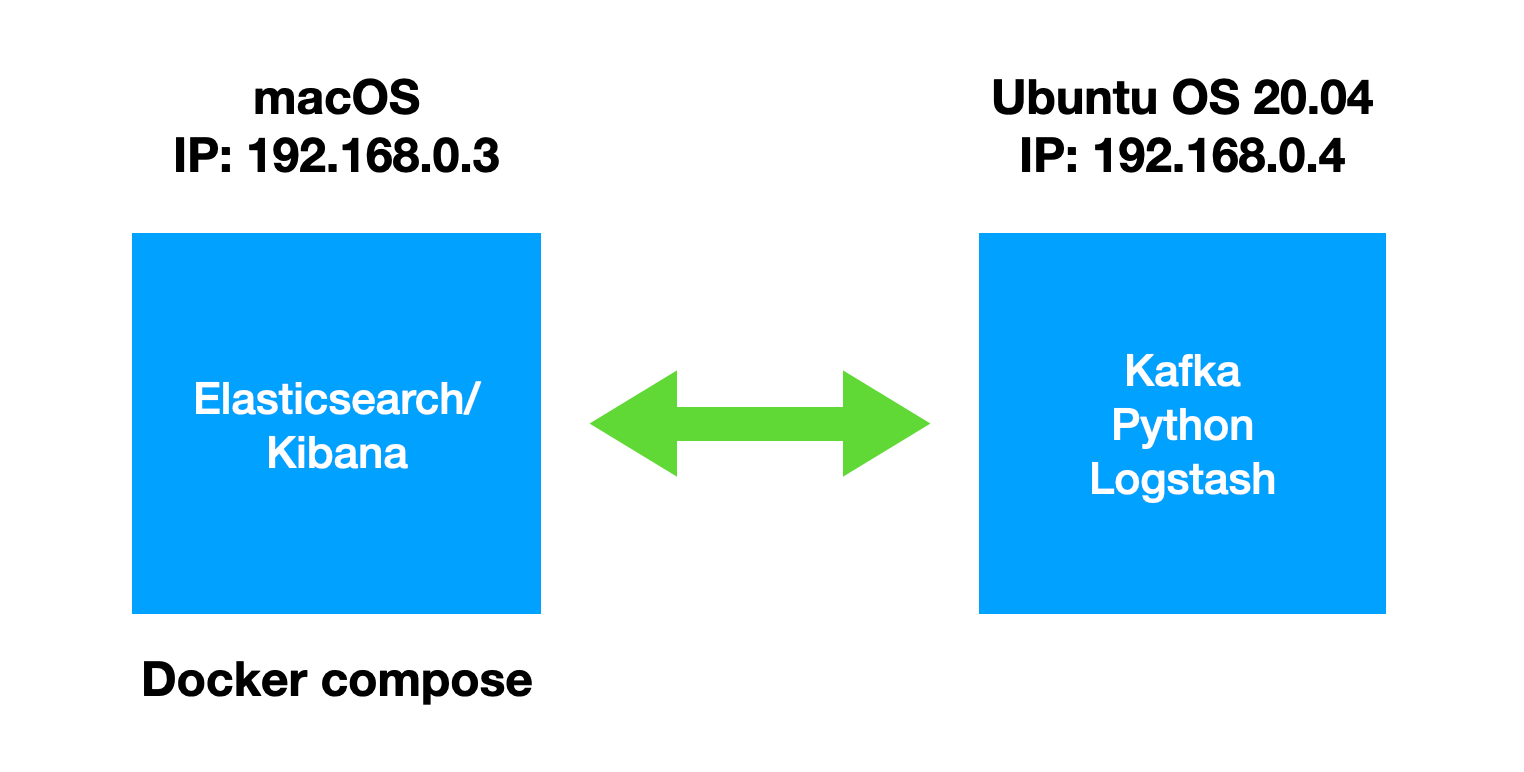
如上所示,我使用两台机器:macOS 用于安装 Elastic Stack,而另外一台 Ubuntu 机器将被用于安装 Kafka 及 Logstash。我将在 Ubuntu OS 机器上使用 Python 向 Kafka 写入数据。
我将使用 docker compose 的方法来安装 Elasticsearch 及 Kibana。我们可以参考文章 “Elasticsearch:使用 Docker compose 来一键部署 Elastic Stack 8.x” 来进行部署。当然,我们也可以参阅如下的文章来进行部署:
在默认的情况下,Elasticsearch 的访问是带有 HTTPS 的安全访问。
我们可以在电脑的 terminal 中打入如下的命令来检查:
curl -k -u elastic:password https://192.168.0.3:9200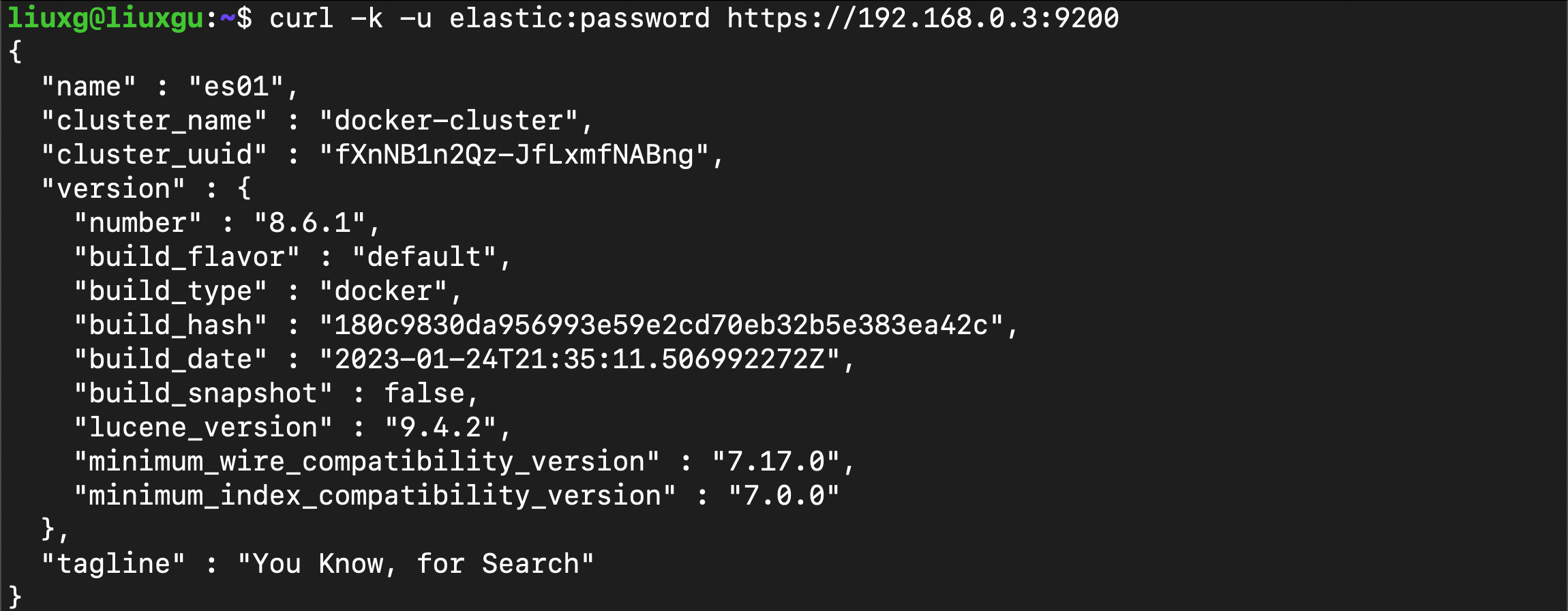
上述命令是在 Ubuntu OS 的机器上运行。它表明,我们可以在 Ubuntu OS 的机器上成功地访问 Elasticsearch。
我们安装涉及设置 Apache Kafka(我们的消息代理)。Kafka 使用 ZooKeeper 来维护配置信息和同步,因此在设置 Kafka 之前,我们需要先安装 ZooKeeper:
sudo apt-get install zookeeperd接下来,让我们下载并解压缩 Kafka:
wget https://apache.mivzakim.net/kafka/2.4.0/kafka_2.13-2.4.0.tgz
tar -xzvf kafka_2.13-2.4.0.tgz
sudo cp -r kafka_2.13-2.4.0 /opt/kafka现在,我们准备运行 Kafka,我们将使用以下脚本进行操作:
sudo /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties你应该开始在控制台中看到一些 INFO 消息:

Kafka 的配置如下:
我们接下来打开另外一个控制台中,并为 registered_user 创建一个主题:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic registered_user我们创建了一个叫做 registered_user 的 topic。上面的命令将返回如下的结果:
$ /opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic registered_user
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic registered_user.我们现在已经完全为开始管道做好了准备。
有关 kafka 的安装,我们也可以使用 docker-compose 来进行安装。具体安装步骤请参考 “Elastic:Data pipeline:使用 Kafka => Logstash => Elasticsearch”。
我们接下来安装 Logstash。我们到 Elastic 的官方网站来下载时候我们平台的安装包:
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4wliuxg@liuxgu:~/logstash$ wget https://artifacts.elastic.co/downloads/logstash/logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w
--2023-01-29 14:20:31-- https://artifacts.elastic.co/downloads/logstash/logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w
Resolving artifacts.elastic.co (artifacts.elastic.co)... 34.120.127.130, 2600:1901:0:1d7::
Connecting to artifacts.elastic.co (artifacts.elastic.co)|34.120.127.130|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 341638094 (326M) [binary/octet-stream]
Saving to: ‘logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w’
logstash-8.6.1-amd64.de 100%[==============================>] 325.81M 10.7MB/s in 31s
2023-01-29 14:21:03 (10.6 MB/s) - ‘logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w’ saved [341638094/341638094]
liuxg@liuxgu:~/logstash$ mv 'logstash-8.6.1-amd64.deb?_gl=1*1b5e8ui*_ga*MTEyNjEzOTY5Ni4xNjQ3MDY1ODMx*_ga_Q7TEQDPTH5*MTY3NDk3MjkzNS4zODAuMS4xNjc0OTcyOTQ4LjAuMC4w' logstash-8.6.1-amd64.deb
我们使用如下的命令来安装 Logstash:
sudo dpkg -i logstash-8.6.1-amd64.deb liuxg@liuxgu:~/logstash$ sudo dpkg -i logstash-8.6.1-amd64.deb
[sudo] password for liuxg:
(Reading database ... 386953 files and directories currently installed.)
Preparing to unpack logstash-8.6.1-amd64.deb ...
Unpacking logstash (1:8.6.1-1) over (1:8.4.2-1) ...
Setting up logstash (1:8.6.1-1) ...
Installing new version of config file /etc/logstash/jvm.options ...为了能够配置 Logstash 能够正确地访问 Elasticsearch,我们可以参考我之前的文章 “Logstash:如何连接到带有 HTTPS 访问的集群”。我们需要按照文章里的要求创建一个叫做 truststore.p12 的文件。由于我们是以 docker 的形式启动 Elasticsearch 及 Kibana 的,我们在 macOS 的机器上使用如下的命令来拷贝证书。我们先查看容器:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a2374f620b78 docker.elastic.co/kibana/kibana:8.6.1 "/bin/tini -- /usr/l…" 7 hours ago Up 7 hours (healthy) 0.0.0.0:5601->5601/tcp elastic8-kibana-1
e2d6443b8edb docker.elastic.co/elasticsearch/elasticsearch:8.6.1 "/bin/tini -- /usr/l…" 7 hours ago Up 7 hours (healthy) 9200/tcp, 9300/tcp elastic8-es03-1
a29bbeb4bdf2 docker.elastic.co/elasticsearch/elasticsearch:8.6.1 "/bin/tini -- /usr/l…" 7 hours ago Up 7 hours (healthy) 9200/tcp, 9300/tcp elastic8-es02-1
81de3d45943c docker.elastic.co/elasticsearch/elasticsearch:8.6.1 "/bin/tini -- /usr/l…" 7 hours ago Up 7 hours (healthy) 0.0.0.0:9200->9200/tcp, 9300/tcp elastic8-es01-1我们可以看到有一个叫做 elastic8-es01-1 的容器。
$ pwd
/Users/liuxg/data/elastic8
$ ls
docker-compose.yml http_ca.crt kibana.yml write_to_kafka.py
$ docker cp 81de3d45943c:/usr/share/elasticsearch/config/certs/ca/ca.crt .
$ ls
ca.crt docker-compose.yml http_ca.crt kibana.yml write_to_kafka.py
$ ls
ca.crt docker-compose.yml kibana.yml 运用 ca.crt 文件,我们使用如下的命令来创建一个叫做 truststore.p12 的文件。它的 storepass 是 password:
keytool -import -file ca.crt -keystore truststore.p12 -storepass password -noprompt -storetype pkcs12$ keytool -import -file ca.crt -keystore truststore.p12 -storepass password -noprompt -storetype pkcs12
Certificate was added to keystore
$ ls
ca.crt docker-compose.yml kibana.yml truststore.p12从上面,我们可以看出来它创建了 truststore.p12 这个文件。我们接下来把这个文件拷贝到 Ubuntu OS 机器下的 /etc/logstash/conf.d 目录中。
liuxg@liuxgu:/etc/logstash/conf.d$ ls
truststore.p12我们接下来在地址 /etc/logstash/conf.d 创建一个叫做叫做 kafka_to_logstash.conf 的配置文件:
kafka_to_logstash.conf
input {
kafka {
bootstrap_servers => "192.168.0.4:9092"
topics => ["registered_user"]
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => ["https://192.168.0.3:9200"]
index => "registered_user"
workers => 1
user => "elastic"
password => "password"
ssl_certificate_verification => true
truststore => "/etc/logstash/conf.d/truststore.p12"
truststore_password => "password"
}
}在上面,请注意的是:
这样我们的 Logstash 的配置就完成了。
sudo service logstash start我们可以通过如下的命令来检查 Logstash 是否已经成功地运行起来了。
service logstash statusliuxg@liuxgu:~$ service logstash status
● logstash.service - logstash
Loaded: loaded (/lib/systemd/system/logstash.service; disabled; vendor preset: enabled)
Active: active (running) since Sun 2023-01-29 15:25:57 CST; 7s ago
Main PID: 60841 (java)
Tasks: 33 (limit: 18977)
Memory: 508.6M
CGroup: /system.slice/logstash.service
└─60841 /usr/share/logstash/jdk/bin/java -Xms1g -Xmx1g -Djava.awt.headless=true ->
1月 29 15:25:57 liuxgu systemd[1]: Started logstash.
1月 29 15:25:57 liuxgu logstash[60841]: Using bundled JDK: /usr/share/logstash/jdk上面表明我们的 logstash 服务已经被成功地运行起来了。我们还可以通过如下的命令来查看 logstash 服务的日志:
journalctl -u logstash
我们使用如下的 Python 应用向我们的 Kafka topic “registered_user” 来写入数据:
write_to_kafka.py
from faker import Faker
from kafka import KafkaProducer
import json
fake = Faker()
import time
def get_registered_data():
return {
'first name': fake.first_name(),
'last name': fake.last_name(),
'age': fake.random_int(0, 60),
'address': fake.address(),
'register_year': fake.year(),
'register_month': fake.month(),
'register_day': fake.day_of_month(),
'monthly_income': fake.random_int(28000, 100000)
}
def json_serializer(data):
return json.dumps(data).encode('utf-8')
producer = KafkaProducer(bootstrap_servers=['192.168.0.4:9092'],
value_serializer=json_serializer)
if __name__ == '__main__':
while True:
registered_data = get_registered_data()
print(registered_data)
producer.send('registered_user', registered_data)
time.sleep(3)为了运行上面的应用,我们必须安装如下的两个包:
pip3 install Faker
pip3 install kafka-python我们在 Ubuntu OS 机器上运行上面的代码:
python write_to_kafka.py 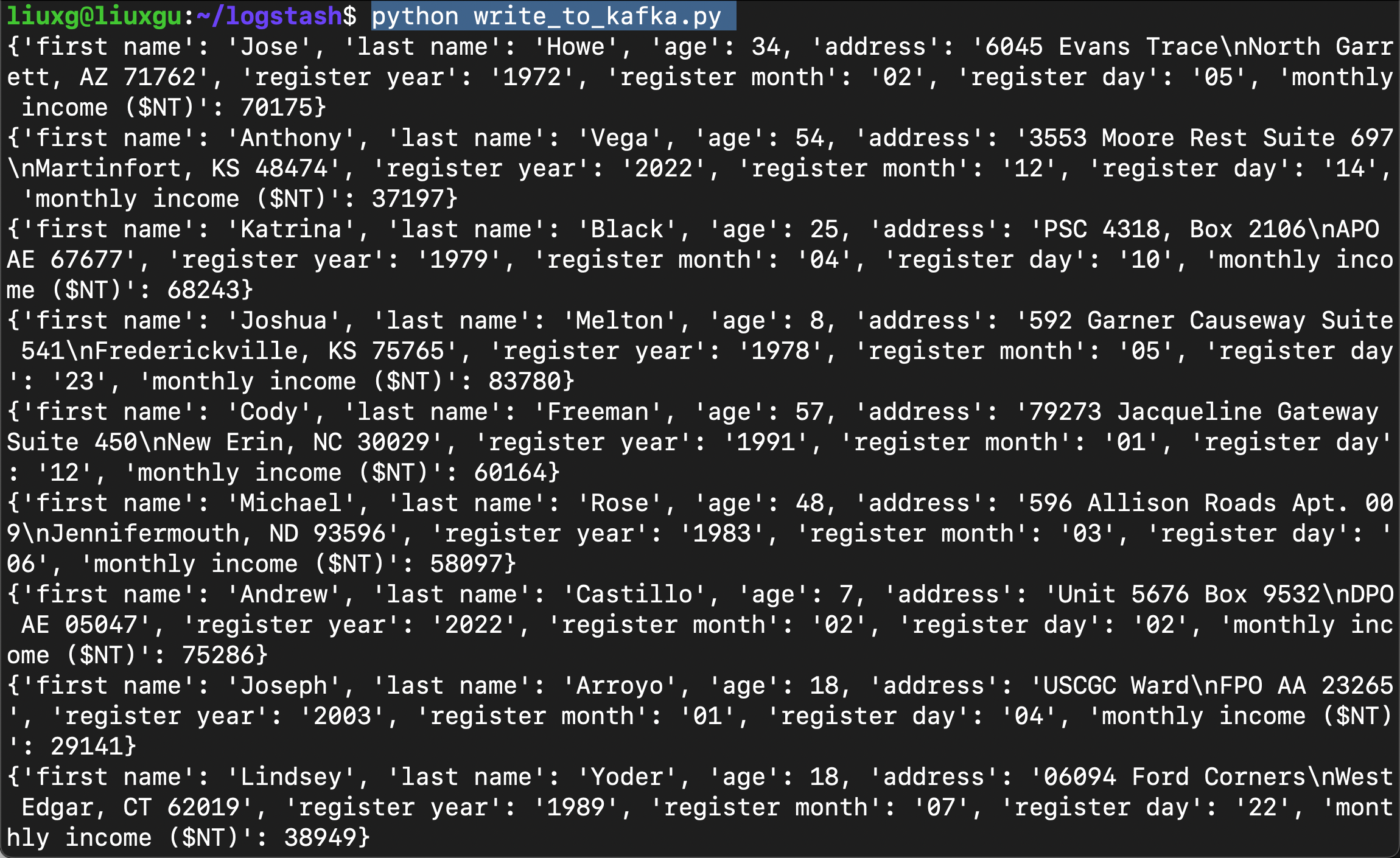
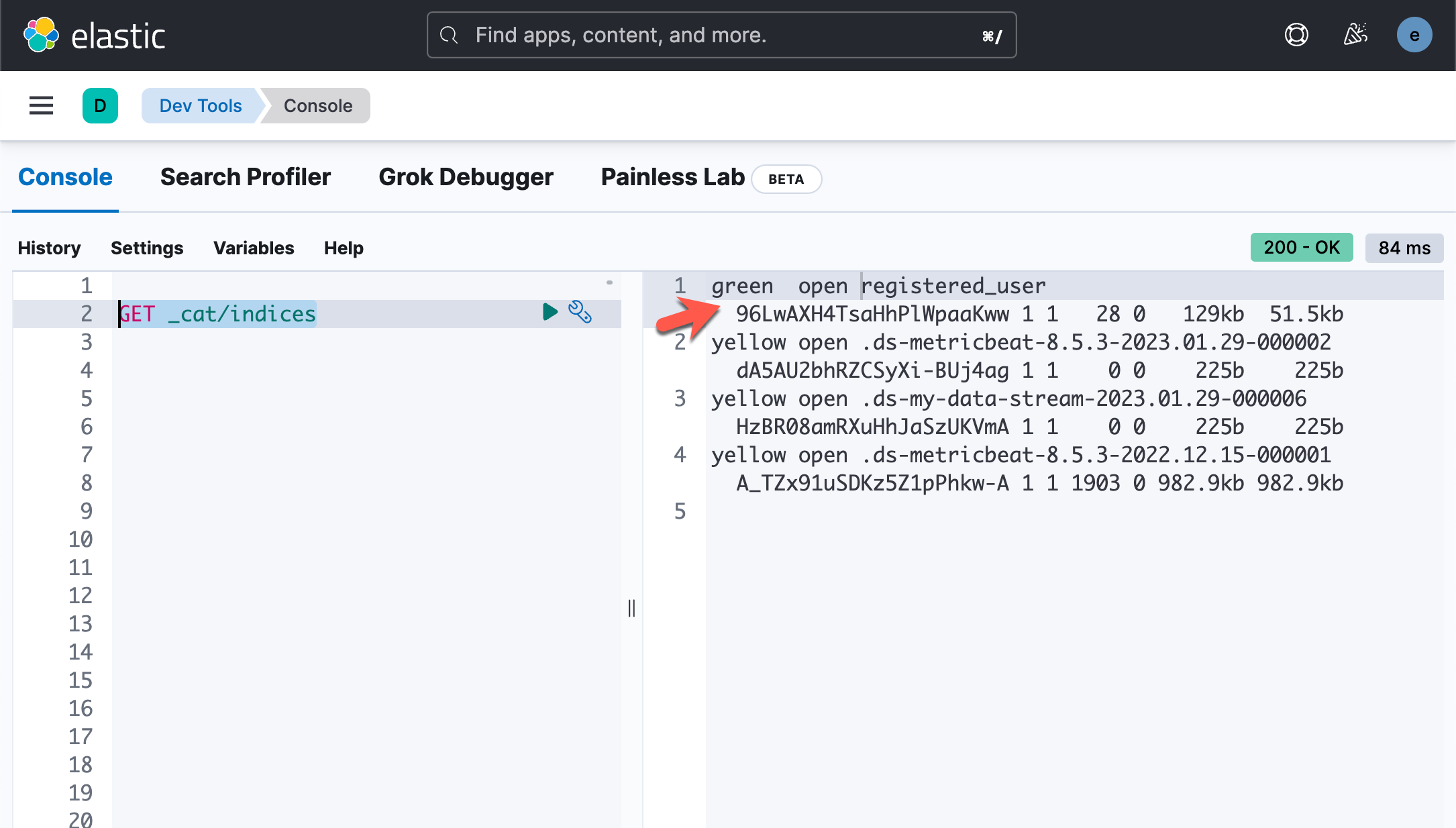
我们回到 Kibana 的界面来进行查看:
GET _cat/indices上面的命令显示:
我们可以对这个文件进行搜索:
GET registered_user/_search我们可以看到如下的结果:
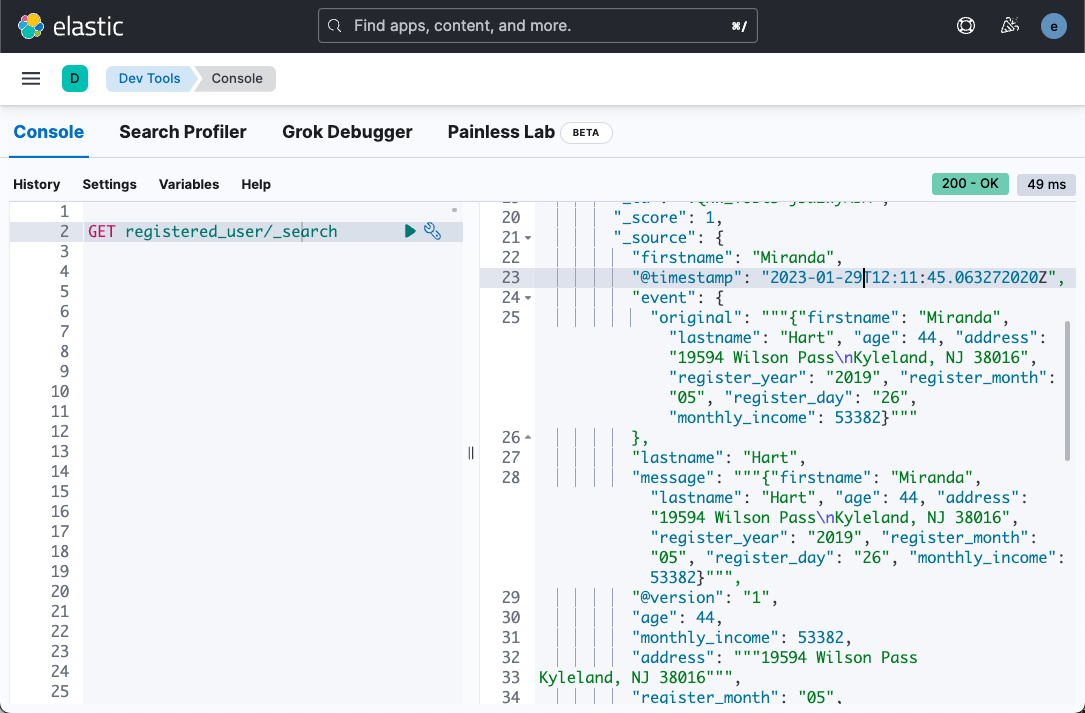
从上面,我们可以看出来我们的数据已经被结构化。
我们可以针对这个索引进行可视化。你可以阅读我博客里的相应文章以了解更多。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A